基于梯度改进的元学习少样本文本分类方法
1.本发明涉及一种计算机自然语言处理方法,特别涉及一种基于梯度改进的元学习少样本文本分类方法。
背景技术:
2.近年来随着互联网的普及和发展,大量文本数据的积累为深度学习提供了有力的训练支撑,从而促进了深度学习技术的快速发展。然而在许多少样本文本分类任务场景中,可供训练的数据样本量不足以支撑复杂的深度神经网络,更重要的是,特定任务下学习到的深度神经网络模型难以泛化到新的文本分类任务之中,即传统的深度学习网络学习新类别的能力有限。而元学习是解决这个问题的一种方法,它使网络能够学习如何学习。其关键思想是随着模型学习过任务的增多,模型能够从不同任务之间学到一些可以泛化的通用知识,从而在遇到新的分类任务时,能够利用模型的学习能力,在仅有少量样本的场景下,出色地完成模型从未见过的分类任务。元学习的训练过程涉及内部层面和外部层面;在内部层面,模型每次都会遇到新的分类任务,其类别是之前未学习过的类别,模型试图通过从前学习到的通用知识,在该新的分类任务中快速完成学习和适应,内层的学习误差将会传递给外部层面,外部层面根据误差来修改模型的通用知识,从而具备越来越完善的学习能力。尽管元学习很大程度上提升了少样本文本分类任务的表现,但它也存在着若干待解决的问题,其中一个显著的问题是网络容易在训练集上过拟合,导致模型在新任务上的泛化表现不好。
技术实现要素:
3.本发明要解决的技术问题在于提供一种基于梯度改进的元学习少样本文本分类方法,该方法针对元学习内部和外部层次的梯度算法进行改进,改善了元学习存在的过拟合问题。
4.为了解决上述技术问题,本发明通过以下方式来实现:
5.基于梯度改进的元学习少样本文本分类方法,包括以下具体步骤:
6.1)元学习训练数据划分,构建基于少样本文本框架下的元数据集,并将元数据集划分为训练任务集、验证任务集和测试任务集;
7.2)构建元学习模型;
8.3)训练元学习模型,通过构建训练任务集,每次将一批次的元任务送入到内层基础学习器,元任务对应的训练将外层元学习器的参数作为内层基础学习器的初始化参数,内层基础学习器在元任务的支持集上进行训练,得到在支持集上的误差和梯度,再在查询集上检验内层基础学习器训练的效果,得到查询集上的误差和梯度;
9.4)将学习到的元学习模型应用于少样本文本分类。
10.进一步的,所述步骤1)中元数据集的划分过程包括:元学习根据分类任务包括元学习的外部层次和元学习的内部层次,其中元学习的外部层次划分为训练任务集、验证任
务集和测试任务集,元学习的内部层次划分为支持集和查询集,并保证各个集合类别互斥;构建对应的n-way k-shot任务,从元数据集抽取n个不同类别,每类别中抽取出k+q个样本,其中k个样本划分到支持集,q个样本划分到查询集。
11.进一步的,所述步骤3)中训练元学习模型的具体步骤如下:
12.31)通过对元学习的内层梯度改进模块,计算出内层基础学习器传递给外层元学习器的梯度;
13.首先元学习模型在支持集上利用元知识学习,得到适用于解决新任务的模型参数,其公式如下:
[0014][0015]
式中:f
θ
表示外层元学习器的元模型,模型的参数为θ,表示模型随机从训练任务集中抽取的任务ti支持集上的损失,代表反向传播得到的梯度,α表示内层基础学习器的学习率,θ表示经过更新后内层模型的参数;
[0016]
然后在查询集上检验参数θ的效果,通过模型在查询集上的预测结果和查询集数据的真实标签,得到模型的损失和梯度,内层基础学习器将梯度传递给外层元学习器,并加上内层模型在支持集上最后一步更新的损失和反向传播梯度,外层元学习器根据此梯度来更新元知识,其公式如下:
[0017][0018]
式中:表示内层基础学习器经过在支持集上的学习后得到的模型,表示模型在支持集上最后一次更新的参数,表示模型在支持集上最后一次更新时的损失,w
sprt
表示模型赋予损失的权重,f
θ
′
表示内层模型经过在支持集上进行学习得到的适用于解决新任务的模型,模型的参数为θ
′
,表示新参数在查询集上的损失的梯度,β表示外层元学习器的学习率,θ
*
表示经过更新后的参数;
[0019]
32)外层元学习器的梯度改进模型根据各个元任务回传出的梯度特征,动态地分配不同的权重,计算出总的梯度回传给元学习器,元学习器根据此梯度和外层学习率来更新一次参数,其公式如下:
[0020][0021]
式中表示各任务回传梯度的权重,对于每一批内层任务ti,其权重的计算公式如下:
[0022][0023]
式中表示元学习模型内部层次学习任务时回传的梯度,表示所有内层学习任务回传梯度之和。
[0024]
与现有技术相比,本发明具有的有益效果:
[0025]
本发明针对元学习存在的过拟合问题,分别对元学习的内部层次和外部层次的梯度计算算法进行改进,显著地改善了元学习存在的过拟合问题;通过将预测结果和查询集文本数据的真实标签进行比对,采用交叉熵损失,反向传播得到梯度,外层根据内层传出来的梯度,对元知识进行更新完善。经过在训练任务集中的学习之后,模型能够学习到通用的元知识,能够在验证任务集和测试任务集中,仅通过少量的样本学习,就能对模型之前未见过的分类任务做出较好的预测。
附图说明
[0026]
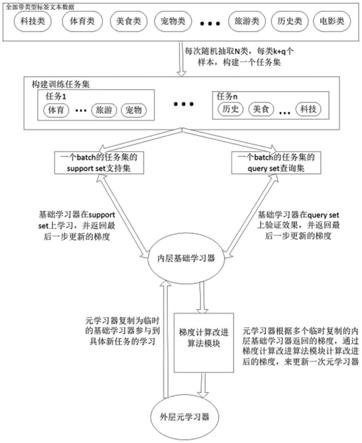
图1为本发明的基于梯度改进的元学习少样本文本分类方法的模型图。
[0027]
图2为本发明中梯度计算改进算法模块的模型图。
具体实施方式
[0028]
下面结合附图和具体实施例对本发明的具体实施方式作进一步详细的说明。应当理解,本文所使用的诸如“具有”、“包含”以及“包括”术语并不排除一个或多个其它网络或其组合的存在或添加。
[0029]
如图1~2所示,基于梯度改进的元学习少样本文本分类方法,包括以下具体步骤:
[0030]
1)元学习训练数据划分,构建基于少样本文本框架下的元数据集,并将元数据集划分为训练任务集、验证任务集和测试任务集;
[0031]
2)构建元学习模型;基于maml(model-agnostic meta-learning)框架,在元学习的内层基础学习器的构建上,选择包括但不限于基于bert预训练模型的文本分类网络、基于词嵌入和lstm的文本分类网络,而随机初始化外层网络的参数。
[0032]
3)训练元学习模型,通过构建训练任务集,每次将一批次的元任务送入到内层基础学习器,元任务对应的训练将外层元学习器的参数作为内层基础学习器的初始化参数,内层基础学习器在元任务的支持集上进行训练,得到在支持集上的误差和梯度,再在查询集上检验内层基础学习器训练的效果,得到查询集上的误差和梯度;
[0033]
4)将学习到的元学习模型应用于少样本文本分类。将元学习模型的参数初始化给解决各个未见过的文本少样本分类任务的基础学习器,基础学习器在分类任务的支持集上进行很少步骤的训练,即可在该任务上完成文本分类。
[0034]
进一步的,所述步骤1)中元数据集的划分过程包括:元学习根据分类任务包括元学习的外部层次和元学习的内部层次,其中元学习的外部层次划分为训练任务集、验证任务集和测试任务集,元学习的内部层次划分为支持集和查询集,并保证各个集合类别互斥;构建对应的n-way k-shot任务,从元数据集抽取n个不同类别,每类别中抽取出k+q个样本,其中k个样本划分到支持集,q个样本划分到查询集。
[0035]
元学习的训练和测试数据是各不相同且有一定相似度的分类任务,即元学习中的每一个训练或测试数据的形式是一个分类任务,通常称作元学习的外部层次,外部层次根据不同的分类任务,划分为训练任务集、验证任务集和测试任务集,训练任务集支撑元学习模型学习跨任务的元知识,验证任务集和测试任务集中均为模型从未见过的分类任务,供元学习模型验证学习到的元知识在未见过的分类任务上的表现效果;元学习的内层是去学
习一个具体的分类任务,包含了带标签的多类训练数据支持集(support set)和测试数据查询集(query set)。
[0036]
在少样本文本分类任务中,对于训练任务集的构建,从一集合中随机取样n个不同类别,每类中抽取取k个样本作为支持集(support set),q个样本作为查询集(query set);对于测试任务集的构建,从一集合中随机取样n个不同类别,每类别取k个样本作为支持集,q个样本作为查询集。模型利用外层已经从训练过程中学习到的元知识,在内层的n way k shot任务的支持集中有限的n*k个样本中进行学习,并在查询集上进行一轮预测,通过将预测结果和查询集文本数据的真实标签进行比对,采用交叉熵损失,反向传播得到梯度,外层根据内层传出来的梯度,对元知识进行更新完善。经过在训练任务集中的学习之后,模型能够学习到通用的元知识,能够在验证任务集和测试任务集中,仅通过少量的样本学习,就能对模型之前未见过的分类任务做出较好的预测。
[0037]
所述步骤3)中训练元学习模型的具体步骤如下:
[0038]
31)通过对元学习的内层梯度改进模块,计算出内层基础学习器传递给外层元学习器的梯度;
[0039]
传统的元学习模型存在着比较严重的过拟合问题,即模型在训练任务集上表现的很好,但是在测试任务集中,模型在内层利用元知识,经过在支持集上的学习,在查询集上表现得并没有达到预期效果。这是由于元模型在训练过程中,对训练任务集中有限的分类任务反复多轮地学习,得到了并不完全通用的元知识,模型很容易在训练过程中,错误地学习到具体任务的具体知识。究其原因,是因为原模型定义的损失函数或者梯度的计算算法,导致模型在有限的训练任务集中,学习到有利于这些具体任务集的针对性知识的时候,损失函数反而下降,造成模型学到的元知识不能够很好的运用到未见过的文本分类任务之中。
[0040]
首先元学习模型在支持集上利用元知识学习,得到适用于解决新任务的模型参数,其公式如下:
[0041][0042]
式中:f
θ
表示外层元学习器的元模型,模型的参数为θ,表示模型随机从训练任务集中抽取的任务ti支持集上的损失,代表反向传播得到的梯度,α表示内层基础学习器的学习率,θ
′
表示经过更新后内层模型的参数;
[0043]
然后在查询集上检验参数θ
′
的效果,通过模型在查询集上的预测结果和查询集数据的真实标签,得到模型的损失和梯度,内层基础学习器将梯度传递给外层元学习器,并加上内层模型在支持集上最后一步更新的损失和反向传播梯度,外层元学习器根据此梯度来更新元知识,其公式如下:
[0044][0045]
式中:表示内层基础学习器经过在支持集上的学习后得到的模型,表示模型在支持集上最后一次更新的参数,表示模型在支持集上
最后一次更新时的损失,w
sprt
表示模型赋予损失的权重,f
θ
′
表示内层模型经过在支持集上进行学习得到的适用于解决新任务的模型,模型的参数为θ
′
,表示新参数在查询集上的损失的梯度,β表示外层元学习器的学习率,θ
*
表示经过更新后的参数;
[0046]
其中权重在各个内层模型之间共享,w
sprt
的初始值设置为0,开始训练元学习器,在训练收敛后测试元学习模型在测试任务集上的平均准确率;然后将w
sprt
的数值增加一个步长,再次重复上一步的训练和测试,得到新的平均准确率为一次循环,经过指定次数的循环之后,准确率指标不再上升后,此时模型最终设置整个过程中平均准确率最高时对应的w
sprt
作为元学习内层梯度改进时的支持集梯度权重。
[0047]
32)在元学习的内部层次给外部层次传递梯度时,不同的内部层次的文本分类任务难度和分布特征存在着差异,因此梯度的特征和重要程度应是不同的,而传统的元学习算法并未考虑到这一点,在训练过程中,往往个别较难或较特殊的任务偏离了其他任务,往往会使得模型错误的倾向于该个体任务。本发明对此做出了改进,在内部层次给外部层次传递梯度的时候,赋予各个内层任务回传的梯度以不同的权重计算出总的梯度回传给元学习器,元学习器根据此梯度和外层学习率来更新一次参数,循环此训练步骤,直至模型收敛,其公式如下:
[0048][0049]
式中表示各任务回传梯度的权重,对于每一批内层任务ti,其权重的计算公式如下:
[0050][0051]
式中表示元学习模型内部层次学习任务时回传的梯度,表示所有内层学习任务回传梯度之和,利用该式那些偏离适用元知识任务的特殊任务梯度的权重将会被减小,而靠近通用元知识的任务梯度将会被放大。
[0052]
以上所述仅是本发明的实施方式,再次声明,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以对本发明进行若干改进,这些改进也列入本发明权利要求的保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1