一种基于深度学习的高精度多角度行为识别方法
1.本发明属于人工智能技术领域,涉及数据处理、特征提取及动作分类,特别涉及一种基于深度学习的高精度多角度行为识别方法。
背景技术:
2.目前,人体行为识别是计算机视觉领域的研究热点之一,主要应用于视频监控、人机交互、医疗看护等多个领域。因此,对基于视频的动作识别方法进行分析研究有十分重要的意义。
3.最近几年人们对行为识别的研究,其主要都集中于特征的提取。行为是发生在一定时空的事件,特征不仅仅具有空间性,也具有时间性。如何有效描述时间空间特征是行为识别问题的关键。针对以上问题,行为识别方法目前已有多种解决方法。双流卷积模型考虑时间和空间两方面的特点,分别对其进行编码和融合;3d时空卷积方法在时间序列和空间序列上同时进行计算;也有改变特征的描述手段的方法,sift算法具有尺度不变性,可用于在图片中检测行为关键点;光流利用图像序列中像素在时间域上的变化以及相邻帧之间的相关性来找到上一帧跟当前帧之间存在的对应关系,从而计算出相邻帧之间物体的运动信息;还有将图使用到行为识别中的方法。这些方法在视频角度单一、背景较为简单的情况下获得了不错的精度,然而随着科学技术的进步,经济的发展,在实际生活中同一地点通常有着多台摄像机器多角度进行人体动作抓取,如何将收集到的多角度数据进行更好的融合成为亟待解决的问题。
技术实现要素:
4.为了克服上述现有技术的缺点,本发明的目的在于提供一种基于深度学习的高精度多角度行为识别方法,使用对比学习方法构建自监督模型对数据进行动作分类,有效增强数据特征提取的鲁棒性,学习到更有利于行为分类的知识,并满足了在实际场景下对视频数据中目标行为分类的高准确度需求,为后续依据分类结果进行的其他操作提供良好基础。
5.为了实现上述目的,本发明采用的技术方案是:
6.一种基于深度学习的高精度多角度行为识别方法,其特征在于,包括:
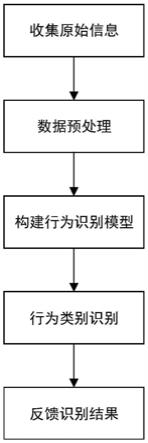
7.步骤1,以摄像设备作为边缘缓存节点,多台摄像设备同一时段从同一高度不同的水平角度收集同一行为的原始视频数据,并上传至服务器,对原始视频数据进行预处理,得到按时间顺序的图片帧;
8.步骤2,基于步骤1所得图片帧,应用对比学习思想搭建用于动作分类的卷积神经网络模型;
9.步骤3,使用训练好的卷积神经网络模型对预处理完的图片帧进行动作分类得到并反馈行为识别结果。
10.在一个实施例中,所述步骤1原始视频数据处理过程包括:首先,将视频按时间顺
序切割成图片帧;其次,对得到的图片帧进行区别性命名;最后,将不同角度的图片帧放在同一文件夹中,图片帧的时序顺序不变。
11.在一个实施例中,所述将不同角度的图片帧放在同一文件夹中是指:
12.以每个水平角度收集的原始视频数据得到的图片帧为一组,将每两组图片帧独立地放在一个文件夹中,每个文件夹中的每组图片帧中,图片帧的时序顺序不变。
13.在一个实施例中,所述对比学习思想,是在欧氏空间中将正样本距离拉近,将正样本与负样本距离拉远,在视频数据中,以同一时间不同角度的任意两个图片帧数据x1和x2为一对正样本,经过神经网络编码后提取出一对特征表示对,分别最小化其负余弦相似性以达到拉近正样本距离的目的。
14.在一个实施例中,所述卷积神经网络模型基于siamese network孪生神经网络框架进行搭建,包括输入层、隐藏层和输出层,所述输入层的输入为若干对所述的正样本,所述隐藏层分别对所述一对正样本进行编码,处理后由输出层输出数据。
15.在一个实施例中,所述隐藏层由编码函数f(
·
)和编码函数g(
·
)组成,编码函数f(
·
)包括一个主干网络和一个投影头,每一对所述的正样本在编码函数f(
·
)编码时共享权重,编码函数g(
·
)作为预测头;
16.编码函数f(
·
)的编码结果表示为:
[0017][0018]
编码函数g(
·
)的编码结果表示为:
[0019][0020]
其中,ω1和b1为编码函数f(
·
)的训练参数,ω2和b2为编码函数g(
·
)的训练参数。
[0021]
在一个实施例中,所述卷积神经网络模型的损失l的计算过程:
[0022]
最小化p1和z2的负余弦相似性:
[0023][0024]
最小化p2和z1的负余弦相似性:
[0025][0026]
d(p1,z2)为p1和z2间的欧式距离,d(p2,z1)为p2和z1间的欧式距离,||
·
||2是l2范数;
[0027]
整体损失定义为:
[0028][0029]
其中stopgrad(
·
)为停止梯度操作;
[0030]
最后利用深度神经网络进行迭代训练,得到使得损失函数最小的压缩自动编码器参数θ={w,b},其中b为偏置项,w为训练参数。
[0031]
与现有技术相比,本发明从多个设备上收集同一行为视频数据,对多个方位的数
据进行处理,高效地利用了多角度数据,针对多角度数据的特点,将对比学习方法引入行为识别模型,搭建的自监督模型在空间上更好地融合多角度数据特征,提取出与时间维度上互补的动作信息。
附图说明
[0032]
图1是本发明流程图。
具体实施方式
[0033]
下面结合附图和实施例详细说明本发明的实施方式。
[0034]
如图1所示,本发明为一种基于深度学习的高精度多角度行为识别方法,包括:
[0035]
步骤1,以摄像设备作为边缘缓存节点,多台摄像设备同一时段从同一高度的不同水平角度收集同一行为的原始视频数据,并上传至服务器,对原始视频数据进行预处理,得到按时间顺序的图片帧,以利于行为特征提取。
[0036]
在本发明中,多台摄像设备的垂直高度均相同,但水平角度不同,其原因在于,人在做动作的时候,多台水平角度不同的相机拍摄可以收集到动作的多个不同角度下的数据。目的在于模拟实际场景中摄像机收集的数据为不同角度下人体姿态的动作。以三台摄像设备为例,水平角度可分别设置为-45
°
、0
°
和45
°
。
[0037]
本发明的原始视频数据处理过程包括:首先,将视频按时间顺序切割成图片帧;其次,对得到的图片帧进行区别性命名;最后,将不同角度的图片帧放在同一文件夹中,图片帧的时序顺序不变。具体地,以每个水平角度收集的原始视频数据得到的图片帧为一组,将每两组图片帧独立地放在一个文件夹中,每个文件夹中的每组图片帧中,图片帧的时序顺序不变。
[0038]
例如,有两个不同的水平角度,对提取的n张图片帧以10001、10002、
……
、1000n和20001、20002、
……
2000n的方式命名,用以区分不同角度。
[0039]
再例如,有三个不同的水平角度,角度一获取的图片帧为(a1~a9),角度二获取的图片帧为(b1~b9);角度三获取的图片帧为(c1~c9)。则每两组图片帧放一个文件夹,一共放三个文件夹,文件夹一:[(a1~a9),(b1~b9)],文件夹二:[(b1~b9),(c1~c9)],文件夹三:[(a1~a9),(c1~c9)]。以文件夹一为例,在进行模型训练时,输入顺序为(a1~a9)~(b1~b9),也可(b1~b9)~(a1~a9)。
[0040]
步骤2,对于多角度这一特点进行针对性的模型构建,以此提高多角度数据的利用并获得行为识别的高精度结果。具体地,基于步骤1所得图片帧,本发明应用对比学习思想搭建用于动作分类的卷积神经网络模型。
[0041]
所谓对比学习思想,是在欧氏空间中将正样本距离拉近,将正样本与负样本距离拉远,本发明中,以同一时间不同角度的任意两个图片帧数据x1和x2为一对正样本,经过神经网络编码后提取出一对特征表示对,分别最小化其负余弦相似性以达到拉近正样本距离的目的。当有n个水平角度时,进行排列组合,以两个不同角度组成一组正样本。
[0042]
本发明卷积神经网络模型基于siamese network孪生神经网络框架进行搭建,包括输入层、隐藏层和输出层,输入层的输入即为若干对所述的正样本,每一对正样本从输入层的两个数据层输入,隐藏层分别对输入的每一对正样本进行编码,处理后由输出层输出
数据。
[0043]
示例地,隐藏层由编码函数f(
·
)和编码函数g(
·
)组成,编码函数f(
·
)包括一个主干网络和一个投影头,每一对所述的正样本在编码函数f(
·
)编码时共享权重,编码函数g(
·
)作为预测头;
[0044]
编码函数f(
·
)的编码结果表示为:
[0045][0046]
编码函数g(
·
)的编码结果表示为:
[0047][0048]
其中,ω1和b1为编码函数f(
·
)的训练参数,ω2和b2为编码函数g(
·
)的训练参数。
[0049]
本发明卷积神经网络参数值确定过程为:
[0050]
预训练卷积神经网络,从而确定参数的初始值,通过计算损失l来训练参数,损失l的计算过程:
[0051]
最小化p1和z2的负余弦相似性:
[0052][0053]
最小化p2和z1的负余弦相似性:
[0054][0055]
d(p1,z2)为p1和z2间的欧式距离,d(p2,z1)为p2和z1间的欧式距离,||
·
||2是l2范数;
[0056]
整体损失定义为:
[0057][0058]
其中stopgrad(
·
)为停止梯度操作;
[0059]
最后利用深度神经网络进行迭代训练,得到使得损失函数最小的压缩自动编码器参数θ={w,b},其中b为偏置项(偏置参数),w为训练参数(权重参数),即为前述参数(ω1和b1、ω2和b2)训练结束的最终值。当网络模型训练到收敛时,认为该神经网络能很好地提取输入数据的特征信息。
[0060]
步骤3,使用训练好的卷积神经网络模型,即可对预处理完的图片帧进行特征提取,提取完成后进一步进行动作分类,得到并反馈分类后的行为识别结果。
[0061]
在本发明的一个具体实施例中,采用ntu rgb+d行为识别数据集进行训练,ntu rgb+d是由南洋理工大学的rose lab实验室提出来的人体(骨架)行为识别数据集,该数据集包含56880个数据样本,一共60类动作,前面50类动作是单人动作,后面10类动作是双人交互动作,数据集样本文件格式如下::s001c003p008r002a058。其中:
[0062]
s:设置号,“ntu rgb+d”数据集包括设置号在s001和s017之间的文件/文件夹,而“ntu rgb+d 120”数据集包括设置号在s001和s032之间的文件/文件夹;
[0063]
c:相机id,共有三架;
[0064]
p:人物id,p001表示一号动作执行人,但并非每个人都执行了所有动作;
[0065]
r:同一个动作的表演次数;
[0066]
a:动作类别,a001到a060种动作类别。
[0067]
现有的行为识别方式为:对单一的原始视频数据进行预处理,通过训练深度神经网络提取图片帧时间或空间上的特征信息,利用特征信息进行有监督的行为分类。
[0068]
本发明识别方式为:利用多角度视频数据的多方位特点,将其与siamese network孪生神经网络框架相结合,在基于对比学习思想的基础上对多角度视频数据进行编码。通过对比学习的思想搭建自监督卷积神经网络模型,充分抓取数据的动作特征与时间序列提取的特征相互补,使得网络模型可以达到高精度高效率的行为识别。
[0069]
具体地,本发明选取ntu rgb+d行为识别数据集其中十种动作类别,数据集样本文件格式为:
[0070]
s001c001p001r001a001_rgb
[0071]
s001c001p001r001a007_rgb
[0072]
s001c001p001r001a013_rgb
[0073]
s001c001p001r001a019_rgb
[0074]
s001c001p001r001a025_rgb
[0075]
s001c001p001r001a031_rgb
[0076]
s001c001p001r001a037_rgb
[0077]
s001c001p001r001a043_rgb
[0078]
s001c001p001r001a049_rgb
[0079]
s001c001p001r001a055_rgb
[0080]
s001c002p001r001a001_rgb
[0081]
……
[0082]
将其c001、c002两台相机拍摄的数据中同一行为视为正样本,c001、c002为两台垂直高度均相同,但水平角度不同的相机,例如两台相机同时拍摄到的喝水动作s001c001p001r001a001_rgb和s001c002p001r001a001_rgb为一对正样本。并可设置另一相机用于测试,使用开源视频动作分析库mmaction中视频提取图片帧的方法对其进行数据处理,处理后每一种类动作分别放置在文件夹中,命名0,
……
,10。将处理好的数据作为卷积神经网络的输入,图片输入尺寸大小裁减为227
×
227输入,经过特征提取后大小输出为1*2048的特征向量。最后,将分类后的结果发送给后台管理员。表1为本发明与现有的2d卷积方法评价指标对比,可以看出本发明的评价指标远远优于2d卷积方法。
[0083]
表1本文方法与2d卷积方法在ntu-rgb+d数据集上各类评价指标的比较
[0084]
方法准确率精确率召回率f1值2d卷积7.4336.2262.9543.39本文方法15.4042.8670.0053.17
[0085]
综上,本发明使用对比学习方法构建自监督模型对数据进行动作分类,有效增强数据特征提取的鲁棒性,使模型学习到更有利于行为分类的知识,并满足了在实际场景下对视频数据中目标行为分类的高准确度需求,为后续依据分类结果进行的其他操作提供良
好基础。
[0086]
以上,对本发明的具体实施方式做了具体描述,但是不应该认定本发明的具体实施只局限于这些说明。对于本发明所属领域的普通技术人员来说,在不脱离本发明构思和由权利要求书所限定的保护范围的前提之下,还可以做出若干简单推演或替换,都应当视为属于本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1