一种基于步态关系网络的步态识别方法
1.本发明涉及一种步态识别方法,尤其是涉及一种基于步态关系网络的步态识别方 法。
背景技术:
2.步态识别技术是利用步态信息对人的身份进行识别的技术。与指纹、虹膜、人脸等 生物特征识别方法相比,基于视频的步态识别方法具有采集容易、距离远、非接触、难 以伪装和无需配合等优点。作为新一代生物特征识别技术,步态识别技术近些年受到了 广大专家学者越来越多的关注。随着计算机视觉和人工智能技术的快速发展,结合步态 识别技术的公共安防系统和智能视频分析系统,在保障社会公共安全、提高智慧城市的 科学化管理水平等方面存在广泛的技术需求,其发展也受到工业界的密切关注。
3.真实监控场景存在复杂多变的条件,对于步态特征的提取来说极具挑战性。步态识 别是对行人的步态序列进行识别,而步态序列由一系列的步态图像组成,步态序列的完 整性影响步态识别的准确性,把步态序列中缺失数据的情况称为步态的数据缺失,例如 步态图像是乱序的(即缺失序列内的时间信息)和步态图像数量非常少的。数据缺失是 步态识别在实际应用场景中面临的重要技术瓶颈,造成步态数据缺失的原因主要有:(1) 视角、携带物、服装等导致的行人自遮挡(该原因是造成行人步态建模数据缺失的最常 见原因);(2)由于场景中的对象遮挡,如实际监控中的行人之间、车辆、建筑物等的 遮挡,导致目标行人的短暂或完全丢失;(3)受复杂背景、光线、天气状况等影响导致 算法无法获得有效的源图像,如获取的行人轮廓信息模糊、包含较大噪声。
4.在现有步态识别方法的研究领域中,一些主流方法基于步态序列的顺序进行步态建 模,在这些方法内,有些方法认为认为短时间的躯干变化是步态应该关注的重点,如文 献gaitpart【fan c,peng y,cao c,et al.gaitpart:temporal part-based model for gaitrecognition[c]//proceedings of the ieee/cvf conference on computer vision and patternrecognition.2020:14225-14233.】利用微运动原理进行建模;有些方法认为长时间的依 赖关系是必不可少的,如文献gaitgl【lin b,zhang s,yu x,et al.learning effectiverepresentations from global and local features for cross-view gait recognition[j]. 2020.】利用3d卷积块来进行步态识别。上述这些方法在步态序列中图像数量较多,且 步态图像顺序未打乱情况下,具有较高的识别准确率;但是一旦步态序列中图像数量较 少或者步态图像顺序被打乱,其识别准确率将急剧下降。由此上述这些方法不适用于步 态图像缺失以及打乱导致的步态数据缺失的情况。针对步态数据缺失的问题,文献 gaitset【chao h,wang k,he y,et al.gaitset:cross-view gait recognition throughutilizing gait as a deep set[j].ieee transactions on pattern analysis and machineintelligence(tpami).2021.】中提出了深度集合的建模方法来解决此问题。但是,该深 度集合的建模方法采用了时间轴上的压缩操作,该操作易导致时间信息的丢失。总的来 说,目前的大多数方法对步态序列的连续性和步态序列中的
步态图像数量有着高要求,在步态图像顺序打乱情况下识别准确率低,同时也在步态图像数量较少时识别准确率低。
技术实现要素:
[0005]
本发明所要解决的技术问题是提供一种在步态图像顺序打乱情况下以及步态图像数量较少情况下,识别准确率仍然较高的基于步态关系网络的步态识别方法。
[0006]
本发明解决上述技术问题所采用的技术方案为:一种基于步态关系网络的步态识别方法,包括以下步骤:
[0007]
步骤1:从生物识别与安全技术研究中心(centerforbiometricsandsecurityresearch,简称cbsr)的步态数据集casia-b中获取一个步态数据集,该步态数据集包含124个行人身份在3个步行条件和11个视角下的步态图像,其中,124个行人身份采用数字001-124进行标记,3个步行条件为正常行走、背包行走和穿着外套或夹克行走,11个视角为0
°
、18
°
、36
°
、54
°
、72
°
、90
°
、108
°
、126
°
、144
°
、162
°
以及180
°
,该步态数据集中,每个行人身份下具有正常行走条件下的6个序列集、背包行走条件下的2个序列集以及着外套或夹克行走条件下的2个序列集,每个序列集中分别包括了11个步态图像序列,11个步态图像序列分别在11个视角下拍摄,11个视角与11个步态图像序列一一对应,每个步态图像序列分别由若干张步态图像构成;
[0008]
步骤2、通过文献【norikotakemura,yasushimakihara,daigomuramatsu,tomioechigo,andyasushiyagi.multi-viewlargepopu-lationgaitdatasetanditsperformanceevaluationforcross-viewgaitrecognition.ipsjtransactionsoncomputervisionandapplications,10,122018.1,2,6,7,8】提出的takemura方法对步态数据集中的每张步态图像分别进行处理,使每张步态图像高度为h且宽度为w,其中,h=64,w=44,此时得到训练数据集;
[0009]
步骤3:构建步态关系网络,所述的步态关系网络包括1个空间特征提取网络、16个时间特征提取网络和16个空间特征选择模块;所述的空间特征提取网络包括1个全局编码网络、1个图像切割网络、4个局部编码网络、1个融合编码网络和1个空间特征切割网络;所述的全局编码网络包括1个输入层、4个卷积层、1个最大池化层和2个输出层,所述的全局编码网络的第1个卷积层采用大小为5
×
5、补零参数的值为2、步长为1的32个卷积核实现,所述的全局编码网络的第2个卷积层采用大小为3
×
3、补零参数的值为1、步长为1的32个卷积核实现,所述的全局编码网络的第3个卷积层采用大小为3
×
3、补零参数的值为1、步长为1的64个卷积核实现,所述的全局编码网络的第4个卷积层采用大小为3
×
3、补零参数的值为1、步长为1的64个卷积核实现,所述的全局编码网络的最大池化层的步长设置为2;所述的图像切割网络包括1个输入层、1个切割层和4个输出层,每个所述的局部编码网络分别包括1个输入层、4个卷积层、1个最大池化层和2个输出层,每个所述的局部编码网络的第1个卷积层分别采用大小为5
×
5、补零参数的值为2、步长为1的32个卷积核实现,每个所述的局部编码网络的第2个卷积层分别采用大小为3
×
3、补零参数的值为1、步长为1的32个卷积核实现,每个所述的局部编码网络的第3个卷积层分别采用大小为3
×
3、补零参数的值为1、步长为1的64个卷积核实现,每个所述的局部编码网络的第4个卷积层分别采用大小为3
×
3、补零参数的值为1、步长为1的64个卷积核实现,每个所述的局部编码网
络的最大池化层的步长分别设置为2;所述的融合编码网络包括10个输入层、2个 特征拼接层、3个特征融合层、2个卷积层、1个最大池化层和1个输出层,所述的融合 编码网络的第1个卷积层采用大小为3
×
3、补零参数的值为1、步长为1的128个卷积 核实现,所述的融合编码网络的第2个卷积层采用大小为3
×
3、补零参数的值为1、步 长为1的128个卷积核实现,所述的融合编码网络的最大池化层的步长设置为2;所述 的空间特征切割网络包括1个输入层、1个切割层、1个池化层和1个输出层;每个所 述的时间特征提取网络分别包括1个输入层、3个映射层、1个时间特征选择层、1个独 立映射层和1个输出层,所述的时间特征提取网络的3个映射层和独立映射层分别为一 个输入通道数为128,输出通道数为128的全连接层,所述的时间特征提取网络的时间 特征选择层采用max函数实现;每个所述的空间特征选择网络分别包括1个输入层、1 个特征选择层、1个独立映射层和1个输出层,每个所述的空间特征选择网络的独立映 射层分别为一个输入通道数为128,输出通道数为128的全连接层;
[0010]
在对所述的步态关系网络进行训练时,所述的全局编码网络的输入层接入维度为 30
×1×
64
×
44的步态图像序列,其中,维度表示形式为图像数量
×
通道数
×
图像长度
×
图像 宽度,所述的全局编码网络的第1个卷积层接入所述的全局编码网络的输入层输出的维 度为30
×1×
64
×
44的步态图像序列,并进行特征提取,得到维度为30
×
32
×
64
×
44的特征 图f
global_1
输出,所述的全局编码网络的第2个卷积层接入所述的全局编码网络的第1个 卷积层输出的特征图f
global_1
,并进行特征提取,得到维度为32
×
64
×
44的特征图f
global_2
输出,所述的全局编码网络的最大池化层接入所述的全局编码网络的第2个卷积层输出 的特征图f
global_2
,并进行特征提取,得到维度为30
×
32
×
32
×
22的特征图f
global_pool
输出, 所述的全局编码网络的第3个卷积层接入所述的全局编码网络的最大池化层输出的特征 图f
global_pool
,并进行特征提取,得到维度为30
×
64
×
32
×
22的特征图f
global_3
输出,所述 的全局编码网络的第4个卷积层接入所述的全局编码网络的第3个卷积层输出的特征图 f
global_3
,并进行特征提取,得到维度为30
×
64
×
32
×
22的特征图f
global_4
输出,所述的全 局编码网络的第1个输出层接入所述的全局编码网络的最大池化层输出的特征图 f
global_pool
并输出,所述的全局编码网络的第2个输出层接入所述的全局编码网络的第4 个卷积层输出的特征图f
global_4
并输出;所述的图像切割网络的输入层接入维度为 30
×1×
64
×
44的步态图像序列并输出,所述的图像切割网络的切割层接入所述的图像切 割网络的输入层输出的维度为30
×1×
64
×
44的步态图像序列,并将该步态图像序列按长 度和宽度的中点进行切割,得到4个维度分别为30
×1×
32
×
22的步态图像子序列输出, 所述的图像切割网络的4个输出层一一对应接入所述的图像切割网络的切割层输出的4 个维度为30
×1×
32
×
22的步态图像子序列并输出;4个局部编码网络一一对应接入所述 的图像切割网络的4个输出层输出的4个维度为30
×1×
32
×
22的步态图像子序列,第n 个所述的局部编码网络的输入层接入所述的图像切割网络的第n个输出层输出的维度 为30
×1×
32
×
22的步态图像子序列并输出,n=1,2,3,4,第n个所述的局部编码网络 的第1个卷积层接入第n个所述的局部编码网络的输入层输出的维度为30
×1×
32
×
22的 步态图像子序列,并进行特征提取,得到维度为30
×
32
×
32
×
22的特征图输出,第n个 所述的局部编码网络的第2个卷积层接入第n个所述的局部编码网络的第1个卷积层输 出的特征图,并进行特征提取,得到维度为30
×
32
×
32
×
22的特征图输出,第n个所述 的局部编码网络的最大池化层接入第n个所
述的局部编码网络的第2个卷积层输出的特 征图,并进行特征提取,得到维度为30
×
32
×
16
×
11的特征图输出,第n个所述的局部 编码网络的第3个卷积层接入第n个所述的局部编码网络的最大池化层输出的特征图, 并进行特征提取,得到维度为30
×
64
×
16
×
11的特征图输出,第n个所述的局部编码网 络的第4个卷积层接入第n个所述的局部编码网络的第3个卷积层输出的特征图,并进 行特征提取,得到维度为30
×
64
×
16
×
11的特征图输出,第n个所述的局部编码网络的 第1个输出层用于接入第n个所述的局部编码网络的最大池化层输出的特征图,并将该 特征图输出,第n个所述的局部编码网络的第2个输出层用于接入第n个所述的局部 编码网络的第4个卷积层输出的特征图,并将该特征图输出;在4个局部编码网络中, 将第1个局部编码网络的第1个输出层输出的特征图和第2个输出层输出的特征图分别 记为f
local_pool,1
和f
local_4,1
,将第2个局部编码网络的第1个输出层输出的特征图和第2 个输出层输出的特征图分别记为f
local_pool,2
和f
local_4,2
,将第3个局部编码网络的第1个 输出层输出的特征图和第2个输出层输出的特征图分别记为f
local_pool,3
和f
local_4,3
,将第4 个局部编码网络的第1个输出层输出的特征图和第2个输出层输出的特征图分别记为 f
local_pool,4
和f
local_4,4
;所述的融合编码网络的10个输入层一一对应接入所述的全局编码 网络的第1个输出层输出的特征图f
global_pool
、所述的全局编码网络的第2个输出层输出 的特征图f
global_4
、4个所述的局部编码网络的第1个输出层和第2个输出层输出的特征 图f
local_pool,1
、特征图f
local_4,1
、特征图f
local_pool,2
、特征图f
local_4,2
、特征图f
local_pool,3
、特 征图f
local_4,3
、特征图f
local_pool,4
和特征图f
local_4,4
,并将接入的特征图输出,所述的融合 编码网络的第1个特征拼接层接入特征图f
local_pool,1
、特征图f
local_pool,2
、特征图f
local_pool,3
和特征图f
local_pool,4
并按之前对应的切割位置摆放后拼接,得到维度为30
×
32
×
32
×
22的 特征图f
local_pool,all
输出,所述的融合编码网络的第2个特征拼接层接入特征图f
local_4,1
、 f
local_4,2
、f
local_4,3
和f
local_4,4
,并按之前对应的切割位置摆放后拼接,得到维度为 30
×
64
×
32
×
22的特征图f
local_4,all
输出,所述的融合编码网络的第1个特征融合层接入特 征图f
local_pool,all
和特征图f
local_4,all
,并将特征图f
local_pool,all
和特征图f
local_4,all
进行维度拼 接,然后采用大小为1
×
1的卷积核进行特征融合,得到维度为30
×
64
×
32
×
22的特征图 f
local
输出,所述的融合编码网络的第2个特征融合层接入特征图f
global_pool
和特征图 f
global_4
,并将两者进行维度拼接,然后采用大小为1
×
1的卷积核进行特征融合,得到 维度为30
×
64
×
32
×
22的特征图f
global
输出,所述的融合编码网络的第3个特征融合层接 入所述的融合编码网络的第1个特征融合层输出的特征图f
local
和所述的融合编码网络 的第2个特征融合层输出的特征图f
global
,并将两者按像素位置一一对应相加,得到维 度为30
×
64
×
32
×
22的特征图f
fuse
输出,即f
fuse
=f
global
+f
local
,所述的融合编码网络的第 1个卷积层接入所述的融合编码网络的第3个特征融合层输出的特征图f
fuse
,并进行特 征提取,得到维度为30
×
128
×
32
×
22的特征图f
fuse_1
输出;所述的融合编码网络的第2 个卷积层接入所述的融合编码网络的第1个卷积层输出的特征图f
fuse_1
,并进行特征提 取,得到维度为30
×
128
×
32
×
22的特征图f
fuse_2
输出,所述的融合编码网络的最大池化 层接入所述的融合编码网络的第2个卷积层输出的特征图f
fuse_2
,并进行特征提取,得 到维度为30
×
128
×
16
×
11的空间特征图f输出,所述的融合编码网络的输出层接入所述 的融合编码网络的最大池化层输出的空间特征图f并输出;所述的空间特征切割网络的 输入层接入所述的融合编码网络的输出层输出的维度为30
×
128
×
16
×
11的空间特征图f 并输出,所述的空间特征切割网络的切割层
entropyloss(交叉熵损失);
[0012]
步骤5、当待识别行人需要进行步态识别时,将拍摄的该待识别行人的一个步态图像序列按照步骤2相同的方法进行处理,使该步态图像序列中每张步态图像的尺寸均为64
×
44(长度
×
宽度),然后将处理后的步态图像序列输入到训练好的步态关系网络中,得到该待识别行人的32张步态特征图输出;
[0013]
步骤6、对预先建立的已包括该待识别行人身份的步态数据库中的所有步态图像序列进行步骤5相同的操作,得到每个行人身份的32张步态特征图,然后,将步骤5得到的32特征图与此时得到的每个行人身份的32张步态特征图分别进行欧氏距离的计算,得到与步骤5得到的32特征图欧式距离最小的行人身份,该行人身份即为待识别行人的身份。
[0014]
与现有技术相比,本发明的优点在于通过构建步态关系网络,步态关系网络包括1个空间特征提取网络、16个时间特征提取网络和16个空间特征选择模块;空间特征提取网络包括1个全局编码网络、1个图像切割网络、4个局部编码网络、1个融合编码网络和1个空间特征切割网络;全局编码网络包括1个输入层、4个卷积层、1个最大池化层和2个输出层,全局编码网络的第1个卷积层采用大小为5
×
5、补零参数的值为2、步长为1的32个卷积核实现,全局编码网络的第2个卷积层采用大小为3
×
3、补零参数的值为1、步长为1的32个卷积核实现,全局编码网络的第3个卷积层采用大小为3
×
3、补零参数的值为1、步长为1的64个卷积核实现,全局编码网络的第4个卷积层采用大小为3
×
3、补零参数的值为1、步长为1的64个卷积核实现,全局编码网络的最大池化层的步长设置为2;图像切割网络包括1个输入层、1个切割层和4个输出层,每个局部编码网络分别包括1个输入层、4个卷积层、1个最大池化层和2个输出层,每个局部编码网络的第1个卷积层分别采用大小为5
×
5、补零参数的值为2、步长为1的32个卷积核实现,每个局部编码网络的第2个卷积层分别采用大小为3
×
3、补零参数的值为1、步长为1的32个卷积核实现,每个局部编码网络的第3个卷积层分别采用大小为3
×
3、补零参数的值为1、步长为1的64个卷积核实现,每个局部编码网络的第4个卷积层分别采用大小为3
×
3、补零参数的值为1、步长为1的64个卷积核实现,每个局部编码网络的最大池化层的步长分别设置为2;融合编码网络包括10个输入层、2个特征拼接层、3个特征融合层、2个卷积层、1个最大池化层和1个输出层,融合编码网络的第1个卷积层采用大小为3
×
3、补零参数的值为1、步长为1的128个卷积核实现,融合编码网络的第2个卷积层采用大小为3
×
3、补零参数的值为1、步长为1的128个卷积核实现,融合编码网络的最大池化层的步长设置为2;空间特征切割网络包括1个输入层、1个切割层、1个池化层和1个输出层;每个时间特征提取网络分别包括1个输入层、3个映射层、1个时间特征选择层、1个独立映射层和1个输出层,时间特征提取网络的3个映射层和独立映射层分别为一个输入通道数为128,输出通道数为128的全连接层,时间特征提取网络的时间特征选择层采用max函数实现;每个空间特征选择网络分别包括1个输入层、1个特征选择层、1个独立映射层和1个输出层,每个空间特征选择网络的独立映射层分别为一个输入通道数为128,输出通道数为128的全连接层,在采用步态关系网络来获取行人的步态特征图时,能充分利用各种步态条件的步态图像数据,增加识别精度,对待识别步态图像序列中的步态图像的数量,顺序无要求,由此在步态数据缺失的情况下,识别精度仍然较高,鲁棒性强,具有优异的性能。
具体实施方式
[0015]
以下结合实施例对本发明作进一步详细描述。
[0016]
实施例:一种基于步态关系网络的步态识别方法,包括以下步骤:
[0017]
步骤1:从生物识别与安全技术研究中心(centerforbiometricsandsecurityresearch,简称cbsr)的步态数据集casia-b中获取一个步态数据集,该步态数据集包含124个行人身份在3个步行条件和11个视角下的步态图像,其中,124个行人身份采用数字001-124进行标记,3个步行条件为正常行走(nm)、背包行走(bg)和穿着外套或夹克(cl)行走,11个视角为0
°
、18
°
、36
°
、54
°
、72
°
、90
°
、108
°
、126
°
、144
°
、162
°
以及180
°
,该步态数据集中,每个行人身份下具有正常行走条件下的6个序列集、背包行走条件下的2个序列集以及着外套或夹克行走条件下的2个序列集,每个序列集中分别包括了11个步态图像序列,11个步态图像序列分别在11个视角下拍摄,11个视角与11个步态图像序列一一对应,每个步态图像序列分别由若干张步态图像构成;
[0018]
步骤2、通过文献【norikotakemura,yasushimakihara,daigomuramatsu,tomioechigo,andyasushiyagi.multi-viewlargepopu-lationgaitdatasetanditsperformanceevaluationforcross-viewgaitrecognition.ipsjtransactionsoncomputervisionandapplications,10,122018.1,2,6,7,8】提出的takemura方法对步态数据集中的每张步态图像分别进行处理,使每张步态图像高度为h且宽度为w,其中,h=64,w=44,此时得到训练数据集;
[0019]
步骤3:构建步态关系网络,步态关系网络包括1个空间特征提取网络、16个时间特征提取网络和16个空间特征选择模块;空间特征提取网络包括1个全局编码网络、1个图像切割网络、4个局部编码网络、1个融合编码网络和1个空间特征切割网络;全局编码网络包括1个输入层、4个卷积层、1个最大池化层和2个输出层,全局编码网络的第1个卷积层采用大小为5
×
5、补零参数的值为2、步长为1的32个卷积核实现,全局编码网络的第2个卷积层采用大小为3
×
3、补零参数的值为1、步长为1的32个卷积核实现,全局编码网络的第3个卷积层采用大小为3
×
3、补零参数的值为1、步长为1的64个卷积核实现,全局编码网络的第4个卷积层采用大小为3
×
3、补零参数的值为1、步长为1的64个卷积核实现,全局编码网络的最大池化层的步长设置为2;图像切割网络包括1个输入层、1个切割层和4个输出层,每个局部编码网络分别包括1个输入层、4个卷积层、1个最大池化层和2个输出层,每个局部编码网络的第1个卷积层分别采用大小为5
×
5、补零参数的值为2、步长为1的32个卷积核实现,每个局部编码网络的第2个卷积层分别采用大小为3
×
3、补零参数的值为1、步长为1的32个卷积核实现,每个局部编码网络的第3个卷积层分别采用大小为3
×
3、补零参数的值为1、步长为1的64个卷积核实现,每个局部编码网络的第4个卷积层分别采用大小为3
×
3、补零参数的值为1、步长为1的64个卷积核实现,每个局部编码网络的最大池化层的步长分别设置为2;融合编码网络包括10个输入层、2个特征拼接层、3个特征融合层、2个卷积层、1个最大池化层和1个输出层,融合编码网络的第1个卷积层采用大小为3
×
3、补零参数的值为1、步长为1的128个卷积核实现,融合编码网络的第2个卷积层采用大小为3
×
3、补零参数的值为1、步长为1的128个卷积核实现,融合编码网络的最大池化层的步长设置为2;空间特征切割网络包括1个输入层、1个切割层、1个池化层和1个输出层;每个时间特征提取网络分别包括1个输入层、3个映射层、1个时间特征选择层、1个独立映射层和1个输
输出层输出的特征图分别记为f
local_pool,2
和f
local_4,2
,将第3个局部编码网络的第1个输 出层输出的特征图和第2个输出层输出的特征图分别记为f
local_pool,3
和f
local_4,3
,将第4 个局部编码网络的第1个输出层输出的特征图和第2个输出层输出的特征图分别记为 f
local_pool,4
和f
local_4,4
;融合编码网络的10个输入层一一对应接入全局编码网络的第1个 输出层输出的特征图f
global_pool
、全局编码网络的第2个输出层输出的特征图f
global_4
、4 个局部编码网络的第1个输出层和第2个输出层输出的特征图f
local_pool,1
、特征图 f
local_4,1
、特征图f
local_pool,2
、特征图f
local_4,2
、特征图f
local_pool,3
、特征图f
local_4,3
、特征图 f
local_pool,4
和特征图f
local_4,4
,并将接入的特征图输出,融合编码网络的第1个特征拼接 层接入特征图f
local_pool,1
、特征图f
local_pool,2
、特征图f
local_pool,3
和特征图f
local_pool,4
并按之 前对应的切割位置摆放后拼接,得到维度为30
×
32
×
32
×
22的特征图f
local_pool,all
输出,融 合编码网络的第2个特征拼接层接入特征图f
local_4,1
、f
local_4,2
、f
local_4,3
和f
local_4,4
,并按 之前对应的切割位置摆放后拼接,得到维度为30
×
64
×
32
×
22的特征图f
local_4,all
输出,融 合编码网络的第1个特征融合层接入特征图f
local_pool,all
和特征图f
local_4,all
,并将特征图 f
local_pool,all
和特征图f
local_4,all
进行维度拼接,然后采用大小为1
×
1的卷积核进行特征融 合,得到维度为30
×
64
×
32
×
22的特征图f
local
输出,融合编码网络的第2个特征融合层接 入特征图f
global_pool
和特征图f
global_4
,并将两者进行维度拼接,然后采用大小为1
×
1的 卷积核进行特征融合,得到维度为30
×
64
×
32
×
22的特征图f
global
输出,融合编码网络的 第3个特征融合层接入融合编码网络的第1个特征融合层输出的特征图f
local
和融合编码 网络的第2个特征融合层输出的特征图f
global
,并将两者按像素位置一一对应相加,得 到维度为30
×
64
×
32
×
22的特征图f
fuse
输出,即f
fuse
=f
global
+f
local
,融合编码网络的第1 个卷积层接入融合编码网络的第3个特征融合层输出的特征图f
fuse
,并进行特征提取, 得到维度为30
×
128
×
32
×
22的特征图f
fuse_1
输出;融合编码网络的第2个卷积层接入融合 编码网络的第1个卷积层输出的特征图f
fuse_1
,并进行特征提取,得到维度为 30
×
128
×
32
×
22的特征图f
fuse_2
输出,融合编码网络的最大池化层接入融合编码网络的第 2个卷积层输出的特征图f
fuse_2
,并进行特征提取,得到维度为30
×
128
×
16
×
11的空间特 征图f输出,融合编码网络的输出层接入融合编码网络的最大池化层输出的空间特征图 f并输出;空间特征切割网络的输入层接入融合编码网络的输出层输出的维度为 30
×
128
×
16
×
11的空间特征图f并输出,空间特征切割网络的切割层接入空间特征切割 网络的输入层输出的空间特征图f,并按照长度和宽度方向16等分进行切割,得到16 个维度为30
×
128
×1×
11的特征图输出,将此时输出的第i个维度为30
×
128
×1×
11的特征 图记为fi,i=1,2,3,
…
,16,空间特征切割网络的池化层接入空间特征切割网络的切割 层输出的16个维度为30
×
128
×1×
11的特征图,并分别进行特征提取,得到16个维度为 30
×
128
×1×
1的特征图输出,将对第i个维度为30
×
128
×1×
11的特征图进行特征提取后 得到的特征图fi;16个时间特征提取网络一一对应接入空间特征切割网络的池化层输出 的16个维度为30
×
128
×1×
1的特征图,其中第i个时间特征提取网络的输入层接入空间 特征切割网络的池化层输出的第i个维度30
×
128
×1×
1的特征图fi并输出,第i个时间特 征提取网络的第1个映射层接入第i个时间特征提取网络的输入层输出的特征图fi,并 进行特征提取,得到维度为30
×
128
×1×
1的特征图ai输出,第i个时间特征提取网络的 第2个映射层接入第i个时间特征提取网络的第1个映射层输出的特征图ai,先进行特 征提取,得到维度为30
×
128
×1×
1的特征图bi,然后将特征图ai
的所有维度与特征图bi按照对应的维度进行相减操作,得到维度为900
×
128
×1×
1的特征图ci输出,第i个时间特征提取网络的第3个映射层接入第i个时间特征提取网络的第2个映射层输出的特征图ci,然后进行特征提取,得到维度为900
×
128
×1×
1的特征图di输出,第i个时间特征提取网络的时间特征选择层接入第i个时间特征提取网络的第3个映射层输出的特征图di,并进行特征提取,得到维度为1
×
128
×1×
1的特征图ei输出,第i个时间特征提取网络的独立映射层接入第i个时间特征提取网络的时间特征选择层输出的特征图ei,并进行特征提取,得到维度为1
×
128
×1×
1的特征图vi输出;16个空间特征选择网络一一对应接入空间特征切割网络的池化层输出的16个维度为30
×
128
×1×
1的特征图,其中第i个空间特征选择网络的输入层接入空间特征切割网络的池化层输出的第i个维度30
×
128
×1×
1的特征图fi并输出,第i个空间特征选择网络的特征选择层接入第i个空间特征选择网络的输入层输出的特征图fi并进行特征提取,得到维度为1
×
128
×1×
1的特征图ai输出,第i个空间特征选择网络的独立映射层接入第i个空间特征选择网络的特征选择层输出的特征图ai,并进行特征提取,得到维度为1
×
128
×1×
1的特征图si输出;特征图vi和特征图si即步态关系网络输出的步态特征图;
[0021]
步骤4、对构建的步态关系网络进行训练,具体为:首先将步骤2得到的训练数据集划分为训练集和测试集其中,74个行人身份下的数据作为训练集,剩下50个行人身份下的数据作为测试集,在每次训练时,随机从训练集中选择42个步态图像序列,然后在每个步态图像序列中随机选择30张步态图像作为步态关系网络的输入,如果某个步态图像序列中步态图像数量不足30,则随机重复选择,直至得到30张步态图像,在每次训练过程中,利用损失函数对步态关系网络参数进行优化,直至迭代训练达到200000次,得到训练完成的步态关系网络,其中,损失函数设置为文献【a.hermans,l.beyer,b.leibe,indefenseofthetripletlossforpersonre-identification,corrabs/1703.07737(2017).】中公开了的batchall(ba+)tripletloss和文献【haoluo,youzhigu,xingyuliao,shenqilai,andweijiang.bagoftricksandastrongbaselinefordeeppersonre-identification.incvprworkshops,june2019.2,3】中公开了cross-entropyloss(交叉熵损失);
[0022]
步骤5、当待识别行人需要进行步态识别时,将拍摄的该待识别行人的一个步态图像序列按照步骤2相同的方法进行处理,使该步态图像序列中每张步态图像的尺寸均为64
×
44(长度
×
宽度),然后将处理后的步态图像序列输入到训练好的步态关系网络中,得到该待识别行人的32张步态特征图输出;
[0023]
步骤6、对预先建立的已包括该待识别行人身份的步态数据库中的所有步态图像序列进行步骤5相同的操作,得到每个行人身份的32张步态特征图,然后,将步骤5得到的32特征图与此时得到的每个行人身份的32张步态特征图分别进行欧氏距离的计算,得到与步骤5得到的32特征图欧式距离最小的行人身份,该行人身份即为待识别行人的身份。
[0024]
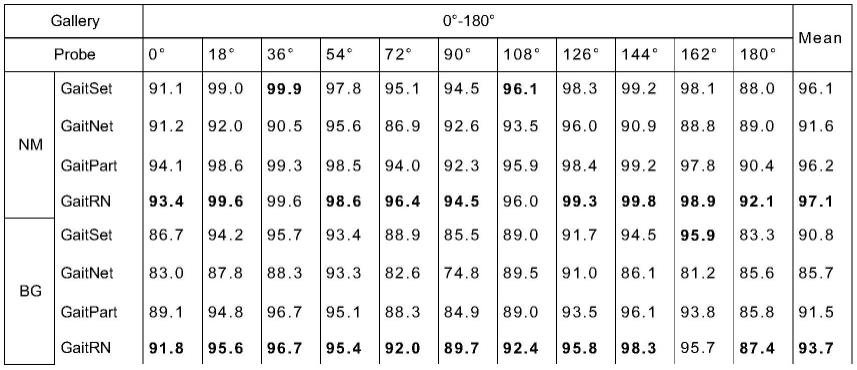
为了评价本发明的基于步态关系网络的步态识别方法中的步态关系网络的有效性,将本发明的步态关系网络(简称gaitrn)与其他几个现有的识别模型进行了比较。具体识别对比数据如表1所示:
[0025]
表1
[0026][0027][0028]
分析表1数据我们可以知道:本发明的步态关系网络在lt的训练条件下,在nm、 bg和cl条件下,在casia-b数据集上的平均rank-1准确率分别为97.1%、93.7%和79.1%。 与最近的方法gaitpart进行了比较,同样是对时空特征提取方法的改进,本发明的步态 关系网络在精度分别提高了0.9%,2.2%和0.4%,识别进度显著提高。
[0029]
对本发明的基于步态关系网络的步态识别方法的实用性进行如下分析:在真实场景 下,由于遮挡等原因,获得的步态图像可能出现以下几种情况:1)步态图像的顺序是 打乱的;2)步态图像数量是受限制的;3)步态图像可能来自于同一行走条件且视角相 同的不同步态图像序列;4)步态图像可能来自于不同行走条件且不同视角下的步态图 像序列。以下基于casia-b数据集,通过实验测试了在这些情况下本发明的步态关系网 络的识别准确率:
[0030]
1)真实场景下,可能会出现获得的步态图像顺序不确定的情况,于是我们将测试 的步态图像数据集中步态图像顺序打乱以达到模拟这种情况,本发明的步态关系网络及 现有的几种步态识别模型在步态图像打乱和不打乱顺序情况下的准确性如表2所示:
[0031]
表2
[0032][0033]
分析表2数据可知:本发明的步态关系网络在打乱步态图像顺序的情况下和不打乱 步态图像顺序情况下的测试结果一致,说明本发明的步态关系网络成功抵抗了步态图
可组成到一个步态周期,步态存在特殊的周期性,不同步态图像序列的图像可以补充步 态周期内的数据;二、本发明可以充分利用相同视角和行走条件下多个步态图像序列中 的步态图像,对图像图像序列的连续性和完整性无要求。
[0042]
4)在现实生活中,步态图像很可能是在不同角度,不同步态图像序列和不同行走 条件下获得的。为了模拟这种情况,我们重新生成待预测样本,将不同步态图像序列, 不同视角和不同行走条件的步态图像进行组合。从待预测样本中随机取20帧步态图像作 为最终测试的样本,取50次实验结果的平均值作为测试结果,测试结果如表5所示:
[0043]
表5
[0044][0045]
分析表5可知:实验表明,在包含多视角和多行走状态的待预测步态数据集合中, 本发明准确率也能达到97.6%,高于gaitset模型3.4%,在只有bg和cl条件下步态图像 数据的情况下,准确率超过gaitset模型5.6%。同时,我们发现多视角的情况下的准确率 显著高于单视角情况下的准确率,说明本发明充分利用多视角的步态图像;在只有cl 条件下步态数据集中加入bg或nm条件下步态图像数据,准确率提升,说明本发明可以 利用多种行走条件下的步态图像。由此说明了本发明可以充分利用步态图像数据,在有 约束的现实情况下,仍然具有较强鲁棒性。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1