一种基于逆透视变换和点云投影的鸟瞰图语义分割标签生成方法与流程
1.本发明涉及汽车自动驾驶环绕感知技术领域,具体涉及基于逆透视变换和点云投影的鸟瞰图语义分割标签生成方法。
背景技术:
2.自动驾驶系统是当前智能汽车的核心系统之一,其主要由三个大的模块组成,即感知融合模块、决策规划模块、控制模块,其中,感知融合作为另外两个模块的前置模块,其感知的精度将直接决定整个自动驾驶系统的性能。
3.当前不少自动驾驶公司开始将注意力放在环绕感知上,具体而言,就是将多个相机分布在车身的四周,如图1所示,为最常见的布置,这六个相机分别采集不同视角的图像信息,然后将图像信息送入感知模型中直接输出鸟瞰图(bev:bird eyes view)语义信息,该鸟瞰图是相对于本车而言,从本车正上方俯视得到的图,鸟瞰图语义信息指的是鸟瞰图的语义分割,其中主要包含四类:行人、车辆、可行驶区域、车道线。
4.为了训练这样的鸟瞰图语义分割模型,需要获取相应的鸟瞰图语义分割标签(以下简称bev标签)。当前业内获取bev标签主要采用了两种方式:
5.第一种方式:离线生成高精地图,然后通过高精地图的语义信息元素生成对应的bev标签。这种方式有两个个不足,其一为bev标签容易受到高精地图精度影响,其二为高精地图获取成本较高,周期较长,而且高精地图的地理范围有限,制约了数据的多样性。
6.第二种方式:通过无人机同步航拍鸟瞰图,然后人工对鸟瞰图进行标注。这种方式最大的不足就是,数据采集车无法在无人机受到管制的禁飞区域进行数据采集,这样数据采集的范围就会受到限制,从而场景多样性受到限制,同时这种采集模型,没办法通过影子模式进行自动采集,影响了模型的迭代更新。
技术实现要素:
7.本发明的目的是提供一种基于逆透视变换和点云投影的鸟瞰图语义分割标签生成方法,解决的技术问题:当前业内获取bev标签主要有两种方式,其一,离线生成高精地图,然后通过高精地图的语义信息元素生成对应的bev标签,该种方式存在两个缺陷,第一,bev标签容易受到高精地图精度影响,第二,高精地图获取成本较高,周期较长,且高精地图的地理范围有限,制约数据多样性。
8.其二,通过无人机同步航拍鸟瞰图,然后人工对鸟瞰图进行标注。这种方式的缺陷是数据采集车无法在无人机受到管制的禁飞区域进行数据采集,数据采集的范围就会受到限制,从而场景多样性受到限制,同时这种采集模型没办法通过影子模式进行自动采集,影响模型的迭代更新。
9.为解决上述技术问题,本发明采用的技术方案为:一种基于逆透视变换和点云投影的鸟瞰图语义分割标签生成方法,包括以下步骤:
10.s01:数据采集,利用同步信号同步同一时刻的相机和激光雷达数据,且每个时刻所有相机和激光雷达传感器数据的时间戳相差不超过设定值;
11.s02:数据标注,同一时刻的m张图像和n个点云数据联合标注,图像上面标出路面的静态区域,点云标注出动态物体3d包围盒;
12.s03:逆透视变换生成bev标签的路面区域,基于仿射几何的逆透视变换,将各个相机视角的路面的语义分割标签透视到bev画布上面并进行拼接,并对拼接后的图片进行精细化处理;
13.s04:点云投影生成bev标签动目标,通过刚体变换将点云转换到车身坐标系下,然后通过点投影变换将3d包围盒投影到bev画布上面;
14.s05:合并路面和动目标:将s03和s04生成的语义分割标签进行融合,获得完整的高精度bev标签。
15.优选地,
16.s01还包括传感器配置和标定,所述传感器为相机和激光雷达,布置在数据采集车上;所述标定是利用相机标定板标定出每个相机相对于车身的外参和自身的内参,利用相机和激光雷达联合标定法标定出激光雷达相对于车身的外参。
17.优选地,
18.所述相机分布在车身四周,每个相机的视角有部分重叠在一起;激光雷达搭载于车身顶部,水平fov为360度,竖直fov为-20度到20度;外参为相机相对于车身的偏航角yaw、俯仰角pitch、翻转角roll、平移距离tx、平移距离ty、平移距离tz;内参为相机的x方向和y方向的像素尺度f
x
、fy和像素中心p
x
、py;从车身坐标系到相机像素坐标系的投影换矩阵通过外参和内参求出,变换推导公式为:
[0019][0020][0021][0022]
r=r
yawrpitchrroll
,
[0023][0024][0025][0026][0027]
其中,r为刚体旋转矩阵,旋转方向为从车身坐标系到相机坐标系,t为平移矩阵,平移方向从车身坐标系到相机坐标系;k为相机内参构成的内参矩阵,其中r、t、k三者共同构成3x4的投影矩阵p,矩阵将车身坐标系下的某一点的齐次坐标投影为相机像素平面的像素坐标,zc为此点在相机坐标系下的深度。
[0028]
优选地,
[0029]
在所述s02中,对同一时刻的6张图像和1个点云数据联合标注,其中,图像上面只标识路面区域,包括可行驶区域和路面车道线;点云上标示出动目标的行人和车辆。
[0030]
优选地,
[0031]
相机图像上路面区域的一点(u,v),其对应的车身坐标系的路面点为其中下标r表示road,zr为0。画布的像素坐标系(ur,vr)和车身坐标系路面点
的关系为:
[0032][0033][0034]
其中,w
target
、h
target
为bev画布的宽度和高度,ppx
target
、ppy
target
为bev画布在宽度方向和高度方向上每米对应的像素个数。
[0035]
相机路面点像素坐标和bev路面点像素坐标的关系:
[0036][0037]
pm为3x3方阵且可逆,故得到
[0038][0039]
其中p∈{p1,p2,p3,p4,p5,p6},即为6个环绕相机的投影矩阵,其中p和m矩阵均为已知量,(u,v)为相机原图上给定的路面像素坐标点,其对应的bev画布上的投影像素点齐次
坐标像素坐标为:
[0040][0041][0042]
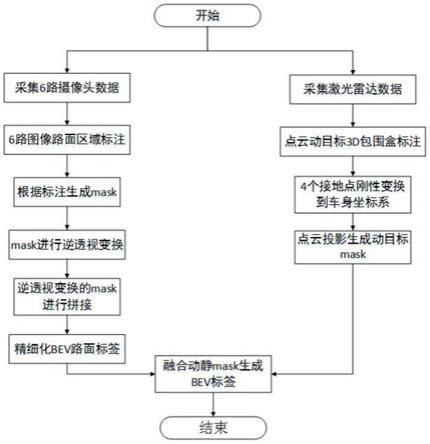
优选地,
[0043]
在所述s04中,通过刚体变换将每个动目标的标注好的3d包围盒的4个接地点的坐标转换到车身坐标系下,转换按照以下公式进行:
[0044][0045]
此公式将激光雷达坐标系的每个动目标的包围盒4个接地点转化到车
[0046]
身坐标系下的4个接地点,将4个接地点投影到bev图,并在图上生
[0047]
成包围矩阵,进而生成动目标在bev画布上的标签。
[0048]
优选地,
[0049]
将生成的路面静态bev图和生成的动目标图进行叠加融合,生成包括可行驶区域、车道线、车辆、行人属性的bev标签图。
[0050]
通过采用上述技术方案,本发明可达到的有益技术效果陈述如下:本发明参考了高精地图生成方式,本发明不是着眼于高精地图的生成,而是着眼于一套低成本的bev标签自动生成算法,设计了一套降低成本的bev标签自动生成算法流程,免去了无人机和高精地图的繁琐,直接从原始图像和点云得到精度较高的bev标签,具体地,本发明直接从某一时刻同步的原图和点云生成精确的鸟瞰图语义分割标签,从而避免了通过无人机航拍路面的方式获取鸟瞰图和进行标注,极大降低了数据标签的成本,同时
[0051]
拓展了可采集数据场景(无人机被管制的场景)。
附图说明
[0052]
图1为数据采集车传感器配置示意图;
[0053]
图2为标注示例图(a原始图片);
[0054]
图3为标注示例图(b原始图片的标签生成的mask);
[0055]
图4为逆透视变换生成bev标签示意图;
[0056]
图5为点云投影生成bev标签示意图(a行人的bev投影图);
[0057]
图6为点云投影生成bev标签示意图(b车辆的bev投影图);
[0058]
图7为生成的bev标签示意图;
[0059]
图8为整个bev标签自动生成算法流程图。
具体实施方式
[0060]
下面结合附图对本发明作进一步说明。
[0061]
本发明所述的一种基于逆透视变换和点云投影生成鸟瞰图语义分割标签的方法,具体实施步骤如下:
[0062]
第一步,配置数据采集车:如图1所示,配置数据采集车,其中为了进行环绕感知,将6个200万像素的摄像头分布在了车身的四周,并且每个摄像头的视角有部分是重叠在一起的,这样保证能够360度无死角的进行环境感知。对于激光雷达(lidar),其搭载在了车身的顶部,水平fov为360度,竖直fov约为-20度到20度。
[0063]
第二步,传感器标定:利用相机标定板标定出每个相机相对于车身(ego vehicle)的外参(extrinsic)和自身的内参(intrinsic),其中的外参指的是相机相对于车身的偏航角yaw、俯仰角pitch、翻转角roll、平移距离tx、平移距离ty、平移距离tz,内参指相机的x方向和y方向的像素尺度f
x
、fy和像素中心p
x
、py,然后利用标注好的相机和lidar进行联合标定,标定出lidar相对车身的外参,从车身坐标系到摄像头像素坐标系的投影换矩阵可以通过外参和内参求出,具体变换推导如公式(1)-(8)。
[0064][0065][0066][0067]
r=r
yawrpitchrroll
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4)
[0068][0069]
[0070][0071][0072][0073]
其中r为刚体旋转矩阵,旋转方向为从车身坐标系到相机坐标系,而t为平移矩阵,平移方向也是从车身坐标系到相机坐标系,k为相机内参构成的内参矩阵,由式子(6)和(8)可以推导出式(9),其中r、t、k三者共同构成了一个3x4的投影矩阵p,此矩阵将车身坐标系下的某一点的齐次坐标投影为相机像素平面的像素坐标,其中zc为此点在相机坐标系下的深度。
[0074]
对于lidar,同理可得其从车身坐标系到自身坐标系的变换满足式子(6),由于lidar没有内参,因此只考虑外参矩阵r、t。在后面的讨论中,设第i个相机的投影矩阵为pi,lidar的外参矩阵为r
lidar
、t
lidar
。
[0075]
第三步,数据采集:数据采集过程中,最为重要的就是所有6路摄像头和激光雷达之前的同步。本专利的同步方式为lidar每扫过一路相机,此相机触发曝光,因此当lidar扫满360度,所有相机均曝光一次。lidar的扫描频率为20hz,因此lidar转动一圈需要约50ms,故6路相机同步最大时差为(50/6)x5=41.6ms,满足小于45ms的需求。
[0076]
第四步,数据标注:对同一个时刻的6张图像和1个点云数据联合标注,其中图像上面只标识路面区域,包括可行驶区域和路面车道线,而点云上标示出动目标的行人和车辆,标注示例参考图2和图3。
[0077]
第五步,逆透视变换生成bev标签的路面区域和标签精细化:对于摄像头图像上路面区域的一点(u,v),其对应的车身坐标系的路面点为其中下标r表示road。由于路面区域相对于车身的高度为0,因此zr=0。如图4所示,根据画布的坐标系设置,可以
得出画布的像素坐标系(ur,vr)和车身坐标系路面点的关系为:
[0078][0079][0080]
这里w
target
、h
target
分别表示bev画布的宽度和高度,ppx
target
、ppy
target
表示bev画布在宽度方向(x方向)和高度方向(y方向)上每米对应的像素个数。
[0081]
联立式(9)和式(10),可以得到相机路面点像素坐标和bev路面点像素坐标的关系:
[0082][0083]
由于p为3x4矩阵,而m为4x3矩阵,因此pm为3x3方阵且可逆,故可以得到
[0084][0085]
其中p∈{p1,p2,p3,p4,p5,p6},即为6个环绕相机的投影矩阵。此公式即为逆透视变换公式,其中p和m矩阵均为已知量,(u,v)为相机原图上给定的路面像素坐标点,故可以反
求出其对应的bev画布上的投影像素点齐次坐标由此可以得出像素坐标为:
[0086][0087][0088]
首先对6个环绕相机拍摄的原图进行了路面区域标注,其中标注了车道线和可行驶区域,并生成了如图4所示的掩码标签。然后利用公式(12)-(14),将每个视角的掩码标签投影到了同一张bev画布上面。如图3所示,每个视角的掩码标签在bev画布上面依次拼接起来,生成了一个全息的bev投影图。由于摄像头存在抖动,同时车身本身也有震动,因此摄像头外参会有变动,导致拼接出的bev投影图会存在错位,因此需要通过人工进行修补,修补后的bev路面标签如图4所示。
[0089]
如图5和图6所示,第六步,点云投影生成bev标签动目标:对于动目标,通过刚体变换将每个动目标的标注好的3d包围盒的4个接地点的坐标转换到车身坐标系下,转换按照公式(15)进行:
[0090][0091]
此公式将lidar坐标系的每个动目标的包围盒4个接地点转化到了车身坐标系下的4个接地点,然后将这4个接地点投影到bev图,并在图上生成包围矩阵,从而生成了动目标在bev画布上的标签。
[0092]
第七步,合并路面和动目标:将第五步生成的路面静态bev图和第六步生成的动目标图进行简单的叠加融合,从而生成了包含可行驶区域、车道线、车辆、行人这4种属性的bev标签图,如图7所示;整个bev标签生成流程如图8,即采集6路相机(摄像头)数据,6路图像路面区域标注,根据标注生成mask,mask进行逆透视变换,逆透视变换的mask进行拼接,精细化bev路面标签,采集激光雷达数据,点云动目标3d包围盒标注,4个接地点刚性变换到车身坐标系,点云投影生成动目标mask,融合动静mask生成bev标签。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1