一种基于无监督学习的中文地址分词方法及系统与流程
1.本技术涉及地址分词技术领域,尤其涉及一种基于无监督学习的中文地址分词方法及系统。
背景技术:
2.随着智慧城市建设和社会治理水平的提高,地址已成为众多领域开展业务的重要支撑数据,例如地图导航、物流配送等。因此,地址分词的结果对于地址能否有效且准确地使用起着越来越重要的作用。
3.中文地址文本分词本质上是中文分词在地址处理领域中的应用。与英文地址不同的是,中文地址大都不具有自然分割标记;而且,中文地址文本又比普通中文文本具有更加独特的分词特征,分词逻辑更加复杂。因此,如何准确且高效地实现中文地址分词,是现阶段实际应用过程中的重难点。
4.目前,常用的中文地址分词方法是通过人工构建地址词典,利用规则基于字符串匹配实现地址分词;或者通过标注大量的地址数据训练地址分词模型,利用训练好的分词模型对待处理地址进行分词。但是,上述方法依赖大量的地址先验知识,需要构建庞大的地址词典,对分词人员有较强的专业性要求,地址数据标注和分词成本很高。
5.无监督学习是一种不依赖于标签数据的机器学习范式,通过对数据内在特征的挖掘,找到数据间潜在的关系,发现数据里有价值的信息,从而能够大幅度降低人力和时间成本,因此广泛应用于文本处理、语音识别和计算机视觉相关任务中。
6.综上所述,如何利用大量地址数据内含有的相同或相似的地址特征信息,通过无监督学习方式实现中文地址的自动分词是现有技术亟待解决的问题。
技术实现要素:
7.为了克服现有技术的不足,解决现有技术中过度依赖地址词典或构建训练数据标注成本高的问题,本技术旨在提供一种基于无监督学习的中文地址分词方法及系统,能够利用大量地址数据内含有的相同或相似的地址特征信息,通过无监督学习的方式实现地址的自动分词。
8.为了实现上述目的,一方面,本技术提供一种基于无监督学习的中文地址分词方法,具体包括:地址文本预处理,包括:获取原始中文地址文本;去掉任意一条原始中文地址文本中的特殊字符,获得地址文本;地址文本初步切分,包括:以词为最小单元,利用中文分词工具对所述地址文本进行切分,获得任意一条地址文本对应的词列表;根据所有地址文本对应的词列表,获得切分词集合;根据预设的停用词,构建停用词表;根据所述停用词表,去除所述切分词集合中的停用词,获得词集合;以字为最小单元,对所述地址文本直接进行切分,获得所述任意一条地址文本对
应的字列表;根据所有地址文本对应的字列表,获得切分字集合;根据所述停用词表,去除所述切分字集合中的停用词,获得字集合;构建地址候选特征词库,包括:构建lda主题模型;利用所述lda主题模型对所述词集合进行建模,获得第一候选特征词库;利用所述lda主题模型对所述字集合进行建模,获得第二候选特征词库;构建每条地址的候选特征词集,包括:根据所述第一候选特征词库,对所述词集合进行筛选,获得候选特征词集;根据所述第二候选特征词库,对所述字集合进行筛选,获得候选特征字集;对所述候选特征词集和所述候选特征字集取交集,获得候选特征词交集;对所述候选特征词集和所述候选特征字集取并集,获得候选特征词并集;基于候选特征词进一步分词,包括:根据所述候选特征词交集,筛选出所述任意一条地址文本中含有的候选特征词;如果所述候选特征词交集中存在位置相邻的两个候选特征词,则根据所述两个候选特征词在所述地址候选特征词库中出现的频率进行判断,保留频率高的候选特征词作为所述任意一条地址文本的候选特征词;对所述任意一条地址文本利用分词工具形成的多个文本段,判断候选特征词是否出现在文本段中,若所述候选特征词出现在所述文本段中,则将所述文本段进一步切分成子文本段和候选特征词;筛选每条地址的特征词,包括:判断所述候选特征词并集中的词项是否出现在所述任意一条地址文本的各个文本段尾部;如果所述候选特征词并集中的词项出现在所述任意一条地址文本的各个文本段尾部,则判定所述词项为地址特征词;对于位置相邻的地址特征词,保留词频高的地址特征词,直至不再出现位置相邻的地址特征词,获得所述任意一条地址文本的全部地址特征词;基于地址特征词对地址文本分词,包括:根据所述全部地址特征词在所述任意一条地址文本中出现的位置,对所述任意一条地址文本进行切分,获得地址分词结果。
9.进一步的,利用所述lda主题模型对所述词集合进行建模,获得第一候选特征词库的具体方法为:根据所述词集合,获得词袋词频向量。
10.利用所述词袋词频向量,训练所述lda主题模型,获得主题-词项分布。
11.根据所述主题-词项分布,获得潜在主题下的词项概率。
12.对所述潜在主题下的词项概率进行排序。
13.获取预设阈值,并判断所述潜在主题下的词项概率与所述预设阈值的大小。
14.保留所述潜在主题下的词项概率高于所述预设阈值的词项,并将所述词项作为所述潜在主题下的主题词。
15.合并所有潜在主题下的主题词,获得主题词集合。
16.统计任意一个主题词在所述主题词集合中出现的次数。
17.根据所述任意一个主题词在所述主题词集合中出现的次数,获得相对词频。
18.根据所述相对词频,对所有主题词进行排序,获得第一候选特征词库。
19.进一步的,确定潜在主题数量的方法具体包括以下步骤:获取预设的主题数量变化范围。
20.根据所述主题数量变化范围,计算任意一个lda主题模型的困惑度。
21.从所有lda主题模型的困惑度中选取最小困惑度。
22.将所述最小困惑度对应的主题数量作为潜在主题数量。
23.进一步的,所述第一候选特征词库中的词项至少包含一个中文汉字,所述第二候选特征词库中的词项仅包含一个中文汉字。
24.进一步的,所述预设阈值为0.01。
25.进一步的,所述相对词频,即为任意一个主题词在主题词集合中出现的次数与所有主题词出现的次数之和之间的比值,具体可表示为:式中,为相对词频,为主题词在主题词集合中出现的次数,n为主题词数量。
26.进一步的,所述候选特征词并集中的词项排列规则为:所述候选特征字集的字项排列在前面,属于所述候选特征词集但不包含在所述候选特征字集内的词项排在后面。
27.进一步的,所述特殊字符包括标点、括号和英文。
28.进一步的,所述停用词包括地址所属省、市、区的名称,方位词和数量词。
29.第二方面,本技术还提供一种基于无监督学习的中文地址分词系统,具体包括:预处理模块,用于获取原始中文地址文本;以及,去掉任意一条原始中文地址文本中的特殊字符,获得地址文本。
30.初步切分模块,用于以词为最小单元,利用中文分词工具对所述地址文本进行切分,获得任意一条地址文本对应的词列表;根据所有地址文本对应的词列表,获得切分词集合;根据预设的停用词,构建停用词表;根据所述停用词表,去除所述切分词集合中的停用词,获得词集合。
31.以及,以字为最小单元,对所述地址文本直接进行切分,获得所述任意一条地址文本对应的字列表;根据所有地址文本对应的字列表,获得切分字集合;根据所述停用词表,去除所述切分字集合中的停用词,获得字集合。
32.候选特征词库构建模块,用于构建lda主题模型;以及,利用所述lda主题模型对所述词集合进行建模,获得第一候选特征词库;以及,利用所述lda主题模型对所述字集合进行建模,获得第二候选特征词库。
33.候选特征词集构建模块,用于根据所述第一候选特征词库,对所述词集合进行筛选,获得候选特征词集;以及,根据所述第二候选特征词库,对所述字集合进行筛选,获得候选特征字集;以及,对所述候选特征词集和所述候选特征字集取交集,获得候选特征词交集;以及,对所述候选特征词集和所述候选特征字集取并集,获得候选特征词并集。
34.进一步分词模块,用于根据所述候选特征词交集,筛选出所述任意一条地址文本中含有的候选特征词;如果所述候选特征词交集中存在位置相邻的两个候选特征词,则根据所述两个候选特征词在所述地址候选特征词库中出现的频率进行判断,保留频率高的候选特征词作为所述任意一条地址文本的候选特征词;对所述任意一条地址文本利用分词工具形成的多个文本段,判断候选特征词是否出现在文本段中,若所述候选特征词出现在所述文本段中,则将所述文本段进一步切分成子文本段和候选特征词。
35.特征词筛选模块,用于判断所述候选特征词并集中的词项是否出现在所述任意一条地址文本的各个文本段尾部;如果所述候选特征词并集中的词项出现在所述任意一条地址文本的各个文本段尾部,则判定所述词项为地址特征词;对于位置相邻的地址特征词,保
留词频高的地址特征词,直至不再出现位置相邻的地址特征词,获得所述任意一条地址文本的全部地址特征词。
36.输出模块,用于根据所述全部地址特征词在所述任意一条地址文本中出现的位置,对所述任意一条地址文本进行切分,获得地址分词结果。
37.本技术提供一种基于无监督学习的中文地址分词方法及系统,利用地址数据间的相关信息,即对于描述内容不同的地址含有全部或部分相同或相近的特征词,以及特征词会在地址数据中反复出现的特性,通过lda主题模型自动挖掘出地址数据的候选特征词;还通过将地址数据切分成词和字两种形式,增强不同长度特征词的挖掘能力;以及利用特征词在地址要素内的词位信息和在地址数据中出现的词频信息,进一步合理地确定地址的切分位置,提高地址分词的有效性。本技术在完成中文地址分词的过程中,仅仅使用地址自身的信息,无需额外建立规模庞大的地址特征词词典,也无需标注大量用于训练模型的地址数据,从而能够有效解决地址分词过程中,地址先验知识要求多和人工标注成本高的问题。
附图说明
38.为了更清楚地说明本技术的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,对于本领域普通技术人员而言,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
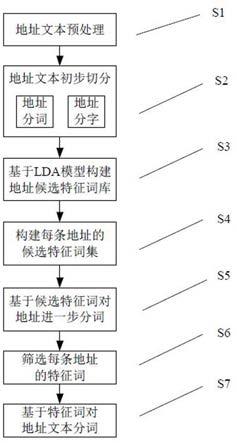
39.图1为本技术实施例提供的一种基于无监督学习的中文地址分词方法流程示意图;图2为本技术实施例提供的地址特征词挖掘及筛选流程示意图;图3为本技术实施例提供的地址数据集的部分候选特征词及其词频分布示意图;图4为本技术实施例提供的地址数据集的部分候选特征字及其词频分布示意图。
具体实施方式
40.下面将结合本技术实施例中的附图,对本技术实施例中的技术方案进行完整、清楚的描述。显然,所描述的实施例仅仅是本技术一部分实施例,而不是全部的实施例。基于本技术中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本技术保护的范围。
41.参见图1,为本技术实施例提供的一种基于无监督学习的中文地址分词方法流程示意图。本技术实施例第一方面提供一种基于无监督学习的中文地址分词方法,该中文地址分词方法具体包括以下步骤:步骤s1:地址文本预处理,预处理的具体内容为:获取原始中文地址文本,以及去掉任意一条原始中文地址文本中的特殊字符,获得地址文本。本技术实施例中,特殊字符包括标点、括号和英文。
42.步骤s2:地址文本初步切分,该步骤又具体包括以下内容:步骤s21:以词为最小单元,利用结巴(jieba)分词器对步骤s1获得的地址文本进行切分,获得任意一条地址文本对应的词列表。
43.步骤s22:根据所有地址文本对应的词列表,获得切分词集合。
44.步骤s23:根据预设的停用词,构建停用词表。
45.本技术实施例中,停用词具体包括中文地址所属省、市、区的名称,方位词和数量词。具体的,停用词是根据具体情况进行相应设置的,具有较强的目的性和针对性,以减少分词结果出现误判的概率,以及节省后续程序的计算时间,需要在进行分词操作前构建好停用词表。需要说明的是,所属省、市、区的名称是指地名中的专名,例如{
‘
江苏省’}对应的停用词,包括以词的形式存在的
‘
江苏’和以字的形式存在的
‘
江’、
‘
苏’。
46.步骤s24:根据停用词表,去除切分词集合中的停用词,获得词集合。
47.步骤s25:以字为最小单元,对步骤s1获得的地址文本直接进行切分,获得任意一条地址文本对应的字列表。
48.步骤s26:根据所有地址文本对应的字列表,获得切分字集合。
49.步骤s27:根据步骤s23构建的停用词表,去除切分字集合中的停用词,获得字集合。
50.步骤s3:构建地址候选特征词库,该步骤又具体包括以下内容:步骤s31:构建lda主题模型。
51.步骤s32:利用上述lda主题模型对步骤s24得到的词集合进行建模,获得第一候选特征词库。
52.更具体的,本技术实施例中,假设每一条地址数据为一篇文档d,地址中特征词列可构成一个主题,地址数量为,主题数量为k,地址数据的主题分布为,主题的主题-词项分布为,整个地址数据的主题分布依赖于先验参数(),每个主题下的主题-词分布依赖于先验参数(),获得第一候选特征词库的具体方法为:步骤s3201:根据步骤s24得到的词集合,获得词袋词频向量。
53.步骤s3202:利用词袋词频向量,训练lda主题模型,获得地址数据-主题分布和主题-词项分布。
54.步骤s3203:根据主题-词项分布,获得潜在主题下的词项概率{w1,w2,...,wm},例如:t
词i
={江苏省 0.126,连云港市 0.126,街道 0.116,海州区 0.082,号 0.075,室 0.062,单元 0.061,......}。
55.步骤s3204:对潜在主题下的词项概率进行排序。
56.步骤s3205:获取预设阈值l,并判断潜在主题下的词项概率与预设阈值的大小。
57.具体的,本技术实施例中,预设阈值l取值为0.01。如果阈值设置过高,会剔除掉部分潜在主题词,影响地址切分准确度;如果阈值设置过低,又会将不必要的文本归入主题词中,增加了后续处理的工作量,因此本技术实施例中的阈值0.01是经过反复试验获得的优选值,但并不限定为该取值,可以根据实际需要进行设置。
58.步骤s3206:保留潜在主题下的词项概率高于预设阈值的词项,并将该词项作为潜在主题下的主题词。
59.步骤s3207:合并所有潜在主题下的主题词,获得主题词集合st。
60.步骤s3208:统计任意一个主题词在主题词集合st中出现的次数。
61.步骤s3209:根据任意一个主题词在主题词集合st中出现的次数,获得相对词频。
62.步骤s3210:根据相对词频,对所有主题词进行排序,获得第一候选特征词库。需要说明的是,相对词频高意味着该词在多个主题中出现,其成为地址特征词的概率更高。
63.具体的,本技术实施例中,所谓相对词频,即为任意一个主题词在主题词集合中出现的次数与所有主题词出现的次数之和之间的比值,具体可表示为:式中,为相对词频,为主题词在主题词集合中出现的次数,n为主题词数量。
64.更具体的,本技术实施例中,确定潜在主题数量的方法具体包括以下步骤:步骤s3221:获取预设的主题数量变化范围。
65.步骤s3222:根据主题数量变化范围,计算任意一个lda主题模型的困惑度。
66.步骤s3223:从所有lda主题模型的困惑度中选取最小困惑度。
67.步骤s3224:将最小困惑度对应的主题数量作为潜在主题数量。
68.步骤s33:利用上述lda主题模型对步骤s27得到的字集合进行建模,获得第二候选特征词库。具体的,由于构建第二候选特征词库的原理和步骤与第一候选特征词库相同,此处不再赘述,具体请参考第一候选特征词库的构建过程。
69.本技术实施例中,第一候选特征词库中的词项至少包含一个中文汉字,第二候选特征词库中的词项仅包含一个中文汉字,并且第一候选特征词库和第二候选特征词库构成了本技术实施例的候选特征词库,涵盖了整个地址数据集的候选特征词。
70.步骤s4:构建每条地址的候选特征词集,该步骤又具体包括以下内容:步骤s41:根据第一候选特征词库,对步骤s24获得的词集合进行筛选,获得候选特征词集。
71.步骤s42:根据第二候选特征词库,对步骤s27获得的字集合进行筛选,获得候选特征字集。
72.步骤s43:对候选特征词集和候选特征字集取交集,获得候选特征词交集。
73.步骤s44:对候选特征词集和候选特征字集取并集,获得候选特征词并集。
74.本技术实施例中,候选特征词并集中的词项排列规则为:候选特征字集的字项排列在前面,属于候选特征词集但不包含在候选特征字集内的词项排在后面。
75.步骤s5:基于候选特征词集进一步分词,该步骤又具体包括以下内容:步骤s51:根据候选特征词交集,筛选出任意一条地址文本中含有的候选特征词。
76.步骤s52:如果候选特征词交集中存在位置相邻的两个候选特征词,则根据两个候选特征词在地址候选特征词库中出现的频率进行判断,保留频率高的候选特征词作为任意一条地址文本的候选特征词。
77.步骤s53:对任意一条地址文本利用分词工具形成的多个文本段,判断候选特征词是否出现在文本段中,若候选特征词出现在文本段中,则将该文本段进一步切分成子文本段和候选特征词。
78.步骤s6:筛选每条地址的特征词,该步骤又具体包括以下内容:步骤s61:判断候选特征词并集中的词项是否出现在该条地址的各个文本段尾部。
79.步骤s62:如果候选特征词并集中的词项出现在该条地址的各个文本段尾部,则判定该词项为该条地址的地址特征词,否则,不作为该条地址的地址特征词。
80.步骤s63:对于位置相邻的地址特征词,保留词频高的地址特征词,直至不再出现
位置相邻的地址特征词,从而获得该条地址的全部地址特征词。
81.需要说明的是,步骤s3至步骤s6重点阐述了地址特征词挖掘及筛选的过程,具体流程示意图可参考图2。
82.步骤s7:基于地址特征词对地址文本分词,包括:根据步骤s63获得的该条地址文本的全部地址特征词在该条地址中出现的位置,对该条地址进行切分,获得地址分词结果,实现中文地址分词。
83.下面将通过具体实施例,对本技术实施例所提供的一种基于无监督学习的中文地址分词方法进行详细描述。
84.本技术具体实施例主要包括以下内容:步骤1:地址文本预处理,即去掉地址文本中的标点、括号、英文等字符。
85.步骤2:地址文本初步切分。
86.步骤2.1:利用jieba分词器对中文地址切分,得到每条地址对应的词列表,所有地址按词切分后形成词集合。
87.步骤2.2:以字为最小单元,对地址进行切分,得到每条地址的字列表,所有地址按字切分后形成字集合。
88.步骤2.3:将地址所属的省市区名称、方位词和数量词等设置为停用词,构建停用词表,并根据该停用词表,去除词集合与字集合中的停用词。
89.步骤3:基于lda主题模型构建地址候选特征词库。
90.步骤3.1:通过步骤2的初步分词结果,形成词袋词频向量。根据业界习惯,先验参数和的初始值为50/k和0.01。设置lda主题模型的主题数量k的取值范围[8,20],利用词袋词频向量训练主题模型。
[0091]
通过比较计算不同主题模型的困惑度发现,当困惑度最小时所对应的主题数量为14。通过训练lda主题模型,得到地址中潜在主题和每个主题下的词项的概率,其中表1列举出了不同主题下的部分主题词及概率。
[0092]
表1 不同主题下的主题词及概率步骤3.2:将步骤3.1中获得的每个主题下的候选主题词根据其概率值排序,设定阈值为0.01,将每个主题下概率值大于阈值的词项进行保留,作为候选主题词。
[0093]
例如:主题1的候选主题词:{
‘
街','单元','室', '号', '幢', '浦口区','南京市’},主题2的候选主题词:{
‘
连云港市’,
‘
江苏省’,
‘
号','街道','海州区','单元','室','号楼','东海县','灌南县','路','新安镇','连云区','南路','乡’}。
[0094]
步骤3.3:合并所有主题的主题词形成主题词集合,统计每个主题词在主题词集合中出现的次数和相对词频;根据相对词频对主题词排序,形成地址数据集的第一候选特征词库,部分候选特征词及其词频分布如图3所示。
[0095]
步骤3.4:重复步骤3.1至步骤3.3,利用步骤2分字形成的词袋词频向量训练lda主题模型,得到地址中潜在主题和每个主题下的字项的概率,表2列举出了不同主题下的主题字及概率。
[0096]
表2 不同主题下的主题字及概率每个主题下的候选主题字根据其概率值排序,设定阈值为0.01,将每个主题下概率值大于阈值的字项进行保留,作为候选主题字;统计所有的主题中出现的主题字的相对词频,根据词频对主题字排序,形成地址数据集的第二候选特征词库,部分候选特征字及其词频分布如图4所示。
[0097]
从而,第一候选特征词库和第二候选特征词库构成了整个地址数据集的候选特征词。
[0098]
步骤4:构建每条地址的候选特征词集。
[0099]
对于每条地址,分别从第一候选特征词库和第二候选特征词库中选出在该地址中出现的词,形成该条地址的候选特征词集合和候选特征字集合。
[0100]
例如,预处理后地址文本为:江苏省连云港市灌云县圩丰镇圩南村一组42号。
[0101]
地址本文经过jieba分词并去除停用词的结果:['江苏省','连云港市','灌云县','圩', '丰镇', '圩','南村','一组','号'],从步骤3形成的第一候选特征词库中,选择出该条地址的候选特征词集合:['号', '镇', '连云港市', '江苏省', '灌云县', '村', '组', '圩'],地址文本经过字切分并去除停用词的结果:['省','市','县','圩', '丰','镇', '圩','村','组','号'],从步骤3形成的第二候选特征词库中,选择出该条地址的候选特征字集合:['号', '市', '省', '村', '镇', '县', '组', '圩', '灌'],
那么,该条地址的的候选特征词集合与候选特征字集合的交集为:['号', '村', '组', '圩', '镇'],以及,该条地址的候选特征词集合与候选特征字集合的并集为:['号', '市', '省', '村', '镇', '县', '组', '圩', '灌','连云港市', '江苏省', '灌云县']。
[0102]
步骤5:基于候选特征词对地址进一步分词。
[0103]
候选特征词交集中若存在位置相邻的词,根据相对词频的大小进行取舍,保留相对词频高的候选特征词。
[0104]
该条地址的候选特征词交集为:['号', '村', '组', '圩', '镇'],其中,
‘
镇’和
‘
圩’在地址文本中的位置相邻,而
‘
镇’和
‘
圩’在整个地址数据集中出现的相对词频分别为:p(
‘
镇’)=0.0112, p(
‘
圩’)=0.0056,由于p(
‘
镇’)》p(
‘
圩’),因此保留候选特征词
‘
镇’,该条地址的候选特征词交集最终为:['号', '村', '组', '镇'],利用候选特征词交集对地址jieba分词结果进一步分词,得到结果如下所示:['江苏省','连云港市','灌云县','圩','丰', '镇','圩','南','村', '一','组','号']。
[0105]
步骤6:筛选每条地址的特征词判断地址的候选特征词并集中的词是否出现在地址文本段的尾部,若是,则作为地址特征词。通过筛选,得到的地址特征词为:['省', '市', '县',
‘
圩’, '镇', '村', '组', '号'],由于筛选出的结果中
‘
圩’与
‘
县’在地址中的位置相邻,通过判断这两个字的词频,即:p(
‘
县’)=0.0112,p(
‘
圩’)=0.0056,因此,保留词频大的特征词
‘
县’,那么该条地址的最终特征词为:['省', '市', '县', '镇', '村', '组', '号']。
[0106]
进一步的,上述特征词在预处理后地址文本中的位置为:[2 6 9 12 15 17 20],需要说明的是,此处的位置标识是基于计算机语言进行设置的,所以初始值是从0开始,那么上述位置集合中的2,则表示该条地址文本的第三个汉字。
[0107]
步骤7:基于特征词对地址文本分词根据地址特征词及其位置,对地址进行切分,实现中文地址分词。
[0108]
中文地址分词结果为:江苏省/ 连云港市/ 灌云县/ 圩丰镇/ 圩南村/ 一组/ 42号将地址数据集中的所有地址,根据其特征词及位置切分,就完成整个地址数据的分词。
[0109]
本技术实施例第二方面提供一种基于无监督学习的中文地址分词系统,用于执行
本技术实施例第一方面提供的一种基于无监督学习的中文地址分词方法,对于本技术实施例第二方面提供的一种基于无监督学习的中文地址分词系统中未公开的细节,请参见本技术实施例第一方面提供的一种基于无监督学习的中文地址分词方法。
[0110]
该中文地址分词系统具体包括:预处理模块,用于获取原始中文地址文本;以及,去掉任意一条原始中文地址文本中的特殊字符,获得地址文本。
[0111]
初步切分模块,用于以词为最小单元,利用中文分词工具对所述地址文本进行切分,获得任意一条地址文本对应的词列表;根据所有地址文本对应的词列表,获得切分词集合;根据预设的停用词,构建停用词表;根据所述停用词表,去除所述切分词集合中的停用词,获得词集合。
[0112]
以及,以字为最小单元,对所述地址文本直接进行切分,获得所述任意一条地址文本对应的字列表;根据所有地址文本对应的字列表,获得切分字集合;根据所述停用词表,去除所述切分字集合中的停用词,获得字集合。
[0113]
候选特征词库构建模块,用于构建lda主题模型;以及,利用所述lda主题模型对所述词集合进行建模,获得第一候选特征词库;以及,利用所述lda主题模型对所述字集合进行建模,获得第二候选特征词库。
[0114]
候选特征词集构建模块,用于根据所述第一候选特征词库,对所述词集合进行筛选,获得候选特征词集;以及,根据所述第二候选特征词库,对所述字集合进行筛选,获得候选特征字集;以及,对所述候选特征词集和所述候选特征字集取交集,获得候选特征词交集;以及,对所述候选特征词集和所述候选特征字集取并集,获得候选特征词并集。
[0115]
进一步分词模块,用于根据所述候选特征词交集,筛选出所述任意一条地址文本中含有的候选特征词;如果所述候选特征词交集中存在位置相邻的两个候选特征词,则根据所述两个候选特征词在所述地址候选特征词库中出现的频率进行判断,保留频率高的候选特征词作为所述任意一条地址文本的候选特征词;对所述任意一条地址文本利用分词工具形成的多个文本段,判断候选特征词是否出现在文本段中,若所述候选特征词出现在所述文本段中,则将所述文本段进一步切分成子文本段和候选特征词。
[0116]
特征词筛选模块,用于判断所述候选特征词并集中的词项是否出现在所述任意一条地址文本的各个文本段尾部;如果所述候选特征词并集中的词项出现在所述任意一条地址文本的各个文本段尾部,则判定所述词项为地址特征词;对于位置相邻的地址特征词,保留词频高的地址特征词,直至不再出现位置相邻的地址特征词,获得所述任意一条地址文本的全部地址特征词。
[0117]
输出模块,用于根据所述全部地址特征词在所述任意一条地址文本中出现的位置,对所述任意一条地址文本进行切分,获得地址分词结果。
[0118]
由以上技术方案可知,本技术提供一种基于无监督学习的中文地址分词方法及系统,利用地址数据间的相关信息,即对于描述内容不同的地址含有全部或部分相同或相近的特征词,以及特征词会在地址数据中反复出现的特性,通过lda主题模型自动挖掘出地址数据的候选特征词;还通过将地址数据切分成词和字两种形式,增强不同长度特征词的挖掘能力;以及利用特征词在地址要素内的词位信息和在地址数据中出现的词频信息,进一步合理地确定地址的切分位置,提高地址分词的有效性。本技术在完成中文地址分词的过
程中,仅仅使用地址自身的信息,无需额外建立规模庞大的地址特征词词典,也无需标注大量用于训练模型的地址数据,从而能够有效解决地址分词过程中,地址先验知识要求多和人工标注成本高的问题。
[0119]
以上结合具体实施方式和范例性实例对本技术进行了详细说明,使本领域技术人员能够理解或实现本技术,不过这些说明并不能理解为对本技术的限制。本领域技术人员理解,在不偏离本技术精神和范围的情况下,可以对本技术技术方案及其实施方式进行多种等价替换、修饰或改进,这些均落入本技术的范围内。本技术的保护范围以所附权利要求为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1