一种基于改进的YOLOv5输电线路航拍图像缺陷检测方法
一种基于改进的yolov5输电线路航拍图像缺陷检测方法
技术领域
1.本发明涉及图像处理技术领域,具体涉及一种基于改进的yolov5输电线路航拍图像缺陷检测方法。
背景技术:
[0002][0003]
由于输电线路覆盖跨度大,所处的环境多变,气候复杂,并且长期直接暴露在自然环境下,容易受风吹雨打雷击等自然因素影响,线路容易产生绝缘子掉串、防震锤脱落等损伤,这类零部件损伤都可能导致线路供电中断。另外,鸟害也是导致输电线路故障的一个重要原因。鸟类在输电线路上停留时可能会造成相间短路;鸟巢的筑巢材料可能会导致导线间隙短路。如果故障得不到及时处理,就有可能导致整个线路供电中断,甚至引发大面积停电。因此,对输电线路定期巡检至关重要。
[0004]
随着智能电网的发展,国家电网公司和南方电网公司积极推进无人机班组建设,巡检方式正以“机巡为主,人巡为辅”的模式转变。通过定位技术让无人机到达指定位置,并且自主对输电线路设备进行多方位拍摄,将包含大量输电线设备状态的图像信息传送到地面接收站,工作人员在地面对图像信息进行处理。与传统人工巡检相比,无人机巡检不会受到山川湖泊等地理环境的约束,没有人身安全的危险,并且拍摄角度灵活,没有视觉盲区,可以大大节省人工成本和时间成本,提高巡检效率。
[0005]
虽然无人机巡检拥有许多优势,但也带来了种种新的挑战。由于无人机拍摄到的图片仅是数据采集,仍然需要人工手动从图片中标注故障点,对工作人员的经验要求较高,容易发生漏检,误判的情况。且零部件尺度不一,背景复杂,人工检查容易出现视觉疲劳,降低判断的准确率。因此,迫切需要一种目标检测方法自动对图片中的零部件进行检测。随着计算机视觉的发展,硬件设备的更新,深度学习理论在图片处理方面大放异彩。通过卷积神经网络提取图像的高层特征,然后结合这些特征进行分类和定位。但是由于输电线路背景复杂,部件之间存在遮挡,缺陷处目标较小等问题,图像识别的效果并不好。因此,本技术需要对此进一步研究,以解决上述技术问题。
技术实现要素:
[0006]
针对以上问题,本发明提供了一种基于改进的yolov5输电线路航拍图像缺陷检测方法,能够对一幅图像中的多种缺陷进行识别与检测,比如绝缘子掉串、防震锤脱落、鸟巢等,在背景复杂、存在遮挡以及目标较小的情况下有较好检测效果。
[0007]
为了实现上述目的,本发明采用的技术方案如下:
[0008]
一种基于改进的yolov5输电线路航拍图像缺陷检测方法,包括以下步骤:
[0009]
步骤1、建立输电线路航拍图像数据集,利用图片数据增强技术对图片进行扩充,并且平衡样本类别;用labelimg工具对图片进行标注,用矩形框标注物体位置和类别,生成与其一一对应的xml格式文件;
[0010]
步骤2、构造改进的yolov5网络,取消原本的focus层,改用2*2像素的卷积模块代替;增加更小尺度检测层来提高小物体检测能力;将骨干网络的特征连接到颈部网络的特征融合层以防特征丢失;构造c3mhsa模块,将注意力机制与cnn结合,用mhsa模块替换c3模块中3*3像素的卷积模块,并用 c3mhsa模块替换backbone和neck的最后一个c3模块,增强在复杂背景、遮挡情况下的抗干扰能力;
[0011]
步骤3、将步骤1得到的图片划分为训练集、验证集和测试集;设置训练参数,将训练集图片放入改进后的yolov5网络进行训练,保留最佳的训练网络权重best.pt;
[0012]
步骤4、将步骤3得到的最佳网络权重载入网络,对测试集进行检测,输出结果为在图片中框出输电线路各部件的位置以及标注类别。
[0013]
优选地,所述步骤1的具体方法如下:
[0014]
步骤1.1、将输电线路航拍图像通过数据增强技术进行扩充,数据增强技术包括:水平翻转、角度旋转、随机通道变换、随机色度变换和增加高斯噪声;
[0015]
步骤1.2、利用labelimg工具对图片进行标注,用矩形框标注物体位置和类别,生成的xml格式文件记录了图片的名称、图片内物体的位置信息、尺寸信息和类别信息。
[0016]
优选地,所述步骤2的具体方法如下:
[0017]
步骤2.1、构造改进的yolov5网络,取消focus层。原先的focus层采用切片的方式对图像进行压缩,将空间信息压缩到通道信息,提升了速度但也降低了精度,因此这里采用2*2像素的卷积模块替换掉focus层,更好保留原图像特征。其中,卷积模块(cbs)由卷积层、bn层、激活函数组成,激活函数选用silu函数,公式为:silu(x)=x*sigmoid(x)。
[0018]
步骤2.2、在原本3个检测层的基础上,增加一个160*160像素的检测层,用来提升检测小物体的能力;由neck层80*80像素的concat拼接模块引出一条分支,经过c3、cbs、上采样模块变为160*160像素,同时backbone层160*160 像素的c3模块引出一条分支与合并后送入c3模块进行特征整合,然后经过一个大小为1*1像素的卷积模块后送入检测头;
[0019]
步骤2.3、基于c3模块构建c3mhsa模块,c3模块是由bottleneckcsp简化而来,包括3个1*1像素的卷积模块和n个bottleneck模块组成,而bottleneck 模块由1*1、3*3像素的卷积和残差模块组成;c3mhsa模块就是将bottlencek 模块中的3*3像素的卷积模块换成mhsa多头自注意力机制,用来增强在遮挡情况下和复杂背景下的学习能力。考虑到大目标的干扰、遮挡情况比较多,最后决定将backbone的最底层c3模块和neck的最底层c3模块替换为c3mhsa 模块。
[0020]
其中,mhsa(multi-head self-attention)模块增加二维位置编码部分,由 rh和rw分别代表垂直和水平方向上的相对信息。具体流程如下:首先输入经过 3个逐点卷积后分别得到对应的q、k、v,rh和rw进行相加后得到r,其中q、 k、v、r分别代表着query、key、value和位置编码。然后将r与q进行矩阵相乘得到qr
t
、q与k进行矩阵相乘得到qk
t
,将qr
t
与qk
t
相加后经过softmax层再与v进行矩阵相乘得到单头输出。最后将多个输出进行拼接,经过一个矩阵将特征融合,最终得到多头输出。
[0021]
步骤2.4、从backbone层80*80、40*40像素的c3模块和20*20像素的 c3mhsa模块中分别引出一条分支对应的接入pan层的80*80、40*40、20*20 像素的concat模块中,防止特征丢失。
[0022]
优选地,所述步骤3的具体方法如下:
[0023]
步骤3.1、将步骤1得到的图片和xml文件按训练集、验证集、测试集按 70%:15%:15%的比例划分;
[0024]
步骤3.2、设置训练参数为:批次大小为16,初始学习率为0.01,最终学习率为0.2,冲量为0.937,权重衰减系数为0.0005;
[0025]
步骤3.3,采用ciou作为预测框的损失函数lciou,定义为:
[0026][0027]
其中ρ(b,b
gt
)表示预测框和真实框中心点的欧氏距离,c表示能够同时包含两个框的最小闭包区域的对角线距离,α表示权重函数,v表示长宽比的相似程度;
[0028]
步骤3.4、利用改进后的yolov5网络训练训练集图片,通过多次迭代使损失函数最小,在到达最大训练次数后停止训练,保存本次训练最佳网络权重。
[0029]
优选地,所述步骤4的具体方法如下:
[0030]
步骤4.1、将步骤3得到的最佳网络权重载入网络,对测试集图片进行检测,输出结果为在图片中框出输电线路各部件的位置以及标注类别;
[0031]
步骤4.2、用精确度(precision)、召回率(recall)和平均精确率均值(map) 指标对网络进行评价。
[0032]
本发明与现有技术相比,具有以下有益效果:
[0033]
1、本发明通过图片增强技术,增强了网络的泛化能力,适用于多种场景,不局限于单一缺陷,可以同时框出图中多种缺陷,更适用于无人机电力巡检。
[0034]
2、本发明针对无人机电力巡检,输电线路航拍图像中远处物体较小、缺陷处较小的问题,通过增加小目标检测层,虽然增加了网络计算量,但是提高了对网络对小目标的检测能力。
[0035]
3、本发明针对输电线路航拍图像中,经常会出现物体相互遮挡,同时复杂的背景也加大了识别难度,使用ciou预测框损失函数,引入cnn和注意力机制结合的方法,可以更好的在遮挡、复杂背景下识别目标。
附图说明
[0036]
图1是本发明的流程图;
[0037]
图2是本发明改进后的yolov5总结构图;
[0038]
图3是本发明构建的c3mhsa模块结构图;
[0039]
图4是本发明改进后的yolov5训练过程示意图;
[0040]
图5是本发明利用训练完的yolov5测试实际效果;
[0041]
图6是本发明改进前后的评价指标对比图。
具体实施方式
[0042]
下面结合附图和实施例对本发明的技术方案进行详细说明:
[0043]
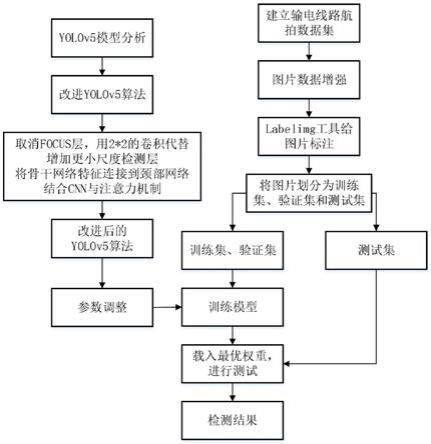
如图1所示,一种基于改进的yolov5输电线路航拍图像缺陷检测方法,包括以下步骤:
[0044]
步骤1、建立输电线路航拍图片数据集,图片由cplid公开数据集和github 上收集
的其他图片构成,共计1404张。利用图片数据增强技术对图片进行扩充,并且平衡样本类别。数据增强技术包括水平翻转,角度旋转,随机通道变换,随机色度变换,增加高斯噪声等。用labelimg工具对图片进行标注,用矩形框标注物体位置和类别,生成与其一一对应的xml格式文件。xml格式文件主要记录了图片的名称,图片内物体的位置信息,尺寸信息,类别信息。
[0045]
步骤2、构造改进的yolov5网络,改进后的网络结构如图2所示。
[0046]
步骤2.1,取消原本的focus层,改用2*2像素的卷积模块代替。原先的focus层采用切片的方式对图像进行压缩,将空间信息压缩到通道信息,提升了速度但也降低了精度,因此这里用2*2像素的卷积模块替换掉focus层,更好保留原图像特征。卷积模块由卷积层、bn层、激活函数组成,激活函数选用silu 函数,公式为:silu(x)=x*sigmoid(x)。
[0047]
步骤2.2、在原本3个检测层的基础上,增加一个160*160像素的检测层,用来提升检测小物体的能力。由neck层80*80像素的concat拼接模块引出一条分支,经过c3、cbs、上采样模块变为160*160像素,同时backbone层160*160 像素的c3模块引出一条分支与合并后送入c3模块进行特征整合,然后经过一个大小为1*1像素的卷积模块后送入检测头。
[0048]
步骤2.3、从backbone层80*80、40*40像素的c3模块和20*20像素的c3mhsa 模块中分别引出一条分支对应的接入pan层的80*80、40*40、20*20像素的 concat模块中,防止特征丢失。
[0049]
步骤2.4、构造c3mhsa模块,结构如图3所示,c3mhsa模块是在c3模块基础上改进的,c3模块是由bottleneckcsp简化而来,包括3个1*1像素的卷积模块和n个bottleneck模块组成,而bottleneck模块由1*1、3*3像素的卷积和残差模块组成。c3mhsa模块就是将bottlencek模块中的3*3像素的卷积模块换成mhsa多头自注意力机制,用来增强在遮挡情况下和复杂背景下的学习能力。考虑到大目标的干扰、遮挡情况比较多,最后决定将backbone的最底层c3 模块和neck的最底层c3模块替换为c3mhsa模块。
[0050]
其中,mhsa(multi-head self-attention)模块增加二维位置编码部分,由 rh和rw分别代表垂直和水平方向上的相对信息。具体操作如下:首先输入经过 3个逐点卷积后分别得到对应的q、k、v,rh和rw进行相加后得到r,其中q、 k、v、r分别代表着query、key、value和位置编码。然后将r与q进行矩阵相乘得到qr
t
、q与k进行矩阵相乘得到qk
t
,将qr
t
与qk
t
相加后经过softmax层再与v进行矩阵相乘得到单头输出。最后将多个输出进行拼接,经过一个矩阵将特征融合,最终得到多头输出。
[0051]
步骤3,将s1得到的图片划分为训练集、验证集和测试集。设置训练参数,将训练集图片放入改进后的yolov5网络进行训练,保留最佳的训练网络权重 bset.pt。具体操作如下:
[0052]
步骤3.1,将步骤1得到的图片和xml文件按训练集、验证集、测试集按70%: 15%:15%的比例划分。
[0053]
步骤3.2,采用ciou作为预测框的损失函数lciou。定义为:
[0054][0055]
其中ρ(b,b
gt
)表示预测框和真实框中心点的欧氏距离,c表示能够同时包含两个框的最小闭包区域的对角线距离,α表示权重函数,v表示长宽比的相似程度。
[0056]
步骤3.3,设置训练参数为:批次大小为16,初始学习率为0.01,最终学习率为0.2,冲量为0.937,权重衰减系数为0.0005。
[0057]
步骤3.4,利用改进后的yolov5网络训练训练集图片,训练过程如图4所示,通过多次迭代使损失函数最小,在到达最大训练次数后停止训练,保存本次训练最佳网络权重。
[0058]
步骤4,将s3得到的最佳网络权重载入网络,对测试集进行检测,输出结果为在图中框出输电线路各部件的位置以及标注类别。
[0059]
如图5所示,图中自动框出绝缘子、防震锤、鸟巢、defect1(绝缘子缺陷、 defect2(防震锤缺陷)等具体位置并且标注其类别。
[0060]
用精确度(precision)、召回率(recall)和平均精确率均值(map)等指标对网络进行评价。
[0061]
如图6所示,改进后的yolov5网络最终map为0.956,比改进前的0.927 提升了3.1%,其中防震锤和defect2(防震锤缺陷)提升比较大,达到了5%的提升,这也验证了本方法对小目标有较好的识别效果。
[0062]
以上对本发明的一个实施例进行了详细说明,但所述内容仅为本发明的较佳实施例,不能被认为用于限定本发明的实施范围。凡依本发明申请范围所作的均等变化与改进等,均应仍归属于本发明的专利涵盖范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1