基于文本的语种识别方法、相关装置,设备以及存储介质与流程
本技术涉及人工智能,尤其涉及基于文本的语种识别方法、相关装置,设备以及存储介质。
背景技术:
1、随着现代社会信息的全球化,文本的语种识别成为识别技术研究热点之一。在全球化背景下,世界范围内产生的交互越来越多。因此,在对文本进行识别的过程中,不仅需要对中文进行识别,还需要对其他语种的文本进行识别,以适应全球化浪潮。
2、在资源搜索场景下,搜索文本的语种与得到的搜索结果的语种是一致的。目前,对于用户输入的搜索文本,可对每个字符进行编码,再根据编码结果获取各个字符的语言标签特征,由此,基于语言标签特征预测搜索文本的语种识别结果。
3、虽然根据用户输入的搜索文本能够预测其对应的语种识别结果。但在实际用于中,发明人发现现有方案中至少存在如下问题,仅利用搜索文本进行语种识别,得到的语种识别结果准确率并不理想,因此,对语种识别方法进行优化显得尤为必要。
技术实现思路
1、本技术实施例提供了一种基于文本的语种识别方法、相关装置,设备以及存储介质。本技术利用关联资源的语种标签,并结合目标搜索文本,能够为资源搜索提供更加可靠的语种线索,从而有利于提升语种识别的准确性。
2、有鉴于此,本技术一方面提供一种基于文本的语种识别方法,包括:
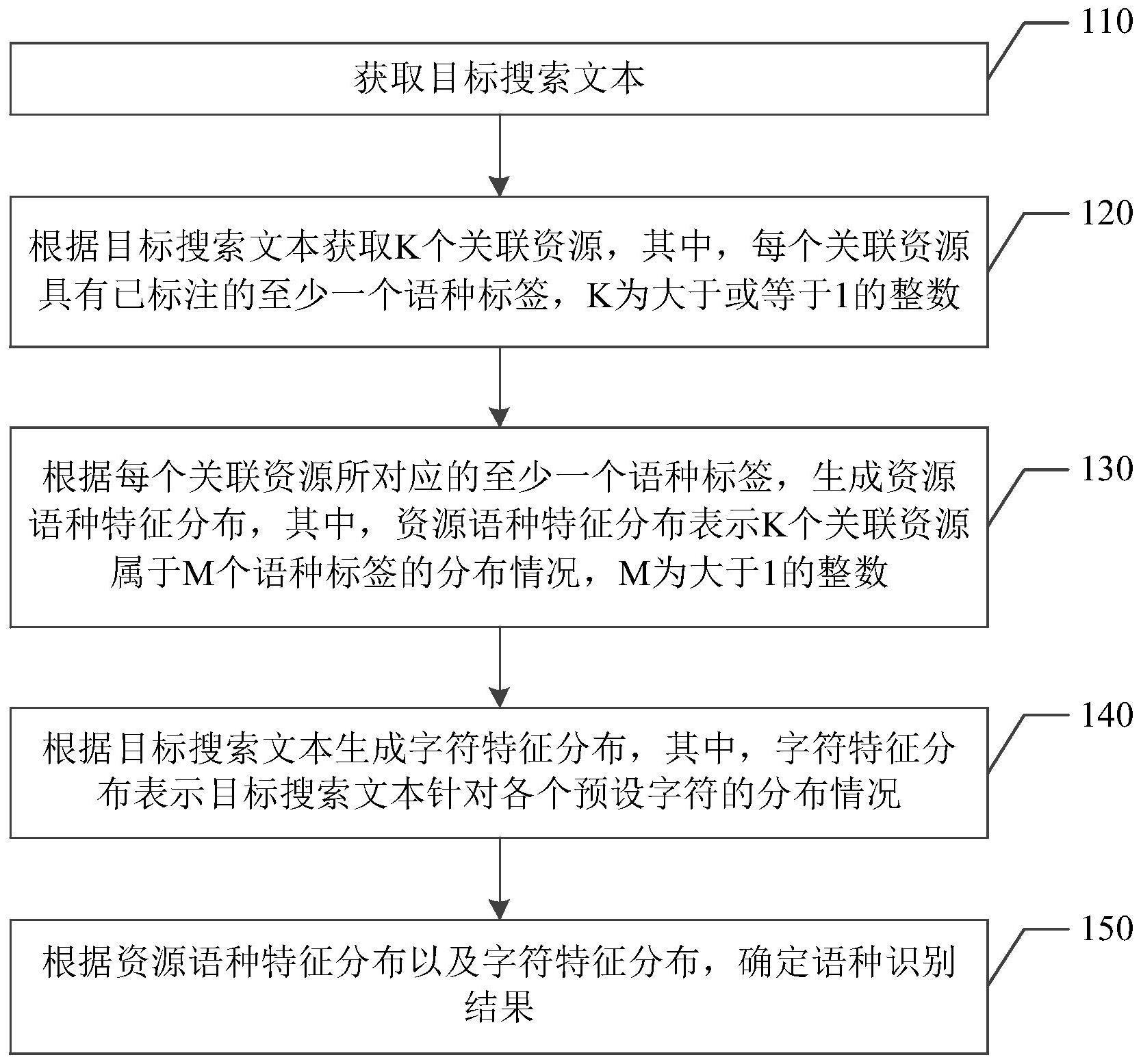
3、获取目标搜索文本;
4、根据目标搜索文本获取k个关联资源,其中,每个关联资源具有已标注的至少一个语种标签,k为大于或等于1的整数;
5、根据每个关联资源所对应的至少一个语种标签,生成资源语种特征分布,其中,资源语种特征分布表示k个关联资源属于m个语种标签的分布情况,m为大于1的整数;
6、根据目标搜索文本生成字符特征分布,其中,字符特征分布表示目标搜索文本针对各个预设字符的分布情况;
7、根据资源语种特征分布以及字符特征分布,确定语种识别结果。
8、本技术另一方面提供一种基于文本的语种识别方法,包括:
9、获取目标搜索文本;
10、根据目标搜索文本,获取针对目标对象的q个历史资源,其中,目标对象为输入目标搜索文本的对象,q个历史资源为目标对象在历史时段内触达过的资源,每个历史资源具有已标注的至少一个语种标签,q为大于或等于1的整数;
11、根据每个历史资源所对应的至少一个语种标签,生成对象语种特征分布,其中,对象语种特征分布表示q个历史资源属于m个语种标签的分布情况,m为大于1的整数;
12、根据目标搜索文本生成字符特征分布,其中,字符特征分布表示目标搜索文本针对各个预设字符的分布情况;
13、根据对象语种特征分布以及字符特征分布,确定语种识别结果。
14、本技术另一方面提供一种语种识别装置,包括:
15、获取模块,用于获取目标搜索文本;
16、获取模块,还用于根据目标搜索文本获取k个关联资源,其中,每个关联资源具有已标注的至少一个语种标签,k为大于或等于1的整数;
17、生成模块,用于根据每个关联资源所对应的至少一个语种标签,生成资源语种特征分布,其中,资源语种特征分布表示k个关联资源属于m个语种标签的分布情况,m为大于1的整数;
18、生成模块,还用于根据目标搜索文本生成字符特征分布,其中,字符特征分布表示目标搜索文本针对各个预设字符的分布情况;
19、识别模块,用于根据资源语种特征分布以及字符特征分布,确定语种识别结果。
20、在一种可能的设计中,在本技术实施例的另一方面的第一种实现方式中,
21、生成模块,具体用于根据每个关联资源所对应的至少一个语种标签,统计m个语种标签中每个语种标签所对应的第一累计数量;
22、根据m个语种标签中每个语种标签所对应的第一累计数量,生成资源语种特征分布。
23、在一种可能的设计中,在本技术实施例的另一方面的第一种实现方式中,
24、生成模块,具体用于对每个关联资源所对应的至少一个语种标签进行并集处理,得到第一语种标签集;
25、针对第一语种标签集中的每个语种标签,获取具有相同语种标签的关联资源集;
26、针对第一语种标签集中的每个语种标签,获取关联资源集中每个关联资源的第一相关参数,其中,第一相关参数包括以下一项或多项:关联资源与目标搜索文本的相似度,关联资源的播放热度;
27、针对第一语种标签集中的每个语种标签,根据关联资源集中每个关联资源的第一相关参数,计算得到语种概率值;
28、根据第一语种标签集中每个语种标签所对应的语种概率值,生成资源语种特征分布。
29、在一种可能的设计中,在本技术实施例的另一方面的第一种实现方式中,
30、生成模块,具体用于将目标搜索文本划分为字符序列,其中,字符序列包括t个字符,t为大于或等于1的字符;
31、采用字符词典对字符序列中的每个字符进行匹配,得到t个字符编码向量,其中,每个字符编码向量对应于一个字符,且,每个字符编码向量包括n个元素,字符词典包括n个预设字符;
32、对t个字符编码向量中对应位置上的元素进行或运算,得到字符特征分布。
33、在一种可能的设计中,在本技术实施例的另一方面的第一种实现方式中,
34、识别模块,具体用于基于资源语种特征分布,通过语种识别模型所包括的资源语种网络,获取资源语种特征向量;
35、基于字符特征分布,通过语种识别模型所包括的文本语种网络,获取文本特征向量;
36、根据资源语种特征向量以及文本特征向量,生成目标特征向量;
37、基于目标特征向量,通过语种识别模型所包括的语种分类输出网络,获取语种概率分布;
38、根据语种概率分布确定语种识别结果。
39、在一种可能的设计中,在本技术实施例的另一方面的第一种实现方式中,
40、识别模块,具体用于基于资源语种特征分布,通过资源语种网络所包括的语种向量映射关系,获取资源语种特征表示,其中,资源语种网络属于语种识别模型;
41、基于资源语种特征表示,通过资源语种网络所包括的全连接层,获取资源语种特征向量。
42、在一种可能的设计中,在本技术实施例的另一方面的第一种实现方式中,
43、识别模块,具体用于基于字符特征分布,通过文本语种网络所包括的字符向量映射关系,获取字符嵌入表示,其中,文本语种网络包含于语种识别模型;
44、基于字符嵌入表示,通过文本语种网络所包括的文本编码网络,获取文本深度表示;
45、基于文本深度表示,通过文本语种网络所包括的全连接层,获取文本特征向量。
46、在一种可能的设计中,在本技术实施例的另一方面的第一种实现方式中,
47、获取模块,还用于获取针对目标对象的q个历史资源,其中,目标对象为输入目标搜索文本的对象,q个历史资源为目标对象在历史时段内触达过的资源,每个历史资源具有已标注的至少一个语种标签,q为大于或等于1的整数;
48、生成模块,还用于根据每个历史资源所对应的至少一个语种标签,生成对象语种特征分布,其中,对象语种特征分布表示q个历史资源属于m个语种标签的分布情况;
49、识别模块,具体用于基于资源语种特征分布、字符特征分布以及对象语种特征分布,通过语种识别模型确定语种识别结果。
50、在一种可能的设计中,在本技术实施例的另一方面的第一种实现方式中,
51、生成模块,具体用于根据每个历史资源所对应的至少一个语种标签,统计m个语种标签中每个语种标签所对应的第二累计数量;
52、根据m个语种标签中每个语种标签所对应的第二累计数量,生成对象语种特征分布。
53、在一种可能的设计中,在本技术实施例的另一方面的第一种实现方式中,
54、生成模块,具体用于对每个历史资源所对应的至少一个语种标签进行并集处理,得到第二语种标签集;
55、针对第二语种标签集中的每个语种标签,获取具有相同语种标签的历史资源集;
56、针对第二语种标签集中的每个语种标签,获取历史资源集中每个历史资源的第二相关参数,其中,第二相关参数包括以下一项或多项:历史资源的播放完成度,历史资源的播放间隔时长;
57、针对第二语种标签集中的每个语种标签,根据历史资源集中每个历史资源的第二相关参数,计算得到语种概率值;
58、根据第二语种标签集中每个语种标签所对应的语种概率值,生成对象语种特征分布。
59、在一种可能的设计中,在本技术实施例的另一方面的第一种实现方式中,
60、识别模块,具体用于基于资源语种特征分布,通过语种识别模型所包括的资源语种网络,获取资源语种特征向量;
61、基于字符特征分布,通过语种识别模型所包括的文本语种网络,获取文本特征向量;
62、基于对象语种特征分布,通过语种识别模型所包括的对象语种网络,获取对象语种特征向量;
63、根据资源语种特征向量、文本特征向量以及对象语种特征向量,生成目标特征向量;
64、基于目标特征向量,通过语种识别模型所包括的语种分类输出网络,获取语种概率分布;
65、根据语种概率分布确定语种识别结果。
66、在一种可能的设计中,在本技术实施例的另一方面的第一种实现方式中,
67、识别模块,具体用于基于对象语种特征分布,通过对象语种网络所包括的语种向量映射关系,获取对象语种特征表示,其中,对象语种网络属于语种识别模型;
68、基于对象语种特征表示,通过对象语种网络所包括的全连接层,获取对象语种特征向量。
69、在一种可能的设计中,在本技术实施例的另一方面的第一种实现方式中,语种识别装置还包括发送模块;
70、获取模块,具体用于接收终端发送的资源搜索请求,其中,资源搜索请求携带目标搜索文本;
71、根据资源搜索请求,获取目标搜索文本;
72、发送模块,用于根据资源语种特征分布以及字符特征分布,确定语种识别结果之后,响应资源搜索请求,向终端发送与语种识别结果匹配的资源搜索结果,以使终端显示资源搜索结果。
73、本技术另一方面提供一种语种识别装置,包括:
74、获取模块,用于获取目标搜索文本;
75、获取模块,还用于根据目标搜索文本,获取针对目标对象的q个历史资源,其中,目标对象为输入目标搜索文本的对象,q个历史资源为目标对象在历史时段内触达过的资源,每个历史资源具有已标注的至少一个语种标签,q为大于或等于1的整数;
76、生成模块,用于根据每个历史资源所对应的至少一个语种标签,生成对象语种特征分布,其中,对象语种特征分布表示q个历史资源属于m个语种标签的分布情况,m为大于1的整数;
77、生成模块,还用于根据目标搜索文本生成字符特征分布,其中,字符特征分布表示目标搜索文本针对各个预设字符的分布情况;
78、识别模块,用于根据对象语种特征分布以及字符特征分布,确定语种识别结果。
79、在一种可能的设计中,在本技术实施例的另一方面的第一种实现方式中,
80、获取模块,还用于根据目标搜索文本获取k个关联资源,其中,每个关联资源具有已标注的至少一个语种标签,k为大于或等于1的整数;
81、生成模块,还用于根据每个关联资源所对应的至少一个语种标签,生成资源语种特征分布,其中,资源语种特征分布表示k个关联资源属于m个语种标签的分布情况;
82、识别模块,具体用于基于资源语种特征分布、字符特征分布以及对象语种特征分布,通过语种识别模型确定语种识别结果。
83、本技术另一方面提供一种计算机设备,包括存储器和处理器,存储器存储有计算机程序,处理器执行计算机程序时实现上述各方面的方法。
84、本技术的另一方面提供了一种计算机可读存储介质,其上存储有计算机程序,计算机程序被处理器执行时实现上述各方面的方法。
85、本技术的另一个方面,提供了一种计算机程序产品,包括计算机程序,该计算机程序被处理器执行时实现上述各方面的方法。
86、从以上技术方案可以看出,本技术实施例具有以下优点:
87、本技术实施例中,提供了一种基于文本的语种识别方法,获取目标搜索文本,然后根据目标搜索文本获取k个关联资源,再根据每个关联资源所对应的至少一个语种标签,生成资源语种特征分布,基于此,可根据目标搜索文本生成字符特征分布,最后,根据资源语种特征分布以及字符特征分布,确定语种识别结果。通过上述方式,利用目标搜索文本,从资源平台中获取与目标搜索文本相关的k个关联资源,这些关联资源具有一个或多个语种标签。因此,基于这些关联资源的语种标签,并结合目标搜索文本,能够为资源搜索提供更加可靠的语种线索,从而有利于提升语种识别的准确性。
- 还没有人留言评论。精彩留言会获得点赞!