一种基于轻量级卷积神经网络的金蝉若虫夜间检测方法
1.本发明涉及农业养殖领域,尤其涉及一种基于轻量级卷积神经网络的金蝉若虫夜间检测方法。
背景技术:
2.金蝉属于蝉科类昆虫,其生长发育历经虫卵、若虫、成虫三个时期。每年夏季虫卵开始孵化,若虫落到地面并潜入土中,经过3~5年成长后钻出地面,爬到树上羽化为成虫,交配产卵后死去,进入下一轮循环,日常俗称的知了龟或知了猴指的就是准备羽化的金蝉成熟若虫。一方面,金蝉作为一种农林害虫,其幼虫和成虫都从树木中吸取汁液为生,成虫还会将产卵器插入树枝之中产卵导致树枝枯死,危害到树木的健康成长。但另一方面,金蝉体内富含脂肪酸、氨基酸,提供多种人体所需的微量元素,起到降低胆固醇、改善内分泌、预防心血管疾病等作用,具备较高的食用及药用价值,越来越受到人们的青睐。作为新兴的养殖项目,金蝉养殖正在我国各个地区正广泛开展。
3.近年来随着深度学习技术的兴起,卷积神经网络在现代农业中得到了广泛应用。图像目标检测是指从图像中定位感兴趣目标、准确判断其类别,并预测出每个目标的边界框。目前,基于卷积神经网络的目标检测技术主要分为两类:一是以faster-rcnn代表的两阶段算法。这类算法首先生成一系列作为样本的候选框,再通过卷积神经网络进行样本分类,在消耗部分检测时间的基础上提升检测精度。另一类是以yolo和ssd为代表的单阶段算法。单阶段检测不需要提取候选框,直接将整张原始图像作为输入,回归出图像中病虫害的具体位置和类别,在小幅牺牲检测精度的基础上显著提升检测速度。
4.ssd(single shot multibox detector)是一种应用广泛的高性能单阶段目标检测模型,综合了yolo的回归思想和faster-rcnn的anchor boxes机制,加入了rpn网络的特征金字塔的检测方式,较好均衡了检测精度和检测速度。原始ssd模型以vgg16作为骨干网络对图片进行特征提取,但vgg16参数量庞大,模型大小达到500mb,模型计算量达到30.49gflops,难以部署在嵌入式系统中。mobilenet是一种兼备检测精度和速度的轻量型神经网络,其通过构建深度可分离卷积(depthwise separable convolution)改变网络的计算方式降低网络参数量的同时提高模型的检测速度,可替代vgg16作为ssd的骨干特征提取网络,形成mobilenet-ssd模型结构。
技术实现要素:
5.本发明的目的在于提供一种基于轻量级卷积神经网络的金蝉若虫夜间检测方法,在保持较高识别性能的同时,大幅减少模型大小以及计算量,以适用于资源受限的嵌入式实时系统,为金蝉的人工养殖以及机器人的金蝉捕捉奠定良好的基础。
6.为实现上述目的,本发明提供如下技术方案:一种基于轻量级卷积神经网络的金蝉若虫夜间检测方法,包括如下步骤:
7.1)模拟机器人近距离检测金蝉若虫目标,以自然环境中拍摄和从互联网上收集的
夜间树上金蝉若虫图像为研究对象,对原始数据集进行数据扩充,将数据集使用labelimg工具对图中目标进行标记,并按照80%、20%的比例随机拆分为训练集和验证集,并按照pascal voc数据集的格式进行存储;
8.2)基于mobilenet-ssd模型结构,以减少网络深度及网络宽度的思路进行模型结构精简改进,设计三种初始模型结构;
9.3)利用建立的金蝉若虫数据训练集对设计的三种初始模型分别进行训练参数设置,多次迭代得到训练后的模型;
10.4)将验证集图像输入训练后的模型中进行性能检验,并择优选定方案,获得适用于夜间树上金蝉若虫检测的轻量级目标检测模型;
11.5)机器人夜间近距离对树干区域进行拍摄,将拍摄图像输入至计算机中,利用上述步骤的检测模型进行检测,如果树干上有金蝉若虫存在,则输出的图像上叠加各个目标的位置检测框;如果树干上没有金蝉若虫,则输出返回原图。
12.优选的,所述步骤2)中,三种初始模型分别为模型m0,模型m1,模型m2,其中模型m0是在mobilenet-ssd原始模型基础上,通过删除骨干网络的3
×
3、2
×
2、1
×
1这3个小尺度卷积层结构,减小网络宽度,增加部分中高层卷积层的深度得到;模型m1是在模型m0的基础上,进一步减少网络宽度得到;模型m2是在模型m1的基础上,减少部分中高层卷积层深度得到的。
13.优选的,所述模型m0的设计步骤包括:
14.①
、删除原始mobilenet-ssd模型骨干网络中3
×
3、2
×
2、1
×
1这3个小尺度卷积层结构,以减小模型大小及计算量;
15.②
、削减网络宽度,将原始mobilenet-ssd模型的第1卷积层的输出通道数由32减少到24,同时将后面的卷积层2,3,5,9,13的输出通道也分别减少至48,48,96,192和384;
16.③
、增加部分中高层卷积层的深度,特征图大小为38
×
38、19
×
19和10
×
10的卷积层上各自进行了4次卷积运算,得到模型m0。
17.优选的,所述模型m0的结构为:卷积层1~2对原模型150
×
150的输出特征图进行了两次卷积,输出通道数分别减少至24、48;卷积层3~4对原模型75
×
75的输出特征图进行了两次卷积,输出通道数从原来的128减少为48;卷积层5~8对原模型38
×
38的输出特征图进行了四次卷积,卷积层深度由2层增加到4层,卷积层宽度由256减少为96;卷积层9~12对原模型19
×
19的输出特征图进行了四次卷积,卷积层深度由6层减少到4层,卷积层宽度由512减少为192;卷积层13~17对原模型10
×
10的输出特征图进行了四次卷积,卷积层深度由2层增加到4层,卷积层宽度由1024减少为384。
18.优选的,模型m1在模型m0的结构基础上,继续减少网络宽度,将模型m0第1卷积层的输出通道数由24减少到16,将卷积层2、5、9、13的输出通道数也分别减少至32、64、128、256。
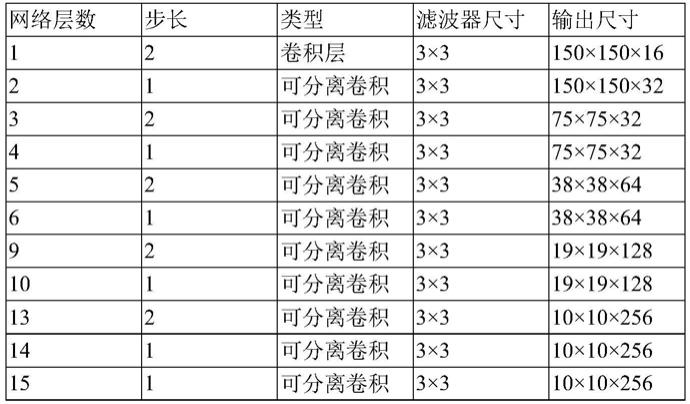
19.优选的,模型m2在模型m1的基础上,保持模型m1总体架构不变,将模型m1特征图大小为38
×
38和19
×
19的卷积层数由4层减少为2层,此时骨干特征网络由17层减少为13层。
20.有益效果:
21.本发明所揭示的一种基于卷积神经网络的金蝉若虫检测模型构建方法,从模拟机器人的近距离金蝉若虫目标检测出发,为适应模型尺寸小型化和计算过程轻量化,在
mobilenet-ssd模型框架结构基础上,结合单一目标检测任务对模型结构进行改进设计,在大幅减少模型大小以及其计算量的同时将模型性能保持在一个较高的水平,有助于将模型部署在资源受限的嵌入式系统中,为金蝉的人工养殖以及机器人的金蝉捕捉奠定良好的基础。
附图说明
22.图1是原始图像数据的增强效果示例;
23.图2是原始mobilenet-ssd的结构图;
24.图3是模型m0的结构图;
25.图4是模型m1的结构图;
26.图5是模型m2的结构图;
27.图6是训练集上的四种模型的损失函数曲线;
28.图7是验证集上的四种模型的损失函数曲线;
29.图8是验证集上的四种模型的p-r曲线;
30.图9是验证集夜间图片检测效果示例;
31.图10是另外采集的白天图像检测效果示例。
具体实施方式
32.下面结合附图所示内容,对本发明的技术内容进行详细阐述。
33.本发明所揭示的一种基于卷积神经网络的金蝉若虫检测模型构建方法,包括如下步骤:
34.1)模拟机器人近距离检测金蝉若虫目标,以自然环境中拍摄和从互联网上收集的夜间树上金蝉若虫图像为研究对象,对原始数据集进行数据扩充,将数据集使用labelimg工具对图中目标进行标记,并按照80%、20%的比例随机拆分为训练集和验证集,并按照pascal voc数据集的格式进行存储。
35.2)由于图像为大都为近距离拍摄,图像中金蝉若虫大小近似且目标类别单一,所需学习特征不多,为方便模型在资源受限的移动终端上的部署,直接在mobilenet-ssd模型基础上进行优化设计,以减少网络深度及网络宽度的思路进行模型结构精简改进,设计三种初始模型结构;
36.三种初始模型分别为模型m0,模型m1,模型m2,其中模型m0是在mobilenet-ssd原始模型基础上,通过删除骨干网络的3
×
3、2
×
2、1
×
1这3个小尺度卷积层结构,减小网络宽度,增加部分中高层卷积层的深度得到;模型m1是在模型m0的基础上,进一步减少网络宽度得到;模型m2是在模型m1的基础上,减少部分中高层卷积层深度得到的。
37.3)利用建立的金蝉若虫数据训练集对设计的三种初始模型分别进行训练参数设置,多次迭代得到训练后的模型;
38.4)将验证集图像输入训练后的模型中进行性能检验,并择优选定方案,获得适用于夜间树上金蝉若虫检测的轻量级目标检测模型;
39.5)机器人夜间近距离对树干区域进行拍摄,将拍摄图像输入至计算机中,利用上述步骤的检测模型进行检测,如果树干上有金蝉若虫存在,则输出的图像上叠加各个目标
的位置检测框;如果树干上没有金蝉若虫,则输出返回原图。
40.所述模型m0是在原始mobilenet-ssd模型的基础上设计而得的,原始mobilenet-ssd模型结构在conv12、conv14、conv15、conv16、conv17、conv18层上进行边框回归和分类,其对应的分辨率分别为19
×
19、10
×
10、5
×
5、3
×
3、2
×
2、1
×
1,其中后3层的小特征图主要用于大目标物体检测,而具体到本发明中目标大小适中的客观实际,在调节过程中如果去除这3层则对检测效果几乎没有影响。
41.故而在设计模型m0时,首先删除原始mobilenet-ssd模型骨干网络中3
×
3、2
×
2、1
×
1这3个小尺度卷积层结构,以减小模型大小及计算量;
42.因为模型的参数量大小及其计算量主要是由网络的宽度决定的,单一目标检测所须学习的特征大幅减少,因此削减网络宽度,将原始mobilenet-ssd模型的第1卷积层的输出通道数由32减少到2,同时将后面的卷积层2,3,5,9,13的输出通道也分别减少至48,48,96,192和384;
43.在减少网络宽度的同时为保持模型的非线性表达能力,故而增加部分中高层卷积层的深度,经过反复调节,在特征图大小为38
×
38、19
×
19和10
×
10的卷积层上各自进行了4次卷积运算,得到模型m0。
44.所述模型m0的结构如图3所示:卷积层1~2对原模型150
×
150的输出特征图进行了两次卷积,输出通道数分别减少至24、48;卷积层3~4对原模型75
×
75的输出特征图进行了两次卷积,输出通道数从原来的128减少为48;卷积层5~8对原模型38
×
38的输出特征图进行了四次卷积,卷积层深度由2层增加到4层,卷积层宽度由256减少为96;卷积层9~12对原模型19
×
19的输出特征图进行了四次卷积,卷积层深度由6层减少到4层,卷积层宽度由512减少为192;卷积层13~17对原模型10
×
10的输出特征图进行了四次卷积,卷积层深度由2层增加到4层,卷积层宽度由1024减少为384。
45.模型m0的检测网络部分只针对19
×
19、10
×
10和5
×
5这种3尺度特征图进行目标检测。在特征图上的每个像素点处,生成不同宽高比的k(4、6、6)个默认检测框(default box),模型预测的边界框(bounding boxes)就是以这些默认检测框为基础进行训练的。默认检测框的总数为19
×
19
×
4+10
×
10
×
6+5
×5×
6=2194。经测算,m0参数个数大幅数减少到84.5万个,模型大小缩减至3.23mb(million bytes,兆字节),模型计算量为255.41mflops(million floating-point operations,mflops,百万次浮点运算)。
46.而对于模型m1则是在模型m0的结构基础上,继续减少网络宽度,将模型m0第1卷积层的输出通道数由24减少到16,将卷积层2、5、9、13的输出通道数也分别减少至32、64、128、256。模型结构如图4所示,经测算,m1的参数继续减少到39.5万个,模型大小进一步减少至1.51mb,模型计算量继续减少到125.57mflops。
47.在获取模型m1的基础上,为验证削减网络宽度的同时须增加中高层的卷积层深度的必要性,在m1的基础上设计出模型m2以进行比较,即保持模型m1总体架构不变,仅将m1特征图大小为38
×
38和19
×
19的卷积层数由4层减少为2层,此时骨干特征网络由17层减少为13层,得到模型m2。经测算,其参数个数进一步减少到38.3万个,模型大小为1.46mb,模型计算量为减少到99.8mflops。
48.具体实施例
49.下面以具体的试验实例对本发明的内容进行详细描述。
50.数据集采用了自然环境下的金蝉若虫图片366张,图像采集地点为江苏大学校园内,由于金蝉若虫是在夏天18-22时开始钻出地面并爬上附近树干准备蜕壳,根据这一点特性,在距离地面1米高的树干上事先围上一圈光滑透明胶带,阻止其继续向上攀爬,手持手机在距离树干大约0.5~1米处,模拟树干附近的机器人进行近距离拍摄。连续数天对不同树干上的金蝉若虫进行拍摄,拍摄时间包括了晴天的傍晚、夜间,拍摄角度包括正面、侧面,图片中金蝉数量不等。为丰富数据来源的多样性,将居民小区绿化带内以同样方式采集以及互联网下载的共180张图片作为补充,然后将这些数据合并,原始数据集一共包含图片546张。为了减小模型的过拟合并增加图片样本数,这里采用了数据增强技术。数据增强就是在样本中加入随机噪声、干扰数据或通过一定规则产生新的合成样本。本发明采用开源的python库imgaug(https://github.com/aleju/imgaug)对金蝉若虫图片进行数据增强。增强的方法包括水平镜像翻转、垂直镜像翻转、随机截取、加噪声、改变亮度和对比度等,并将尺寸归一化至300
×
300像素。对原始图片,随机选取上述数据增强技术的一种对图像进行增强。经过数据增强和筛检后,剔除了部分不清楚的图片,最终的数据集包含1030张金蝉若虫图片。将上述数据集使用labelimg工具对目标进行标记,并将数据集按照80%、20%的比例随机拆分为训练集和验证集。训练集有金蝉若虫图片824张,含边框的标注样本2155个。验证集有金蝉若虫图片206张,含边框的标注样本573个,按照pascal voc数据集格式进行存储。这样的数据集明显偏小,后续借助于voc2007数据集进行迁移学习。
51.如图1所示为原始图像数据的增强效果示例,其中标号1是原图;标号2为1的水平翻转;标号3为1的增强对比度;标号4为1的随机截取。
52.ssd网络模型基本工作过程如下:首先,ssd通过骨干网络对输入图像进行特征提取;接着,从骨干网络的不同卷积层选取不同大小的特征图,再从不同大小的特征图中预测出多个边界框;最后通过非极大值抑制(non-maximum suppression,nms)确定图片中待测目标的位置框和类别。在ssd网络中,尺寸大的浅层特征图用来预测小目标,尺寸小的深层特征图用来预测大的目标。但原始ssd模型以vgg16作为骨干网络对图片进行特征提取,vgg16参数量庞大,模型大小达到了500mb,模型计算量达到30.49gflops,无法应用在嵌入式系统中,而mobilenet-ssd较好的平衡了检测速度与准确率,比较适于部署在嵌入式系统中,mobilenet-ssd的骨干网络参数参见表1。
53.表1:mobilenet-ssd的骨干网络参数
54.网络层数步长类型滤波器尺寸输出尺寸12卷积层3
×
3150
×
150
×
3221可分离卷积3
×
3150
×
150
×
6432可分离卷积3
×
375
×
75
×
12841可分离卷积3
×
375
×
75
×
12852可分离卷积3
×
338
×
38
×
25661可分离卷积3
×
338
×
38
×
25672可分离卷积3
×
319
×
19
×
51281可分离卷积3
×
319
×
19
×
51291可分离卷积3
×
319
×
19
×
512101可分离卷积3
×
319
×
19
×
512
111可分离卷积3
×
319
×
19
×
512121可分离卷积3
×
319
×
19
×
512132可分离卷积3
×
310
×
10
×
1024141可分离卷积3
×
310
×
10
×
1024152可分离卷积3
×
35
×5×
512162可分离卷积3
×
33
×3×
256172可分离卷积3
×
32
×2×
256182可分离卷积3
×
31
×1×
128
55.如表1所示,mobilenet-ssd的骨干网络中除第一个卷积层conv1外,其余卷积层都采用了深度可分离卷积,其原理如下:对于一个卷积层,假设输入特征图为h
×w×
m,其中m为输入通道个数,h为输入特征图的高,w为输入特征图的宽。以3
×
3卷积核为例,传统的卷积计算量为n
×h×w×m×
9。对于深度可分离卷积,其计算量分两个部分:一是深度卷积,其计算量为h
×w×m×
9;另一部分为逐点卷积,其计算量为h
×w×m×
n,所以深度可分离卷积的计算量与传统卷积的计算量之比可以表示为:
[0056][0057]
其中,n为输出特征图数量,通常n》》9。因此,采用深度可分离卷积的计算量大为缩减,约为传统卷积的1/9。因此,本发明在后续模型设计过程中,在目标检测的分类层和预测框的回归层中都使用深度可分离卷积代替传统的3
×
3卷积,有效减少模型计算量。
[0058]
图2为表1对应的原始mobilenet-ssd模型的结构图,为了应对不同大小的目标,原始mobilenet-ssd结构中选取了6种不同尺度的特征图进行目标检测,大小分别为19
×
19、10
×
10、5
×
5、3
×
3、2
×
2、1
×
1等6个不同尺度。对于不同尺度特征图,借鉴faster-rcnn的anchor机制,特征图上的每个点分别选择了k(4、6、6、6、6、6)个默认检测框来进行目标预测,则每幅图像上检测框总数为19
×
19
×
4+10
×
10
×
6+5
×5×
6+3
×3×
6+2
×2×
6+1
×1×
6=2278。
[0059]
一般而言,网络深度定义为网络的层数,网络宽度定义为每层的通道数。通常来说,更深的网络具有更好的非线性表达能力,可以学习更复杂的特征。网络的宽度决定了可以学习到的特征数目,也主导了模型大小及其计算量。一方面如果宽度不够,则特征不够充分,网络性能受限。另一方面,如果宽度太宽则会提取过多的重复特征,对网络性能的提高没有实质性贡献,反而加大模型计算量。因此,在保持网络性能基本不变的前提下,设计出适用的精简结构也是当下检测模型轻量化研究的方向之一。
[0060]
本发明任务为模拟机器人的单一目标近距离检测,由于图像大都为近距离拍摄,图像中金蝉若虫大小近似且目标类别单一,所需学习特征不多,为方便模型在资源受限的移动终端上的部署,因此本发明基于适当减少网络深度及网络宽度的思路对mobilenet-ssd结构进行改进设计,提出3种初始模型结构:
[0061]
模型m0结构如图3所示,内部参数如表2所示,具体结构为:卷积层1~2对大小为150
×
150的输出特征图进行了两次卷积,输出通道数分别从原来的32、64减少为24、48;卷积层3~4对大小为75
×
75的输出特征图进行了两次卷积,输出通道数从原来的128减少为48;卷积层5~8对大小为38
×
38的输出特征图进行了四次卷积,相对于图2,卷积层深度由2
层增加到4层,卷积层宽度由256减少为96;卷积层9~12对大小为19
×
19的输出特征图进行了四次卷积,相对于图2,卷积层深度由6层减少到4层,卷积层宽度由512减少为192;卷积层13~16对大小为10
×
10的输出特征图进行了四次卷积,相对于图2,卷积层深度由2层增加到4层,卷积层宽度由1024减少为384。
[0062]
表2:模型m0的骨干网络参数
[0063]
网络层数步长类型滤波器尺寸输出尺寸12卷积层3
×
3150
×
150
×
2421可分离卷积3
×
3150
×
150
×
4832可分离卷积3
×
375
×
75
×
4841可分离卷积3
×
375
×
75
×
4852可分离卷积3
×
338
×
38
×
9661可分离卷积3
×
338
×
38
×
9671可分离卷积3
×
338
×
38
×
9681可分离卷积3
×
338
×
38
×
9692可分离卷积3
×
319
×
19
×
192101可分离卷积3
×
319
×
19
×
192111可分离卷积3
×
319
×
19
×
192121可分离卷积3
×
319
×
19
×
192132可分离卷积3
×
310
×
10
×
384141可分离卷积3
×
310
×
10
×
384151可分离卷积3
×
310
×
10
×
384161可分离卷积3
×
310
×
10
×
384172可分离卷积3
×
35
×5×
384
[0064]
m0的检测网络部分只针对19
×
19、10
×
10和5
×
5这种3尺度特征图进行目标检测。在特征图上的每个像素点处,生成不同宽高比的k(4、6、6)个默认检测框(default box),模型预测的边界框(bounding boxes)就是以这些默认检测框为基础进行训练的。默认检测框的总数为19
×
19
×
4+10
×
10
×
6+5
×5×
6=2194。经测算,m0参数个数大幅数减少到84.5万个,模型大小缩减至3.23mb(million bytes,兆字节),模型计算量为255.41mflops(million floating-point operations,mflops,百万次浮点运算)。
[0065]
模型m1结构如图4所示,其内部参数如表3所示,在获取模型m0的基础上,为进一步考察比较,继续采用减少网络宽度的思路,将m0第1卷积层的输出通道数由24减少到16。与此相适应,将卷积层2、5、9、13的输出通道数也分别减少至32、64、128、256,并将此模型标识为m1。经测算,m1的参数继续减少到39.5万个,模型大小进一步减少至1.51mb,计算量继续减少到125.57mflops。
[0066]
表3模型m1的内部参数
[0067]
网络层数步长类型滤波器尺寸输出尺寸12卷积层3
×
3150
×
150
×
1621可分离卷积3
×
3150
×
150
×
3232可分离卷积3
×
375
×
75
×
32
41可分离卷积3
×
375
×
75
×
3252可分离卷积3
×
338
×
38
×
6461可分离卷积3
×
338
×
38
×
6471可分离卷积3
×
338
×
38
×
6481可分离卷积3
×
338
×
38
×
6492可分离卷积3
×
319
×
19
×
128101可分离卷积3
×
319
×
19
×
128111可分离卷积3
×
319
×
19
×
128121可分离卷积3
×
319
×
19
×
128132可分离卷积3
×
310
×
10
×
256141可分离卷积3
×
310
×
10
×
256151可分离卷积3
×
310
×
10
×
256161可分离卷积3
×
310
×
10
×
256172可分离卷积3
×
35
×5×
256
[0068]
模型m2结构如图5所示,其内部参数如表4所示,在获取模型m1的基础上,为验证削减网络宽度的同时须增加卷积层深度的必要性,在m1的基础上设计出模型m2以进行比较,即保持模型m1总体架构不变,仅将m1特征图大小为38
×
38和19
×
19的卷积层数由4层减少为2层,此时骨干特征网络由17层减少为13层,并将此模型标识为m2。经测算,其参数个数进一步减少到38.3万个,模型大小为1.46mb,模型的计算量为减少到99.8mflops。
[0069]
表4模型m2的内部参数
[0070][0071][0072]
下面对几种模型进行试验,本发明试验的软件环境为ubuntu 16.04lts 64位系统,采用目前流行的pytorch(https://pytorch.org/)深度学习开源框架。计算机内存为16gb,搭载intel core i5-8300 cpu,gpu采用英伟达的gtx1050ti对深度学习模型进行加速。
[0073]
本发明中直接利用小样本数据集训练会导致的模型收敛慢及模型不稳定等问题。
因此,本发明借助于voc2007数据集下预训练好的模型,通过迁移学习来适应金蝉目标检测任务,以节约模型训练成本并加速模型收敛。试验中训练和测试数据的批次大小都设置为32,遍历一次训练集中的所有图片称作一轮迭代(epoch)。训练模型时采用了随机梯度下降优化算法(stochastic gradient descent,sgd),动量(momentum)设置为0.9,初始学习率设置为0.01,学习率衰减策略为余弦退火策略。具体训练采用anaconda环境,框架是pytorch1.0,训练迭代一共200轮。
[0074]
评价目标检测模型性能的主要指标有f1分数,平均精确率(ap,average precision),平均交并比(average iou,intersection over union)。首先,定义混淆矩阵中的变量:tp,真实值为正且预测也为正的数量;tn,真实值为负且预测也为负的数量;fp,真实值为负但预测为正的数量;fn,真实值为正,但预测为负的数量。
[0075]
准确率(precision)定义如下:
[0076][0077]
查准率是分类器预测的正样本中预测正确的比例,取值范围为[0,1],取值越大表示模型预测能力越好。
[0078]
查全率(recall)定义如下:
[0079][0080]
查全率又称召回率,是分类器预测正确的正样本占所有正样本的比例,取值范围为[0,1],取值越大模型预测能力越好。
[0081]
f1分数(f1 score)定义如下:
[0082][0083]
平均准确率(ap)的定义如下:
[0084][0085]
交并比(iou)用来评估预测框的准确率,其定义如下:
[0086][0087]
其中a定义为网络给出的预测框,b定义为物体的真实框,本发明中iou阈值设为0.5。
[0088]
利用建立的金蝉若虫数据集对原始mobilenet-ssd模型与所设计的3种模型进行训练,这四个检测模型在训练集和验证集的损失函数曲线分别如图6、图7所示。四个模型在训练集和验证集上都有不错的表现,随着循环次数的增加模型逐渐收敛,在循环次数达到180左右时模型在训练集和验证集上都达到了收敛,其中原始mobilenet-ssd模型略好于改进模型m0、m1。
[0089]
图8给出了四种模型的p-r曲线,p-r曲线刻画了模型准确率和召回率之间的关系,准确率p和召回率r往往是一对矛盾的度量,而平均准确率ap是同时衡量p、r的指标,为p-r
曲线下面的面积,用来衡量金蝉若虫类别的检测效果。为比较四种模型的性能,图8中画出了平衡点(break-even point,bep)曲线,平衡点是指p-r曲线上准确率和召回率相等时的点。可以看出,模型m2的平衡点约0.9,模型m0、m1的平衡点互相重合(0.93),这表明m0、m1的性能非常接近,且均略优于m2。原始mobilenet-ssd模型的平衡点约0.96,略优于模型m0、m1。
[0090]
表5综合比较了m0、m1、m2和原始mobilenet-ssd模型的参数大小、总运算量、平均准确率(ap)、平均交并比(average iou)和f1分数,对比结果参见表5。
[0091]
表5模型的参数及性能比较
[0092][0093]
由表5可知,原始mobilenet-ssd模型在平均交并比这个指标上表现最好,比模型m0、m1分别高了约1.5、1.9个百分点。这表明原始模型在定位精度上要略优于m0、m1,原因主要在于原始模型选取了6种不同尺度的特征图对目标进行预测,多于m0、m1的3种尺度,但收效甚微。在平均准确率ap指标上,原始mobilenet-ssd模型仅仅比m0、m1和m2分别高了0.1、0.3和0.75个百分点;在f1分数指标上,原始模型仅比m0、m1和m2分别高了0.24、0.37和0.8个百分点。总体上看,模型m0、m1的性能与原始模型基本相当,差距并不明显。但在模型计算量上,m0、m1要远优于原始模型,其中m1的计算量仅为125.57mflops,相比于原始模型的1130mflops,计算量减少至原来的约1/9;在模型大小上,m0、m1也远小于原始模型,其中m1仅为1.51mb,相比于原始模型的15.2mb,大幅减少至原来的约1/10。
[0094]
如表5所示,模型m2大小仅为1.46mb,计算量也仅为99.8mflops,都是所有模型中最小的,但在平均交并比指标上仅为81.71%,比原始模型低了约3.7个百分点,定位精度下降比较明显,而且其余指标也均为最低。原因分析在于模型m2在特征图大小为38
×
38和19
×
19卷积层的卷积深度较浅,对于复杂特征的提取不够充分,导致性能指标都有些下滑。
[0095]
纵观表5,针对近距离目标检测,本文设计的模型m0、m1在精度指标大体持平的前提下,其模型大小以及运算量优势明显,其中模型m1在检测精度与速度上具有更为均衡的综合性能,更符合实际场景中的应用需求,因此将其作为本发明最终的模型设计结果。
[0096]
表6给出了模型m1与原始模型在gpu和上cpu的检测速度对比。一般移动机器人主要配置普通cpu笔记本电脑,本发明gpu采用英伟达gtx1050ti,cpu型号为intel core i5-8300,批次大小设定为1,统计两种平台上的处理速度。
[0097]
表6不同平台下的检测速度比较
[0098][0099]
由表6可知,gpu的并行加速计算大大提升了检测速度。模型m1的gpu检测速度为
179.30帧/秒,是原mobilenet-ssd的2.58倍;而模型m1的cpu检测速度为6.49帧/秒,是原mobilenet-ssd的4.16倍。由此可见,无论gpu、cpu平台,模型m1显著提高了检测速度,而且cpu平台的处理速度也基本满足实用需求。
[0100]
图9直观显示本发明的模型检测效果,选取了不同数量、姿态、光照、背景、攀爬物等条件下的若干夜间图像,采用模型m1进行测试,图9给出了部分代表性的效果图示。其中,图9(a)中稀疏分布着两只分离的金蝉若虫;图9(b)包含密集多只;图9(c)显示的是侧视环境下的两只粘连目标;图9(d)为不同视角下的拍摄图像,以模拟不同姿态下目标检测;上述图像均光照理想、对比度清晰,检测难度不高。相比之下,图9(e)中目标所在位置处存在一定程度的过度曝光,对比度稍弱一些;图9(f)中金蝉背部附着部分干燥泥土,图9(g)中树干表面与金蝉背部呈现出近似的斑驳状褐色,图8(h)为雨后树干上的金蝉,这三张图片中的金蝉若虫与所在背景区域比较近似,呈现出不同程度的伪装色效果,但模型m1也都能进行成功检测。此外,在其它攀爬物背景上,图9(i)选取了低矮灌木,由于强光照因素目标成像稍显模糊,图9(j)选取了宽大绿色叶片背部上的正处于脱壳状态中金蝉,m1均测试成功。上述结果显示出本发明设计的轻量级模型在诸多场景下都取得较好的目标检测效果。
[0101]
图10所示,为进一步考察模型m1在非夜间环境下的测试效果,另外选取一些白天环境下的场景图像进行检测,其结果如图10所示。与夜晚图像相比,白天环境下的图像背景干扰更为显著。由于白天金蝉已经羽化脱壳飞走,所以可用本文模型检测金蝉空壳,以模拟夏日傍晚时段的金蝉若虫检测。图9(a)与9(b)所示为晴天及雨后树干上的空壳样本,图9(c)所示为白天居民区水泥墙上的空壳样本,模型m1均可成功检测。总体而言,本发明设计的模型具备较好的抗干扰能力,泛化效果总体较好。
[0102]
本发明的技术内容及技术特征已揭示如上,然而熟悉本领域的技术人员仍可能基于本发明的教示及揭示而作种种不背离本发明精神的替换及修饰,因此,本发明保护范围应不限于实施例所揭示的内容,而应包括各种不背离本发明的替换及修饰,并为本专利申请权利要求所涵盖。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1