一种图像处理的方法及相关装置和系统与流程
本发明涉及计算机,尤其涉及一种图像处理的方法及相关装置。
背景技术:
1、视频流的人工智能(artificial intelligence,ai)处理会串行经过多个处理模块,其中,主要包括视频读取模块、模型推理模块、逻辑后处理模块以及业务后处理模块。当前处理模块会处理输入图片以及上一处理模块的输出,从而得到当前处理模块的输出,而图片和元数据在各个处理模块间则通过队列的方式进行交互。
2、由于上述各个处理模块之间是串行地部署于一个计算设备当中,因此,各个视频的处理任务需要基于先进先出(first input first output,fifo)机制进行队列等候。在面对并行处理多路视频的场景时,需要由多个线程(进程)来执行,一路视频由一个线程(进程)负责。
3、而面对多路视频并行处理的场景,这对计算设备的算力开销是巨大的,各个线程(进程)之间的资源竞争剧烈,造成处理性能下降。
技术实现思路
1、本技术提供了一种图像处理的方法及相关装置,用于提高计算设备在进行ai视频处理时的性能。
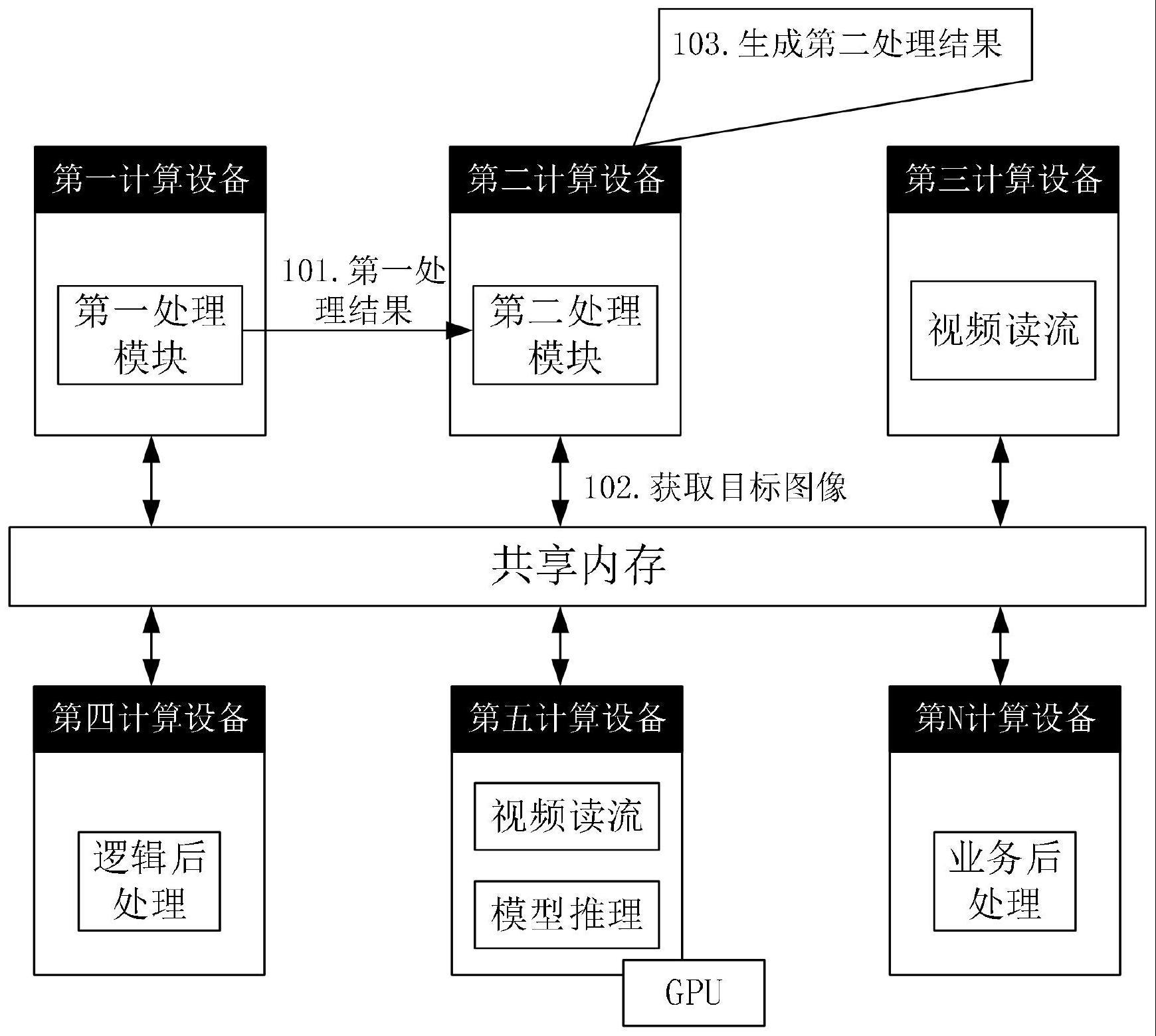
2、第一方面,本技术提供了一种图像处理的方法,该图像处理方法应用于ai视频处理系统,ai视频处理系统包括第一计算设备和第二计算设备在内的多个计算设备,多个计算设备之间建立远程直接内存访问(remote direct memory access,rdma)连接,每个计算设备拥有处理功能(例如设置至少一个处理模块)。这些计算设备的内存构成ai视频处理系统的共享内存,多个计算设备协同工作,共同参与ai视频处理流程。
3、本技术中,通过使用rdma将多个计算设备的内存组成共享内存池,每个计算设备可以从共享内存池中获得目标图片以及前一个计算设备的处理结果,从而可以把完整一个图像处理(单独的静态图像或者视频中的图像帧)任务分解为串行的多个任务,不同的任务分配到不同的计算设备来完成。利用多个计算设备的资源来协同进行视频处理,不再由一个计算设备来独立完成所有的任务,从而减少了单个计算设备的算力开销,实现负载均衡,提高了处理性能。
4、在第一方面的一种可能的实现方式中,ai视频处理需要执行视频读取任务、模型推理任务、逻辑后处理任务以及业务后处理任务,每个任务需要由一个进程(或线程)来执行,即每个进程(或线程)相当于一个处理模块。换句话说,ai视频处理需要经过视频读取模块、模型推理模块、逻辑后处理模块以及业务后处理模块的处理,本技术中,可以将上述模块分布部署于整个ai视频处理系统的各个计算设备中。基于内存的rdma技术可以把不同计算设备的内存连通,形成一个整体的内存池(即本技术的共享内存),不同的模块就可以部署在不同的计算设备,通过多个计算设备的内存池形成数据的共享,则ai视频处理系统中每个计算设备的内存均可以被其他计算设备通过rdma技术所访问。示例性的,第一计算设备中部署有第一处理模块,第二计算设备中部署有第二处理模块,其中,第一处理模块为第二处理模块的上游处理模块。第一计算设备和第二计算设备均可以通过rdma连接从共享内存中获取数据(例如本技术的目标图像)进行处理。需要说明的是,本技术的目标图像,可以是单独的静态图像或者是视频中的图像帧,具体此处不做限定。
5、本技术中,各个处理模块的部署具有较高的灵活性。在实际应用中,可以根据每个计算设备自身的性能、负载或场景需要等因素,来部署处理模块,本技术对此不做限定。例如,第一计算设备中的第一处理模块可以是视频读流模块,第二计算设备中的第二处理模块是模型推理模块;或者,第一计算设备中的第一处理模块可以是逻辑后处理模块,第二计算设备中的第二处理模块是业务后处理模块。另一方面,本技术也不限定计算设备中所部署的处理模块的数量,即一个计算设备中可以部署有一个处理模块,或者,一个计算设备中也可以部署有多个处理模块,本技术对此不做限定。
6、第一计算设备通过rdma技术从ai视频处理系统的共享内存中获取目标图像,并根据其所部署的处理模块来对目标图像进行处理,生成第一处理结果,并将该第一处理结果传递给第二计算设备,由第二计算设备进一步执行下游的处理任务。
7、ai视频处理流程中,上游处理任务的处理结果以及目标图像,会作为下游处理任务的输入。因此,第二计算设备在接收到来自第一计算设备的处理结果(即上游处理任务的处理结果)之后,还需要通过rdma连接从共享内存中获取目标图像。第二计算设备获取到第一处理结果和目标图像之后,进一步执行下游任务,从而生成第二处理结果。
8、另一方面,本技术中的各个处理模块是通过封装成容器,来部署到各个计算设备当中的。所以,各个处理模块之间是解耦状态,从而便可以根据实际场景的需要,灵活地新增或删减处理模块,实现处理模块的热插拔,实现细粒度的业务部署,使得处理任务的分配更加灵活。例如,可以新增任意一个处理模块到当前ai视频处理系统中的计算设备;又例如,也可以新增一个计算设备,来参与到该ai视频处理系统中,从而执行ai视频处理任务。
9、基于第一方面,一种可选的实施方式中,为了第二计算设备能够获取到该目标图像,第一计算设备除了向第二计算设备发送第一处理结果之外,第一计算设备还需要向第二计算设备发送目标图像的指针,目标图像的指针用于指示目标图像在共享内存中的存储地址。第二计算设备获取到目标图像的指针之后,根据指针的指示,查找到目标图像在共享内存中的存储地址,从而获取该目标图像。
10、基于第一方面,一种可选的实施方式中,由于模型推理模块,是需要部署在显卡上的gpu来完成的,换句话说,计算设备需要配置有gpu,才可以用于部署模型推理模块,才能对目标图像执行模型推理任务;而对于视频读取模块、逻辑后处理模块以及业务后处理模块,则是通过中央处理器(central processing unit,cpu)来执行的,不需要gpu的参与,这些模块可以部署于未配置有gpu但配置有cpu的计算设备中,或者,也可以部署于同时配置有gpu和cpu的计算设备中。可选的,第二计算设备中包括cpu而不包括gpu,则第二计算设备中可以用于通过cpu来执行非gpu任务,其中,非gpu任务为不需要gpu参与执行的任务,具体包括视频读取任务、逻辑后处理任务或业务后处理任务。换句话说,第二计算设备可以通过cpu对第一处理结果和目标图像进行非gpu任务的处理,得到第二处理结果,其中,第二处理结果为视频读流任务、逻辑后处理任务或业务后处理任务的处理结果;而第一计算设备中包括gpu,则第一计算设备中即可以用于通过gpu来执行gpu任务,其中,gpu任务为需要gpu参与执行的任务,具体包括模型推理任务,或者,也可以用于通过cpu来执行非gpu任务,第一计算设备通过gpu对目标图像执行模型推理任务,得到第一处理结果。
11、传统的ai视频处理流程中,计算设备是必须要配置有gpu,才能够执行模型推理任务。因此,未配置gpu的计算设备,是不能执行ai视频处理流程的。而本技术中,通过将完整的、串行的ai视频处理流程分配到不同的多个计算设备来完成,因此,仍然可以将视频读取任务、逻辑后处理任务以及业务后处理任务,分配给未配置gpu的计算设备来执行,从而降低了ai视频处理流程的实施条件,让更多的计算设备能够参与到ai视频处理流程中,进一步地提高了ai视频处理的效率。
12、第二方面,本技术提供了一种人工智能ai视频处理系统,ai视频处理系统包括第一计算设备、第二计算设备在内的多个计算设备,多个计算设备之间建立远程直接内存访问rdma连接,多个计算设备的内存通过rdma连接构成ai视频处理系统的共享内存,ai视频处理系统包括:
13、第一计算设备,用于根据目标图像计算生成第一处理结果,将第一处理结果通过rdma连接发送给第二计算设备;
14、第二计算设备,用于通过rdma连接从共享内存中获取目标图像,根据第一处理结果和目标图像生成第二处理结果。
15、基于第二方面,一种可选的实施方式中,ai视频处理系统还包括第三计算设备和第四计算设备;
16、第三计算设备,用于根据对目标图像执行视频读流任务,得到第三处理结果,将第三处理结果通过rdma连接发送给第一计算设备,第一处理结果为第一计算设备对目标图像和第三处理结果执行模型推理任务所得到的,第二处理结果为第二计算设备对目标图像和第一处理结果执行逻辑后处理任务所得到的;
17、第四计算设备,用于根据目标图像和第二处理结果执行业务后处理任务,得到第四处理结果,并输出第四处理结果。
18、基于第二方面,一种可选的实施方式中,第二计算设备还用于:
19、通过rdma连接接收来自第一计算设备的目标图像的指针,目标图像的指针用于指示目标图像在共享内存中的存储地址。
20、基于第二方面,一种可选的实施方式中,第二计算设备中包括中央处理器cpu不包括图形处理器gpu,第二计算设备在根据第一处理结果和目标图像生成第二处理结果时,具体用于:
21、通过cpu对第一处理结果和目标图像进行非gpu任务处理,得到第二处理结果,非gpu任务是不需要gpu参与的任务。
22、基于第二方面,一种可选的实施方式中,第一计算设备中包括gpu,第一计算设备在根据目标图像生成第一处理结果时,具体用于:
23、通过gpu对目标图像执行gpu任务,得到第一处理结果,gpu任务为需要gpu参与的任务。
24、第三方面,本技术提供了一种图像处理装置,图像处理装置应用于人工智能ai视频处理系统,ai视频处理系统包括第一计算设备、第二计算设备在内的多个计算设备,多个计算设备之间建立远程直接内存访问rdma连接,多个计算设备的内存通过rdma连接构成ai视频处理系统的共享内存,图像处理装置包括:
25、接收单元,用于通过rdma连接接收来自第一计算设备的第一处理结果,第一处理结果是第一计算设备根据目标图像生成的;
26、获取单元,用于通过rdma连接从共享内存中获取目标图像;
27、生成单元,用于根据第一处理结果和目标图像生成第二处理结果。
28、基于第三方面,一种可选的实施方式中,接收单元还用于:
29、通过rdma连接接收来自第一计算设备的目标图像的指针,目标图像的指针用于指示目标图像在共享内存中的存储地址。
30、基于第三方面,一种可选的实施方式中,图像处理装置中包括中央处理器cpu不包括图形处理器gpu,生成单元具体用于:
31、通过cpu对第一处理结果和目标图像进行非gpu任务处理,得到第二处理结果,非gpu任务是不需要gpu参与的任务。
32、基于第三方面,一种可选的实施方式中,第一计算设备中包括gpu,第一处理结果为第一计算设备通过gpu对目标图像执行gpu任务的处理结果,gpu任务为需要gpu参与的任务。
33、第四方面,本发明提供了一种计算机设备,包括存储器、通信接口及与所述存储器和通信接口耦合的处理器;所述存储器用于存储指令,所述处理器用于执行所述指令,所述通信接口用于在所述处理器的控制下与其他设备进行通信;其中,所述处理器执行所述指令时执行上述任一方面所述的方法。
34、第五方面,本技术提供了一种计算机可读存储介质,所述计算机可读存储介质中存储有计算机程序,当其在计算机上运行时,使得计算机执行上述任一方面所述的方法。
35、第六方面,本技术提供了一种计算机程序产品或计算机程序,该计算机程序产品或计算机程序包括计算机指令,当其在计算机上运行时,使得计算机执行上述任一方面所述的方法。
36、从以上技术方案可以看出,本技术具有以下优点:
37、本技术中,通过使用rdma将多个计算设备的内存组成共享内存池,每个计算设备可以从共享内存池中获得目标图片以及前一个计算设备的处理结果,从而可以把完整一个图像处理(单独的静态图像或者视频中的图像帧)任务分解为串行的多个任务,分配到不同的多个计算设备来完成。利用多个计算设备的资源来协同进行视频处理,不再由一个计算设备来独立完成所有的任务,从而减少了单个计算设备的算力开销,实现负载均衡,提高了处理性能。另一方面,还可以根据场景需要在该ai视频处理系统中,新增或删减处理模块,使得处理任务的分配更加灵活。
- 还没有人留言评论。精彩留言会获得点赞!