基于机器学习的命名实体识别(NER)机制的弱监督和可解释训练的制作方法
基于机器学习的命名实体识别(ner)机制的弱监督和可解释训练
背景技术:
1.本发明涉及用于使用机器学习技术执行命名实体识别(ner)并且更具体地用于训练命名实体识别(ner)模型的系统和方法。
技术实现要素:
2.命名实体识别(ner)是一种机制,其中自动化处理(例如,基于计算机的处理)被应用于非结构化文本,以便在非结构化文本中标识和分类“命名实体”(例如,人、企业、位置等)的出现。例如,在一些实现中,ner是基于机器学习的自然语言处理机制,其中非结构化的自然语言语句被提供作为到机器学习模型的输入,并且机器学习模型的输出包括语句中每个“实体”(或潜在实体)的分配类别的指示(例如,机器学习模型确定可能对应于专有名称、对象等的出现在语句中的单词或短语)。例如,如果作为输入提供给的输入语句叙述:“约翰正在去伦敦旅行”,则经训练的ner机器学习模型的输出可以指示“约翰”被分类为“人”,并且“伦敦”被分类为“位置”。
3.在一些实现中,命名实体识别(ner)是许多下游信息提取任务(例如,关系提取)和知识库构造的基本任务。例如,由于深度神经模型的进步,命名实体识别的监督训练已经实现了可靠的性能。然而,ner模型的监督训练需要用于训练的数据的大量手动注释。这在所有情况下可能需要大量的时间,但是在一些特定领域中和/或当训练用于低资源语言的ner模型时——其中领域专家注释难以获得——特别具有挑战性。
4.在一些实现中,“远程监督”训练被用于从开放的知识库或字典中自动生成标注数据。远程监督使得大规模生成用于ner模型的训练数据而无需昂贵的人力成为可能。然而,所有远程监督的方法都依赖于现有的知识库或字典,并且在一些情况下,开放的知识库是不可用的(例如,在生物医学领域、技术文档等中)。
5.因此,在一些实现中,本文描述的系统和方法提供了用于训练机器学习ner模型的“弱监督”机制。在弱监督方法中,小的符号规则集——本文称为“播种规则”——用于标注非结构化文本中的数据。在一些实现中,播种规则及其相关联的标注可以为特定任务(即,ner模型将针对其被训练的任务)手动提供或定义。在使用播种规则将播种规则应用于非结构化文本之后,弱标注数据用于训练基于人工神经网络的ner模型的初始迭代。非结构化文本也被处理以自动标识用于标注“命名实体”的多个潜在规则。将自动标识的规则应用于非结构化文本,并将由规则确定的文本/标注组合与由ner模型的初始迭代确定的文本/标注组合进行比较。使用评分标准来标识最成功的“规则”,并且然后将其应用于原始的非结构化文本,以生成另一训练数据集。然后,基于由新的所选规则集所标注的数据,重新训练ner模型。该训练过程被迭代地重复,以继续完善和改进ner模型。
6.在一些实现中,用于训练ner模型的“弱监督”机制使用自举法(bootstrapping)来生成具有符号规则的弱标注数据,并且还自动训练ner模型来识别具有神经表示的实体。例如,在一些实现中,初始播种规则可以包括诸如“位于__中”之类的规则,以显式地标识非结
构化文本中的至少一些位置。此外,通过比较低维神经表示(即,单词嵌入)并迭代地重新训练ner模型,可以训练ner模型来标识新的实体。下面示例中描述的框架使用显式逻辑规则和神经表示两者来迭代地从未标注语料库(例如,非结构化文本)中寻找新的实体。此外,因为系统和方法使用逻辑规则来获得弱标注并识别实体,所以由经训练的ner模型提供的每个系统预测可以追溯到原始逻辑规则,这使得预测结果是可解释的。
7.在一个实施例中,本发明提供了一种用于训练机器学习模型来执行命名实体识别的方法。在未标注文本的输入数据集中自动标识所有可能的实体候选和所有可能的规则候选。通过将播种规则集应用于输入数据集以将标注分配给实体候选并将标注分配用作第一训练数据集来执行机器学习模型的初始训练。然后,将经训练机器学习模型应用于未标注文本,并且从规则候选中标识产生与经训练机器学习模型所分配的标注最准确地匹配的标注的规则子集。然后,使用由所标识的规则子集分配的标注作为第二训练数据集来重新训练机器学习模型。迭代地重复应用重新训练的模型、标识分配与重新训练的模型所分配的标注最准确地匹配的标注的规则子集以及执行模型的附加重新训练的过程,以进一步完善和改进用于命名实体识别的机器学习模型的性能。
8.在另一个实施例中,本发明提供了一种用于训练机器学习模型来执行命名实体识别的系统。该系统包括电子处理器,该电子处理器被配置为标识未标注文本的输入数据集中的所有可能的实体候选和所有可能的规则候选。电子处理器通过将播种规则集应用于输入数据集以将标注分配给实体候选并将标注分配用作第一训练数据集来执行机器学习模型的初始训练。然后,电子处理器将经训练机器学习模型应用于未标注的文本,并且从规则候选中标识产生与经训练机器学习模型所分配的标注最准确地匹配的标注的规则子集。电子处理器然后使用由所标识的规则子集分配的标注作为第二训练数据集来重新训练机器学习模型。迭代地重复应用重新训练的模型、标识分配与重新训练的模型所分配的标注最准确地匹配的标注的规则子集以及执行模型的附加重新训练的过程,以进一步完善和改进用于命名实体识别的机器学习模型的性能。
9.通过考虑详细描述和附图,本发明的其他方面将变得清楚。
附图说明
10.图1是根据一个实施例的用于训练和使用基于机器学习的命名实体识别(ner)机制的系统的框图。
11.图2是使用图1的系统训练和/或应用的ner机制的一个示例的示意图。
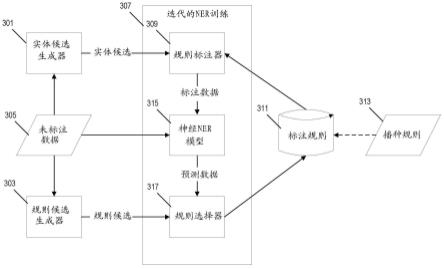
12.图3是用于使用自动生成的逻辑规则来训练图1的系统中的ner机制的系统框架的示意图。
13.图4是用于使用图3的系统框架训练图2的ner机制的方法的流程图。
具体实施方式
14.在详细解释本发明的任何实施例之前,应理解的是,本发明在其应用方面不限于在以下描述中阐述的或者在以下附图中图示的组件的构造和布置的细节。本发明能够有其他实施例,并且能够以各种方式实践或实行。
15.图1图示了基于计算机的系统100的示例,该基于计算机的系统100可以被配置用
于训练命名实体识别(ner)机器学习机制,用于应用经训练的ner机制,或者两者。系统100包括电子处理器101和非暂时性计算机可读存储器103。存储器103存储由电子处理器101访问和执行的数据和计算机可执行指令,以提供系统100的功能性,包括例如本文下面描述的功能性。电子处理器101通信耦合到显示器105和用户输入设备107(例如,键盘、鼠标、触摸屏等)以提供用于操作系统100和向用户显示数据的用户接口。电子处理器101还通信耦合到输入/输出设备109(例如,有线或无线通信接口),用于与其他基于计算机的系统通信。
16.图2图示了由图1的系统100训练和/或应用的机器学习模型的示例。机器学习模型201被配置为接收作为输入的非结构化和未标注的文本,包括例如文本语句203。响应于接收到输入文本,机器学习模型被配置为输出来自语句的文本的多个“跨度”中的每一个以及为每个跨度分配的标注。机器学习模型201输出的标注指示该跨度是否已经被标识为命名实体,并且如果是,哪个类别标注已经被分配给该跨度。在图2的示例中,机器学习模型已经在输入语句203中标识了三个不同的跨度205、207、209。第一跨度205已经被机器学习模型201分配了“人”标注211,其指示第一跨度205的文本已经被标识为对应于人的名字。第二跨度207已经被机器学习模型201分配了“位置”标注213,其指示第二跨度207的文本已经被标识为对应于位置的名称(例如,建筑物、城市、州、国家等)。最后,第三跨度209已经被机器学习模型201分配了“neg”标注215。如下面进一步详细描述的,“neg”标注215指示机器学习模型201已经确定第三跨度209的文本不对应于任何命名实体。
17.每个“跨度”可以包括来自输入语句的单个单词或来自输入语句的多个单词的组合。例如,如果将语句“我喜欢跑步”作为输入提供给机器学习模型201,则在一些实现中,机器学习模型可以被配置为产生以下跨度作为输出:[我]、[喜欢]、[跑步]、[我喜欢]、[喜欢跑步]和[我喜欢跑步]。尽管图2的特定示例示出了机器学习模型201仅产生3个跨度作为输出,但是在其他实现中,机器学习模型201可以被配置为输出更多或更少的标识跨度。类似地,在一些实现中,作为输出产生的跨度的数量可以取决于作为输入提供的语句而变化。事实上,在一些实现中,机器学习模型201可以被配置为产生输入语句中所有可能的跨度作为输出。
[0018]
作为另外的示例,如果提供语句“乔治生活在伦敦”作为输入203,则经训练机器学习模型201可以被配置为产生以下跨度和标注的组合作为输出:跨度标注[乔治]per(“人”)[生活]neg[在]neg[伦敦]loc(“位置”)[乔治生活]neg[乔治生活在]neg[乔治生活在伦敦]neg[生活在]neg[生活在伦敦]neg[在伦敦]neg表1。
[0019]
图3图示了用于训练图2的机器学习模型201以对非结构化文本输入执行命名实体识别和标注的框架的示例。实体候选生成器301和规则候选生成器303均被应用于未标注的训练数据集305。实体候选生成器301被配置为自动处理输入文本305,以标识输入文本305中所有可能的候选(例如,“跨度”)。类似地,规则候选生成器303被配置为从可能用于确定特定“跨度”是否是命名实体的未标注数据中自动生成潜在的“候选规则”。
[0020]
实体候选和规则候选作为输入被提供给迭代ner训练模块307。规则标注器309自动将标注规则集311应用于每个实体候选,并将标注分配给实体候选。如下面进一步详细描述的,在迭代ner训练模块307的第一次迭代中,标注规则311包括基本的播种规则313集。来自规则标注器309的标注数据然后被提供作为神经ner模型315的训练输入。然后,原始未标注数据305作为输入数据被提供给经训练的神经ner模型315,以产生“预测数据”输出。预测数据包括一个或多个跨度的标识和由经训练的神经ner模型315分配给该跨度的标注(参见例如上面的表1)。然后,规则选择器317被配置为通过将规则候选应用于未标注数据并将每个规则的结果与神经ner模型315输出的预测数据进行比较,来评分并从规则候选集(由规则候选生成器303生成)中选择最准确的标注规则。
[0021]
已经被规则选择器317标识为最准确的规则候选集然后被用作下一次迭代的标注规则311。在迭代ner训练模块307的下一次迭代中,规则标注器309将所选择的规则集应用于实体候选以产生新的标注数据集,并且新的标注数据集被用作训练数据以重新训练神经ner模型315。更新的神经ner模型315然后被应用于未标注数据305,以产生新的预测数据集,并且规则选择器317标识产生与更新的神经ner数据315的输出最准确地匹配的结果的规则候选集。在各种实现中,重复该迭代过程307,直到达到退出条件(例如,在定义的迭代次数之后,在实现定义的性能度量之后,或者直到规则选择器317收敛于特定的标注规则集)。
[0022]
图4图示了由图1的系统应用的方法的示例,该方法使用图3的框架来训练机器学习机制(例如,人工神经网络)以执行命名实体识别和标注(例如,如图2的示例中所图示)。系统100开始于将实体候选生成器301应用于未标注数据305以标识所有实体候选(步骤401),并将规则候选生成器303应用于未标注数据以标识所有规则候选(步骤403)。接下来,系统100将播种规则集213应用于实体候选以标注实体候选(步骤405),并使用该“弱标注”数据集作为训练数据来训练神经ner模型315(步骤407)。系统100然后将初始训练的神经ner模型315应用于原始未标注数据305(步骤409)以产生“预测数据”标注集。来自规则候选生成器303的每个规则候选也被应用于原始未标注数据(步骤411),并且通过将规则候选的结果与来自初始训练的神经ner模型315的“预测数据”标注集进行比较,对每个规则候选的准确性进行评分(步骤413)。系统标识表现最佳的规则候选(例如,产生与神经ner模型产生的“预测数据”标注集最准确地匹配的标注的规则候选)(步骤415)。系统100然后将该标识的表现最佳的规则候选集作为新的标注规则应用于原始的未标注数据(步骤417),并且使用由新的标注规则集标注的数据作为训练数据来重新训练神经ner模型(步骤407)。然后,将重新训练的神经ner模型315应用于原始未标注数据,以产生新的“预测数据”标注集(步骤409),并且再次对每个规则候选进行评分——这一次是通过将每个规则候选生成的标注与重新训练的神经ner模型生成的新的预测数据标注集进行比较(步骤413)。
[0023]
在每次迭代之后,系统100确定神经ner模型315的目标性能是否已经实现(步骤
419)。如果不是,则系统100执行神经ner模型315的另一次迭代重新训练。然而,一旦系统100确定已经实现目标性能,训练就完成(步骤421)。在一些实现中,神经ner模型315然后可以使用图4的方法和不同的未标注数据集被进一步训练,而在其他实现中,经训练的神经ner模型315可以准备好使用。
[0024]
图3的训练框架利用显式逻辑规则和神经表示两者来迭代地从未标注的语料库中寻找新的实体。由于框架使用逻辑规则来获得“弱”标注并识别实体,因此每个系统预测都可以追溯到原始逻辑规则,这使得预测结果是可解释的。
[0025]
在一些实现中,规则候选生成器303被配置为使用规则模板(例如,原子规则和复合规则),以便从未标注数据305中提取可能的规则候选。“原子规则”是可以用于描绘候选实体的一个信号方面的规则,而“复合规则”是可以用于匹配实体的多个方面的规则。在一些实现中,原子规则r
ti
是从规则模板ti生成的原子匹配逻辑。每个原子规则与实体标注相关联。原子规则模板的示例包括:(1) surfaceform(与实体的给定全名匹配的表面名称(例如,如果x匹配“伦敦”,则x是loc));(2)prefix(匹配候选跨度的前缀(例如,如果x匹配“伦*”,则x是loc));(3)suffix(匹配候选跨度的后缀(例如,如果x匹配“*敦”,则x是loc));(4)prengram(匹配候选跨度的左上下文(例如,如果“位于x
”ꢀ
则x是loc),(4) postngram(匹配候选跨度的右上下文(例如,如果“x 镇”,则x是loc)),(5) postag(匹配候选跨度的词性模式),以及(6) predependency(其依存树上跨度的父和兄弟)。
[0026]
例如,考虑以下语句:“新公司称为adon gmbh并且位于汉堡。”。如果我们使用prengram规则“公司称为{*}”,那么我们将匹配以下跨度:[adon]、[adon gmbh]、[adon gmbh并且]等,直到高达跨度的最大长度。因此,仅使用原子规则将引入许多“有噪声的”跨度(即,被原子规则错误地标识为“命名实体”的跨度)。
[0027]
复合规则是多个原子规则通过逻辑合取“^”、逻辑析取“v”或其他逻辑运算符的复合物,其被公式化为:其中r1、r2、
…
、rn是原子规则,并且是连接原子规则的逻辑函数。再次考虑语句:“新公司称为adon gmbh并且位于汉堡。”。如果我们具有来自模板(prengram ^postag)的复合规则“(公司称为{*},propn)”(其中“propn”标示专有名词的词性标签),那么我们将与实体[adon gmbh]完全匹配。
[0028]
因此,在一些实现中,对于每个候选实体,规则候选生成器303将根据给定的规则模板提取其所有规则。针对不同领域的有效规则可能不同。因此,系统可能潜在地被配置为对不同的目标领域使用不同类型的规则。例如,在一些生物医学领域数据集中,前缀和后缀规则是比词性标签更高效的规则模板。在一些实现中,上面图3的示例中图示的框架允许用户根据他们的数据集和领域定制他们的规则模板。
[0029]
如上面所讨论的,规则标注器309被配置为接收未标注的候选实体集(即跨度)和标注规则集311,并且将标注规则应用在未标注的跨度上以获得弱标注的数据。在一些情形下,可能的是,不同的规则可能针对相同候选实体产生不同标注。因此,在一些实现中,系统100被配置为使用多数投票者方法来处理规则冲突。例如,如果候选实体总共与三个规则匹配,并且两个规则将该候选实体标注为“位置”,而第三个规则将该实体标注为“组织”,则系
统100将使用多数投票将“位置”标注分配给该候选实体。在一些实现中,如果相等数量的规则将每个不同的标注应用于候选实体(例如,“平局”),则系统100将被配置为将候选实体标注为“弃权”,这意味着该候选实体将不被分配用于训练神经ner模型315的标注。
[0030]
如以上参考图2所讨论的,在一些实现中,机器学习模型201(例如,神经ner模型315)被配置为产生不同的跨度集和分配给每个输出跨度的标注作为输出。给定n个标记的语句 x = [w1, w2,
ꢀ…ꢀ
, wn] ,跨度,其中bi和ei分别是开始和结束索引,跨度可以由两个分量表示:内容表示,计算为跨该跨度中所有标记嵌入的加权平均;以及边界表示,其连结在该跨度的开始和结束位置处的嵌入。具体来说:其中tokenrepr是嵌入层(其可以是非上下文化的或上下文化的),bilstm是双向lstm层,并且selfattn是自我关注层。
[0031]
在一些实现中,神经ner模型315被配置为使用多层感知器(mlp)来预测高达固定长度l个单词的所有跨度的标注:其中oi是针对跨度的预测。如上面所讨论的,在一些实现中,否定标注neg被用作附加标注来指示无效跨度(例如,在未标注数据中不是命名实体的跨度)。
[0032]
如上面所讨论的,规则候选生成器303被配置为使用预定义的规则模板从未标注数据中生成所有候选规则。在图3的学习框架的一些实现中,系统被配置为使用规则选择器317从规则候选中自动选择新的标注规则。在每次迭代中,规则选择器317对所有候选规则进行评分,并选择评分最高的规则作为新的标注规则311。例如,在一些实现中,系统首先使用经训练的神经ner模型315(即,“预测数据”标注集)来估计所有候选跨度的可能标注,并且然后通过将每个规则的结果与这些弱估计的标注进行比较来对每个候选规则进行评分。在一些实现中,可以使用以下等式来计算每个候选规则ri的评分:其中fi是由规则ri提取的类别成员的数量(即,“正确”标注的跨度),并且ni是由规则ri提取的跨度的总数。该方法考虑了规则的精度和召回率两者,因为分量是规则的精
度评分,并且分量表示规则对更多跨度进行分类的能力。例如,如果规则r1匹配100个实例(n1= 100),并且匹配该规则的80个跨度也被神经ner模型315分配了相同的标注(f
1 = 80),则规则r1的评分将是f(r1)=5.06。
[0033]
在一些实现中,该系统被配置为标识每个规则模板和每个实体类别的定义数量(n)的最高评分规则,作为下一次迭代的新标注规则。在一些实现中,该系统被配置为针对第一次迭代使用n = 5。在一些实现中,该系统还被配置为通过设置规则精度的阈值(τ = 0.8)来防止低精度规则被添加到标注规则池。该方法允许考虑各种模式,而且它们足够精确使得所有模式与实体类别密切相关联。
[0034]
因此,除其他事物外,在上面的示例中描述的系统和方法还提供了一种用于基于机器学习的命名实体识别(ner)模型的弱监督训练的机制,其通过对照经训练的ner模型迭代地对自动生成的规则候选集进行评分,并使用最高评分的规则候选来针对ner模型的后续重新训练迭代生成训练数据标注。本发明的特征和优点在以下权利要求书中阐述。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1