一种基于PYNQ平台的神经网络通用加速处理方法
一种基于pynq平台的神经网络通用加速处理方法
技术领域
1.本发明涉及人工智能和fpga设计技术领域,具体涉及一种基于pynq平台的神经网络通用加速处理方法。
背景技术:
2.随着人工智能技术的快速发展,神经网络算法成为了研究人员争先研究的课题。而其中的cnn(convolutional neural networks,卷积神经网络) 网络算法在图像识别分类、语音分析检索、目标检测监控等领域中具有重要的应用价值和非凡的研究意义。神经网络的计算大多是以层级结构递进式计算,网络中相同层神经元的计算可以并行执行,且都依赖于前一层神经元的输出,数据可以得到复用,这是cnn可以实现计算加速的重要因素。
3.然而在卷积神经网络演变中,数以亿计的参数量与计算量对硬件性能提出了更高的需求。一方面,随着工艺水平的进步,目前的加速平台计算性能在逐步提升,如何在新型加速平台上进行高性能卷积神经网络算法加速需要进一步探索;另一方面,部分关于轻量化卷积神经网络的研究,在尽量保证性能的前提下,如何减少计算量与数据传输量也是一个重要的研究方向。
4.xilinx公司的pynq平台采用处理系统ps(processing system)+可编程逻辑pl(processing logic)的模式。处理系统ps端兼容了gige、usb、 can等多种外设接口,且官方在image文件中已经打好了usb接口的摄像头、网卡等设备的驱动,后期可以很方便地使用。处理系统ps端支持多种外部存储设备,如flash,dram,sram。可编程逻辑pl端主要负责一些高速外设接口,例如pcie、hdmi、pmod接口、音频输入等。通过在sd卡中烧入linux 镜像,使用linux操作系统实现可编程逻辑pl端fpga与计算机的联合开发,最终实现并行运算、高速图像处理、硬件加速算法、实时信号处理、高速通信、低延迟控制。
技术实现要素:
5.针对现有技术中存在的问题,本发明的目的在于一种基于pynq平台的神经网络通用加速处理方法。
6.为了达到上述目的,本发明采用以下技术方案予以实现。
7.一种基于pynq平台的神经网络通用加速处理方法,包括以下步骤:
8.步骤1,基于pynq平台,ps端的arm处理器从上位机获取特征图数据和权重数据,并存入到ddr存储器中;
9.步骤2,arm处理器对pl端的cnn寄存器进行赋值配置,且为pl端的非线性处理模块提供查找表;pl端的dma仿存模块将ddr存储器中的特征图数据和权重数据或中间计算结果加载至片上缓存fifo;pl端的卷积模块或池化模块或非线性处理模块在cnn寄存器的控制下,对片上缓存fifo中的数据进行计算得到中间计算结果,并将中间计算结果送回片上缓存fifo;dma仿存模块再将片上缓存fifo中的计算结果存入到ddr存储器中;
10.步骤3,根据计算需要,重复步骤2,获得最终计算结果;
11.步骤4,arm处理器将pl端的最终计算结果从ddr存储器中取出并完成概率运算,将概率运算结果传输给上位机。
12.进一步的,arm处理器还通过arm访存接口访问ddr存储器,获取中间计算结果进行辅助运算,并将辅助运算结果作为中间计算结果送回ddr存储器。
13.与现有技术相比,本发明的有益效果为:在原有pynq平台的基础上加入神经网络通用加速处理,采取多输入多输出通道的并行方法,并针对vgg-16、 tiny-yolov3网络结构对其进行了优化,在实现较小的资源消耗与较低功耗的基础上,提高了神经网络的数据处理速度、性能、通用性,提升了加速性能与加速效率。
附图说明
14.下面结合附图和具体实施例对本发明做进一步详细说明。
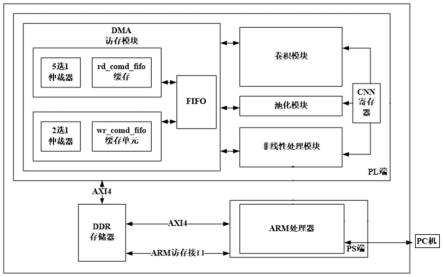
15.图1为本发明的pynq平台的架构示意图;
16.图2为卷积模块的架构示意图;
17.图3为池化模块的运算流程示意图;
18.图4为非线性处理模块的架构及运算流程示意图。
19.图5为实施例中vgg16预测的目标图像。
20.图6为实施例中tiny-yolov3得到的计算结果后预测的目标图。
具体实施方式
21.下面将结合实施例对本发明的实施方案进行详细描述,但是本领域的技术人员将会理解,下列实施例仅用于说明本发明,而不应视为限制本发明的范围。
22.一种基于pynq平台的神经网络通用加速处理方法,包括以下步骤:
23.步骤1,基于pynq平台,ps端的arm处理器从上位机获取特征图数据和权重数据,并存入到ddr存储器中;
24.具体的,参考图1,pynq平台包含处理系统ps端、可编程逻辑pl端和ddr 存储器,ddr存储器分别与处理系统ps端、可编程逻辑pl端通过axi4总线连接; ddr存储器还通过arm访存接口与arm处理器连接;
25.处理系统ps端包含arm处理器;arm处理器包含softmax模块和辅助运算模块;
26.arm处理器用于从上位机获取特征图数据和权重数据,并通过axi4总线存入到ddr存储器中;arm处理器还用于通过axi4总线对cnn寄存器进行赋值;arm 处理器还用于通过axi4总线为非线性处理模块提供查找表;arm处理器还用于通过arm访存接口获取ddr存储器中的中间计算结果,并使用辅助运算模块对中间计算结果进行辅助运算;arm处理器还用于对最终计算结果使用softmax 模块进行概率运算,并将概率运算结果传输给上位机;
27.ddr存储器用于存储特征图数据和权重数据,以及暂存可编程逻辑pl端的中间计算结果和arm处理器的辅助运算结果;
28.特征图数据存储方式:将特征图分割为tc*1*1的子块,按照每32通道一组,按照c、h、w的顺序存储(由于输入特征是三维张量,从通道1,宽为1,高为1的数据开始存储,先存满32维通道数据,高维度加一,再存储32维通道数据,直至高维度到达输入特征图的高值,宽维度加一,重复上述过程,直至将特征图的每一个元素存到ddr存储器中)。其中,tc为输入
通道数,为32 通道输入,w、h、c分别为特征图的宽高和通道。将计算得到的特征图(即pl 端的中间计算结果和arm处理器的辅助运算结果)分割为tk*1*1的子块,同样按c、h、w的顺序输出特征数据。其中,tk为输出通道数,为32通道输出。
29.权重图数据存储方式:将卷积核分组,每组tk个,最后一组可以少于 tk个;将每个卷积核分成tc*1*1大小的子块,若卷积核的输入通道总数不能整除tk,即32,则补0元素,使输入通道总数成为32的倍数;将卷积核的权重元素,按照输入通道cin、输出通道cout、高h、宽w的顺序将卷积核权重存储到ddr存储器中。这样的存储方式可以在通道维度上实现输入特征图和权重的矩阵运算。
30.可编程逻辑pl端包含dma仿存模块、卷积模块、池化模块、非线性处理模块和cnn寄存器;dma仿存模块包含读模块、写模块和片上缓存fifo;读模块包含rd_cmd_fifo缓存单元和5选1仲裁器;写模块包含wr_cmd_fifo缓存单元和2选1仲裁器;参考图2,卷积模块包含4个ram和乘加运算单元;
31.dma仿存模块用于使用读模块通过axi4总线将ddr存储器中的特征图数据、权重数据、中间计算结果和辅助运算结果加载至片上缓存fifo,即读操作;读操作:rd_cmd_fifo缓存单元存储每个内部总线的读命令,当满足一定条件(数据传输过程中需要在pl端和axi端口设计握手信号,即数据传输时,通过axi端传输一个读取信号,pl端接收该读取信号时回馈一个接收控制信号反馈给axi端,之后实现pl端的rd_cmd_fifo缓存单元通过axi4总线读取ddr存储器的数据,目的是防止因模块中的读数据fifo满而阻塞axi4总线的读数据通道)时,通过设计的五选一仲裁器接收来自rd_cmd_fifo缓存单元的请求,若五选一仲裁器准许这个请求,那么这个请求就会被送到axi4总线的读地址通道上。改变axi4总线读请求的id标志位为a,此后所请求的数据通过读数据通道返回的时候也会跟着一个标志位id,其值为a。当第n(n为0到4)个内部总线的读请求被准许时,dma访存模块会将这个请求送到axi4总线的读地址通道上时,同时还会把读地址通道上的这一个请求的标志位id设为n。因此,通过axi4总线读数据通道上的id信号就可以知道这是对哪一个读口所请求数据的响应,dma访存模块便可把这一数据送往对应对口的数据返回通道。 dma仿存模块还用于使用写模块通过axi4总线将卷积模块或池化模块或非线性处理模块输出至片上缓存fifo的中间计算结果存入ddr存储器,即写操作;写操作:wr_cmd_fifo缓存存储内部总线的写命令,当满足一定条件(数据传输过程中需要pl端和axi端口设计握手信号,即数据传输时,通过axi端口传输一个读取信号,pl端接收该读取信号时回馈一个接收控制信号反馈给axi 端,之后实现pl端的wr_cmd_fifo缓存单元通过axi4总线读取ddr4的数据,目的是防止因模块中的写数据fifo满而阻塞axi4总线的写数据通道)时,通过设计的二选一仲裁器就会收到来自wr_cmd_fifo缓存单元的请求,若二选一仲裁器准许这个请求,那么这个请求就会被送到axi4总线的写地址通道上。内部总线的写数据会被wr_dat_fifo缓存单元缓存,缓存后的数据会通过axi4 总线的写数据通道写入ddr存储器中。
32.卷积模块用于对片上缓存fifo中的数据进行卷积运算和全连接运算;参考图2,卷积模块的4个ram用于实现权重的预加载,4个ram将加载权重所需的延迟隐藏掉;乘加运算单元中包含tc*tk个16bit乘法器与(tc-1)*tk个 (32+log2tc)bit的加法器(增加log2tc bit是为了防止在加法运算时数据的溢出),最高可以提供2*tc*tk*主频的运算能力。其中,tc为输入通道数, tk为输出通道数。由于一次阵列运算需要用到权重存储区中所有的权
重,ram 仅能使用寄存器堆来实现,也就是共需2*tc*tk个16bit的寄存器。同时,乘加器阵列将会导致很长的逻辑延时,为了减短关键路径,乘加器阵列为流水线结构。使用5级流水寄存器,大致需要5*tc*tk/2个(32+log2tc)bit的寄存器(加法器树的压缩导致的数据总位宽变少,加法器树的输入为 tc*tk*(32+log2tc)bits,因此5级流水寄存器大致需要
33.5*tc*tk/2*(32+log2tc)bits)。
34.池化模块用于对片上缓存fifo中的数据进行池化运算;参考图3,首先进行宽度方向上的池化运算,输出结果为一个高为h,宽为wout的临时矩阵,记作ftp。其中ftp的第i行第j列的数据是输入特征图层第i行,第sw*j列至第 sw*j+kw-1列的数据(长度为kw的行向量)在进行“求最大值”、“求最小值”或“求均值”运算后的结果。接着进行高度方向的池化运算,这一步运算的输入为上一步的运算结果——临时矩阵ftp。在对ftp进行高度方向的池化运算之后,便可得到一个高为hout,宽为wout的矩阵,这个矩阵便是输出特征图层fout。其中,fout的第i行第j列的数据是临时矩阵ftp第j列,第sy*i行至第sy*i+ky-1行的数据(长度为ky的列向量)在进行“求最大值”、“求最小值”或“求均值”运算后的结果。
35.非线性处理模块用于根据arm处理器提供的查找表,对片上缓存fifo中的数据进行激活函数运算;
36.查找表包含所有输入对应数据的中间结果x,输入x的值域,由于值域为 16bit,为了减少查找表在pl端的存储空间,截断后5位数据,将其置为0,把第6位数据置1已完成对输入中间结果x的处理,这样将查找表的数据量从16m 压缩到1m,可以在兼顾灵活性的同时保证一定的计算精度,从而实现多种激活函数和量化等非线性运算。其中,查找表的生成在ps端完成,首先编写c代码,建立一个1024规模的数组用以存储输出结果,通过循环,从0开始,遍历所有输入的1024个数据,其中由于16bit数据的低第6位置一,所以输入的数据都加0.5。根据输入激活函数之前的缩放因子通过移位操作,将输入数据x 校准为输入激活函数之前的浮点型数据,经过激活函数的运算得到激活函数计算结果,再经过移位得到激活函数结果量化后的16位定点数据,输入到下一层。在pc机通过pytorch框架编写python代码通过16bit对称量化将32浮点型数据的权重、偏置和输入特征量化为定点型16bit数据,并得到的量化权重偏置数据和图像数据卷积并得到对应的权重缩放因子q_w,偏置缩放因子q_b 和特征缩放因子q_i,以及输入结果的缩放因子q_o,量化系数均为2的整数倍。可以通过定点数据除以以2的缩放因子次方将定点数反量化为浮点数。
37.参考图4,非线性处理模块的运算流程如下:输入的16bit定点数的输入特征和权重进行16bit乘法操作,输出结果存储在44bit的寄存器中,防止溢出,将一次卷积运算中每一次乘运算得到的结果经过累加运算,卷积乘法运算的结果保留在44bit寄存器中。再将卷积结果左移偏置的缩放因子q_b位完成校准操作,偏置左移输入特征的缩放因子q_i位再左移权重的缩放因子q_w 完成校准操作,然后与卷积的乘法运算得到的累加结果进行加法运算,得到卷积运算的结果。得到累加偏置结果后,右移3个缩放因子(q_i、q_w、q_b) 的和与输出缩放因子(q_o)的差位进行反量化操作,得到输入激活函数表前完整的卷积运算计算结果,最后经过激活函数表输出,得到激活函数的运算结果。激活函数的运算结果进入下一次卷积运算时重复上述操作。
38.cnn寄存器用于根据arm处理器的赋值,控制dma仿存模块对ddr存储器的读写操作,以及控制卷积模块或池化模块或非线性处理模块进行计算。cnn寄存器位于pl端,通过
在pl端设计特定数量的寄存器,在ps端通过axi4总线向 pl端指定寄存器写入数据,生成特定信号来控制pl端的dma仿存模块的读写操作,以及控制pl端的各个计算模块的运行。
39.步骤2,arm处理器对pl端的cnn寄存器进行赋值配置,且为pl端的非线性处理模块提供查找表;pl端的dma仿存模块将ddr存储器中的特征图数据和权重数据或中间计算结果加载至片上缓存fifo;pl端的卷积模块或池化模块或非线性处理模块在cnn寄存器的控制下,对片上缓存fifo中的数据进行计算得到中间计算结果,并将中间计算结果送回片上缓存fifo;dma仿存模块再将片上缓存fifo中的计算结果存入到ddr存储器中;
40.步骤3,根据计算需要,重复步骤2,获得最终计算结果;
41.步骤4,arm处理器将pl端的最终计算结果从ddr存储器中取出并完成概率运算,将概率运算结果传输给上位机。
42.进一步的,arm处理器还通过arm访存接口访问ddr存储器,获取中间计算结果进行辅助运算,并将辅助运算结果作为中间计算结果送回ddr存储器。已知特征存储顺序为whc,每16个输入通道为一组,arm处理器通过arm访存接口访问ddr存储器即可以按如下公式:
43.address=mem_map_base+(ch/tk)
×
feature_surface_stride+row
ꢀ×
feature_line_stride+col
×
tk
×
2+(ch%tk)
×244.其中,address为访问元素位置;mem_map_base为ddr中特征存储初地址;ch为输入特征通道总数;tk为并行16通道;feature_surface_stride为单个通道特征图地址总量,即长宽之积乘以2;feature_line_stride为特征行地址总量,即宽乘以2;row、col分别为特征的宽和高。
45.仿真实验过程:
46.通过pc机访问pynq平台,通过在ps端的arm芯片编写c代码控制pl端的cnn 寄存器,并实现加速器功能,编译运行vgg16和tiny-y0l0v3。
47.在150m的频率下,得到vgg16检测结果即vgg16各层的运算时间如表1所示;参考图5,为vgg16预测的目标图像,可以看出,vgg16使用本发明方法加速后可以得到正确的结果。
48.表1
49.[0050][0051]
在150m的频率下,得到tiny-yolov3各层的运算时间如表2所示;参考图6,为得到的计算结果后预测的目标图,可以看出tiny-yolov3使用本发明方法加速后后可以得到正确的结果。
[0052]
表2
[0053]
[0054][0055]
参考表1、表2、图5和图6,可以看出,在保证精度的情况下,本发明的加速方法可以对vgg16网络和tiny-yolov3网络进行有效加速。
[0056]
虽然,本说明书中已经用一般性说明及具体实施方案对本发明作了详尽的描述,但在本发明基础上,可以对之作一些修改或改进,这对本领域技术人员而言是显而易见的。因此,在不偏离本发明精神的基础上所做的这些修改或改进,均属于本发明要求保护的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1