基于多标签的衣着属性识别模型构建方法及构建系统与流程
1.本发明涉及计算机视觉技术领域,具体地说是基于多标签的衣着属性识别模型构建方法及构建系统。
背景技术:
2.衣着属性识别有成熟的方案,但这些方案都是基于单标签模型的方案,每个模型只能识别一个属性,在多重属性识别时需要使用多个模型。在国产ai加速卡上同时使用多个模型进行实时计算时存在性能问题,因此需要一种多标签模型进行衣着的多属性识别。
3.深度学习算法通常有一个先验的假设,即参与训练的训练数据集(traindata)和验证数据集(testdata)与实际数据之间是独立同分布的,所以一般要求训练数据集与验证数据集是均衡的。但是在实际工程应用中,收集数据集是一件昂贵的工作,需要权衡数据集质量与花费,通常情况下很难收集到均衡数据集。在本方法收集的关于衣着属性的数据集中,白色与黑色远远多于其他颜色,长裤与t恤远远多于其他样式,因此直接将数据集放入深度学习模型中训练是不可行的,需要均衡数据集。
4.数据集均衡的方法分为数据层面和算法层面两类方法:数据层面的方法主要是过采样和欠采样,算法层面的主要方法是使用带权重惩罚的损失函数。这些方法主要针对单标签数据集,在推广到多标签数据集时存在模型精度下降,惩罚权重函数难以确定等问题。
5.如何实现国产ai加速卡环境上的多标签衣着属性识别,是需要解决的技术问题。
技术实现要素:
6.本发明的技术任务是针对以上不足,提供基于多标签的衣着属性识别模型构建方法及构建系统,来解决如何实现国产ai加速卡环境上的多标签衣着属性识别的技术问题。
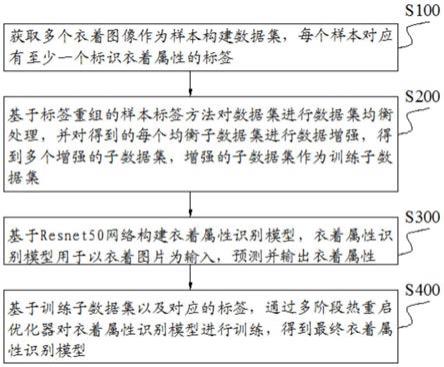
7.本发明实施例的基于多标签的衣着属性识别模型构建方法,包括如下步骤:
8.获取多个衣着图像作为样本构建数据集,每个样本对应有至少一个标识衣着属性的标签;
9.基于标签重组的样本标签方法对所述数据集进行数据集均衡处理,并对得到的每个均衡子数据集进行数据增强,得到多个增强的子数据集,所述增强的子数据集作为训练子数据集;
10.基于resnet50网络构建衣着属性识别模型,所述衣着属性识别模型用于以衣着图片为输入,预测并输出衣着属性;
11.基于所述训练子数据集以及对应的标签,通过多阶段热重启优化器对所述衣着属性识别模型进行训练,得到最终衣着属性识别模型。
12.作为优选,通过mixup数据增强方法对每个均衡子数据集进行数据增强。
13.作为优选,基于标签重组的样本标签方法对所述数据集进行数据集均衡处理。包括如下步骤:
14.计算数据集中各个标签的样本数量;
15.提取标签最少的样本组成一个集合g,剩余样本组成的集合r;
16.计算集合g中各标签的样本数量,并集合r中随机挑选样本加入集合g中,得到集合g1,集合g1中各标签样本数均衡;
17.设定集合r的数量为m,添加到集合g的样本数量为n,记t为需要重复的次数,重复t次,得到t个均衡子数据集,将剩余的样本随机添加至所述t个均衡子数据集。
18.作为优选,所述衣着属性识别模型包括:
19.数据预处理模块,所述数据预处理模块包括图片缩放层和数据归一化层,所述图片缩放层用于对输入的衣着图片缩放为统一尺寸,所述数据归一化层用于将缩放后的衣着图片中每个像素值的范围从[0,255]映射至[0,1];
[0020]
特征提取模块,所述特征提取模块为resnet50主干网络,用于提取图形特征,得到2048维特征向量;
[0021]
数据后处理模块,所述数据后处理模块包括数据特征向量分类层和分类结果转义层,所述特征向量分类层将2048维特征向量映射成2维特征向量,从而得到预测结果,所述分类结果转义层将2维特征向量映射为衣着的样式与颜色两个属性作为模型输出。
[0022]
作为优选,基于所述训练子数据集以及对应的标签,通过多阶段热重启优化器对所述衣着属性识别模型进行训练,包括如下步骤:
[0023]
依次加载所述训练数据集,根据每个训练数据集样本数量和批量大小确定不同的迭代次数;
[0024]
循环训练每一个训练数据集,在每个训练数据集上使用多阶段重启优化训练器进行模型训练,开始循环时重置学习率,直到训练完所有训练数据集,得到最终衣着属性识别模型。
[0025]
作为优选,所述最终衣着属性识别模型量化后部署于国产ai加速卡上。
[0026]
第二方面,本发明的基于多标签的衣着属性识别模型构建系统,包括:
[0027]
数据集获取模块,所述数据集获取模块用于获取多个衣着图像作为样本构建数据集,每个样本对应有至少一个标识衣着属性的标签;
[0028]
数据集均衡处理模块,所述数据集均衡处理模块用于基于标签重组的样本标签方法对所述数据集进行数据集均衡处理,并对得到的每个均衡子数据集进行数据增强,得到多个增强的子数据集,所述增强的子数据集作为训练子数据集;
[0029]
模型配置模块,所述模型配置模块用于基于resnet50网络构建衣着属性识别模型,所述衣着属性识别模型用于以衣着图片为输入,预测并输出衣着属性;
[0030]
模型训练模块,所述模型训练模块用于基于所述训练子数据集以及对应的标签,通过多阶段热重启优化器对所述衣着属性识别模型进行训练,得到最终衣着属性识别模型。
[0031]
作为优选,数据集均衡处理模块用于通过如下步骤对所述数据集进行数据集均衡处理:
[0032]
计算数据集中各个标签的样本数量;
[0033]
提取标签最少的样本组成一个集合g,剩余样本组成的集合r;
[0034]
计算集合g中各标签的样本数量,并集合r中随机挑选样本加入集合g中,得到集合g1,集合g1中各标签样本数均衡;
[0035]
设定集合r的数量为m,添加到集合g的样本数量为n,记t为需要重复的次数,重复t次,得到t个均衡子数据集,将剩余的样本随机添加至所述t个均衡子数据集;
[0036]
且数据集均衡处理模块用于通过mixup数据增强方法对每个均衡子数据集进行数据增强。
[0037]
作为优选,所述衣着属性识别模型包括:
[0038]
数据预处理模块,所述数据预处理模块包括图片缩放层和数据归一化层,所述图片缩放层用于对输入的衣着图片缩放为统一尺寸,所述数据归一化层用于将缩放后的衣着图片中每个像素值的范围从[0,255]映射至[0,1];
[0039]
特征提取模块,所述特征提取模块为resnet50主干网络,用于提取图形特征,得到2048维特征向量;
[0040]
数据后处理模块,所述数据后处理模块包括数据特征向量分类层和分类结果转义层,所述特征向量分类层将2048维特征向量映射成2维特征向量,从而得到预测结果,所述分类结果转义层将2维特征向量映射为衣着的样式与颜色两个属性作为模型输出。
[0041]
作为优选,所述模型训练模块用于通过如下步骤对所述衣着属性识别模型进行训练:
[0042]
依次加载所述训练数据集,根据每个训练数据集样本数量和批量大小确定不同的迭代次数;
[0043]
循环训练每一个训练数据集,在每个训练数据集上使用多阶段重启优化训练器进行模型训练,开始循环时重置学习率,直到训练完所有训练数据集,得到最终衣着属性识别模型。
[0044]
本发明的基于多标签的衣着属性识别模型构建方法及构建系统具有以下优点:
[0045]
1、对于获取的数据集,基于标签重组的样本标签方法对所述数据集进行数据集均衡处理,即通过数据均衡方法充分利用数据集中的全部数据,避免一般的数据均衡办法造成的过拟合与欠拟合问题;
[0046]
2、在对衣着属性识别模型进行训练时,利用热重启技术充分在数据集上训练,避免模型陷入局部最优点,提高了模型预测精度;
[0047]
3、通过该方法构建的衣着属性识别模型充分考虑了国产环境的性能问题,提高了国产环境下算法的运行效率。
附图说明
[0048]
为了更清楚地说明本发明实施例中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域的普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
[0049]
下面结合附图对本发明进一步说明。
[0050]
图1为实施例1基于多标签的衣着属性识别模型构建方法的流程框图;
[0051]
图2为实施例1基于多标签的衣着属性识别模型构建方法中衣着识别模型的结构框图。
具体实施方式
[0052]
下面结合附图和具体实施例对本发明作进一步说明,以使本领域的技术人员可以更好地理解本发明并能予以实施,但所举实施例不作为对本发明的限定,在不冲突的情况下,本发明实施例以及实施例中的技术特征可以相互结合。
[0053]
本发明实施例提供基于多标签的衣着属性识别模型构建方法及构建系统,用于解决如何实现国产ai加速卡环境上的多标签衣着属性识别的技术问题。
[0054]
实施例1:
[0055]
本发明基于多标签的衣着属性识别模型构建方法,包括如下步骤:
[0056]
s100、获取多个衣着图像作为样本构建数据集,每个样本对应有至少一个标识衣着属性的标签;
[0057]
s200、基于标签重组的样本标签方法对数据集进行数据集均衡处理,并对得到的每个均衡子数据集进行数据增强,得到多个增强的子数据集,增强的子数据集作为训练子数据集;
[0058]
s300、基于resnet50网络构建衣着属性识别模型,衣着属性识别模型用于以衣着图片为输入,预测并输出衣着属性;
[0059]
s400、基于训练子数据集以及对应的标签,通过多阶段热重启优化器对衣着属性识别模型进行训练,得到最终衣着属性识别模型。
[0060]
本实施例中步骤s100获取数据集,该数据集中包括多个样本,每个样本对应至少一个标签,该标签用于标识衣着属性,例如样式和颜色等。
[0061]
步骤s200对数据集进行均衡处理,作为一个具体实施,该方法首先计算数据集中各标签的样本数量,将标签数最少的样本提取出来组成一个集合g,剩余样本记为集合r;然后计算集合g中各标签的样本数,从集合r中随机挑选样本加入集合g中,使得集合g的各标签样本数均衡,记为g1,假设集合r的数量为m,添加到集合g的样本数量为n,记t为需要重复的次数,则重复t次,得到g1...gt共t个均衡子数据集,将剩余的样本随机添加到t个子数据集中;对t个子数据集使用mixup数据增强方法,生成t个增强的子数据集。
[0062]
步骤s300使用深度卷积网络结构构建衣着属性识别模型,由数据预处理模块、resnet50经典主干网络、数据后处理模块组成。国产化cpu性能较弱,将数据预处理与后处理功能添加到模型网络中,提高数据并行能力,显著提升预测速度。数据预处理模块包含图片缩放层,数据归一化层;图片缩放层将输入网络的图片统一缩放长为96像素,宽为96像素的图像;数据归一化层将每个像素值的范围从[0,255]映射至[0,1]。使用resnet50主干网络提取图像特征,生成一个2048维的特征向量。数据后处理模块包含数据特征向量分类层,分类结果转义层;特征向量分类层将2048维特征向量映射成2维特征向量,从而得到预测结果;分类结果转义层将2维特征向量映射为衣着的样式与颜色两个属性作为模型输出。
[0063]
步骤s400对上述构建的衣着属性识别模型进行训练。作为一个具体实施,方法使
用多阶段热重启优化器进行训练。将所步骤s200得到的t个训练子数据集依次加载,根据每个子数据集样本数量和批量大小确定不同的迭代次数;在每个子数据集上使用多阶段重启优化训练器进行训练,开始训练时选择较大的学习率,使得模型进行快速收敛,模型收敛后逐步调小学习率,寻找最优点;循环训练每一个数据集,开始循环时重置学习率,直到训练完所有数据集,得到最终模型。
[0064]
将训练好的衣着属性识别模型量化后部署至国产ai加速卡上,传入衣着图像,使用模型进行预测,返回预测的衣着属性结果。
[0065]
该方法通过重组样本的方法获取多个样本均衡的子数据集;设计了一种适应国产ai加速卡的深度学习模型,使用多阶段热重启优化器在各个子数据集上训练模型,避免模型陷入局部最优点,提高了模型衣着属性识别精度;充分考虑了国产环境的性能问题,提高了国产环境下模型的运行效率。
[0066]
实施例2:
[0067]
本发明基于多标签的衣着属性识别模型构建系统,包括数据集获取模块、数据集均衡处理模块、模型配置模块以及模型训练模块,数据集获取模块用于获取多个衣着图像作为样本构建数据集,每个样本对应有至少一个标识衣着属性的标签;数据集均衡处理模块用于基于标签重组的样本标签方法对所述数据集进行数据集均衡处理,并对得到的每个均衡子数据集进行数据增强,得到多个增强的子数据集,增强的子数据集作为训练子数据集;模型配置模块用于基于resnet50网络构建衣着属性识别模型,所述衣着属性识别模型用于以衣着图片为输入,预测并输出衣着属性;模型训练模块用于基于所述训练子数据集以及对应的标签,通过多阶段热重启优化器对所述衣着属性识别模型进行训练,得到最终衣着属性识别模型。
[0068]
本实施例中,数据集均衡处理模块用于通过如下步骤对所述数据集进行数据集均衡处理:
[0069]
(1)计算数据集中各个标签的样本数量;
[0070]
(2)提取标签最少的样本组成一个集合g,剩余样本组成的集合r;
[0071]
(3)计算集合g中各标签的样本数量,并集合r中随机挑选样本加入集合g中,得到集合g1,集合g1中各标签样本数均衡;
[0072]
(4)设定集合r的数量为m,添加到集合g的样本数量为n,记t为需要重复的次数,重复t次,得到t个均衡子数据集,将剩余的样本随机添加至所述t个均衡子数据集.
[0073]
数据集均衡处理模块用于通过mixup数据增强方法对每个均衡子数据集进行数据增强。
[0074]
衣着属性识别模型由数据预处理模块、resnet50经典主干网络、数据后处理模块组成。国产化cpu性能较弱,将数据预处理与后处理功能添加到模型网络中,提高数据并行能力,显著提升预测速度。数据预处理模块包含图片缩放层,数据归一化层;图片缩放层将输入网络的图片统一缩放长为96像素,宽为96像素的图像;数据归一化层将每个像素值的范围从[0,255]映射至[0,1]。使用resnet50主干网络提取图像特征,生成一个2048维的特征向量。数据后处理模块包含数据特征向量分类层,分类结果转义层;特征向量分类层将
2048维特征向量映射成2维特征向量,从而得到预测结果;分类结果转义层将2维特征向量映射为衣着的样式与颜色两个属性作为模型输出。
[0075]
模型训练模块用于通过如下步骤对所述衣着属性识别模型进行训练:将第一步中得到的t个子数据集依次加载,根据每个子数据集样本数量和批量大小确定不同的迭代次数;在每个子数据集上使用多阶段重启优化训练器进行训练,开始训练时选择较大的学习率,使得模型进行快速收敛,模型收敛后逐步调小学习率,寻找最优点;循环训练每一个数据集,开始循环时重置学习率,直到训练完所有数据集,得到最终模型。
[0076]
本实施例的系统可执行实施例1公开的方法构建衣着属性识别模型。
[0077]
上文通过附图和优选实施例对本发明进行了详细展示和说明,然而本发明不限于这些已揭示的实施例,基与上述多个实施例本领域技术人员可以知晓,可以组合上述不同实施例中的手段得到本发明更多的实施例,这些实施例也在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1