一种深度图与位姿优化方法和系统与流程
1.本发明属于计算机视觉领域,一种基于分组双增强模块和多级感知优化器的深度图与位姿优化方法和系统。
背景技术:
2.运动恢复结构(sfm)旨在准确地计算出一组相机图片的深度图和彼此的相对位姿,从而建模相应场景的三维结构。传统的sfm优化方案一般依赖于光束平差法(ba)解决。但是传统ba方法需要借助良好的图像关键点和图像间的特征匹配,导致其性能严重受限于光照条件和结构纹理。
3.为了解决这些问题,近年来出现了一些应用深度学习解决sfm优化问题的方法和系统。早期的方法直接使用神经网络对输入图片做回归来预测结果,但是由于缺乏基本的几何约束,效果不理想。最近的方法尝试将深度学习与传统优化方法的优势结合起来。这些方法主要可分为两类:间接更新法和直接更新法。然而,间接更新法只适用于目标函数比较简单的情况,难以很好地利用神经网络的优势。另一方面,现有的直接更新法依赖体积成本或传统的光度测量成本。但是前者的计算量过大,后者由于忽略了空间信息,导致优化过程容易受噪声影响而使得优化不稳定。此外,现有系统的优化器由于计算资源限制,只采用了感受野较小的卷积操作,这使得优化器对大目标的特征捕获能力较差,导致预测结果不完整。
技术实现要素:
4.本发明要解决的是现有方法中,优化过程不稳定以及优化器对大目标感知能力差的问题。
5.本发明所采用的技术方案是:一种深度图与位姿优化方法,包括以下步骤:
6.s1,预备包括rgb图像数据、真实深度图数据和真实相机位姿数据的序列,从中抽取目标图像it、it的多个相邻图像iri、it相对于iri的真实位姿、以及it的真实深度图;
7.s2,对it和iri进行特征提取,得到图像特征ft和fri,对it进行深度提取,得到深度上下文信息,作为深度隐藏状态,将it和iri进行拼接并对拼接后的图像进行位姿提取,得到位姿上下文信息,作为位姿隐藏状态;
8.s3,对图像特征ft经过深度图网络得到初始深度图,ft和fri拼接后输入位姿网络得到初始位姿;
9.s4,根据初始深度图和初始位姿在特征空间上计算光度测量成本,对光度测量成本进行成本增强得到深度增强成本和位姿增强成本;
10.将深度隐藏状态、深度增强成本和初始深度图输入到深度多级感知优化器来得到新的初始深度图,使用新的初始深度图和初始位姿计算新的光度测量成本,用新的光度测量成本更新深度增强成本进而更新初始深度图,迭代更新m 次初始深度图,m为正整数;
11.将位姿隐藏状态、位姿增强成本和初始位姿输入到位姿多级感知优化器来来得到
新的初始位姿,使用初始深度图和新的初始位姿计算新的光度测量成本,用新的光度测量成本更新位姿增强成本进而更新初始位姿,迭代更新n次初始位姿,n为正整数;
12.s5,重复执行k次s4,得到最终的深度图和位姿,k为正整数;
13.s6,利用损失函数构造深度图损失和位姿损失,根据深度图损失和位姿损失得到总损失,利用总损失更新深度多级感知优化器和位姿多级感知优化器的权重;
14.s7,重复s1到s6,直到总损失收敛,得到训练模型,将待测试图像输入到训练模型,得到预测的深度图和位姿。
15.进一步的,所述s4中,光度测量成本的计算方法为:根据初始深度图d、初始位姿pi和相机内参k,计算fri上的重投影二维坐标,再根据所得二维坐标对fri进行采样,将采样得到的特征图与ft计算l2范数得到光度测量成本。
16.进一步的,所述s4中,深度增强成本和位姿增强成本的计算方法均为:对光度测量成本进行编码,按通道进行分组,对每一组做全局平均池化,得到每一组的统计向量,之后利用统计向量对其所属组的成本进行空间增强和通道增强,将每组的结果按通道拼接,得到总的增强成本。
17.进一步的,所述s4中得到新的初始深度图或初始位姿的具体步骤为:首先将深度增强成本和初始深度图或位姿增强成本和初始深度图投影到特征空间,拼接后作为优化特征,然后将优化特征和深度隐藏状态或优化特征和位姿隐藏状态输入到深度多级感知优化器或位姿多级感知优化器,得到新的深度隐藏状态或新的位姿隐藏状态,之后用深度图网络或位姿网络根据新的深度隐藏状态或新的位姿隐藏状态得到深度图增量或位姿增量,将该增量加到初始深度图或初始位姿来更新初始深度图或初始位姿。
18.进一步的,所述s6中,损失函数l的计算公式为:
19.l=l
psoe
+l
depth
,
[0020][0021][0022]
其中,d
*
和pi
*
表示真实深度和位姿,γ表示衰减系数,k表示迭代总次数, t表示第t次迭代,d
t
和pi
t
表示预测的深度和位姿,d(x)表示d中的像素坐标,k为相机内参,proj为投影函数,iri为根据坐标采样图像的像素值。
[0023]
进一步的,所述深度多级感知优化器和位姿多级感知优化器均由不同膨胀系数的空洞卷积和门控循环单元组成。
[0024]
进一步的,所述空间增强操作的计算方法为:对统计向量和成本的逐个元素向量做内积,得到空间增强权重,然后将空间增强权重进行缩放和转换,再经过sigmoid函数与成本相乘,得到空间增强成本。通道增强操作的计算方法为:对统计变量进行一维卷积操作得到通道权重向量b,然后b经过sigmoid函数与空间增强成本相乘,得到双增强成本。
[0025]
进一步的,所述多级感知结构由不同膨胀系数的空洞卷积和门控循环单元组成。
[0026]
一种深度图与位姿优化系统,包含图像特征提取模块、深度上下文提取模块、位姿上下文提取模块、深度分组双增强模块、位姿分组双增强模块,深度多级感知优化器模块和位姿多级感知优化器模块;图像特征提取模块用于提取图像特征,上下文信息提取模块用于提取上下文信息作为隐藏状态,分组双增强模块对成本进行增强,深度多级感知优化器模块用于更新深度图,位姿多级感知优化器模块用于更新位姿。
[0027]
进一步的,图像特征提取模块和上下文信息提取模块使用残差网络的结构,深度图网络和位姿网络采用二维卷积神经网络结构,深度多级感知优化器和位姿多级感知优化器均由不同膨胀系数的空洞卷积和门控循环单元组成,深度多级感知优化器的输出层含有深度图网络,位姿多级感知优化器的输出层含有位姿网络。
[0028]
本发明同现有技术相比具有以下优点及效果:
[0029]
1.本发明模型涉及到的分组双增强模块能有效增强光度测量成本的空间语义信息和通道间的相互依赖关系,从而降低了潜在噪声对后续优化过程的干扰,使得预测结果更加清晰和精确。
[0030]
2.本发明模型涉及到的多级感知优化器通过高效的多级感知结构,提高了优化器对优化特征中大目标的特征捕获能力,从而对大目标的预测结果更加完整和准确。
附图说明
[0031]
构成本技术的一部分的附图用来提供对本发明的进一步理解,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。
[0032]
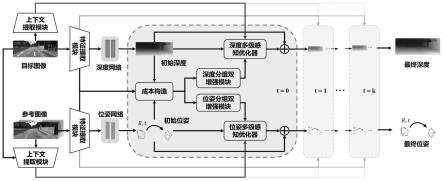
图1为本发明模型示意图;
[0033]
图2为分组双增强模块结构图;
[0034]
图3为分组双增强模块对每一组的实现细节;
[0035]
图4为多级感知优化器的核心结构图;
[0036]
图5为分组双增强模块和多级感知优化器的消融实验结果图;
[0037]
图6为本发明与其他方法的深度估计结果的对比。
具体实施方式
[0038]
为了使本发明的目的、技术方案及优点更加清楚,下面将结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
[0039]
实施例1:
[0040]
如图1所示,一种基于分组双增强模块和多级感知优化器的深度图与位姿优化方法和系统,包括以下步骤。
[0041]
步骤1,数据准备,分成两步:
[0042]
1.1,预备包括rgb图像数据、真实深度图数据和真实相机位姿数据的序列,例如kitti无人驾驶数据集,其包含由车载摄像头以及多种传感器所获取的图像数据、真实深度图数据和真实相机位姿数据的序列。
[0043]
1.2,从1.1的预备数据中抽取目标图像it,it的相邻图像iri(i从1到2), it相对于iri的真实位姿pi,以及it的真实深度图d。作为优选,图像的大小预处理为高320像素,宽
960像素。
[0044]
步骤2,图像特征提取与上下文信息提取。利用特征提取模块和上下文提取模块对步骤1.2中的it和iri提取图像特征和上下文特征。
[0045]
2.1,图像特征的提取。作为优选,特征提取模块的结构采用现有的为图像分类任务设计的残差网络18,其输出的特征图大小是原图像大小的八分之一,通道数为128。由此分别得到it和iri的特征图ft和fri。
[0046]
2.2,上下文信息的提取。作为优选,上下文提取模块的结构采用现有的为图像分类任务设计的残差网络18。其中,深度上下文提取模块的输入为it,位姿上下文提取模块的输入为it和iri在通道维度上的拼接结果。模块输出的特征图大小均为原图像大小的八分之一,通道数为160。由此得到深度上下文信息和位姿上下文信息,分别作为初始的深度隐藏状态和位姿隐藏状态。
[0047]
步骤3,光度测量成本的构造与增强。
[0048]
3.1,光度测量成本的构造。第一次迭代时,将步骤2.1中得到的特征图ft 输入深度图网络得到初始深度图d,将ft和fri在通道维度上拼接后输入位姿网络得到初始位姿pi。然后根据相机内参k计算fri上的重投影二维坐标,再根据所得二维坐标对fri进行采样。最后,将采样得到的特征图与ft计算l2范数得到光度测量成本。
[0049]
3.2,光度测量成本的增强。使用分组双增强模块对成本增强,其整体结构图如图2所示,具体操作为:首先对光度测量成本进行编码。作为优选,成本编码器使用卷积核大小依次为1和3的卷积层,输出尺寸保持不变。然后按通道将成本分为32组。接着对每一组的操作如图3所示,我们先进行全局平均池化,得到统计向量,之后利用统计向量对该组的成本进行空间增强和通道增强,空间增强的计算方法为:对统计向量和成本做内积,得到空间增强权重,然后将空间增强权重进行缩放和转换,再经过sigmoid函数与成本相乘,得到空间增强成本;通道增强的计算方法为:对统计变量进行一维卷积操作得到通道权重向量b,然后权重向量b经过sigmoid函数与空间增强成本相乘,得到双增强成本。最后将每组的结果按通道拼接,得到总的增强成本。
[0050]
步骤4,迭代更新深度图与位姿。利用多级感知优化器更新深度图与位姿。多级感知优化器的核心结构如图4所示,深度多级感知优化器和位姿多级感知优化器都是由多个不同膨胀系数的空洞卷积和门控循环单元组成,作为优选,使用膨胀系数分别为1和4的空洞卷积;深度多级感知优化器的输出层含有深度图网络,位姿多级感知优化器的输出层含有位姿网络。首先将总的增强成本和初始深度图投影到特征空间并拼接作为优化特征,然后将优化特征和隐藏状态输入到多级感知结构得到新的隐藏状态。之后用深度图网络或位姿网络根据新的隐藏状态得到深度图增量或位姿增量。最后将该增量加到初始深度图或初始位姿得到更新的初始深度图或初始位姿。具体的迭代更新过程如下:
[0051]
4.1,更新深度图。将深度隐藏状态、增强成本和初始深度图输入到深度多级感知优化器,得到更新的深度图和新的深度隐藏状态,分别作为下一次迭代的初始深度图和深度隐藏状态。重复本步骤m次,m为正整数,优选为4。
[0052]
4.2,更新位姿。将位姿隐藏状态、增强成本和初始位姿输入到位姿多级感知优化器,得到更新的位姿和新的位姿隐藏状态,分别作为下一次迭代的初始位姿和位姿隐藏状态。重复本步骤n次,n为正整数,优选为4。
[0053]
4.3,重复步骤4.1到4.2k次,k为正整数,优选为10。得到最终预测的深度图和位姿。
[0054]
步骤5,损失函数计算与网络参数更新。利用步骤4得到的深度图和位姿,以及深度图和位姿的真实值,根据以下损失函数计算损失:
[0055]
l=l
psoe
+l
depth
,
[0056][0057][0058]
其中,d
*
和pi
*
表示真实深度和位姿,γ表示衰减系数,k表示迭代总次数,t 表示第t次迭代。作为优选,k取值为3,γ取值为0.85。经过上述计算损失之后,进行反向传播更新网络参数。
[0059]
步骤6,重复步骤1到步骤5,直到损失函数收敛,例如在kitti数据集上迭代40个周期,得到基于分组双增强模块和多级感知优化器的深度图与位姿优化模型。图5为本发明的消融实验结果图,加粗的数值表示最优的结果。可以看到,本发明的各个模块都有效提高了基线的性能,并且当所有模块结合后,能达到最佳性能。图6为本发明与现有先进方法的深度估计结果对比,加粗的数值表示最优的结果,可以看到,本发明的精度超过了现有算法。
[0060]
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1