一种基于kubernetes的全链路监控方法与流程
1.本发明涉及全链路监控技术领域,具体而言,涉及一种基于kubernetes的全链路监控方法。
背景技术:
2.随着分布式系统和微服务架构的应用和发展,全链路监控成为系统运维管理和网络管理的一个重要方向,它能够对企业的关键业务应用进行监测、优化,提高企业应用的可靠性和质量,保证用户得到良好的服务,降低it总拥有成本(tco)。全链路监控能够对整个企业的it系统各个层面进行集中的性能监控,并对有可能出现的性能问题进行及时、准确的分析和处理。它能轻松地从一个it应用系统中找到故障点,并提供有相关解决建议或方法,从而提高整体的系统性能。一个企业的关键业务应用的性能强大,可以保证企业业务应用系统的高效性和稳定性,为企业带来核心竞争力的提升。
3.kubernetes是google开源的一个容器编排引擎,它支持自动化部署、大规模可伸缩、应用容器化管理。在生产环境中部署一个应用程序时,通常要部署该应用的多个实例以便对应用请求进行负载均衡。
4.当下成熟的互联网公司都建立有从基础设施到应用程序的全方位监控系统,力求及时发现故障进行处理并为优化程序提供性能数据支持,降低整体运维成本,因此需要提高全链路监控的功能和全面性,因此我们提出一种新的基于kubernetes的全链路监控方法。
技术实现要素:
5.本发明的主要目的在于提供一种基于kubernetes的全链路监控方法,以改善相关技术中的问题。
6.为了实现上述目的,本发明提供了一种基于kubernetes的全链路监控方法,包括以下具体步骤:
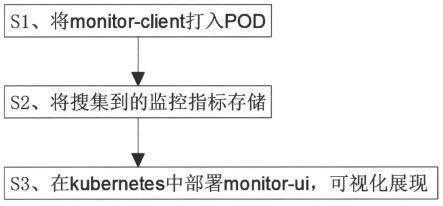
7.s1、将monitor-client打入pod;
8.s2、将搜集到的监控指标存储;
9.s3、在kubernetes中部署monitor-ui,可视化展现。
10.在本发明的一种实施例中,s1中,通过文件共享的方式将monitor-client以sidcar模式打入应用pod中。
11.在本发明的一种实施例中,将monitor-client与业务应用代码相互独立。
12.在本发明的一种实施例中,s2中,将s1中的monitor-client将从业务应用中搜集到的监控指标信息发送到monitordb中存储。
13.在本发明的一种实施例中,s3中,将第一步汇总至monitor-db的各种监控指标可视化展示。
14.在本发明的一种实施例中,创建一个statefulset部署应用服务。filebeat以
sidecar形式一起部署statefulset.yaml。
15.在本发明的一种实施例中,s3中,monitor在部署的时安装cx_oracle,安装mysqldb,编辑mysql_config,最后安装安装paramiko。
16.在本发明的一种实施例中,在安装cx_oracle时,注意配置oracle_home。
17.与现有技术相比,本发明的有益效果是:通过上述设计的基于kubernetes的全链路监控方法,使用时,将monitor-client打入pod:通过文件共享的方式将monitor-client以sidcar模式打入应用pod中,并不在业务代码中做修改,与业务应用代码相互独立;将搜集到的监控指标存储:第一步中monitor-client将从业务应用中搜集到的监控指标信息发送到monitordb中存储;在kubernetes中部署monitor-ui,可视化展现,将第一步汇总至monitor-db的各种监控指标可视化展示。本方法基于kubernetes进行全链路追踪,有良好的可扩展性,可移植性和可维护性,使kubernetes应用调用链监控可视化,透明化,同时包括以下功能:请求链路追踪,故障快速定位:可以通过调用链结合业务日志快速定位错误信息;可视化:各个阶段耗时,进行性能分析;依赖优化:各个调用环节的可用性、梳理服务依赖关系以及优化;数据分析,优化链路:可以得到用户的行为路径,汇总分析应用在很多业务场景。与现有技术相比,通过将公用基础设施相关功能抽象到不同的层来降低微服务的代码复杂性;由于不需要在每个微服务中编写配置代码,因此减少了微服务架构中的代码重复,并且应用和底层平台之间实现了松耦合。
附图说明
18.图1为根据本发明实施例提供的基于kubernetes的全链路监控方法的方法流程示意图;
19.图2为根据本发明实施例提供的基于kubernetes的全链路监控方法的技术方案示意图;
20.图3为根据本发明实施例提供的基于kubernetes的全链路监控方法的全链路示意图;
21.图4为根据本发明实施例提供的基于kubernetes的全链路监控方法的monitor server启动时示意图。
具体实施方式
22.为了使本技术领域的人员更好地理解本发明方案,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分的实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都应当属于本发明保护的范围。
23.需要说明的是,本发明的说明书和权利要求书及上述附图中的术语“第一”、“第二”等是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。应该理解这样使用的数据在适当情况下可以互换,以便这里描述的本发明的实施例。此外,术语“包括”和“具有”以及他们的任何变形,意图在于覆盖不排他的包含,例如,包含了一系列步骤或单元的过程、方法、系统、产品或设备不必限于清楚地列出的那些步骤或单元,而是可包括没有清
楚地列出的或对于这些过程、方法、产品或设备固有的其它步骤或单元。
24.在本发明中,术语“上”、“下”、“左”、“右”、“前”、“后”、“顶”、“底”、“内”、“外”、“中”、“竖直”、“水平”、“横向”、“纵向”等指示的方位或位置关系为基于附图所示的方位或位置关系。这些术语主要是为了更好地描述本发明及其实施例,并非用于限定所指示的装置、元件或组成部分必须具有特定方位,或以特定方位进行构造和操作。
25.并且,上述部分术语除了可以用于表示方位或位置关系以外,还可能用于表示其他含义,例如术语“上”在某些情况下也可能用于表示某种依附关系或连接关系。对于本领域普通技术人员而言,可以根据具体情况理解这些术语在本发明中的具体含义。
26.另外,术语“多个”的含义应为两个以及两个以上。
27.需要说明的是,在不冲突的情况下,本发明中的实施例及实施例中的特征可以相互组合。下面将参考附图并结合实施例来详细说明本发明。
28.实施例1
29.请参阅图1-图3,本发明提供了一种基于kubernetes的全链路监控方法,包括以下具体步骤:
30.s1、将monitor-client打入pod;
31.s2、将搜集到的监控指标存储;
32.s3、在kubernetes中部署monitor-ui,可视化展现。
33.heapster:集群中各node节点的cadvisor的数据采集汇聚系统,通过调用node上kubelet的api,再通过kubelet调用cadvisor的api来采集所在节点上所有容器的性能数据。heapster对性能数据进行聚合,并将结果保存到后端存储系统,heapster支持多种后端存储系统,如memory,influxdb等。
34.influxdb:分布式时序数据库(每条记录有带有时间戳属性),主要用于实时数据采集,时间跟踪记录,存储时间图表,原始数据等。influxdb提供rest api用于数据的存储与查询。
35.grafana:通过dashboard将influxdb中的时序数据展现成图表或曲线等形式,便于查看集群运行状态。
36.heapster,influxdb,grafana均以pod的形式启动与运行。
37.准备images:
38.kubernetes部署服务时,为避免部署时发生pull镜像超时的问题,建议提前将相关镜像pull到相关所有节点(以下以kubenode1为例),或搭建本地镜像系统。
39.需要从gcr.io pull的镜像,已利用docker hub的
″
create auto-build github
″
功能(docker hub利用github上的dockerfile文件build镜像),在个人的docker hub build成功,可直接pull到本地使用。
40.下载yaml范本;
41.heapster-rbac.yaml;
42.heapster.yaml;
43.hepster.yaml由3个模块组成:serviceaccout,deployment,service。
44.1、serviceaccount默认不需要修改serviceaccount部分,设置serviceaccount资源,获取rbac中定义的权限。
45.2、deployment;
46.3、service:
47.默认不需要修改service部分。
48.influxdb.yaml由2个模块组成:deployment,service。
49.1、deployment;
50.2、service:
51.默认不需要修改service部分,注意service名字的对应即可。
52.grafana.yamlgrafana.yaml由2个模块组成:deployment,service。
53.启动监控相关服务;
54.查看相关服务;
55.访问dashboard,浏览器访问访问dashboard:
56.https://172.30.200.10:6443/api/v1/namespaces/kube-57.system/services/https:kubernetes-dashboard:/proxy
58.注意:dasheboard没有配置hepster监控平台时,不能展示node,pod资源的cpu与内存等metric图形,node资源cpu/内存metric图形、pod资源cpu/内存metric图形。
59.访问grafana,浏览器访问dashboard:
60.https://172.30.200.10:6443/api/v1/namespaces/kube-system/services/monitoring-grafana/proxy
61.查看集群节点信息、pod信息。
62.sidecar模式是一种将应用功能从应用本身剥离出来作为单独进程的方式。该模式允许我们向应用无侵入添加多种功能,避免了为满足第三方组件需求而向应用添加额外的配置代码。
63.就像边车加装在摩托车上一样,在软件架构中,sidecar附加到主应用,或者叫父应用上,以扩展/增强功能特性,同时sidecar与主应用是松耦合的。
64.结合图1、图2和图3,将monitor-client打入pod:通过文件共享的方式将monitor-client以sidcar模式打入应用pod中,并不在业务代码中做修改,与业务应用代码相互独立;将搜集到的监控指标存储:第一步中monitor-client将从业务应用中搜集到的监控指标信息发送到monitordb中存储;在kubernetes中部署monitor-ui,可视化展现,将第一步汇总至monitor-db的各种监控指标可视化展示。本方法基于kubernetes进行全链路追踪,有良好的可扩展性,可移植性和可维护性,使kubernetes应用调用链监控可视化,透明化,同时包括以下功能:请求链路追踪,故障快速定位:可以通过调用链结合业务日志快速定位错误信息;可视化:各个阶段耗时,进行性能分析;依赖优化:各个调用环节的可用性、梳理服务依赖关系以及优化;数据分析,优化链路:可以得到用户的行为路径,汇总分析应用在很多业务场景。与现有技术相比,通过将公用基础设施相关功能抽象到不同的层来降低微服务的代码复杂性;由于不需要在每个微服务中编写配置代码,因此减少了微服务架构中的代码重复,并且应用和底层平台之间实现了松耦合。
65.s1中,通过文件共享的方式将monitor-client以sidcar模式打入应用pod中,并不在业务代码中做修改,与业务应用代码相互独立;具体设置时,定义日志收集相关配置的一个通配configmap,test-filebeat-config.yaml。创建一个statefulset部署应用服务。
filebeat以sidecar形式一起部署statefulset.yaml;导入并上传镜像;应用yaml。等到容器启动完成,进入容器需要-c指定容器name,如果不使用-c的话会进入sidecar容器。
66.手动输出error到error日志或者info日志,观察monitor发现采集成功。
67.ceph monitor的子命令,通过子命令的配合实现对mon的管理和配置。
68.1.添加(add)
69.在某个地址上新增一个名字为《name》的mon服务:
70.ceph mon add《name》《ipaddr[:port]》;
[0071]
2.导出(dump)
[0072]
显示特定版本的mon map的格式化的信息,该命令可以指定mon map的版本信息,具体示例如下,参数为epoch:
[0073]
ceph mon dump{《int[0-]》}
[0074]
ceph mon dump 1;
[0075]
3.获取映射(getmap)
[0076]
获取特定版本的mon map信息,该命令获取的是二进制的信息,可以保持在某个文件中,具体格式如下:
[0077]
ceph mon getmap{《int[0-]》}:
[0078]
4.移除(remove)
[0079]
移除特定名称的mon服务节点。具体格式如下:
[0080]
ceph mon remove《name》;
[0081]
5.获取状态(stat)
[0082]
显示mon的摘要状态信息,具体格式如下:
[0083]
ceph mon stat;
[0084]
6.报告状态(mon_status)
[0085]
报告mon的状态,相对详细,具体格式如下:
[0086]
ceph mon_status。
[0087]
monitor管理了ceph的状态信息,维护着ceph中各个成员的关系,这些信息都是存放在leveldb中的。monitor更新一个值的流程:
[0088]
1、leader
[0089]
1)设置new_value=v,v中值就是我们上面看到的paxos:1869中的值,都是kv。
[0090]
2)将自己加入到同意者集合。
[0091]
3)生成monitordbstore::transaction,以paxos为前缀,last_commited+1的key来将v写入到leveldb中,同时更新pending_v,和pending_pn。
[0092]
4)将new_value,last_commited和accepted_pn发送给quorum中的所有成员。
[0093]
2、peon
[0094]
1)判断自己的accepted_pn和leader发送过来的accepted_pn是否相等,如果小于就忽略,认为是旧一轮的决议。
[0095]
2)判断自己last_commited是否和leader发送过来的相关,如果不相关,就是出现了不一致,直接assert。
[0096]
3)同leader中的3)。
[0097]
4)将accpted_pn和last_commited发送给leader。
[0098]
3、leader
[0099]
1)判断peon发送过来的pn是不是和自己的accepted_pn一致,如果不等可能有则返回。
[0100]
2)判断last_commited,如果peon发送过来的last_commited比last_commted-1小,则认为是旧一轮的消息,丢弃。
[0101]
3)判断peon是否在同意者结合,如果不在就加入,如果在,说明一个peon发送了两次accept消息,leader直接assert。
[0102]
4)当接受者结合和quorum结合一样的时候,也就是大多数人都同意了,leader提交决议。
[0103]
5)更新leveldb中的last_commited为last_commited+1。
[0104]
6)将new_value中的数据都展开封装成transaction,然后写入,插入回调。
[0105]
7)当leader完成本地的提交之后,调用回调向quorum中的所有成员发送commit消息。
[0106]
4、peon
[0107]
1)在接收到commit消息之后,进行内部提交。
[0108]
需要说明的是:
[0109]
在决议的过程中其实提交了leader提交了两次,一次是直接将决议当做bl写入paxos的prefix中,另一次是将bl解析出来(bl里的内容都是封装的小的op操作)在写入bl里封装的prefix的库中。
[0110]
所有的update操作的请求都会路由到leader,也就是说无论你有3个,或者5个,在处理update请求的时候只会是1个。
[0111]
monitor的主要任务就是维护集群视图的一致性,在维护一致性的时候使用了paxos协议,并将其实例化到数据库中,方便后续的访问。所以monitor基本上是由三类结构支撑起来的,第一类是管理各种map和相关内容的paxosservice实例,第二类是paxos实例,第三类是对k/v store的封装,即monitordbstore实例。
[0112]
paxos实例主要是实现paxos协议,然后应用于选主和处理update请求。
[0113]
选主(三个mon同时启动):
[0114]
1)mon启动进入prboing
[0115]
2)当一个mon probing到超半数的mon的时候,就会发起选举
[0116]
3)发起选举的mon会向所有的mon发起propose
[0117]
4)mon处理propose消息的时候会根据自己的rank来决定是重新发起选举还是defer
[0118]
5)如果所有的mon都ack,或者过半数mon回复ack(超时后检查),则选举成功,自己进行leader init,向其它mon发victory消息
[0119]
6)其它mon则lose_election,进入peon_init。
[0120]
7)在此之后,leader会发collect消息去收集peon的信息,为了后续处理请求能达成一致。
[0121]
这样看起来,分工是很明确的,paxosservice handle client过来的请求,paxos
用来处理paxos协议相关的东西,一般在选主和处理update请求的时候才会涉及,而在处理读请求的时候一般不会涉及。monitordbstore是处理数据存储相关的封装,用来将update的数据进行持久化
[0122]
将搜集到的监控指标存储:s1中monitor-client将从业务应用中搜集到的监控指标信息发送到monitordb中存储。具体设置时,使用zabbix监控。每次monitor启动时都会按照monmap中的服务器地址去连接其他monitor服务器,并同步数据。这里有两种情况,一种是db中不存在monmap(需要执行mkfs重新产生),另一种是已经添加过的mon节点由于网络或者其他原因异常,恢复正常后的重启(直接从db中读取)。所有的节点都会从无到有,因此这里的两种情况其实只是单存的区分获取monmap的方式。需要说明的是:monmap很重要,一且产生,之后的启动不会再重新配置,因此一定要确保配置的正确性。
[0123]
见图4,每次monitor server启动时都会按照monmap中的服务器地址去连接其他monitor服务器,并同步数据。这个过程叫做bootstrap().bootstrap的第一个目的是补全数据,从其他服务拉缺失的paxos log或者全量复制数据库,其次是在必要时形成多数派建立一个paxos集群或者加入到已有的多数派中。所有收到op_probe的节点,根据handle_probe中定义的op类型,采用函数handle_probe_probe开始处理了。发送探测包的monitor节点,在最大超时时间内收到op_reply,会调用handle_probe_reply函数进行下一步处理。
[0124]
monmap的各种操作包括:
[0125]
1.stop ceph-mon id=*
[0126]
停掉mon-2,不停掉是操作不了monmap的db的
[0127]
2.导出monmap:
[0128]
ceph-mon-i id-foo-extract-monmap/tmp/monmap
[0129]
3.查看monmap:
[0130]
monmaptool-print-f/tmp/monmap
[0131]
4.删除mon-3
[0132]
monmaptool-rm mon-3-f/tmp/monmap
[0133]
5.注入monmap
[0134]
ceph-mon-i id-inject-monmap/tmp/monmap
[0135]
s3中,将s1中搜集到的监控指标信息汇总至monitor-db的各种监控指标可视化,展示具体设置时,monitor在部署的时安装cx_oracle,安装mysqldb,编辑mysql_config,最后安装安装paramiko。
[0136]
通过将公用基础设施相关功能抽象到不同的层来降低微服务的代码复杂性,实现了以下功能:请求链路追踪,故障快速定位:可以通过调用链结合业务日志快速定位错误信息;可视化:各个阶段耗时,进行性能分析;依赖优化:各个调用环节的可用性、梳理服务依赖关系以及优化;数据分析,优化链路:可以得到用户的行为路径,汇总分析应用在很多业务场景。
[0137]
具体设置时,安装cx_oracle,输入[dbmon@mysql~]$tar-xvzfcx_oracle-5.1.3.tar.gz。
[0138]
注意配置oracle_home,否则会报错:
[0139]
[root@mysql cx_oracle-5.1.3]#python setup.py install
[0140]
traceback(most recent call last):
[0141]
file
″
setup.py
″
,line 135,in《module》
[0142]
raise distutilssetuperror(
″
cannot locate an oracle software
″
\
[0143]
distutils.errors.distutilssetuperror:cannot locate an oracle software installation。
[0144]
如果配置后依然报错,将oracle_home中的libclntsh.so.11.1复制一份到libclntsh.so即可:
[0145]
[dbmon@mysql instantclient_11_2]$cp libclntsh.so.11.1 libclntsh.so。
[0146]
碰到权限问题,赋权后重新执行
[0147]
[root@mysql~]#chown-r dbmon:dbmon/usr/local/python-2.7.14。
[0148]
安装mysqldb:
[0149]
[root@mysql~]#unzip mysql-python-1.2.5.zip;
[0150]
编辑mysql_config:
[0151]
[root@mysql mysql-python-1.2.5]#vi site.cfg;
[0152]
mysql_config=/u01/my3306/bin/mysql_config;
[0153]
build;
[0154]
报错;
[0155]
建立链接:
[0156]
[root@mysql check&alarrm]#ln-s/u01/my3306/lib/libmysqlclient.so.18/usr/lib64/libmysqlclient.so.18;
[0157]
安装paramiko:
[0158]
paramiko依赖于pycrypto模块;
[0159]
[root@mysql~]#tar zxvf pycrypto-2.6.1.tar.gz;
[0160]
[root@mysql~]#cd pycrypto-2.6.1;
[0161]
[root@mysql pycrypto-2.6.1]#python setup.py install;
[0162]
[root@mysql~]#unzip paramiko-1.7.7.1.zip;
[0163]
[root@mysql~]#cd paramiko-1.7.7.1;
[0164]
[root@mysql paramiko-1.7.7.1]#python setup.py install。
[0165]
解压k8s目录中的压缩文件、进入指定目录
[0166]
tar-xvzf/root/k8s/kubernetes/kubernetes-src.tar.gz
[0167]
cd cluster/addons/dashboard/
[0168]
修改dashboard-controller.yaml配置文件中的镜像,vim dashboard-controller.yaml。
[0169]
master端k8s创建配置文件中的配置;
[0170]
查看创建进项,name ready status restarts age
[0171]
kubernetes-dashboard-75584d7f6f-fpdhp 1/1 running 0 21s;
[0172]
查看日志详情;
[0173]
修改service配置文件添加网络;
[0174]
创建service服务,kubectl create-f dashboard-service.yaml;
[0175]
查看创建信息,
[0176]
name type cluster-ip external-ip port(s)age
[0177]
kubernetes-dashboard nodeport 10.0.0.162《none》443:42487/tcp 46s;
[0178]
测试访问,使用node节点外网ip;
[0179]
创建k8s-admin.yaml文件、创建管理绑定指定用户到cluster-admin;
[0180]
创建生成yaml文件中的服务,kubectl create-f k8s-admin.yaml;
[0181]
查看产生的token结果;
[0182]
复制下方token输出值、复制到网站kubernetes仪表板中令牌,kubectl describe secret dashboard-admin-token-xhw6x-n kube-system;
[0183]
输入密令。
[0184]
将monitor-client打入pod:通过文件共享的方式将monitor-client以sidcar模式打入应用pod中,并不在业务代码中做修改,与业务应用代码相互独立;将搜集到的监控指标存储:第一步中monitor-client将从业务应用中搜集到的监控指标信息发送到monitordb中存储;在kubernetes中部署monitor-ui,可视化展现,将第一步汇总至monitor-db的各种监控指标可视化展示。本方法基于kubernetes进行全链路追踪,有良好的可扩展性,可移植性和可维护性,使kubernetes应用调用链监控可视化,透明化,同时包括以下功能:请求链路追踪,故障快速定位:可以通过调用链结合业务日志快速定位错误信息;可视化:各个阶段耗时,进行性能分析;依赖优化:各个调用环节的可用性、梳理服务依赖关系以及优化;数据分析,优化链路:可以得到用户的行为路径,汇总分析应用在很多业务场景。与现有技术相比,通过将公用基础设施相关功能抽象到不同的层来降低微服务的代码复杂性;由于不需要在每个微服务中编写配置代码,因此减少了微服务架构中的代码重复,并且应用和底层平台之间实现了松耦合。
[0185]
具体的,该基于kubernetes的全链路监控方法的工作原理:使用时,将monitor-client打入pod:通过文件共享的方式将monitor-client以sidcar模式打入应用pod中,并不在业务代码中做修改,与业务应用代码相互独立;将搜集到的监控指标存储:第一步中monitor-client将从业务应用中搜集到的监控指标信息发送到monitordb中存储;在kubernetes中部署monitor-ui,可视化展现,将第一步汇总至monitor-db的各种监控指标可视化展示。本方法基于kubernetes进行全链路追踪,有良好的可扩展性,可移植性和可维护性,使kubernetes应用调用链监控可视化,透明化,同时包括以下功能:请求链路追踪,故障快速定位:可以通过调用链结合业务日志快速定位错误信息;可视化:各个阶段耗时,进行性能分析;依赖优化:各个调用环节的可用性、梳理服务依赖关系以及优化;数据分析,优化链路:可以得到用户的行为路径,汇总分析应用在很多业务场景。与现有技术相比,通过将公用基础设施相关功能抽象到不同的层来降低微服务的代码复杂性;由于不需要在每个微服务中编写配置代码,因此减少了微服务架构中的代码重复,并且应用和底层平台之间实现了松耦合。
[0186]
以上所述仅为本发明的优选实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1