众核实现的超越函数处理方法与流程
1.本发明涉及一种众核实现的超越函数处理方法,属于高性能计算技术领域。
背景技术:
2.数学函数库是处理器的基础和核心软件之一,而超越函数是数学函数库的重要组成部分。超越函数相比传统四则运算,由于其非线性的特性,其运算难度和代价开销远大于传统的加减乘除运算。现有技术在处理超越函数问题时,存在计算速度慢、运行效率低、不同数据规模和精度计算支持不够灵活等问题。
3.在现有技术中,最常用的办法有两种:一种是设计超越函数计算的通用处理器,该方法使用通用寄存器和通用功能计算部件执行各种超越函数,但存在通用计算部件无法与专用计算装置整合的问题,导致其它步骤无法享受此类装置进行性能提升;并且,通用处理器的实现过程中通常把超越函数计算转化为运算及访存指令序列,该过程处理器运算时消耗较大的资源开销。另一种方法是造表查表分析法,该方法通过把非线性曲线分成若干个区间,在每个区间使用直线段逼近特性曲线;在实际工程应用中,超越函数的计算可能是已知的,或者并不需要很高的计算精度,例如,在人工智能领域,计算精度一般达到十进制条件下的10-3
即可。
4.不管是通用处理器,还是查表分析法都能在一定范围内收敛,当现阶段随着模型不断的增加,以及数据复杂度的提升,尤其是对于大规模科学计算,为了达到较好的收敛效果,通常采用不同精度对模型、数据进行量化处理,对超越函数的处理提出了一个较大的挑战。
技术实现要素:
5.本发明的目的是提供一种众核实现的超越函数处理方法,以解决如何在处理器上实现不同精度的超越函数计算的问题。
6.为达到上述目的,本发明提供一种众核实现的超越函数处理方法,包括以下步骤:
7.步骤1、通过一定的数学变换,将超越函数转换为常用的基本函数的复合运算实现;
8.步骤2、利用数学函数的性质,将经过步骤1转换后的超越函数按照多项式的形式展开计算,获得相应的多项式函数实现,该多项式函数通常包含无穷个多项式系数;
9.步骤3、结合函数特性,将超越函数的输入区间分解为若干个收敛区间,采用近似多项式逼近的方式,将步骤2中生成的无穷多项式系数降低到有限数量的多项式系数,在每个收敛区间中用近似多项式函数来拟合步骤2中得到的超越函数展开的多项式函数,通过误差逼近来获得收敛区间的范围以及对应的近似多项式函数的系数,具体包括:
10.步骤31、根据步骤2中得到的超越函数展开的多项式函数来初始化近似多项式函数的系数,根据不同精度,设置近似多项式函数与数学函数之间的最大误差;
11.步骤32、初始化近似多项式的收敛区间的数量以及每个收敛区间的范围;
12.步骤33、结合函数特征,利用穷举或者随机生成法,生成每个收敛区间的训练数据;
13.步骤34、将训练数据作为输入,将近似多项式函数和超越函数的实际结果进行对比,得到两者之间的相对误差,若相对误差小于最大误差,则证明该例数据有效,统计有效的训练数据概率和对应边界点的值;
14.步骤35、重复步骤32、33、34,直至每个收敛区间的有效训练数据概率大于设定的概率阈值,则该条件下的收敛区间以及近似多项式函数的系数则为近似多项式拟合超越函数的最佳收敛区间和系数。
15.上述技术方案中进一步改进的方案如下:
16.1.上述方案中,还包括以下步骤:
17.步骤41、针对步骤3得到的近似多项式函数的收敛区间和系数,分析超越函数的数据表,改变数学函数输入与数据表之间的映射关系,通过重新组合数据,压缩数据;
18.步骤42、针对步骤41得到的压缩后的数据表,进一步消除函数代码实现中的访存操作;
19.步骤43、在代码实现过程中,针对近似多项式函数的部分四则运算,使用simd加速方法对不同长度的数据进行更深度的加速计算
20.2.上述方案的步骤1中,所述超越函数包括非基本的超越函数和基本的超越函数,所述基本函数包括三角函数、指数函数、反三角函数和对数函数。
21.由于上述技术方案的运用,本发明与现有技术相比具有下列优点:
22.本发明众核实现的超越函数处理方法,其通过近似多项式确定函数收敛区间,减少超越函数的计算时间、提高计算精确度;同时针对不同精度条件,通过修改算法模板参数生成不同精度下的超越函数代码,支持不同长度数据、不同精度数据集,避免片上资源大量消耗、计算效率高。
附图说明
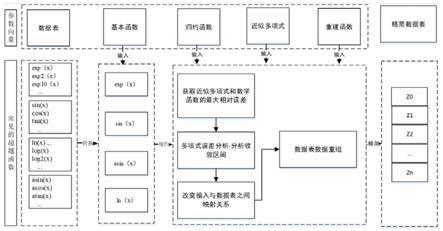
23.附图1为本发明超越函数处理方法的示意图。
具体实施方式
24.实施例:本发明提供一种众核实现的超越函数处理方法,通过多项式和误差分析法近似得到超越函数计算的分段收敛区间,减少超越函数计算的访问时间;首先,利用函数性质将超越函数转换为等价的表达式,将函数的输入区间规约到一个较小的区间;然后,使用近似多项式进行逼近超越函数计算过程,通过逼近多项式和函数之间的最大误差,确定到函数收敛范围和近似多项式的系数等参数;最后,将逼近的近似值代入逼近多项式函数,完成超越函数的重建;使用simd方法对近似后多项式加速计算,减少不必要的访问时间,提高数据计算的精度;该方法通过修改模型的不同参数,来完成不同精度条件下超越函数代码的生成;
25.具体包括以下步骤:
26.步骤1、通过一定的数学变换,将超越函数转换为常用的基本函数的复合运算实现;
27.步骤2、利用数学函数的性质,将经过步骤1转换后的超越函数按照多项式的形式(例如泰勒公式展开)展开计算,获得相应的多项式函数实现,该多项式函数通常包含无穷个多项式系数;
28.步骤3、结合函数特性,将超越函数的输入区间分解为若干个收敛区间,采用近似多项式逼近的方式,将步骤2中生成的无穷多项式系数降低到有限数量的多项式系数,在每个收敛区间中用近似多项式函数来拟合步骤2中得到的超越函数展开的多项式函数,通过误差逼近来获得收敛区间的范围以及对应的近似多项式函数的系数,具体包括:
29.步骤31、根据步骤2中得到的超越函数展开的多项式函数来初始化近似多项式函数的系数,根据不同精度,设置近似多项式函数与数学函数之间的最大误差;
30.步骤32、初始化近似多项式的收敛区间的数量以及每个收敛区间的范围;
31.步骤33、结合函数特征,利用穷举或者随机生成法,生成每个收敛区间的训练数据;
32.步骤34、将训练数据作为输入,将近似多项式函数和超越函数的实际结果进行对比,得到两者之间的相对误差,若相对误差小于最大误差,则证明该例数据有效,统计有效的训练数据概率和对应边界点的值;
33.步骤35、重复步骤32、33、34,直至每个收敛区间的有效训练数据概率大于设定的概率阈值,则该条件下的收敛区间以及近似多项式函数的系数则为近似多项式拟合超越函数的最佳收敛区间和系数。
34.以上步骤通过理论方法改进众核平台上的超越函数实现,步骤4通过代码层面在访存和计算方法上进一步优化该实现方法:
35.步骤41、针对步骤3得到的近似多项式函数的收敛区间和系数,分析超越函数的数据表,改变数学函数输入与数据表之间的映射关系,通过重新组合数据,压缩数据表,从而进一步降低近似多项式函数的计算量;
36.步骤42、针对步骤41得到的压缩后的数据表,进一步消除函数代码实现中的访存操作;
37.步骤43、在代码实现过程中,针对近似多项式函数的部分四则运算,使用simd加速方法对不同长度的数据进行更深度的加速计算。
38.步骤1中的所述超越函数包括非基本的超越函数和基本的超越函数,所述基本函数包括三角函数、指数函数、反三角函数和对数函数。
39.对上述实施例的进一步解释如下:
40.针对现阶段不同长度数据,为了充分提高处理器的应用性能,针对特定的需求定制关键函数,提出一种能够在处理器上实现的可变精度的超越函数处理方法,用于执行常用的三角、双曲、指数或对数函数等运算,该方法依据数据的特点分析归纳常用超越函数,在兼顾各种超越函数的基础上,构建超越函数通用处理转换、规约、逼近、重建的算法模板,实现不同的类型的超越函数;
41.该模板将不同长度数据进行多项式展开近似计算,得到近逼近多项式的最大误差和最大逼近区间,计算过程中调整算法模板参数,确定近似多项式的误差范围和收敛区间以及近似多项式的系数,同时根据不同精度的要求,调整模板参数生成不同精度版本的超越函数计算代码;
42.首先,预定义超越函数能够收敛的区间,将超越函数转化为多项式方式展开近似计算,在此基础上对预定义的收敛区间进行调整,得到调整后的函数与数学函数之间的最大误差,构建出一套转换、规约、逼近、重建的算法模板,实现超越函数计算;
43.同时,根据不同精度要求,调整算法模板参数来控制误差范围和收敛区间,该过程的迭代计算,得到不同精度版本的超越函数。
44.超越函数设计本身只考虑其数学特性,不考虑函数之间的关联关系前提下,其实现步骤如下:
45.1、转换操作:将非基本的超越函数或者基本的超越函数,通过一定的数学变换,转换为常用的基本函数的复合运算,基本函数主要分为4类sin(x)、exp(x)、asin(x)、ln(x);
46.2、规约操作:利用数学函数的性质,将转换后的超越函数按照多项式的形式展开计算,即近似多项式;
47.3、逼近操作:结合函数特性,近似多项式逼近的方式,使得其近似超越函数的计算,得到函数收敛范围和多项式系数等参数;
48.a)从超越函数实现中获取数学函数的近似多项式,根据不同精度,设置逼近多项式与数学函数之间的最大误差;
49.b)初始化近似多项式的收敛区间;
50.c)结合函数特征,利用穷举或者随机生成法,生成收敛区间的测试数据;
51.d)根据测试集数据,采用将近似多项式和超越含糊的实际结果进行对比,得到两者之间的相对误差,若相对误差小于最大误差,则统计该条件下的测试集个数和对应边界点的值;
52.e)重复以上(c)、(d)、(e)步骤,统计相对误差小于最大相对误差的概率,直至最大误差的概率大于设定阈值条件,则该条件下的收敛区间则为近似多项式拟合超越函数的最佳收敛区间;
53.f)通过区间分析的多项式误差分析方法,得到当前误差多项式的系数;
54.4、重建操作:
55.a)针对多项式收敛区间,结合规约函数,分析超越函数的数据表,改变数学函数输入与数据表之间的映射关系,通过重新组合数据,压缩数据表;
56.b)压缩后的数据表,消除函数实现中的访存操作;
57.c)针对近似多项式的部分四则运算,使用simd加速方法对不同长度的数据进行加速计算。
58.[0059][0060]
采用上述众核实现的超越函数处理方法时,其通过近似多项式确定函数收敛区间,减少超越函数的计算时间、提高计算精确度;同时针对不同精度条件,通过修改算法模板参数生成不同精度下的超越函数代码,支持不同长度数据、不同精度数据集,避免片上资源大量消耗、计算效率高。
[0061]
上述实施例只为说明本发明的技术构思及特点,其目的在于让熟悉此项技术的人士能够了解本发明的内容并据以实施,并不能以此限制本发明的保护范围。凡根据本发明精神实质所作的等效变化或修饰,都应涵盖在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1