面向数据双重不平衡的降偏场景图生成方法及系统
1.本发明涉及图像处理技术领域,尤其涉及一种面向数据双重不平衡的降偏场景图生成方法及系统。
背景技术:
2.目前,场景图生成(scene graph generation,简称sgg)通过探索对象之间的关系,在深度理解视觉场景语义方面起着至关重要的作用,被广泛应用于各种视觉智能和推理任务,例如图像检索和视觉问答等。
3.现实中数据集的关系分布通常是有偏的,数据集中头部关系类别占据了主导地位,体现为典型的长尾分布。由于缺乏足够的训练样本,样本少的尾部关系类别在训练中会被样本多的头部关系类别所压制,并出现相关类别特征代表性不足而导致的关系识别准确性降低的问题。为了提高sgg中长尾分布的关系识别准确性,对于此前有偏的场景图生成方法,具体是通过挖掘对象之间的统计相关性来拟合高度偏斜的分布,并忍受了尾部类别关系的较差性能。有人提出了基于降偏的场景图生成方法来减轻头部关系类别对尾部关系类别的抑制,例如,tang kaihua等在中国知网发表的期刊《unbiased scene graph generation from biased training》提出了反事实因果关系以消除不良偏见的影响。
4.然而,除前景的长尾分布不平衡之外,sgg中背景样本(即未被标注的关系)的数量明显超过前景样本(即被人为标注的关系)。例如,在目前常用的权威数据集visual genome的一个子集vg150(vg中出现频率最高的150类物体和50类关系)中,背景样本数量是前景样本数量的18倍数,具体来说,根据vg150数据集上的统计信息,每张图像的场景图包含大约11.5个对象和6.2个关系,也就是说,在这些对象生成的120个候选关系中,只有6.2个候选关系被标记为前景类别(约占5.13%),其余候选关系为背景类别(约占94.87%)。因此,sgg实际上面临的是数据双重不平衡挑战,即前景的长尾分布不平衡和背景与前景分布极不平衡。由于忽略了背景与前景分布极不平衡,现有基于降偏的场景图生成方法倾向于将头部关系实例分为背景类别和尾部类别,从而导致头部类别的关系识别性能遭受了巨大的衰减。
5.因此,如何缓解数据双重不平衡,即前景类别的长尾分布不平衡和背景与前景分布极不平衡给sgg任务带来的偏见依然是当前亟待解决的问题。
技术实现要素:
6.基于此,有必要针对上述技术问题,提供一种面向数据双重不平衡的降偏场景图生成方法及系统。
7.基于上述目的,本发明提供一种面向数据双重不平衡的降偏场景图生成方法,包括:
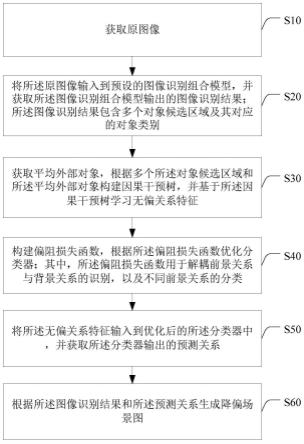
8.获取原图像;
9.将所述原图像输入到预设的图像识别组合模型,并获取所述图像识别组合模型输
出的图像识别结果;所述图像识别结果包含多个对象候选区域及其对应的对象类别;
10.获取平均外部对象,根据多个所述对象候选区域和所述平均外部对象构建因果干预树,并基于所述因果干预树学习无偏关系特征;
11.构建偏阻损失函数,根据所述偏阻损失函数优化分类器;其中,所述偏阻损失函数用于解耦前景关系与背景关系的识别,以及不同前景关系的分类;
12.将所述无偏关系特征输入到优化后的所述分类器中,并获取所述分类器输出的预测关系;
13.根据所述图像识别结果和所述预测关系生成降偏场景图。
14.优选地,所述获取平均外部对象,根据多个所述对象候选区域和所述平均外部对象构建因果干预树,并基于所述因果干预树学习无偏关系特征,包括:
15.对于生成n个所述对象候选区域的所述原图像,通过最小生成树算法构建n个初始节点的初始树;
16.通过在所述初始树中增加一个附加节点构建(n+1)个节点的因果干预树;所述附加节点表示平均外部对象;
17.对所述因果干预树中的每个所述节点进行特征赋予,确定每个所述节点的特征;
18.将每个所述节点的特征输入门控循环单元网络,通过所述门控循环单元网络对每一个候选关系的主语对象、宾语对象和平均外部对象之间进行消息传递,并通过全连接层输出候选关系的logit向量。
19.优选地,所述对所述因果干预树中的每个所述节点进行特征赋予,确定每个所述节点的特征,包括:
20.将所述因果干预树的每一个所述初始节点的特征设置为通过深度神经网络从对应的所述对象候选区域中学习的对象特征,并将所述因果干预树的所述附加节点的特征设置为所述平均外部对象的特征;所述平均外部对象的特征为通过移动平均方法对所有外部对象的特征进行计算得到平均特征。
21.优选地,所述构建偏阻损失函数,根据所述偏阻损失函数优化分类器,包括:
22.构建二分类损失函数,所述二分类损失函数用于识别前景与背景关系;
23.构建多分类损失函数,所述多分类损失函数用于分类各个前景关系;
24.通过对所述二分类损失函数和所述多分类损失函数进行联合构建偏阻损失函数,并对分类器进行优化。
25.优选地,所述构建二分类损失函数,所述二分类损失函数用于识别前景与背景关系,包括:
26.设定深度神经网络输出的logit向量为x=(x0,x1,
…
,x
|r|
),|r|为关系类别的数量,并设定logit向量对应的概率分布为p=(p0,p1,
…
,p
|r|
)以及对应的真实标签向量为y=(y0,y1,
…
,y
|r|
);
27.获取用于前景与背景二分类所需的二维logit向量x
bf
与所述深度神经网络输出的logit向量x的第一转换关系;所述第一转换关系为:
[0028][0029]
其中,x0、xi分别为logit向量x中的第一个logit值和第i个logit值,且i=(1,2,
…
,|r|);p0、pi分别为概率分布p中的第一个概率和第i个概率;β为第一权重参数,用于控制logit向量x中背景关系类别;
[0030]
获取用于前景与背景二分类所需的二维真实标签向量y
bf
与所述logit向量x对应的所述真实标签向量y的第二转化关系;所述第二转化关系为:
[0031][0032]
其中,y0为真实标签向量y中的第一个真实关系标签;
[0033]
根据二值交叉熵损失函数、所述第一转换关系和所述第二转化关系构建二元类损失函数l
bf
;所述二元类损失函数l
bf
表示为:
[0034][0035]
其中,为用于前景与背景二分类所需的logit向量;为用于前景与背景二分类所需的真实标签向量;σ为sigmoid函数;α为前景关系样本的权重参数。
[0036]
优选地,所述构建多分类损失函数,所述多分类损失函数用于分类各个前景关系,包括:
[0037]
定义权重项ω,该权重项ω表示为:
[0038][0039]
其中,r为候选关系;
[0040]
通过在softmax交叉熵损失函数中引入所述权重项ω,构建多分类损失函数l
fore
;所述多分类损失函数l
fore
表示为:
[0041][0042]
其中,pj为概率分布p中的第j个概率,且j=(0,1,2,
…
,|r|);yj为概率pj对应的真实关系标签。
[0043]
优选地,所述构建多分类损失函数,所述多分类损失函数用于分类各个前景关系,还包括:
[0044]
根据softmax均衡损失函数更新所述多分类损失函数l
fore
中的概率pj,更新后的所述概率pj表示为:
[0045]
[0046]
其中,xj为概率pj对应的logit值;xk为第k类关系类别对应的logit值,且k=(0,1,2,
…
,|r|);ωk为第k类关系类别对应的权重,表示为:
[0047]
ωk=1-e(k)t
λ
(fk)(1-yk),
[0048]
其中,e(k)为二元项,在k=0属于背景关系类别时,e(k)=0,而在k>0属于前景关系类别时,e(k)=1;t
λ
()为阈值函数,当第k类关系类别的频率fk小于阈值λ时,t
λ
()=1,否则t
λ
()=0;yk为第k类关系类别对应的真实关系标签。
[0049]
优选地,所述图像识别组合模型由依次连接的快速区域卷积神经网络和双向树结构长短期记忆网络组成;所述将所述原图像输入到预设的图像识别组合模型,并获取所述图像识别组合模型输出的图像识别结果,包括:
[0050]
通过所述快速区域卷积神经网络对输入的所述原图像进行对象检测,获取所述原图像中的多个对象候选区域;
[0051]
将每个所述对象候选区域输入到所述双向树结构长短期记忆网络,通过所述双向树结构长短期记忆网络提取每个所述对象候选区域对应的对象特征,并基于每个所述对象特征识别获得对应的对象类别。
[0052]
基于同一个发明构思,本发明还提供一种面向数据双重不平衡的降偏场景图生成系统,包括:
[0053]
图像获取模块,用于获取原图像;
[0054]
图像识别模块,用于将所述原图像输入到预设的图像识别组合模型,并获取所述图像识别组合模型输出的图像识别结果;所述图像识别结果包含多个对象候选区域及其对应的对象类别;
[0055]
无偏特征学习模块,用于获取平均外部对象,根据多个所述对象候选区域和所述平均外部对象构建因果干预树,并基于所述因果干预树学习无偏关系特征;
[0056]
优化模块,用于构建偏阻损失函数,根据所述偏阻损失函数优化分类器;其中,所述偏阻损失函数用于解耦前景关系与背景关系的识别,以及不同前景关系的分类;
[0057]
关系预测模块,用于将所述无偏关系特征输入到优化后的所述分类器中,并获取所述分类器输出的预测关系;
[0058]
场景图生成模块,用于根据所述图像识别结果和所述预测关系生成降偏场景图。
[0059]
优选地,所述无偏特征学习模块包括:
[0060]
初始树构建子模块,用于对于生成n个所述对象候选区域的所述原图像,通过最小生成树算法构建n个初始节点的初始树;
[0061]
因果干预子模块,用于通过在所述初始树中增加一个附加节点构建(n+1)个节点的因果干预树;所述附加节点表示平均外部对象;
[0062]
特征赋予模块,用于对所述因果干预树中的每个所述节点进行特征赋予,确定每个所述节点的特征;
[0063]
特征输出子模块,用于将每个所述节点的特征输入门控循环单元网络,通过所述门控循环单元网络对每一个候选关系的主语对象、宾语对象和平均外部对象之间进行消息传递,并通过全连接层输出候选关系的logit向量。
[0064]
由上述可知,本发明提供的面向数据双重不平衡的降偏场景图生成方法,首先通过图像识别组合模型对输入的原图像进行对象检测和对象分类,得到对象候选区域和对象
类别,然后根据对象候选区域和引入的平均外部对象构建因果干预树,并基于因果干预树学习关系无偏特征,接下来将关系无偏特征输入到根据偏阻损失函数优化后的分类器,得到预测关系,最后根据对象候选区域、对象类别以及预测关系生成降偏场景图。本发明通过因果干预树来减少因数据不平衡产生的上下文偏见,消除虚假相关并学习无偏关系特征,并通过偏阻损失函数优化分类器来减少场景图生成任务中从前景到背景以及从尾部前景到头部前景的双重不平衡的偏见,显著提高了关系预测的准确度,从而达到有效生成降偏场景图的目的。
附图说明
[0065]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
[0066]
图1为本发明一实施例中面向数据双重不平衡的降偏场景图生成方法的流程示意图;
[0067]
图2为本发明一实施例中面向数据双重不平衡的降偏场景图生成方法步骤s30的流程示意图;
[0068]
图3a为本发明一实施例中有偏场景图生成中关系特征空间分布图;
[0069]
图3b为本发明一实施例中无偏场景图生成中关系特征空间分布图;
[0070]
图4为本发明一实施例中面向数据双重不平衡的降偏场景图生成系统的结构示意图;
[0071]
图5为本发明一实施例中面向数据双重不平衡的降偏场景图生成系统的无偏关系学习模块的结构示意图。
具体实施方式
[0072]
为使本发明所要解决的技术问题、技术方案及有益效果更为清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。
[0073]
本发明中涉及的部分名词解释如下:
[0074]
fast r-cnn:fast region-based convolutional neural network,快速区域卷积神经网络;
[0075]
bi-tree lstm:bi-tree long short-term memory,双向树结构长短期记忆网络;
[0076]
gru:gatedrecurrent unit,门控循环单元。
[0077]
如图1所示,本发明一实施例提供的一种面向数据双重不平衡的降偏场景图生成方法,具体包括以下步骤:
[0078]
步骤s10,获取原图像。
[0079]
在本实施例中,原图像i为需要生成场景图的图像,且从原图像i中可以识别获得多个对象。
[0080]
步骤s20,将原图像输入到预设的图像识别组合模型,并获取图像识别组合模型输
出的图像识别结果,该图像识别结果包含多个对象候选区域及其对应的对象类别。
[0081]
在本实施例中,对于给定的原图像i,通过图像识别组合模型对原图像i进行对象检测和对象分类,获得对象候选区域集合b=(b1,b2,
…
,bn)和对象类别集合o=(o1,o2,
…
,on),并根据对象候选区域集合b和对象类别集合o得到图像识别结果。其中,对象候选区域集合b中的每一个对象候选区域bi对应一个对象类别集合o中的对象类别oi。
[0082]
可理解的,上述对象分类以及后续步骤中的关系分类在场景图生成任务中起着重要作用。场景图生成的损失函数可以包含对象分类部分和关系分类部分。在对象分类中,可以采用softmax交叉熵损失训练优化图像识别组合模型,以利用训练优化后的图像识别组合模型进行对象分类。
[0083]
作为优选,该图像识别组合模型由依次连接的fast r-cnn和bi-tree lstm组成;步骤s20包括以下步骤:
[0084]
首先,通过fast r-cnn对输入的原图像进行对象检测,获取原图像中的多个对象候选区域;
[0085]
然后,将每个对象候选区域输入到bi-tree lstm,通过bi-tree lstm提取每个对象候选区域对应的对象特征,并基于每个对象特征识别获得对应的对象类别。
[0086]
可理解的,首先采用图像识别组合模型中的第一层结构fast r-cnn对原图像i进行对象检测,从原图像i中获取n个对象候选区域bi,也即得到用于生成场景图的对象边框成分p(b|i),然后采用图像识别组合模型中的第二层结构bi-tree lstm提取各对象候选区域bi的对象特征并识别各对象候选区域bi对应的对象类别oi,也即得到用于生成场景图的对象成分p(o|i,b)。对于对象成分p(o|i,b),由于vg数据集中对象样本的类别分布大致是相同的,可以视为无偏学习过程。
[0087]
进一步地,结合后续步骤获取的用于无偏关系预测的关系成分p(r|i,b,o,z),可以得到原图像i对应的场景图g。
[0088]
需要说明的是,目前fast r-cnn、bi-tree lstm已经被广泛应用在图像识别领域中,在此不再赘述。
[0089]
步骤s30,根据多个对象候选区域和引入的平均外部对象构建因果干预树,并通过因果干预树学习无偏关系特征。
[0090]
可理解的,场景图生成任务中的决策(即关系预测)是内容和上下文的相互协作,内容包含对象候选区域的对象特征,是决策的主导因素和内在因素,上下文是一种外生因素,在决策中起到辅助作用。上下文语境可以加深对图像的理解,减少关系决策中潜在候选关系的数量。然而数据双重不平衡产生的上下文可能包含对公平决策有害的偏见,为了消除这种不利影响,本实施例可以构建因果干预树来减少上下文偏见,消除虚假相关并学习无偏关系特征。
[0091]
作为优选,如图2所示,步骤s30包括以下步骤:
[0092]
步骤s301,对于生成n个对象候选区域的原图像,通过最小生成树算法构建n个初始节点的初始树。
[0093]
在步骤s301中,最小生成树算法为prim算法,通过prim算法为n个对象候选区域动态构建初始树的实现流程为:1)建立边集合用来存放结果,建立节点集合用来存放节点同时用于标记是否被访问过,建立边的最小堆;2)开始遍历所有节点,如果没有访问,则添加
到节点集合,再将其相连的边入堆;3)从堆中取最小边,再判断最小边对应的目标节点是否被访问过,如果没有,将最小边加入初始树,并标记该目标节点访问;4)将目标节点所相连的边添加到最小堆中;5)循环上述步骤,直到所有的节点遍历完,得到初始树。
[0094]
步骤s302,通过在初始树中增加一个附加节点构建(n+1)个节点的因果干预树;该附加节点表示平均外部对象。
[0095]
在步骤s302中,构建因果干预树包含n个初始节点和一个附件节点,每一个初始节点表示一个对象候选区域,附件节点表示引入的平均外部对象
[0096]
步骤s303,对因果干预树中的每个节点进行特征赋予,确定每个节点的特征。
[0097]
作为优选,将因果干预树的每一个初始节点的特征设置为通过深度神经网络从对应的对象候选区域中学习到的对象特征,并将因果干预树的附加节点的特征设置为平均外部对象的特征该平均外部对象的特征为通过移动平均方法对所有外部对象的特征进行计算得到平均特征
[0098]
需要说明的是,上述深度神经网络可以为步骤s202中的bi-tree lstm。
[0099]
步骤s304,将每个节点的特征输入gru网络,通过gru网络对每一个候选关系的主语对象、宾语对象和平均外部对象之间进行消息传递,并通过全连接层输出候选关系的logit向量其中,logit向量可以表示为:
[0100][0101]
公式(1)中,oi、oj为分别为主语对象和宾语对象;fc()、||分别表示gru网络中的全连接层和特征拼接层。
[0102]
可理解的,本实施例利用平均外部对象替代了多个外部对象zi,为了充分发挥外部对象的因果干预作用,可以通过gru网络在每一个候选关系r
i-j
的主语对象oi、宾语对象oj和平均外部对象之间增加额外的消息传递,并在gru网络的全连接层利用公式(1)计算得到每一个候选关系ri→j的logit向量也即本实施例将候选关系ri→j的logit向量作为无偏关系特征。
[0103]
进一步地,在通过因果干预树学习无偏关系特征过程中,通过gru网络得到候选关系的logit向量之后,可以先将gru网络输出的logit向量与预设的目标logit向量一起输入到预设的损失函数中,并输出损失值loss,再根据损失值loss,利用反向传播算法迭代更新因果干预树中平均外部对象的特征直至损失值loss小于等于预设损失阈值,保存更新了平均外部对象的特征的因果干预树。此时,对于第t次迭代训练,平均外部对象的特征可以表示为:
[0104][0105]
公式(2)中,λ为每一次迭代训练的更新权重;zk表示引入的第k类外部对象,且k=(1,2,
…
,c);c为引入的外部对象的对象类别数;v(zk)为外部对象zk的特征,且外部对象zk的特征为vg数据集中所有第k类对象的特征平均值。
[0106]
由上述可知,相较于利用卷积神经网络为每个候选关系独立计算多个外部对象干预下的logit向量,本实施例利用平均外部对象替代多个外部对象,可以显著减少计算量,同时有效减轻由数据双重不平衡产出的上下文偏见,过滤掉对象之间的虚假相关。其次,通过因果干预设学习候选关系的logit向量,可以为无偏关系预测提供有效支撑。
[0107]
步骤s40,构建偏阻损失函数,根据偏阻损失函数优化分类器;其中,该偏阻损失函数用于解耦前景关系与背景关系的识别,以及不同前景关系的分类。
[0108]
现有的场景图生成方法通常采用适用于平衡分布的交叉熵损失函数来优化它们的关系分类模型。然而场景图生成中的关系分布是双重不平衡的,如图3(a)所示的有偏场景图生成中关系特征空间分布图,在有偏数据训练的情况下,由于前景关系类别的特征空间会被背景关系类别的特征空间所压制,尤其是尾部前景关系的样本总处于欠表达的状态,因此导致前景关系样本往往会被预测为背景关系类别,从而出现严重降低关系预测的性能。
[0109]
本实施例构建一种偏阻损失函数让分类器学习无偏的关系预测。作为优选,步骤s40包括以下步骤:
[0110]
步骤s401,构建二分类损失函数,该二分类损失函数用于识别前景与背景关系;
[0111]
步骤s402,构建多分类损失函数,该多分类损失函数用于分类各个前景关系;
[0112]
步骤s403,通过对二分类损失函数和多分类损失函数进行联合构建偏阻损失函数,并对分类器进行优化。
[0113]
具体的,为了平衡背景关系类别、频繁背景关系类别和稀有前景关系类别对分类器训练的影响,利用偏阻损失函数对前景与背景关系的识别以及前景关系的分类进行解耦,使得无偏关系特征被分类为前景关系或背景关系的同时,也会被分类为某一种具体的前景关系。偏阻损失函数l
br
由两部分组成,一部分是用于识别前景与背景关系的二分类损失函数l
bf
,另一部分是用于分类不同前景关系l
fore
。偏阻损失函数l
br
可以表示为:
[0114]
l
br
=l
bf
+l
fore
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(3)
[0115]
在一可选实施例中,步骤s401包括以下步骤:
[0116]
步骤s4011,设定深度神经网络输出的logit向量为x=(x0,x1,
…
,x
|r|
),|r|为关系类别的数量,并设定logit向量对应的概率分布为p=(p0,p1,
…
,p
|r|
)以及对应的真实标签向量为y=(y0,y1,
…
,y
|r|
)。
[0117]
其中,深度神经网络可以为步骤s303中的gru网络;logit向量与概率分布的关系为:p=softmax(x);真实标签向量y是一个独热编码向量。
[0118]
步骤s4012,获取用于前景与背景二分类所需的二维logit向量x
bf
与深度神经网络输出的logit向量x的第一转换关系;该第一转换关系为:
[0119][0120]
公式(4),x0、xi分别为logit向量x中的第一个logit值和第i个logit值,且i=(1,2,
…
,|r|);p0、pi分别为概率分布p中的第一个概率和第i个概率;β为第一权重参数,用于控制logit向量x中背景关系类别;max()为最大值函数。
[0121]
步骤s4013,获取用于前景与背景二分类所需的二维真实标签向量y
bf
与logit向量x对应的真实标签向量y的第二转化关系;该第二转化关系为:
[0122][0123]
公式(5)中,y0为真实标签向量y中的第一个真实关系标签。
[0124]
步骤s4014,根据二值交叉熵损失函数、第一转换关系和第二转化关系构建二元类损失函数l
bf
;该二元类损失函数l
bf
可以表示为:
[0125][0126]
公式(6)中,为用于前景与背景二分类所需的二维logit向量,为用于前景与背景二分类所需的二维真实标签向量,σ为sigmoid函数,α为前景关系样本的权重参数。
[0127]
可理解的,构建二元类损失函数l
bf
的关键是获取gur网络输出的logit向量x和对应的真实标签向量y与用于前景与背景二分类的二维logit向量x
bf
和二维真实标签向量y
bf
的转换关系。本实施例利用公式(4)所示的第一转化关系,将原始的logit向量x转换处理为前景与背景二分类所需的二维logit向量x
bf
,并利用公式(5)所示的第二转化关系,将原始的初始真实标签向量转换处理为前景与背景二分类所需的二维真实标签向量y
bf
。
[0128]
由公式(4)所示的第一转化关系可知,如果原始的logit向量x的预测类别是属于背景关系类别,则二分类的二维logit向量x
bf
中且是所有前景关系类别所对应的logit值xi的平均值;反之,如果原始的logit向量x的预测类别是属于前景关系类别,则二分类的二维logit向量x
bf
中且其中权重参数β用于控制原始的logit向量x中背景项元素的大小。
[0129]
由公式(5)所示的第二转化关系可知,如果原始的真实标签向量y中的y0=1,则二分类的二维真实标签向量y
bf
为(1,0),否则为(0,1)。
[0130]
结合公式(4)和公式(6)可知,二元类损失函数l
bf
可以通过两个权重参数α和β来调节二元类损失函数l
bf
中各个部分的贡献程度。权重参数α的主要作用是平衡二分类中前景关系样本的梯度与背景关系样本的梯度之间的权重,权重参数β的主要作用是调节不平衡对logit向量中每一项元素的影响。也就是说,在前景与背景分布极不平衡的情况下,背景关系样本可能会抑制前景关系样本的梯度,为了获取具有平衡和公平决策边界的分类器,二元类损失函数l
bf
使用权重参数α来削弱背景梯度的影响;同时,不平衡的数据可能会膨胀logit向量中背景项元素的值,为了使logit向量中前景项元素和背景项元素的贡献相对平等,并给与正确分类的前景关系样本更多的梯度支持,二元类损失函数l
bf
使用权重参数β来缩小logit向量中背景的影响。可理解的,本实施例通过两个权重参数α和β仅调整背景与前景之间的类别决策边界,而不会影响前景关系中各个类别的决策边界,使得构建的二元类损失函数l
bf
不会损害头部前景关系类别的特征分布,并且有利于分类器学习区分各个前景关系类别的特征表示。
[0131]
在一可选实施例中,步骤s402包括以下步骤:
[0132]
步骤s4021,定义权重项ω,该权重项ω可以表示为:
[0133][0134]
公式(7)中,r为候选关系;为候选关系r对应的概率分布的第一个取值,为候选关系r对应的真实标签向量y的第一个取值。
[0135]
步骤s4022,通过在softmax交叉熵损失函数中引入权重项ω,构建多分类损失函数l
fore
;该多分类损失函数l
fore
可以表示为:
[0136][0137]
公式(8)中,pj为概率分布p中的第j个概率,且j=(0,1,2,
…
,|r|),yj为概率pj对应的真实关系标签。
[0138]
可理解的,为了减少从背景关系的特征空间到前景关系的特征空间的抑制,并增加前景关系类别的特征表示,通过在softmax交叉熵损失函数引入了权重项ω构建多分类损失函数l
fore
,以忽略二元类损失函数l
bf
中已经被正确分类的背景关系样本的梯度。
[0139]
结合公式(7)和公式(8)可知,真实标记为前景关系样本的梯度和被分类器分类为前景关系样本的梯度将会保留,对于已经在二元类损失函数l
bf
中正确分类的背景关系样本,其产生的损失和梯度将在权重项ω的调整下设置为0,也就是说,二元类损失函数l
bf
中错误分类的背景关系样本的梯度在多分类损失函数l
fore
中将会保留,可以增强分类器的鲁棒性和维持分类器学习前景关系类别的特征分布。
[0140]
进一步地,步骤s4022之后还包括以下步骤:
[0141]
步骤s4023,根据softmax均衡损失函数更新多分类损失函数l
fore
中的概率pj,更新后的概率pj可以表示为:
[0142][0143]
公式(9)中,xj为概率pj对应的logit值;xk为第k类关系类别对应的logit值,且k=(0,1,2,
…
,|r|);ωk为第k类关系类别对应的权重,可以表示为:
[0144]
ωk=1-e(k)t
λ
(fk)(1-yk)
ꢀꢀꢀꢀꢀꢀꢀꢀ
(10)
[0145]
公式(10)中,e(k)为二元项,在k=0属于背景关系类别时,e(k)=0,而在k>0属于前景关系类别时,e(k)=1;t
λ
()为阈值函数,当第k类关系类别的频率fk小于阈值λ时,t
λ
()=1,否则t
λ
()=0;yk为第k类关系类别对应的真实关系标签。可选的,阈值λ=0.1。
[0146]
可理解的,为了提高分类器优化训练过程中尾部关系样本的贡献,概率pj将会根据softmax均衡损失函数进行更新,以忽略尾部前景关系类别中的负样本梯度。
[0147]
由上述可知,本实施例通过对二元类损失函数和多分类损失函数进行联合构建偏阻损失函数,并优化训练用于关系分类的分类器,可以有效抑制从背景关系类别到前景关系类别、以及从尾部前景关系到头部前景关系的偏见。如图3(b)所示的无偏场景图生成中关系特征空间分布图,通过移动分类器的决策边界和扩展前景关系类别的特征空间,通过有偏阻损失函数优化后的分类器能够学习各个前景关系类别的更具区分性的表示,并能够
更合理地区分背景关系样本、头部前景关系样本和尾部前景关系样本。此外,设置有权重参数的多个偏阻损失函数,相较于重加权重采样等方法,偏阻损失函数能够保留头部前景类别中更多的有效对象特征信息。
[0148]
步骤s50,将无偏关系特征输入到优化后的分类器中,并获取分类器输出的预测关系。
[0149]
在本实施例中,在利用偏阻损失函数l
br
优化用于关系分类的分类器之后,将通过因果干预树学习得到的无偏关系特征(优选为候选关系的logit向量)输入到分类器中,并获取分类器输出的预测关系r。
[0150]
步骤s60,根据图像识别结果和预测关系生成降偏场景图。
[0151]
在本实施例中,根据通过图像识别组合模型获得的对象候选区域b和对象类别o,以及通过分类器获得的预测关系r,生成原图像i对应的场景图g。
[0152]
由上述可知,本实施例提供的面向数据双重不平衡的降偏场景图生成方法,首先通过图像识别组合模型对输入的原图像进行对象检测和对象分类,得到对象候选区域和对象类别,然后根据对象候选区域和引入的平均外部对象构建因果干预树,并基于因果干预树学习关系无偏特征,接下来将关系无偏特征输入到根据偏阻损失函数优化后的分类器,得到预测关系,最后根据对象候选区域、对象类别以及预测关系生成场景图。本实施例通过因果干预树来减少因数据不平衡产生的上下文偏见,消除虚假相关并学习无偏关系特征,同时通过偏阻损失函数优化分类器来减少场景图生成任务中从前景到背景以及从尾部前景到头部前景的双重不平衡的偏见,显著提高了关系预测的准确度,从而达到有效生成无偏场景图的目的。此外,基于不平衡数据集vg150进行场景图生成,试验表明本实施例提供的面向数据双重不平衡的降偏场景图生成方法准确有效。
[0153]
如图4所示,基于同一发明构思,与上述任意实施例方法相对应的,本发明一实施例还提供了一种面向数据双重不平衡的降偏场景图生成系统,包括图像获取模块110、图像识别模块120、无偏特征学习模块130、优化模块140、关系预测模块150和场景图生成模块160,各功能模块的详细说明如下:
[0154]
图像获取模块110,用于获取原图像;
[0155]
图像识别模块120,用于将原图像输入到预设的图像识别组合模型,并获取图像识别组合模型输出的图像识别结果;该图像识别结果包含多个对象候选区域及其对应的对象类别;
[0156]
无偏特征学习模块130,用于获取平均外部对象,根据多个对象候选区域和平均外部对象构建因果干预树,并基于因果干预树学习无偏关系特征;
[0157]
优化模块140,用于构建偏阻损失函数,根据偏阻损失函数优化分类器;其中,该偏阻损失函数用于解耦前景关系与背景关系的识别,以及不同前景关系的分类;
[0158]
关系预测模块150,用于将无偏关系特征输入到优化后的分类器中,并获取分类器输出的预测关系;
[0159]
场景图生成模块160,用于根据图像识别结果和预测关系生成降偏场景图。
[0160]
在一可选实施方式中,所述图像识别模块120包括以下子模块,各功能子模块的详细说明如下:
[0161]
对象检测子模块,用于通过快速区域卷积神经网络对输入的原图像进行对象检
测,获取原图像中的多个对象候选区域;
[0162]
对象分类子模块,用于将每个对象候选区域输入到双向树结构长短期记忆网络,通过双向树结构长短期记忆网络提取每个对象候选区域对应的对象特征,并基于每个对象特征识别获得对应的对象类别。
[0163]
在一可选实施方式中,如图5所示,所述无偏特征学习模块130包括以下子模块,各功能子模块的详细说明如下:
[0164]
初始树构建子模块131,用于对于生成n个对象候选区域的原图像,通过最小生成树算法构建n个初始节点的初始树;
[0165]
因果干预子模块132,用于通过在初始树中增加一个附加节点构建(n+1)个节点的因果干预树;该附加节点表示平均外部对象;
[0166]
特征赋予模块133,用于对因果干预树中的每个节点进行特征赋予,确定每个节点的特征;
[0167]
特征输出子模块144,用于将每个节点的特征输入门控循环单元网络,通过门控循环单元网络对每一个候选关系的主语对象、宾语对象和平均外部对象之间进行消息传递,并通过全连接层输出候选关系的logit向量。
[0168]
在一可选实施方式中,所述特征赋予模块130用于将因果干预树的每一个初始节点的特征设置为通过深度神经网络从对应的对象候选区域中学习的对象特征,并将因果干预树的附加节点的特征设置为平均外部对象的特征;该平均外部对象的特征为通过移动平均方法对所有外部对象的特征进行计算得到平均特征。
[0169]
在一可选实施方式中,所述优化模块140包括以下子模块,各功能子模块的详细说明如下:
[0170]
二分类子模块,用于构建二分类损失函数,该二分类损失函数用于识别前景与背景关系;
[0171]
多分类子模块,用于构建多分类损失函数,该多分类损失函数用于分类各个前景关系;
[0172]
联合优化子模块,用于通过对二分类损失函数和多分类损失函数进行联合构建偏阻损失函数,并对分类器进行优化。
[0173]
在一可选实施方式中,所述二分类子模块包括以下单元,各功能单元的详细说明如下:
[0174]
设定单元,用于设定深度神经网络输出的logit向量为x=(x0,x1,
…
,x
|r|
),|r|为关系类别的数量,并设定logit向量对应的概率分布为p=(p0,p1,
…
,p
|r|
)以及对应的真实标签向量为y=(y0,y1,
…
,y
|r|
);
[0175]
第一转换处理单元,用于获取用于前景与背景二分类所需的二维logit向量x
bf
与深度神经网络输出的logit向量x的第一转换关系;该第一转换关系为:
[0176][0177]
其中,x0、xi分别为logit向量x中的第一个logit值和第i个logit值,且i=(1,
2,
…
,|r|);p0、pi分别为概率分布p中的第一个概率和第i个概率;β为第一权重参数,用于控制logit向量x中背景关系类别;
[0178]
第二转换处理单元,用于获取用于前景与背景二分类所需的二维真实标签向量y
bf
与logit向量x对应的真实标签向量y的第二转化关系;该第二转化关系为:
[0179][0180]
其中,y0为真实标签向量y中的第一个真实关系标签;
[0181]
第一损失函数构建单元,用于根据二值交叉熵损失函数、第一转换关系和第二转化关系构建二元类损失函数l
bf
;该二元类损失函数l
bf
表示为:
[0182][0183]
其中,为用于前景与背景二分类所需的logit向量;为用于前景与背景二分类所需的真实标签向量;σ为sigmoid函数;α为前景关系样本的权重参数。
[0184]
在一可选实施方式中,所述多分类子模块包括以下单元,各功能单元的详细说明如下:
[0185]
权重定义单元,用于定义权重项ω,该权重项ω表示为:
[0186][0187]
其中,r为候选关系;
[0188]
第二损失函数构建单元,用于通过在softmax交叉熵损失函数中引入权重项ω,构建多分类损失函数l
fore
;该多分类损失函数l
fore
表示为:
[0189][0190]
其中,pj为概率分布p中的第j个概率,且j=(0,1,2,
…
,|r|);yj为概率pj对应的真实关系标签。
[0191]
在一可选实施方式中,所述多分类子模块还包括以下单元,各功能单元的详细说明如下:
[0192]
概率更新单元,用于根据softmax均衡损失函数更新多分类损失函数l
fore
中的概率pj,更新后的概率pj表示为:
[0193][0194]
其中,xj为概率pj对应的logit值;xk为第k类关系类别对应的logit值,且k=(0,1,2,
…
,|r|);ωk为第k类关系类别对应的权重,表示为:
[0195]
ωk=1-e(k)t
λ
(fk)(1-yk),
[0196]
其中,e(k)为二元项,在k=0属于背景关系类别时,e(k)=0,而在k>0属于前景关系类别时,e(k)=1;t
λ
()为阈值函数,当第k类关系类别的频率fk小于阈值λ时,t
λ
()=1,否
则t
λ
()=0;yk为第k类关系类别对应的真实关系标签。
[0197]
上述实施例的系统用于实现前述实施例中相应的方法,并且具有相应的方法实施例的有益效果,在此不再赘述。
[0198]
所属领域的普通技术人员应当理解:以上任何实施例的讨论仅为示例性的,并非旨在暗示本发明的范围限于这些例子;在本发明的思路下,以上实施例或者不同实施例中的技术特征之间也可以进行组合,步骤可以以任意顺序实现,并存在如上所述的本发明实施例的,不同方面的许多其它变化,为了简明它们没有在细节中提供。
[0199]
本发明实施例旨在涵盖落入本发明的宽泛范围之内的所有这样的替换、修改和变型。因此,凡在本发明实施例的精神和原则之内,所做的任何省略、修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1