一种基于信息熵的异常数据判别方法
1.本发明涉及数据治理、深度学习领域,特别涉及一种基于信息熵的异常数据判别方法。
背景技术:
2.近年来,“数据”列为生产要素,充分凸显了数字对经济活动和社会活动的巨大价值。大数据、人工智能、区块链等数字技术被广泛应用于智慧城市、公共事务管理等社会治理领域,加速了社会治理的数字化转型进程。
3.在数字化转型过程中,“数据治理”是最关键的环节之一。“数据治理”关注的是数据规划、数据获取、数据质量、数据共享、数据标注等数据管理的整个生命周期,是各个领域“智能决策”应用的关键支撑。
4.在“数据治理”中,利用信息熵的思想,一条信息的信息量与它的不确定性有直接关系,如果要搞清楚该数据,需要了解的信息就越多,其信息熵越大。所以,利用信息熵思想来判别数据是否是异常数据是一项很重要的工作。
技术实现要素:
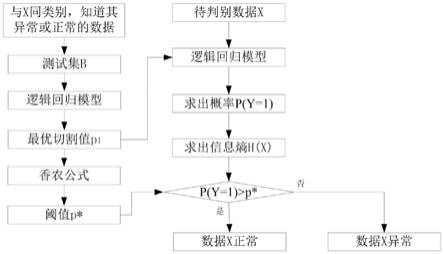
5.本发明所要解决的技术问题是提供一种基于信息熵的异常数据判别方法,判别方法更加准确,以解决现有技术中导致的上述多项缺陷。
6.为实现上述目的,本发明提供以下的技术方案:一种基于信息熵的异常数据判别方法,其特征在于,把需要判别是否异常的数据对象,定义为数据x,x=(x1,x2,
…
,xi,
…
,xn),其中,n为数据x包含的元素个数,xi为数据x中的第i个元素;
7.包括如下步骤:
8.1)利用逻辑回归模型,把一条数据所对应的每个子特征,转化成概率问题;
9.2)把与数据x同性质的,知道其数据是异常或正常的数据集,作为训练模型的测试集,在逻辑回归模型的基础上计算准确率,寻找准确率最高时所对应的切割值,作为最优切割值;
10.3)在最优切割值基础上,计算出相应概率及信息熵,按照比对原则统计出测试集的准确率,寻找准确率最高时所对应的比对值,作为比对阈值;
11.4)通过香农公式,利用求出的概率求出该数据所对应的信息熵;
12.5)把信息熵与阈值进行比对,当信息熵大于等于阈值时,判别该数据为异常数据,当信息熵小于阈值时,判别该数据为正常数据。
13.优选的,所述步骤1)中,假设对于数据x,因变量y的输出值为1,即x为异常数据;或者0,即x为正常数据;解释变量为xi,y 与xi之间的关系由概率p(y=1)来解释,因此概率p(y=1)定义如下:
[0014][0015]
其中,αi是xi的线性模型的估计值,ε是随机变量误差值;
[0016]
通过转换公式(1),可以得到
[0017][0018]
其中,
[0019]
使用逻辑回归转换,可以得到逻辑回归模型,如(3)所示;
[0020][0021]
因此,y可以如下表示:
[0022][0023]
其中,p为切割值,取值范围为[0,1],这里取值为p=p1。
[0024]
优选的,所述步骤2)中,把与数据x同性质的,知道其数据是异常,标志位为“1”的数据集;或正常,标志位为“0”的数据集;作为训练模型的测试集b,bi为数据集b中的元素;
[0025]
针对测试集b,应用逻辑回归模型,当p取值0.00、0.01、0.02、0.03、
…
、0.98、0、99、1时,计算出每个切割值p所对应的准确率。取出准确率最大的值,它所对应的切割值记为p1。
[0026]
优选的,所述步骤3)中,然后把p1带入(4),计算出测试集b相应数据bi的概率;再利用香农公式,计算出所对应的信息熵p(bi);再利用p(bi)》p2,判别预测数据bi为正常;p(bi)=《p2,判别预测数据bi为异常,p2取值范围依然为[0,1];然后与数据集b原有的标志位核对准确性,统计出最大准确率,该准确率所对应的p2记为p
*
,即为与下一步信息熵比对的阈值。
[0027]
优选的,所述步骤4)中,利用香农公式,计算出数据x对应的信息熵:
[0028]
p(x)=-p(y=1)*log2p(y=1)
ꢀꢀꢀ
(5)。
[0029]
优选的,所述步骤5)中,判别结论:
[0030]
当p(x)》p
*
时,表示该数据x正常;
[0031]
当p(x)=《p
*
时,表示该数据x异常。
[0032]
采用以上技术方案的有益效果是:较之于传统的逻辑回归模型,引入了信息熵理论,加入了数据的信息量,判别方法更加准确;较之于传统的信息熵理论,单一的信息熵理论确定概率比较困难,引入逻辑回归模型很简便地确定概率,易于操作计算。
附图说明
[0033]
图1为本发明一种基于信息熵的异常数据判别方法的流程图;
[0034]
图2为本发明中,逻辑回归模型的准确率与切割值的关系图。
具体实施方式
[0035]
下面详细说明本发明的优选实施方式。
[0036]
一种基于信息熵的异常数据判别方法,首先,利用逻辑回归模型,把一条数据所对应的每个子特征,转化成概率问题;其次,把与数据 x同性质的,知道其数据是异常或正常的数据集,作为训练模型的测试集,在逻辑回归模型的基础上计算准确率,寻找准确率最高时所对应的切割值,作为最优切割值;再次,在最优切割值基础上,计算出相应概率及信息熵,按照比对原则统计出测试集的准确率,寻找准确率最高时所对应的比对值,作为比对阈值(作为后面与信息熵比对的阈值);然后,通过香农公式求出该数据所对应的信息熵;最后,把信息熵与阈值进行比对,当信息熵大于等于阈值时,判别该数据未异常数据,当信息熵小于阈值时,判别该数据为正常数据。
[0037]
把“数据治理”中需要判别是否异常的数据对象,定义为数据x, x=(x1,x2,
…
,xi,
…
,xn),其中,n为数据x包含的元素个数,xi为数据x中的第i个元素。
[0038]
逻辑回归模型
[0039]
假设对于数据x,因变量y的输出值为1(即x为异常数据)或者0(即x为正常数据),解释变量为xi(即x中的元素),y与xi之间的关系由概率p(y=1)来解释,因此概率p(y=1)定义如下:
[0040][0041]
其中,αi是xi的线性模型的估计值,ε是随机变量误差值。
[0042]
通过转换公式(1),可以得到
[0043][0044]
其中,
[0045]
使用逻辑回归转换,可以得到逻辑回归模型,如(3)所示。
[0046][0047]
因此,y可以如下表示:
[0048][0049]
其中,p为切割值,取值范围为[0,1],这里取值为p=p1(p1见下一步)。
[0050]
确定最优切割值:
[0051]
把与数据x同性质的,知道其数据是异常(标志位为“1”)或正常(标志位为“0”)的数据集,作为训练模型的测试集b,bi为数据集b中的元素;
[0052]
针对测试集b,应用逻辑回归模型,当p取值0.00、0.01、0.02、 0.03、
…
、0.98、0、99、1时,计算出每个切割值p所对应的准确率。取出准确率最大的值,它所对应的切割值记
为p1(作为上一步p 的取值)。
[0053]
确定阈值:
[0054]
然后把p1带入(4),计算出测试集b相应数据bi的概率。再利用香农公式,计算出所对应的信息熵p(bi)。再利用p(bi)》p2,判别预测数据bi为正常;p(bi)=《p2,判别预测数据bi为异常,p2取值范围依然为[0,1]。然后与数据集b原有的标志位核对准确性,统计出最大准确率,该准确率所对应的p2记为p
*
,即为与下一步信息熵比对的阈值。
[0055]
计算信息熵:
[0056]
利用香农公式,计算出数据x对应的信息熵:
[0057]
p(x)=-p(y=1)*log2p(y=1)
ꢀꢀꢀ
(5)
[0058]
判别结论:
[0059]
当p(x)》p
*
时,表示该数据x正常;
[0060]
当p(x)=《p
*
时,表示该数据x异常。
[0061]
下面结合具体的实施例对本发明做进一步的详细说明,所述是对本发明的解释而不是限定。
[0062]
实施例
[0063]
本发明以cic-ids2017数据集中的ddos攻击数据为例。
[0064]
cic-ids2017数据集中的ddos攻击数据一个有225745条数据(其中,lable为benign的数据为97718条,标记为“0”,label为ddos 的数据为128027条,标记为“1”),其中,选取第一条数据作为待判别数据x,第2-225745条数据作为测试数据集b,bi为数据集b中的元素。
[0065]
确定最优切割值:
[0066]
针对测试数据集b,选取bwd packet length std;average packet size;flow duration;flow iat std这4个特征行为作为解释变量,以label列数据作为因变量,对这5列数据进行回归分析,得出回归系数:α1=-7.87e(-09),α2=0.000171636,α3=3.1074e(-08),α4=-2.31371e(-05),ε=0.365008007。然后,利用逻辑回归模型,把以上数据带入公式(1),可以计算出p(y=1)的值,接着,切割值pi在[0,1] 之间由小到大取值,取步长为0.001,带入公式(4),计算出每个切割值p所对应的准确率。如下所示:
[0067]
由图2可以看出,当准确率取最大值85.62%时,其对应的切割值为0.6,即取p=p1=0.6作为最优切割值。
[0068]
(此时的准确率85.62%,也是单独逻辑回归模型的准确率,可以与本发明准确率进行比较)
[0069]
确定阈值:
[0070]
针对测试数据集b,把p1=0.6带入(4),计算出测试集b相应数据bi的概率。再利用香农公式,计算出所对应的信息熵p(bi)。接着,比对值p2在[0,1]之间由小到大取值,取步长为0.001,按照比对原则(p(bi)》p2,判别预测数据bi为正常;p(bi)=《p2,判别预测数据bi为异常),与数据集b原有的标志位核对准确性,统计出最大准确率为86.68%,其对应的比对值为0.447,即取p2=p
*
=0.447。
[0071]
(此时的准确率86.68%,就是本发明的的准确率,比单独逻辑回归模型的准确率提高了1.02%,证明了本发明的准确率相比单纯的逻辑回归模型得到了提高)
[0072]
逻辑回归模型:
[0073]
针对待判别数据x,同理,利用逻辑回归模型(此时p1=0.6),计算出p(x)=0.5902。
[0074]
计算信息熵:
[0075]
针对待判别数据x,把p(x)值带入香农公式,计算出信息熵为h(x)=0.4490。
[0076]
判别结论:
[0077]
因为p(x)=0.4490》p
*
=0.447,可以判别该数据x正常。
[0078]
(对应数据x,它所对应的label为benign,标记为“0”,与本发明判别的结论一致,证明了本发明的准确性)
[0079]
以上所述的仅是本发明的优选实施方式,应当指出,对于本领域的普通技术人员来说,在不脱离本发明创造构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1