一种变压器声信号去噪装置的制作方法
1.本发明涉及变压器声信号处理技术领域,尤其是指一种变压器声信号去噪装置。
背景技术:
2.变压器是指利用电磁感应的原理来改变交流电压的装置,由于变压器内部放电、过热、绕组变形、机械部件松动及设备绝缘老化等潜伏性故障因素的影响,随着时间积累会导致变压器运行过程中出现严重故障,传统的人工判断方法是通过用人耳听取设备运行声音来判断故障类型与故障位置,此类方法具有一定的局限性、模糊性、主观性与缺乏持久性,具体表现为不同技术人员对变压器故障的判断标准可能存在不一致,且一些细微声信号无法判定,需要一定知识与经验的积累。
3.而长久以来,变压器的声纹信号被当作噪声而忽略了其价值,变压器的不同的故障类型影响着变压器的振动状态,进而会产生不同的声波信号,因此应用声纹采集装置可采集变压器运行中的持续声纹信号,通过对声纹信号的分析与识别可实现对变压器进行工况检测与诊断。
4.但是,变压器工作时产生的声纹信号较丰富,在正常电器振动产生的声纹信号中夹杂着噪声,而这些声纹信号若不能区别出噪声特性,会对基于声纹信号分析变压器故障带来不利影响,因此,本发明提供一种基于多重降噪自编码器模型的变压器声信号去噪方法,对采集到的声信号中的噪声进行降噪处理,以提高变压器故障的判断精准度。
技术实现要素:
5.本发明的目的是克服现有技术中的不足,提供一种变压器声信号去噪装置。
6.本发明的目的是通过下述技术方案予以实现:
7.一种变压器声信号去噪装置,包括:
8.采集单元,用于采集原始声信号,并将原始声信号传输至处理单元,原始声信号为变压器测量面处的原始声信号;
9.处理单元,用于构建多重降噪自编码器模型,多重降噪自编码器模型在收到采集器发出的原始声信号后,将原始声信号进行重构;
10.输出单元,用于输出重构的声信号,重构的声信号即为去噪后的声信号。
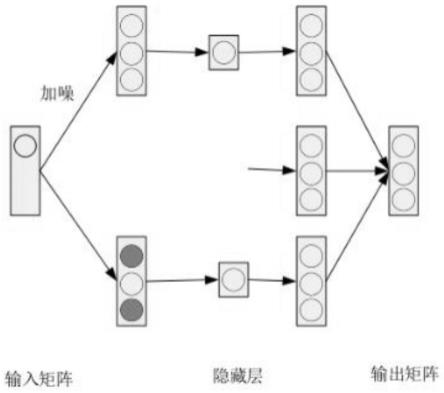
11.作为优选,所述的处理单元中,多重降噪自编码器模型包括
12.输入层,用于构建输入矩阵,输入矩阵是一个规模为m
×
n的关联矩阵
13.加噪层,用于对数据矩阵加入高斯噪声;
14.重构层,通过对加入高斯噪声的数据矩阵进行编码解码操作,对原始声信号进行重构。
15.作为优选,变压器声信号去噪装置还包括显示单元,用于显示原始声信号和重构的声信号的属性以及多重降噪自编码器模型的训练情况。
16.作为优选,所述的采集单元在采集原始声信号后对每一次采集到的原始声信号进
行z-score标准化处理,计算公式为:
[0017][0018]
其中,为原始声信号标准化后的数据矩阵,μ为原始声信号均值,σ为原始声信号标准差,为原始声信号对应的输入矩阵。
[0019]
作为优选,所述的加噪层,加入高斯噪声的最大加噪率p
max
=s
·
p∈[0,1],p∈[0,s-1
],s∈[1,9],k∈[10,100],无监督学习的训练次数∈[10,100],其中s为输入矩阵个数,p为设定的参数,k为节点个数。
[0020]
作为优选,所述的所述s=4或5,p=0.04或0.02,k=50或60,无监督学习的训练次数为70次或80次。
[0021]
作为优选,变压器声信号去噪装置还包括优化单元,优化单元用于对多重降噪自编码器模型进行优化,具体优化过程为:优化单元首先设定多重降噪自编码器模型的最大训练次数,若在最大训练次数内重构信号与原始信号误差收敛于极小值,则优化单元不进行优化,若在最大训练次数内重构信号与原始信号误差未收敛于极小值,则优化单元进行优化,对于多重降噪自编码器模型的参数进行调整,调整的参数包括矩阵个数、节点个数以及加噪的次数,调整的参数的调整幅度为预设的幅度,若在多重降噪自编码器模型的参数进行调整后,最大训练次数内重构信号与原始信号误差收敛于极小值,则判断优化单元优化成功,若在多重降噪自编码器模型的参数进行调整后,最大训练次数内重构信号与原始信号误差未收敛于极小值,则对所有的重构信号进行聚类分析,通过聚类分析寻找聚类中心,聚类中心表示多重降噪自编码器模型的最佳优化程度,优化单元向相关人员提醒重构信号与原始信号误差未收敛于极小值并告知重构信号的最佳优化程度。
[0022]
本发明的有益效果是:
[0023]
1、本发明中,本发明提出的方法是基于无监督学习方式训练多种降噪自编码器模型对加噪声信号重构从而达到去噪目的,对麦克风阵列u采集来的变压器i的原始声信号通过本发明方法进行去噪实验的验证,其输入的声信号波形图与输出的声信号波形图在幅度上得到大幅降低,表明多重降噪自编码器模型的去噪效果具有优势。
[0024]
2、本发明中,本发明采用的多重降噪自编码器模型,相较于传统的滤波去噪、傅里叶变换和小波变换去噪方法而言,具有更优的去噪性能和健壮性,可以有效去除噪声,对于后续声信号识别处理具有重要意义。
附图说明
[0025]
图1示出了根据本发明实施例提供的一种基于多重降噪自编码器模型的变压器声信号去噪方法的多重降噪自编码器模型的结构示意图;
[0026]
图2示出了根据本发明实施例提供的一种基于多重降噪自编码器模型的变压器声信号去噪方法的工作流程示意图;
[0027]
图3示出了根据本发明实施例提供的一种基于多重降噪自编码器模型的变压器声信号去噪方法的原始声信号频谱图;
[0028]
图4示出了根据本发明实施例提供的一种基于多重降噪自编码器模型的变压器声
信号去噪方法的降噪处理后的声信号频谱图。
具体实施方式
[0029]
下面结合附图和实施例对本发明进一步描述。
[0030]
实施例:
[0031]
如图1、图2所示,一种变压器声信号去噪装置,包括:
[0032]
采集单元,用于采集原始声信号,并将原始声信号传输至处理单元,原始声信号为变压器测量面处的原始声信号;
[0033]
处理单元,用于构建多重降噪自编码器模型,多重降噪自编码器模型在收到采集器发出的原始声信号后,将原始声信号进行重构;
[0034]
输出单元,用于输出重构的声信号,重构的声信号即为去噪后的声信号。
[0035]
作为优选,所述的处理单元中,多重降噪自编码器模型包括
[0036]
输入层,用于构建输入矩阵,输入矩阵是一个规模为m
×
n的关联矩阵
[0037]
加噪层,用于对数据矩阵加入高斯噪声;除模型第一次处理不需要加入噪声外,其余每次处理都需要对输入矩阵按照不同的加噪率加入高斯噪声,设定加噪率为p,对输入矩阵根据模型的层数多次加噪,其中,每次的加噪率:
[0038][0039]
s表示模型的层数,其中第0层表示加噪率为0的层,表示s层中麦克风阵列u对变压器i的采集的声信号;
[0040]
加入噪声后,每层噪声以外的数据都需要扩大1/(1-sp)倍,得到模型处理后的输入矩阵;
[0041]
重构层,通过对加入高斯噪声的数据矩阵进行编码解码操作,对原始声信号进行重构。
[0042]
编码:经过加噪处理后,模型得到s+1个输入矩阵,其中第一个矩阵为没有加噪的初始矩阵,之后s个矩阵为经过不同加噪率得出的噪声矩阵,将所有输入矩阵映射为隐藏层的低维密集矩阵表示:
[0043][0044]
隐藏层矩阵有k个节点,这里的k是预先设定的值,表示隐藏层中将输入矩阵进行压缩降维后的节点个数,其中,表示n
×
k的权值矩阵,表示k维的偏置向量,是sigmoid映射函数
[0045]
输入矩阵经过全连接映射,得到隐藏层矩阵和
[0046]
解码:在解码阶段,隐藏层得到的低维密集矩阵将通过全连接还原为初始规模的矩阵输出:
[0047][0048]
在输出层中,隐藏层的k个节点通过全连接映射,得到输出层的n个节点,矩阵表示输出层得到的预测矩阵,其中表示n
×
k规模的权值矩阵,表示n维的偏置向量,是一个映射函数;
[0049]
最后将得到的s+1个预测矩阵结合起来:就是输出层得到的最终预测矩阵。
[0050]
变压器声信号去噪装置还包括显示单元,用于显示原始声信号和重构的声信号的属性以及多重降噪自编码器模型的训练情况。
[0051]
所述的采集单元在采集原始声信号后对每一次采集到的原始声信号进行z-score标准化处理,计算公式为:
[0052][0053]
其中,为原始声信号标准化后的数据矩阵,μ为原始声信号均值,σ为原始声信号标准差,为原始声信号对应的输入矩阵。
[0054]
作为优选,所述的加噪层,加入高斯噪声的最大加噪率p
max
=s
·
p∈[0,1],p∈[0,s-1
],s∈[1,9],k∈[10,100],无监督学习的训练次数∈[10,100],其中s为输入矩阵个数,p为设定的参数,k为节点个数。
[0055]
所述的所述s=4或5,p=0.04或0.02,k=50或60,无监督学习的训练次数为70次或80次。
[0056]
变压器声信号去噪装置还包括优化单元,优化单元用于对多重降噪自编码器模型进行优化,具体优化过程为:优化单元首先设定多重降噪自编码器模型的最大训练次数,若在最大训练次数内重构信号与原始信号误差收敛于极小值,则优化单元不进行优化,若在最大训练次数内重构信号与原始信号误差未收敛于极小值,则优化单元进行优化,对于多重降噪自编码器模型的参数进行调整,调整的参数包括矩阵个数、节点个数以及加噪的次数,调整的参数的调整幅度为预设的幅度,若在多重降噪自编码器模型的参数进行调整后,最大训练次数内重构信号与原始信号误差收敛于极小值,则判断优化单元优化成功,若在多重降噪自编码器模型的参数进行调整后,最大训练次数内重构信号与原始信号误差未收敛于极小值,则对所有的重构信号进行聚类分析,通过聚类分析寻找聚类中心,聚类中心表示多重降噪自编码器模型的最佳优化程度,优化单元向相关人员提醒重构信号与原始信号误差未收敛于极小值并告知重构信号的最佳优化程度。
[0057]
本发明提出的方法是基于无监督学习方式训练多种降噪自编码器模型对加噪声信号重构从而达到去噪目的,如图3和图4所示,对麦克风阵列u采集来的变压器i的原始声信号通过本发明方法进行去噪实验的验证,其输入的声信号波形图与输出的声信号波形图在幅度上得到大幅降低,表明多重降噪自编码器模型的去噪效果具有优势;
[0058]
其次,传统的降噪方法有滤波去噪、傅里叶变换和小波变换,将该三种方法作为本
实施例的对比例,对同一个原始声信号进行降噪处理,取原始声信号和降噪后输出的声信号的多个波峰或者波谷值的幅值的变化率作为降噪比,比较四种方法对变压器i原始声信号的降噪效果,其降噪比数据如以下表1所示:
[0059]
表1四种方法的降噪比数据表
[0060][0061]
通过表1可以看出,本发明采用的多重降噪自编码器模型,相较于传统的滤波去噪、傅里叶变换和小波变换去噪方法而言,具有更优的去噪性能和健壮性,可以有效去除噪声,对于后续声信号识别处理具有重要意义。
[0062]
以上所述的实施例只是本发明的一种较佳的方案,并非对本发明作任何形式上的限制,在不超出权利要求所记载的技术方案的前提下还有其它的变体及改型。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1