一种基于上下文注意力的图片人头计数的方法和装置与流程
1.本发明涉及本发明涉及图片人头计数技术,尤其涉及基于卷积神经网络的深度学习的图片人头计数技术。
背景技术:
2.专利文献cn 112651390 a公开了一种基于卷积神经网络的图片人头计数的方法和装置。该基于卷积神经网络的图片人头计数的方法采用的是单列卷积神经网络。基于多列卷积神经网络进行图片人头计数的方法有很多种。相比于这些基于多列卷积神经网络进行图片人头计数的方法,上述基于单列卷积神经网络进行图片人头计数的方法,可以有效减少模型参数量,从而提高计数的效率。同时该方法在一般密度场景下,图片人头计数时具有较高的准确率。但该方法存在着在高密度人群的场景下时图片人头计数准确率较差,误差较大的问题。
技术实现要素:
3.本发明所要解决的问题:提高图片人头计数的准确度、稳定度和效率。
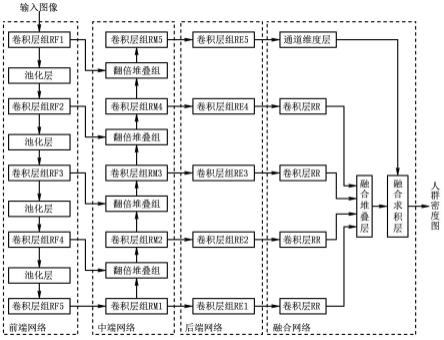
4.为解决上述问题,本发明采用的方案如下:根据本发明的一种基于上下文注意力的图片人头计数的方法,该方法包括模型计算步骤;所述模型计算步骤用于通过上下文注意力网络模型计算得到人群密度图;所述上下文注意力网络模型包括:前端网络、中端网络、后端网络和融合网络;所述前端网络、中端网络和后端网络分别包括五个由卷积层所组成的卷积层组;所述卷积层组包括有若干卷积层;所述融合网络包括通道维度层、融合堆叠层和融合求积层;所述前端网络中,五个卷积层组通过池化层按顺序依次串接,池化层使得五个卷积层组所输出的图像大小逐步缩半,并且最后序的卷积层组输出连接中端网络最前序的卷积层组;所述中端网络中,前序的卷积层组的输出分别通过翻倍层进行图像大小翻倍后和前端网络输出同样图像尺寸大小的卷积层组通过堆叠层在通道维度上堆叠后连接后序的卷积层组,五个卷积层组的输出分别连接后端网络的五个卷积层组;堆叠层用于将所输入的图像在通道维度上堆叠;所述后端网络中,输入连接中端网络最后序卷积层组的卷积层组输出图像大小与输入图像相同、通道数为4的特征图,并且输出连接融合网络的通道维度层;其他四个卷积层组各自间插有数量不同的翻倍层,使得这四个卷积层组输出图像大小与输入图像相同、通道数为64的特征图,并且这四个卷积层组的输出分别通过卷积层rr连接所述融合网络的融合堆叠层;卷积层rr用于将图像大小与输入图像相同、通道数为64的特征图处理后输出图像大小与输入图像相同、通道数为1的特征图;卷积层rr的卷积核大小为1*1,填充为0,步长为
1;融合堆叠层用于将四个通道数为1的特征图在维度上堆叠,输出图像大小与输入图像相同、通道数为4的融合特征图;通道维度层用于将输入的特征图执行sigmoid或softmax操作,生成通道数为4、图像尺寸与输入图像相同的系数特征图;所述融合求积层的输入连接所述通道维度层和融合堆叠层的输出,用于将所述系数特征图和所述融合特征图逐像素相乘,从而得到通道数为4、图像尺寸与输入图像相同的人群密度图;前端网络、中端网络和后端网络的各卷积层均设有激活函数relu。
5.进一步,根据本发明的基于上下文注意力的图片人头计数的方法,前端网络中,五个卷积层组分别标记为卷积层组rf1、卷积层组rf2、卷积层组rf3、卷积层组rf4和卷积层组rf5;所述卷积层组rf1包括依次串接的卷积层rf11和卷积层rf12;所述卷积层组rf2包括依次串接的卷积层rf21和卷积层rf22;所述卷积层组rf3包括依次串接的卷积层rf31、卷积层rf32和卷积层rf33;所述卷积层组rf4包括依次串接的卷积层rf41、卷积层rf42和卷积层rf43;所述卷积层组rf5包括依次串接的卷积层rf51、卷积层rf52和卷积层rf53;卷积层rf11、卷积层rf12、卷积层rf21、卷积层rf22、卷积层rf31、卷积层rf32、卷积层rf33、卷积层rf41、卷积层rf42、卷积层rf43、卷积层rf51、卷积层rf52、卷积层rf53的卷积核大小为3*3,步长为1,填充为1,输入通道数为:3、64、64、128、128、256、256、256、512、512、512、512、512,输出通道数为:64、64、128、128、256、256、256、512、512、512、512、512、512;连接前端网络五个卷积层组的四个池化层均采用池化核大小为2*2、步长为2、填充为0、采用最大池化的池化层;中端网络中,五个卷积层组分别标记为卷积层组rm1、卷积层组rm2、卷积层组rm3、卷积层组rm4和卷积层组rm5;所述卷积层组rm1包括依次串接的卷积层rm11和卷积层rm12;所述卷积层组rm2包括依次串接的卷积层rm21和卷积层rm22;所述卷积层组rm3包括依次串接的卷积层rm31和卷积层rm32;所述卷积层组rm4包括依次串接的卷积层rm41和卷积层rm42;所述卷积层组rm5包括依次串接的卷积层rm51和卷积层rm52;卷积层rm11、卷积层rm12、卷积层rm21、卷积层rm22、卷积层rm31、卷积层rm32、卷积层rm41、卷积层rm42、卷积层rm51、卷积层rm52的卷积核大小为3*3,步长为1,填充为1,输入通道数为:512、1024、1024、512、512、256、256、128、128、64,输出通道数为:1024、512、512、256、256、128、128、64、64、64;翻倍层采用双线性插值方式将图像大小翻倍;后端网络中,卷积层组均包括四个卷积层;五个卷积层组分别标记为卷积层组re1、卷积层组re2、卷积层组re3、卷积层组re4和卷积层组re5;所述卷积层组re1包括依次串接的四倍层ke11、卷积层re11、卷积层re12、翻倍层ke12、卷积层re13、卷积层re14和翻倍层ke13;所述卷积层组re2包括依次串接的翻倍层ke21、卷积层re21、卷积层re22、翻倍层ke22、卷积层re23、卷积层re24和翻倍层k23;所述卷积层组re3包括依次串接的翻倍层ke31、卷积层re31、卷积层re32、翻倍层ke32、卷积层re33和卷积层re34;所述卷积层组re4包括依次串接的的翻倍层ke41、卷积层re41、卷积层re42、卷积层re43和卷积层re44;所述卷积层组re5包括依次串接的卷积层re51、卷积层re52、卷积层re53和卷积层re54;卷积层
re11、卷积层re12、卷积层re13、卷积层re14、卷积层re21、卷积层re22、卷积层re23、卷积层re24、卷积层re31、卷积层re32、卷积层re33、卷积层re34、卷积层re41、卷积层re42、卷积层re43、卷积层re44、卷积层re51、卷积层re52、卷积层re53、卷积层re54的卷积核大小为3*3,步长为1,输入通道数分别为:512、512、256、128、256、256、256、128、128、128、128、128、64、64、64、64、64、64、32、16,输出通道数分别为:512、256、128、64、256、256、128、64、128、128、128、64、64、64、64、64、64、32、16、4;其中,卷积层re12、卷积层re14、卷积层re22、卷积层re24、卷积层re32、卷积层re34、卷积层re42和卷积层re44均为空洞率为2,填充为2的卷积层,其他卷积层填充为1;翻倍层ke12、翻倍层ke13、翻倍层ke21、翻倍层ke22、翻倍层ke23、翻倍层ke31、翻倍层ke32、和翻倍层ke41用于通过双线性插值方式将图像大小翻倍;四倍层ke11用于通过双线性插值方式将图像大小放大成四倍。
6.进一步,根据本发明的基于上下文注意力的图片人头计数的方法,该方法还包括模型初始化步骤、数据初始化步骤、图片预处理步骤和人头计数步骤;所述模型初始化步骤,用于:初始化所述上下文注意力网络模型;所述数据初始化步骤,用于:获取所述上下文注意力网络模型训练得到的模型特征矩阵数据,然后将所述模型特征矩阵数据加载至所述上下文注意力网络模型;所述图片预处理步骤,用于:以边缘切断的方式对输入的图片尺寸进行修整,使得图片的长宽尺寸均为16倍数,并以均值0.485,、0.456、 0.406和标准差0.229、0.224、0.225在三个通道上标准化像素值,使得图像在三个通道上归一化至区间[0,1],得到预处理图像fp;所述人头计数步骤,用于:将所述预处理图像fp输入至所述数据初始化后的上下文注意力网络模型,经所述上下文注意力网络模型计算得到人群密度图;然后通过人群密度图进行积分累加得到所输入的图片中的人数;所述通过人群密度图进行积分累加采用如下公式:;其中,sum为图片总人数,p(xi)表示人群密度图中第i个像素点的像素值。
[0007]
进一步,根据本发明的基于上下文注意力的图片人头计数的方法,该方法还包括获取训练数据集的步骤和模型训练步骤;所述模型训练步骤用于将所述训练数据集中的图片经所述图片预处理步骤后,输入至所述上下文注意力网络模型进行模型计算,得到所述模型特征矩阵数据。
[0008]
进一步,根据本发明的基于上下文注意力的图片人头计数的方法,所述模型训练步骤中采用如下损失函数对所述模型特征矩阵数据进行评估: ;其中,θ是所述模型特征矩阵数据,ii为所述训练数据集中第i幅图片,di(ii, θ)为所述训练数据集中第i幅图片通过所述所述人头计数步骤得到的人群密度图,dgi为所述训练数据集中第i幅图片通过手工编辑得到的期望密度图,n为所述训练数据集中的图片数。
[0009]
根据本发明的一种基于上下文注意力的图片人头计数的装置,该装置包括模型计算模块;所述模型计算模块用于通过上下文注意力网络模型计算得到人群密度图;
所述上下文注意力网络模型包括:前端网络、中端网络、后端网络和融合网络;所述前端网络、中端网络和后端网络分别包括五个由卷积层所组成的卷积层组;所述卷积层组包括有若干卷积层;所述融合网络包括通道维度层、融合堆叠层和融合求积层;所述前端网络中,五个卷积层组通过池化层按顺序依次串接,池化层使得五个卷积层组所输出的图像大小逐步缩半,并且最后序的卷积层组输出连接中端网络最前序的卷积层组;所述中端网络中,前序的卷积层组的输出分别通过翻倍层进行图像大小翻倍后和前端网络输出同样图像尺寸大小的卷积层组通过堆叠层在通道维度上堆叠后连接后序的卷积层组,五个卷积层组的输出分别连接后端网络的五个卷积层组;堆叠层用于将所输入的图像在通道维度上堆叠;所述后端网络中,输入连接中端网络最后序卷积层组的卷积层组输出图像大小与输入图像相同、通道数为4的特征图,并且输出连接融合网络的通道维度层;其他四个卷积层组各自间插有数量不同的翻倍层,使得这四个卷积层组输出图像大小与输入图像相同、通道数为64的特征图,并且这四个卷积层组的输出分别通过卷积层rr连接所述融合网络的融合堆叠层;卷积层rr用于将图像大小与输入图像相同、通道数为64的特征图处理后输出图像大小与输入图像相同、通道数为1的特征图;卷积层rr的卷积核大小为1*1,填充为0,步长为1;融合堆叠层用于将四个通道数为1的特征图在维度上堆叠,输出图像大小与输入图像相同、通道数为4的融合特征图;通道维度层用于将输入的特征图执行sigmoid或softmax操作,生成通道数为4、图像尺寸与输入图像相同的系数特征图;所述融合求积层的输入连接所述通道维度层和融合堆叠层的输出,用于将所述系数特征图和所述融合特征图逐像素相乘,从而得到通道数为4、图像尺寸与输入图像相同的人群密度图;前端网络、中端网络和后端网络的各卷积层均设有激活函数relu。
[0010]
进一步,根据本发明的基于上下文注意力的图片人头计数的装置,前端网络中,五个卷积层组分别标记为卷积层组rf1、卷积层组rf2、卷积层组rf3、卷积层组rf4和卷积层组rf5;所述卷积层组rf1包括依次串接的卷积层rf11和卷积层rf12;所述卷积层组rf2包括依次串接的卷积层rf21和卷积层rf22;所述卷积层组rf3包括依次串接的卷积层rf31、卷积层rf32和卷积层rf33;所述卷积层组rf4包括依次串接的卷积层rf41、卷积层rf42和卷积层rf43;所述卷积层组rf5包括依次串接的卷积层rf51、卷积层rf52和卷积层rf53;卷积层rf11、卷积层rf12、卷积层rf21、卷积层rf22、卷积层rf31、卷积层rf32、卷积层rf33、卷积层rf41、卷积层rf42、卷积层rf43、卷积层rf51、卷积层rf52、卷积层rf53的卷积核大小为3*3,步长为1,填充为1,输入通道数为:3、64、64、128、128、256、256、256、512、512、512、512、512,输出通道数为:64、64、128、128、256、256、256、512、512、512、512、512、512;连接前端网络五个卷积层组的四个池化层均采用池化核大小为2*2、步长为2、填
充为0、采用最大池化的池化层;中端网络中,五个卷积层组分别标记为卷积层组rm1、卷积层组rm2、卷积层组rm3、卷积层组rm4和卷积层组rm5;所述卷积层组rm1包括依次串接的卷积层rm11和卷积层rm12;所述卷积层组rm2包括依次串接的卷积层rm21和卷积层rm22;所述卷积层组rm3包括依次串接的卷积层rm31和卷积层rm32;所述卷积层组rm4包括依次串接的卷积层rm41和卷积层rm42;所述卷积层组rm5包括依次串接的卷积层rm51和卷积层rm52;卷积层rm11、卷积层rm12、卷积层rm21、卷积层rm22、卷积层rm31、卷积层rm32、卷积层rm41、卷积层rm42、卷积层rm51、卷积层rm52的卷积核大小为3*3,步长为1,填充为1,输入通道数为:512、1024、1024、512、512、256、256、128、128、64,输出通道数为:1024、512、512、256、256、128、128、64、64、64;翻倍层采用双线性插值方式将图像大小翻倍;后端网络中,卷积层组均包括四个卷积层;五个卷积层组分别标记为卷积层组re1、卷积层组re2、卷积层组re3、卷积层组re4和卷积层组re5;所述卷积层组re1包括依次串接的四倍层ke11、卷积层re11、卷积层re12、翻倍层ke12、卷积层re13、卷积层re14和翻倍层ke13;所述卷积层组re2包括依次串接的翻倍层ke21、卷积层re21、卷积层re22、翻倍层ke22、卷积层re23、卷积层re24和翻倍层k23;所述卷积层组re3包括依次串接的翻倍层ke31、卷积层re31、卷积层re32、翻倍层ke32、卷积层re33和卷积层re34;所述卷积层组re4包括依次串接的的翻倍层ke41、卷积层re41、卷积层re42、卷积层re43和卷积层re44;所述卷积层组re5包括依次串接的卷积层re51、卷积层re52、卷积层re53和卷积层re54;卷积层re11、卷积层re12、卷积层re13、卷积层re14、卷积层re21、卷积层re22、卷积层re23、卷积层re24、卷积层re31、卷积层re32、卷积层re33、卷积层re34、卷积层re41、卷积层re42、卷积层re43、卷积层re44、卷积层re51、卷积层re52、卷积层re53、卷积层re54的卷积核大小为3*3,步长为1,输入通道数分别为:512、512、256、128、256、256、256、128、128、128、128、128、64、64、64、64、64、64、32、16,输出通道数分别为:512、256、128、64、256、256、128、64、128、128、128、64、64、64、64、64、64、32、16、4;其中,卷积层re12、卷积层re14、卷积层re22、卷积层re24、卷积层re32、卷积层re34、卷积层re42和卷积层re44均为空洞率为2,填充为2的卷积层,其他卷积层填充为1;翻倍层ke12、翻倍层ke13、翻倍层ke21、翻倍层ke22、翻倍层ke23、翻倍层ke31、翻倍层ke32、和翻倍层ke41用于通过双线性插值方式将图像大小翻倍;四倍层ke11用于通过双线性插值方式将图像大小放大成四倍。
[0011]
进一步,根据本发明的基于上下文注意力的图片人头计数的装置,该装置还包括模型初始化模块、数据初始化模块、图片预处理模块和人头计数模块;所述模型初始化模块,用于:初始化所述上下文注意力网络模型;所述数据初始化模块,用于:获取所述上下文注意力网络模型训练得到的模型特征矩阵数据,然后将所述模型特征矩阵数据加载至所述上下文注意力网络模型;所述图片预处理模块,用于:以边缘切断的方式对输入的图片尺寸进行修整,使得图片的长宽尺寸均为16倍数,并以均值0.485,、0.456、 0.406和标准差0.229、0.224、0.225在三个通道上标准化像素值,使得图像在三个通道上归一化至区间[0,1],得到预处理图像fp;所述人头计数模块,用于:将所述预处理图像fp输入至所述数据初始化后的上下
文注意力网络模型,经所述上下文注意力网络模型计算得到人群密度图;然后通过人群密度图进行积分累加得到所输入的图片中的人数;所述通过人群密度图进行积分累加采用如下公式:;其中,sum为图片总人数,p(xi)表示人群密度图中第i个像素点的像素值。
[0012]
进一步,根据本发明的基于上下文注意力的图片人头计数的装置,该装置还包括获取训练数据集的模块和模型训练模块;所述模型训练模块用于将所述训练数据集中的图片经所述图片预处理模块后,输入至所述上下文注意力网络模型进行模型计算,得到所述模型特征矩阵数据。
[0013]
进一步,根据本发明的基于上下文注意力的图片人头计数的装置,所述模型训练模块中采用如下损失函数对所述模型特征矩阵数据进行评估: ;其中,θ是所述模型特征矩阵数据,ii为所述训练数据集中第i幅图片,di(ii, θ)为所述训练数据集中第i幅图片通过所述所述人头计数模块得到的人群密度图,dgi为所述训练数据集中第i幅图片通过手工编辑得到的期望密度图,n为所述训练数据集中的图片数。
[0014]
本发明的技术效果如下:1、相比于现有基于多列卷积神经网络的图片人头计数方法,本发明采用上下文注意力的图片人头计数方法可以有效减少模型参数量,从而提高图片人头计数的效率。
[0015]
2、相比于现有技术,无论是现有的基于多列卷积神经网络的图片人头计数方法,还是现有的基于单列卷积神经网络的图片人头计数方法,本发明的方法在准确度和稳定度上均有一定程度的提升。
附图说明
[0016]
图1是本发明实施例上下文注意力网络模型的整体结构示意图。
[0017]
图2是本发明实施例上下文注意力网络模型的前端网络的结构示意图。
[0018]
图3是本发明实施例上下文注意力网络模型的中端网络的结构示意图。
[0019]
图4是本发明实施例上下文注意力网络模型的后端网络的结构示意图。
[0020]
图5是本发明实施例人流流量分析系统的整体结构示意图。
具体实施方式
[0021]
下面结合附图对本发明做进一步详细说明。
[0022]
本实施例涉及一种人流流量分析系统,如图5所示,包括设置在机房内的服务器100和设置在监测点的若干个前端摄像头200。前端摄像头200通过网络300连接服务器100。服务器100通过前端摄像头200获取监测点的现场场景实时图像,然后通过本发明的一种基于上下文注意力的图片人头计数的方法对所获取的实时图像进行分析,统计出人数,进而计算人流流量。
[0023]
本发明的基于上下文注意力的图片人头计数的方法是由服务器100执行计算机软
件程序所实现的方法。该方法包括以下步骤:包括模型初始化步骤、数据初始化步骤、图片预处理步骤和人头计数步骤。其中,模型初始化步骤,用于:初始化上下文注意力网络模型。数据初始化步骤,用于:获取上下文注意力网络模型预先训练得到的模型特征矩阵数据,然后将模型特征矩阵数据加载至上下文注意力网络模型。图片预处理步骤,用于:以边缘切断的方式对输入的图片尺寸进行修整,使得图片的长宽尺寸均为16倍数,并以均值0.485,、0.456、 0.406和标准差0.229、0.224、0.225在三个通道上标准化像素值,使得图像在三个通道上归一化至区间[0,1],得到预处理图像fp。人头计数步骤,用于将预处理图像fp输入至数据初始化后的上下文注意力网络模型,经上下文注意力网络模型计算得到人群密度图;然后通过人群密度图进行积分累加得到所输入的图片中的人数。
[0024]
其中,图片预处理步骤中“输入的图片”即为图像。“以边缘切断的方式对输入的图片尺寸进行修整,使得图片的长宽尺寸均为16倍数”以数学公式表示为:wo=16*int(wi/16),ho=16*int(hi/16)。其中wi和hi分别为输入图片的宽和高,wo和ho分别为边缘切断后图片的宽和高,int为取整函数。“三个通道上标准化像素值”中的三个通道通常是指图像或图片的rgb通道。人头计数步骤中的“将预处理图像fp输入至数据初始化后的上下文注意力网络模型,经上下文注意力网络模型计算得到人群密度图”为即为本发明所指的模型计算步骤。本发明模型计算步骤通过上下文注意力网络模型计算得到人群密度图。本发明的上下文注意力网络模型是在卷积神经网络模型平台系统中所构建的模型,该卷积神经网络模型平台系统提供模型初始化、模型训练、模型特征矩阵数据输出、模型特征矩阵数据加载、模型计算等接口。前述的模型初始化步骤、数据初始化步骤通过调用卷积神经网络模型平台系统所提供的接口所实现。
[0025]
如图1所示,本发明的上下文注意力网络模型包括:前端网络、中端网络、后端网络和融合网络。其中,前端网络、中端网络和后端网络分别包括了五个由卷积层所组成的卷积层组。前端网络中的五个卷积层组分别为卷积层组rf1、卷积层组rf2、卷积层组rf3、卷积层组rf4和卷积层组rf5。中端网络中的五个卷积层组分别为卷积层组rm1、卷积层组rm2、卷积层组rm3、卷积层组rm4和卷积层组rm5。后端网络中的五个卷积层组分别为卷积层组re1、卷积层组re2、卷积层组re3、卷积层组re4和卷积层组re5。
[0026]
卷积层组rf1、卷积层组rf2、卷积层组rf3、卷积层组rf4和卷积层组rf5按顺序通过池化层依次相连。池化层的池化参数为:池化核大小为2*2,步长为2,填充为0,采用最大池化。
[0027]
卷积层组rm1的输入连接卷积层组rf5的输出。卷积层组rm2的输入通过翻倍堆叠组连接卷积层组rm1和卷积层组rf4的输出。卷积层组rm3的输入通过翻倍堆叠组连接卷积层组rm2和卷积层组rf3的输出。卷积层组rm4的输入通过翻倍堆叠组连接卷积层组rm3和卷积层组rf2的输出。卷积层组rm5的输入通过翻倍堆叠组连接卷积层组rm4和卷积层组rf1的输出。
[0028]
卷积层组rm1、卷积层组rm2、卷积层组rm3、卷积层组rm4和卷积层组rm5的输出分别连接卷积层组re1、卷积层组re2、卷积层组re3、卷积层组re4和卷积层组re5的输入,也就是,卷积层组re1的输入连接卷积层组rm1的输出;卷积层组re2的输入连接卷积层组rm2的输出;卷积层组re3的输入连接卷积层组rm3的输出;卷积层组re4的输入连接卷积层组rm4的输出;卷积层组re5的输入连接卷积层组rm5的输出。
[0029]
融合网络包括通道维度层、融合堆叠层、融合求积层和四个卷积层rr。融合堆叠层的输入通过四个卷积层rr分别连接卷积层组re1、卷积层组re2、卷积层组re3和卷积层组re4的输出。通道维度层的输入连接卷积层组re5的输出。融合求积层的输入连接通道维度层和融合堆叠层的输出。融合求积层所输出的图像即为最终的人群密度图。
[0030]
前端网络,参照图2,总共包括13个卷积层。各卷积层中,卷积核大小均为3*3,卷积步长为1,填充为1。其中,卷积层组rf1和卷积层组rf2分别包含两个卷积层;卷积层组rf3、卷积层组rf4和卷积层组rf5分别包含三个卷积层。具体来说,卷积层组rf1包括依次串接的卷积层rf11和卷积层rf12。卷积层组rf2包括依次串接的卷积层rf21和卷积层rf22。卷积层组rf3包括依次串接的卷积层rf31、卷积层rf32和卷积层rf33。卷积层组rf4包括依次串接的卷积层rf41、卷积层rf42和卷积层rf43。卷积层组rf5包括依次串接的卷积层rf51、卷积层rf52和卷积层rf53。这里的依次串接表示的是前一层的输出连接后一层的输入。结合连接卷积层组rf1、卷积层组rf2、卷积层组rf3、卷积层组rf4和卷积层组rf5的池化层,各卷积层具体连接如下:卷积层rf12的输入连接卷积层rf11的输出,卷积层rf11的输入也就是上下文注意力网络模型的输入。卷积层rf12的输出也就是卷积层组rf1的输出,输出的特征图标记为特征图ff1。卷积层rf11的输入通道数为3,输出通道数为64;卷积层rf12的输入通道数为64,输出通道数为64。由此,特征图ff1的通道数为64,图像大小和输入图像相同。这里的输入图像是上下文注意力网络模型最初的输入图像,以下类同,不再赘述。
[0031]
卷积层rf22的输入连接卷积层rf21的输出,卷积层rf21的输入连接卷积层组rf1和卷积层组rf2之间的池化层的输出,卷积层组rf1和卷积层组rf2之间的池化层的输入连接卷积层rf12的输出。卷积层rf22的输出也就是卷积层组rf2的输出,输出的特征图标记为特征图ff2。卷积层rf21的输入通道数为64,输出通道数为128;卷积层rf22的输入通道数为128,输出通道数为128。由此,特征图ff2的通道数为128。因经过步长为2的池化层处理,特征图ff2的图像大小为输入图像的1/2。这里的图像大小所表示的图像的长宽尺寸,图像大小为输入图像的1/2表示的是长和宽分别为输入图像长和宽的1/2,以下类同,不再赘述。
[0032]
卷积层rf33的输入连接卷积层rf32的输出,卷积层rf32的输入连接卷积层rf31的输出,卷积层rf31的输入连接卷积层组rf2和卷积层组rf3之间的池化层的输出,卷积层组rf2和卷积层组rf3之间的池化层的输入连接卷积层rf22的输出。卷积层rf33的输出也就是卷积层组rf3的输出,输出的特征图标记为特征图ff3。卷积层rf31的输入通道数为128,输出通道数为256;卷积层rf32的输入通道数为256,输出通道数为256;卷积层rf33的输入通道数为256,输出通道数为256。由此,特征图ff3的通道数为256。因经过池化层处理,特征图ff3的图像大小为特征图ff2的1/2,也即为输入图像的1/4。
[0033]
卷积层rf43的输入连接卷积层rf42的输出,卷积层rf42的输入连接卷积层rf41的输出,卷积层rf41的输入连接卷积层组rf3和卷积层组rf4之间的池化层的输出,卷积层组rf3和卷积层组rf4之间的池化层的输入连接卷积层rf33的输出。卷积层rf43的输出也就是卷积层组rf4的输出,输出的特征图标记为特征图ff4。卷积层rf41的输入通道数为256,输出通道数为512;卷积层rf42的输入通道数为512,输出通道数为512;卷积层rf43的输入通道数为512,输出通道数为512。由此,特征图ff4的通道数为512。因经过池化层处理,特征图ff4的图像大小为特征图ff3的1/2,也即为输入图像的1/8。
[0034]
卷积层rf53的输入连接卷积层rf52的输出,卷积层rf52的输入连接卷积层rf51的输出,卷积层rf51的输入连接卷积层组rf4和卷积层组rf5之间的池化层的输出,卷积层组rf4和卷积层组rf5之间的池化层的输入连接卷积层rf43的输出。卷积层rf53的输出也就是卷积层组rf5的输出,输出的特征图标记为特征图ff5。卷积层rf51的输入通道数为256,输出通道数为512;卷积层rf52的输入通道数为512,输出通道数为512;卷积层rf53的输入通道数为512,输出通道数为512。由此,特征图ff5的通道数为512。因经过池化层处理,特征图ff5的图像大小为特征图ff4的1/2,也即为输入图像的1/16。
[0035]
前端网络通过上述连接输出五个特征图,分别为特征图ff1、特征图ff2、特征图ff3、特征图ff4和特征图ff5。特征图ff1、特征图ff2、特征图ff3、特征图ff4和特征图ff5的通道数分别为64、128、256、512和512,图像大小分别为输入图像的1、1/2、1/4、1/8和1/16。这里的“1”表示图像大小和输入图像相同。
[0036]
中端网络,参照图3,包括五个分别由两个卷积层串接所组成的卷积层组、四个翻倍堆叠组,总共包含了10个卷积层。五个卷积层组中的各卷积层中,卷积核大小均为3*3,卷积步长为1,填充为1。五个卷积层组分别为:卷积层组rm1、卷积层组rm2、卷积层组rm3、卷积层组rm4和卷积层组rm5。卷积层组rm1包括依次串接的卷积层rm11和卷积层rm12。卷积层组rm2包括依次串接的卷积层rm21和卷积层rm22。卷积层组rm3包括依次串接的卷积层rm31和卷积层rm32。卷积层组rm4包括依次串接的卷积层rm41和卷积层rm42。卷积层组rm5包括依次串接的卷积层rm51和卷积层rm52。翻倍堆叠组包括翻倍层和堆叠层,由此,四个翻倍堆叠组包括四个翻倍层和四个堆叠层。四个卷积层分别为翻倍层k1、翻倍层k2、翻倍层k3和翻倍层k4。四个堆叠层分别为堆叠层d1、堆叠层d2、堆叠层d3和堆叠层d4。堆叠层用于将输入的图像在通道维度上堆叠后输出。翻倍层用于通过双线性插值方式将图像大小翻倍。结合翻倍层k1、翻倍层k2、翻倍层k3和翻倍层k4,以及堆叠层d1、堆叠层d2、堆叠层d3和堆叠层d4,中端网络各层具体连接如下:卷积层rm11的输入连接卷积层rf5的输出,也就是输入卷积层rm11的是特征图ff5。卷积层rm11的输出连接卷积卷积层rm12的输入。卷积层rm12的输出,也就是,卷积层组rm1的输出,输出的特征图标记为特征图fm1。卷积层rm11的输入通道数为512,输出通道数为1024;卷积层rm12的输入通道数为1024,输出通道数为512。由此,特征图fm1的通道数为512,图像大小和特征图ff5相同,也就是,为输入图像的1/16。
[0037]
卷积层rm21的输入连接堆叠层d1的输出,输出连接卷积卷积层rm22的输入。卷积层rm22的输出,也就是,卷积层组rm2的输出,输出的特征图标记为特征图fm2。堆叠层d1的输入连接翻倍层k1和卷积层rf43的输出。翻倍层k1的输入连接卷积层rm12的输出。特征图fm1通过翻倍层k1图像尺寸加倍后将特征图fm1输出通道数为512、图像尺寸为输入图像的1/8的特征图。由此,堆叠层d1通过翻倍层k1输入的通道数为512、图像尺寸为输入图像的1/8的特征图和卷积层rf43所输出的通道数为512、图像尺寸为输入图像的1/8的特征图ff4在通道维度上堆叠,输出通道数为1024、图像尺寸为输入图像的1/8的特征图,作为卷积层rm21的输入。卷积层rm21的输入通道数为1024,输出通道数为512;卷积层rm22的输入通道数为512,输出通道数为256。由此,特征图fm2的通道数为256,图像大小和特征图ff4相同,也就是,为输入图像的1/8。
[0038]
卷积层rm31的输入连接堆叠层d2的输出,输出连接卷积卷积层rm32的输入。卷积
层rm32的输出,也就是,卷积层组rm3的输出,输出的特征图标记为特征图fm3。堆叠层d2的输入连接翻倍层k2和卷积层rf33的输出。特征图fm2通过翻倍层k2图像尺寸加倍后输出通道数为256、图像尺寸为输入图像的1/4的特征图。由此,堆叠层d2通过翻倍层k2输入的通道数为256、图像尺寸为输入图像的1/4的特征图和卷积层rf33所输出的通道数为256、图像尺寸为输入图像的1/4的特征图ff3在通道维度上堆叠,输出通道数为512、图像尺寸为输入图像的1/4的特征图,作为卷积层rm31的输入。卷积层rm31的输入通道数为512,输出通道数为256;卷积层rm32的输入通道数为256,输出通道数为128。由此,特征图fm3的通道数为128,图像大小和特征图ff3相同,也就是,为输入图像的1/4。
[0039]
卷积层rm41的输入连接堆叠层d3的输出,输出连接卷积卷积层rm42的输入。卷积层rm42的输出,也就是,卷积层组rm4的输出,输出的特征图标记为特征图fm4。堆叠层d3的输入连接翻倍层k3和卷积层rf22的输出。特征图fm3通过翻倍层k3图像尺寸加倍后输出通道数为128、图像尺寸为输入图像的1/2的特征图。由此,堆叠层d3通过翻倍层k3输入的通道数为128、图像尺寸为输入图像的1/2的特征图和卷积层rf22所输出的通道数为128、图像尺寸为输入图像的1/2的特征图ff2在通道维度上堆叠,输出通道数为256、图像尺寸为输入图像的1/2的特征图,作为卷积层rm41的输入。卷积层rm41的输入通道数为256,输出通道数为128;卷积层rm42的输入通道数为128,输出通道数为64。由此,特征图fm4的通道数为64,图像大小和特征图ff2相同,也就是,为输入图像的1/2。
[0040]
卷积层rm51的输入连接堆叠层d4的输出,输出连接卷积卷积层rm52的输入。卷积层rm52的输出,也就是,卷积层组rm5的输出,输出的特征图标记为特征图fm5。堆叠层d4的输入连接翻倍层k4和卷积层rf12的输出。特征图fm4通过翻倍层k4图像尺寸加倍后输出通道数为64、图像尺寸和输入图像相同的特征图。由此,堆叠层d4通过翻倍层k4输入的通道数为64、图像尺寸和输入图像相同的特征图和卷积层rf12所输出的通道数为64、图像尺寸和输入图像相同的特征图ff1在通道维度上堆叠,输出通道数为128、图像尺寸和输入图像相同的特征图,作为卷积层rm51的输入。卷积层rm51的输入通道数为128,输出通道数为64;卷积层rm52的输入通道数为64,输出通道数为64。由此,特征图fm5的通道数为64,图像大小和特征图ff1相同,也就是,图像大小和输入图像相同。
[0041]
中端网络通过上述连接输出五个特征图,分别为特征图fm1、特征图fm2、特征图fm3、特征图fm4和特征图fm5。特征图fm1、特征图fm2、特征图fm3、特征图fm4和特征图fm5的通道数分别为512、256、128、64和64,图像大小分别为输入图像的1/16、1/8、1/4、1/2和1。这里的“1”表示图像大小和输入图像相同。
[0042]
后端网络,参照图4,包括五个分别由四个卷积层串接所组成的卷积层组,分别为:卷积层组re1、卷积层组re2、卷积层组re3、卷积层组re4和卷积层组re5。卷积层组re1、卷积层组re2、卷积层组re3、卷积层组re4和卷积层组re5相互独立。卷积层组re1包括依次串接的四倍层ke11、卷积层re11、卷积层re12、翻倍层ke12、卷积层re13、卷积层re14和翻倍层ke13。卷积层组re2包括依次串接的翻倍层ke21、卷积层re21、卷积层re22、翻倍层ke22、卷积层re23、卷积层re24和翻倍层ke23。卷积层组re3包括依次串接的翻倍层k31、卷积层re31、卷积层re32、翻倍层ke32、卷积层re33和卷积层re34。卷积层组re4包括依次串接的翻倍层ke41、卷积层re41、卷积层re42、卷积层re43和卷积层re44。卷积层组re5包括依次串接的卷积层re51、卷积层re52、卷积层re53和卷积层re54。其中,翻倍层ke12、翻倍层ke13、翻
倍层ke21、翻倍层ke22、翻倍层ke23、、翻倍层ke31、、翻倍层ke32和翻倍层ke41均用于通过双线性插值方式将图像大小翻倍。四倍层ke11用于通过双线性插值方式将图像大小放大为四倍,相当于两个依次相连的翻倍层,也可以视为两个翻倍层的串接。后端网络各层具体连接如下:卷积层组re1中,四倍层ke11的输入连接卷积层rm12的输出。也就是四倍层ke11的输入是特征图fm1。卷积层re11的输入连接四倍层ke11的输出,输出连接卷积层re12的输入,也就是说,卷积层re11的所输入的特征图的图像大小为特征图fm1的四倍,也就是,输入图像的1/4。卷积层re12的输出连接翻倍层ke12的输入。卷积层re13的输入连接翻倍层ke12的输出,输出连接卷积层re14的输入,也就是说,卷积层re13所输入的特征图的图像大小为特征图fm1的八倍,也就是输入图像的1/2。卷积层re14的输出连接翻倍层ke13的输入。翻倍层ke13的输出也就是卷积层组re1的输出,其输出的特征图标记为特征图fe1。各卷积层配置如下:卷积层re11的输入通道数为512,输出通道数为512,填充为1;卷积层re12的输入通道数为512,输出通道数为256,空洞率为2,填充为2;卷积层re13的输入通道数为256,输出通道数为128,填充为1;卷积层re14的输入通道数为128,输出通道数为64,空洞率为2,填充为2。卷积层re11、卷积层re12、卷积层re13和卷积层re14的卷积核大小均为3*3,卷积步长为1。由此,卷积层组re1所输出的特征图fe1的通道数为64、图像大小与输入图像相同。
[0043]
卷积层组re2中,翻倍层ke21的输入连接卷积层rm22的输出。也就是卷积层re21的输入是特征图fm2。卷积层re21的输入连接翻倍层ke21的输出,输出连接卷积层re22的输入,也就是说,卷积层re21的所输入的特征图的图像大小为特征图fm2的两倍,也就是,输入图像的1/4。卷积层re22的输出连接翻倍层ke22的输入。卷积层re23的输入连接翻倍层ke22的输出,输出连接卷积层re24的输入,也就是说,卷积层re23的所输入的特征图的图像大小为特征图fm2的四倍,也就是,输入图像的1/2。卷积层re24的输出连接翻倍层ke23的输入。翻倍层ke23的输出也就是卷积层组re2的输出,其输出的特征图标记为特征图fe2。各卷积层配置如下:卷积层re21的输入通道数为256,输出通道数为256,填充为1;卷积层re22的输入通道数为256,输出通道数为256,空洞率为2,填充为2;卷积层re23的输入通道数为256,输出通道数为128,填充为1;卷积层re24的输入通道数为128,输出通道数为64,空洞率为2,填充为2。卷积层re21、卷积层re22、卷积层re23和卷积层re24的卷积核大小均为3*3,卷积步长为1。由此,卷积层组re2所输出的特征图fe2的通道数为64、图像大小与输入图像相同。
[0044]
卷积层组re3中,翻倍层ke31的输入连接卷积层rm32的输出。也就是卷积层re31的输入是特征图fm3。卷积层re31的输入连接翻倍层ke31的输出,输出连接卷积层re32的输入,也就是说,卷积层re31的所输入的特征图的图像大小为特征图fm3的两倍,也就是,输入图像的1/2。卷积层re32的输出连接翻倍层ke32的输入。卷积层re33的输入连接翻倍层ke32的输出,输出连接卷积层re34的输入,也就是说,卷积层re33的所输入的特征图的图像大小为特征图fm3的四倍,和输入图像相同。卷积层re34的输出也就是卷积层组re3的输出,其输出的特征图标记为特征图fe3。各卷积层配置如下:卷积层re31的输入通道数为128,输出通道数为128,填充为1;卷积层re32的输入通道数为128,输出通道数为128,空洞率为2,填充为2;卷积层re33的输入通道数为128,输出通道数为128,填充为1;卷积层re34的输入通道数为128,输出通道数为64,空洞率为2,填充为2。卷积层re31、卷积层re32、卷积层re33和卷积层re34的卷积核大小均为3*3,卷积步长为1。由此,卷积层组re3所输出的特征图fe3的通
道数为64、图像大小与输入图像相同。
[0045]
卷积层组re4中,翻倍层ke41的输入连接卷积层rm42的输出。也就是卷积层re41的输入是特征图fm4。卷积层re41的输入连接翻倍层ke41的输出,输出连接卷积层re42的输入,也就是说,卷积层re41的所输入的特征图的图像大小为特征图fm4的两倍,也就是,和输入图像相同。卷积层re43的输入连接卷积层re42的输出,输出连接卷积层re44的输入。卷积层re44的输出也就是卷积层组re4的输出,其输出的特征图标记为特征图fe4。各卷积层配置如下:卷积层re41的输入通道数为64,输出通道数为64,填充为1;卷积层re42的输入通道数为64,输出通道数为64,空洞率为2,填充为2;卷积层re43的输入通道数为64,输出通道数为64,填充为1;卷积层re44的输入通道数为64,输出通道数为64,空洞率为2,填充为2。卷积层re41、卷积层re42、卷积层re43和卷积层re44的卷积核大小均为3*3,卷积步长为1。由此,卷积层组re4所输出的特征图fe4的通道数为64、图像大小与输入图像相同。
[0046]
卷积层组re5中,卷积层re51的输入连接卷积层rm52的输出。也就是卷积层re51的输入是特征图fm5。卷积层re51的输出连接卷积层re52的输入。卷积层re52的输出连接卷积层re53的输入。卷积层re53的输出连接卷积层re54的输入。卷积层re54的输出也就是卷积层组re5的输出,其输出的特征图标记为特征图fe5。各卷积层配置如下:卷积层re51的输入通道数为64,输出通道数为64;卷积层re52的输入通道数为64,输出通道数为32;卷积层re53的输入通道数为32,输出通道数为16;卷积层re54的输入通道数为16,输出通道数为4;卷积层re51、卷积层re52、卷积层re53和卷积层re54的卷积核大小为3*3,卷积步长为1,填充为1。卷积层组re5所输出的特征图fe5的通道数为4、图像大小与输入图像相同。
[0047]
由此,后端网络通过上述连接输出五个特征图,分别为特征图fe1、特征图fe2、特征图fe3、特征图fe4和特征图fe5。特征图fe1、特征图fe2、特征图fe3、特征图fe4和特征图fe5的通道数分别为64、64、64、64和4,图像大小均和输入图像相同。
[0048]
融合网络中,卷积层rr是将通道数64的图像卷积成通道数为1的图像。也就是卷积层rr的输入通道数为64、输出通道数为1。卷积层rr的卷积核大小为1*1,步长为1,填充为0。由卷积层组re1、卷积层组re2、卷积层组re3和卷积层组re4输出的特征图fe1、特征图fe2、特征图fe3和特征图fe4经卷积层rr卷积后分别输出四个通道数为1图像大小与输入图像相同的特征图。四个通道数为1的特征图经融合堆叠层在通道维度上堆叠后,堆叠成通道数为4,图像大小与输入图像相同的融合特征图。
[0049]
通道维度层是一个sigmoid或softmax操作的模块,用于将卷积层组re5所输出的特征图fe5通过sigmoid或softmax操作生成通道数为4、图像尺寸与输入图像相同的系数特征图。这里的sigmoid是指将图像的各通道的每个像素值通过sigmoid函数转换。sigmoid函数为本领域计数人员所熟悉,定义如下:sigmoid(x)= invmul (1+exp(-x))。这里的softmax是指将图像的每个像素值通过softmax函数转换。softmax函数定义如下:softmax (x_i)= exp(-x_i)*invmul (exp(-x_1)+ exp(-x_2) +exp(-x_3)+ exp(-x_4));其中,x_i表示第i通道上像素点x的像素值,x_1、x_2、x_3、x_4分别为四个通道上像素点x的像素值,这里i取值为1,2,3或4。
[0050]
上述公式中,invmul表示倒数函数,exp表示以自然常数e为底的指数函数。
[0051]
通道维度层针对的是像素值的转换处理,因此所输出的特征图的通道数和图像大
小保持不变,也就是输出的系数特征图的通道数为4,图像尺寸与输入图像相同。
[0052]
由此,融合求积层所输入的融合特征图和系数特征图在通道数和图像大小上均相同。融合求积层用于将系数特征图和融合特征图逐像素相乘,从而得到通道数为4、图像尺寸与输入图像相同的人群密度图。具体来说,融合求积层将输入的两个特征图按照像素对像素的方式逐一相乘求乘积,从而得到人群密度图中对应像素的像素值。本发明中,系数特征图表示的是上下文注意力的特征,这也是本发明名称的来源。
[0053]
通过上述各卷积层的配置可以知,本发明前端网络、中端网络和后端网络的各个卷积层的卷积核大小均为3*3,步长均1,若卷积层是空洞率为2的空洞卷积层时,填充为2,否则空洞率为1,填充为1。
[0054]
此外,前端网络、中端网络和后端网络的每个卷积层后均设有激活函数relu。
[0055]
此外,需要说明的是,本发明中的上下文注意力网络模型是机器计算的模块。上下文注意力网络模型中的前端网络、中端网络、后端网络和融合网络相当于机器计算模块的集合,模型中的每一层,包括池化层、卷积层相当于计算执行的步骤。
[0056]
模型计算后得到人群密度图,然后根据人群密度图即可计算出图片中的人数。根据人群密度图计算图片中的人数采用积分累加,具体为:;其中,sum为图片总人数,p(xi)表示人群密度图中第i个像素点的像素值。
[0057]
如前,数据初始化步骤中的模型特征矩阵数据通过模型训练学习得到。为训练得到上述的模型特征矩阵数据,本实施例的方法,还包括获取训练数据集的步骤和模型训练步骤。模型训练步骤用于将训练数据集中的图片前述的图片预处理步骤后,输入至上下文注意力网络模型进行模型计算,得到模型特征矩阵数据。模型训练步骤中采用如下损失函数对模型特征矩阵数据进行评估:;其中,θ是模型特征矩阵数据,ii为训练数据集中第i幅图片,di(ii, θ)为训练数据集中第i幅图片通过人头计数步骤得到的人群密度图,d
gi
为训练数据集中第i幅图片通过手工编辑得到的期望密度图,n为训练数据集中的图片数。这里的期望密度图也可以视为真实的人群密度图。
[0058]
本实施例以ucf_cc_50数据集、shanghaitech数据集和mall数据集作为训练和测试数据集。ucf_cc_50数据集来源于互联网,总共包含50张图片,一共有63974人,每张图片人数从94人到4543人不等。由于该数据集场景极为密集,而且图片数量较少,故为当前最具挑战性的数据集之一。shanghaitech数据集是上海科技大学公开的一个数据集分为part_a、part_b两个部分,共有1198张图片,总共标注了330165个人。mall数据集总共包含2000张图片,共有62325人,每张图片人数从13人到53人不等,来源于安装在购物中心的监控摄像头。在ucf_cc_50数据集中,根据本实施例的方法实验测试得到的人头计数的平均误差为238.3,均方根误差为363.1。在shanghaitech数据集part_a上实验测试的人头计数的平均误差为62.2,均方根误差为100.6。在shanghaitech数据集part_b上实验测试的人头计数的平均误差为7.9,均方根误差为12.1。在mall数据集上实验测试的人头计数的平均误差为1.31,均方根误差为1.59,准确度达到96%。
[0059]
对比专利文献cn 112651390 a所公开的方法,该方法在shanghaitech数据集part_a上的平均误差为87.0,均方根误差为134.8,part_b上的平均误差为14.2,均方根误差为23.3。很明显,本发明相比于专利文献cn 112651390 a所公开的方法有较大程度的提升。
[0060]
对比li等所提出的基于多列卷积神经网络的密集场景识别网络,即,congested scene recognition network,简称csrnet。密集场景识别网络是在专利文献cn 112651390 a后所提出的方法。在密集场景识别网络的方法下,在ucf_cc_50数据集中人头计数的平均误差为266.0,均方根误差为397.7;在shanghaitech数据集part_a上实验测试的人头计数的平均误差为68.2,均方根误差为115.0。在shanghaitech数据集part_b上实验测试的人头计数的平均误差为10.6,均方根误差为15.8。显而易见地,本发明方法相比于csrnet其准确度有较大程度的提升。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1