一种基于BERT神经网络与多语义学习的方面级情感分析方法
一种基于bert神经网络与多语义学习的方面级情感分析方法
技术领域
1.本发明涉及自然语言识别处理领域中的情感分析,具体是一种基于bert (bidirectional encoder representations from transformers)神经网络与多语义学习的方面级情感分析方法。该方法以bert语言模型为基础,提出了一种由多个语义学习模块组成、具有方面感知增强的方面级情感分析模型,产生强大的情感语义表征,以实现缓解方面级情感分析方法中普遍存在的细腻情感分析与其语料数量小之间的矛盾问题,可广泛应用于各个领域的方面级情感分析任务中。
背景技术:
2.方面级情感分类的目的是预测方面词在句子或者文档中的极性,它是一项细粒度情感分析的任务,与传统的情感分析任务不同,它是在方面词上做情感极性分析(一般为积极、消极、中性三个分类)。方面级情感分类常用在评论人的评论句子中,如:商场购物评论、餐饮评论、电影评论等。方面级情感分类,通常在一个句子中有多个方面词及其相关的情感极性,例如句子“the environment is romantic,but the food is horrible,对于方面词“environment”它是积极的,但对于方面词“food”它是消极的。总的来说:传统的句子情感分类任务是判断一句话的情感,而方面级情感分类任务是基于方面词去判断方面词极性的情感分类任务。
3.随着人工神经网络技术的不断发展,各种神经网络如long short-term memory(lstm)、 deep memory network和google ai language提出的bidirectional encoderrepresentations from transformers(bert)语言模型被应用于方面极性分类,从而为其提供端到端的分类方法,而无需任何特征工程工作。然而,当句子中有多个目标时,方面极性分类任务需要区分不同方面的情绪。因此,与文档级情感分析中只有一个整体情感取向相比,方面极性分类任务更加复杂,面临更多挑战,主要体现在以下两个方面:首先,与文档级情感分析相比,方面极性分类任务需要更多的语义特征才能进行更精细的情感分析。为了实现这一目标,目前针对方面极性分类的深度学习方法提出了多种以方面为中心的情感语义学习方法,例如:基于注意力的语义学习、位置衰减、左右语义学习、方面连接与全局语义学习等,但每种方法都存在一些不足,需要进行多种语义的综合才能达到较好的效果。另一方面,方面极性分类的深度学习方法是完全监督的机器学习,需要足够数量的标记数据来训练准确的分类器。然而,基于实体目标的精细情感极性标记是一项复杂且耗时的任务,因而方面极性分类的语料库通常较小。因此,如何在小语料库上训练出稳定有效的模型是方面极性分类的深度学习方法面临的一大挑战。为了解决上述问题,本发明充分利用bert 语言模型广泛的预训练和后训练,有效解决方面级情感分析中语料数量小的问题;同时,梳理和改进当前方面极性分类的各种语义学习模型,并将它们与bert语言模型相结合,提出了一种新的基于bert与多语义学习的方面级情感分析方法。
技术实现要素:
4.本发明公开了一种基于bert神经网络与多语义学习的方面级情感分析方法,以bert神经网络为基础,提出了一种由多个语义学习模块组成、具有方面感知增强的方面级情感分析模型,产生强大的情感语义表征,以更有效的方法解决方面级情感分析问题。
5.为实现上述目的,本发明的技术方案为:
6.一种基于bert神经网络与多语义学习的方面级情感分析方法,其特征在于包括以下步骤:
7.s1.将待评测的评语句子分为左序列、右序列、全局序列和方面目标序列,并将左序列、右序列和全局序列分别输入到一个参数共享的bert神经网络模型中进行处理,得到相应的左语义、右语义和全局语义的隐藏表示,以及将方面目标序列输入到一个参数独立的 bert模型中进行处理,得到方面目标语义的隐藏表示;
8.s2.对方面目标语义的隐藏表示进行平均池化处理,得到平均方面语义向量,并将平均方面语义向量与左语义、右语义和全局语义中的每一个隐藏状态相连接,并分别在左语义、右语义和全局语义上通过线性变换和多头注意力合并处理,得到方面感知增强的左语义、右语义和全局语义表示;
9.s3.使用基于线性变换和多头注意力的二级语义融合,将方面感知增强的左语义、右语义和全局语义进行合并,得到最终的综合语义表示;
10.s4.对综合语义表示进行平均池化,得到评语句子的最终情感表示,并将评语的最终情感表示通过线性变换计算评语在所有情感极性上的预测得分和概率,根据概率的高低确定评语句子关于指定方面目标的情感极性;
11.所述bert神经网络是指google ai language提出的bidirectional encoderrepresentations from transformers(bert)语言模型。
12.进一步的,所述步骤s1具体包括:
13.s1.1以方面目标词为中心将待评测的评语句子分为左序列、右序列、全局序列和方面目标序列,并以bert的分类符[cls]作为开始符号、以bert的分离符[sep]作为分隔符和结束符形成输入表示;
[0014]
其中,全局序列sg的结构为:“[cls]+评语句子+[sep]+方面目标词+[sep]”,且dw为bert神经网络模型中字词编码的维度,n为全局序列的字词长度,所述“字词”是指文本经bert的分词器tokenzier分离出的语言片段;左序列s
l
为位于方面目标词左侧且包含方面目标词在内的评语字词子序列,并且根据全局序列的长度,在右侧补充多个结束符[sep],使得左序列的字词长度与全局序列的字词长度相等,即右序列sr为位于方面目标词右侧且包含方面目标词在内的评语字词子序列,并且根据评语句子的字词长度,在左侧补充多个分类符[cls],使得右序列的字词长度与评语句子的字词长度相等,然后再根据全局序列的长度,在右侧补充多个结束符[sep],使得右序列的字词长度与全局序列的字词长度相等,即方面目标序列s
t
的结构为:“[cls]+方面目标词+[sep]”,且m为方面目标序列的字词长度;
[0015]
s1.2将左序列s
l
、右序列sr、全局序列sg分别输入到一个参数共享的bert模型进行学习和编码,得到左语义、右语义和全局语义的隐藏表示h
l
、hr和hg,计算过程如下:
[0016][0017][0018][0019]
其中,sharedbert(
·
)表示一个参数共享的bert模型,d是bert模型中隐藏单元的数量;
[0020]
s1.3将方面目标序列s
t
输入到一个参数独立的bert模型进行学习和编码,得到方面目标的隐藏表示h
t
,计算过程如下;
[0021][0022]
其中,indiebert(
·
)表示一个参数独立的bert模型。
[0023]
进一步的,所述步骤s2具体包括:
[0024]
s2.1对方面目标语义的隐藏表示h
t
使用平均池化操作,生成平均方面语义向量计算过程如下:
[0025][0026]
其中,avepooling(
·
)表示平均池化操作,表示中的第i个元素,计算过程如下:
[0027][0028]
其中,average(
·
)表示求平均值的函数,表示中第i行、第j列的元素;
[0029]
s2.2计算方面感知增强的全局语义表示过程如下:
[0030]
(1)将平均方面语义向量与全局语义的隐藏表示hg中的每一个隐藏状态相连接,得到与方面目标相连的全局语义表示h
gt
,计算过程如下:
[0031][0032]
其中,[x1:x2]表示矩阵按行拼接,是一个有着n个1的向量,是一个将重复n次的线性变换,[;]表示连接操作;
[0033]
(2)通过一个线性变换层,将与方面目标相连的全局语义表示h
gt
进行浓缩,得到与方面目标相融的全局语义表示计算过程如下:
[0034][0035]
其中,是线性变换层中的权重矩阵,是线性变换层中的偏置向量;
[0036]
(3)使用一个多头注意力共同关注中不同位置的信息,得到方面感知增强的全局语义表示计算过程如下:
[0037][0038]
其中,表示输入的多头注意力mha(q,k,v),多头注意力mha(q,k,v)的计算过程如下:
[0039]
mha(q,k,v)=tanh([head1;head2;...;headh]wr)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(10)
[0040]
headi=attention(qi,ki,vi)=attention(qwq,kwk,vwv)
ꢀꢀꢀꢀꢀꢀꢀꢀ
(11)
[0041][0042]
其中,是多头注意力的三个输入,headi表示多头注意力中的第i个头, tanh(
·
)表示双曲正切函数,是可学习的参数矩阵dk=dv=d
÷
h,h是多头注意力中头的数量,上标t表示矩阵的转置操作;
[0043]
s2.3分别使用h
l
和hr代替hg,重复步骤s2.2中的(1)、(2)、(3)步,得到方面感知增强的左语义表示和方面感知增强的左语义表示
[0044]
更进一步的,所述步骤s3具体包括:
[0045]
s3.1组合左语义和右语义得到合并的局部语义计算过程如下:
[0046][0047][0048][0049]
其中,公式(13)表示将和按行列拼接,公式(14)表示一个线性变换层的计算过程,公式(15)表示输入的多头注意力mha(q,k,v)的调用,是线性变换层中的权重矩阵,是线性变换层中的偏置向量,h
lrt
是左语义和右语义的连接表示,是将h
lrt
通过线性就换后的浓缩表示;
[0050]
s3.2组合合并的局部语义和全局语义得到最终的综合语义表示计算过程如下:
[0051][0052][0053][0054]
其中,公式(16)表示将和按行拼接,公式(17)表示一个线性变换层的计算过程,公式(18)表示输入的多头注意力mha(q,k,v)的调用,是线性变换层中的权重矩阵,是线性变换层中的偏置向量,h
lrgt
是合并的局部语义
和全局语义的连接表示,是将h
lrgt
通过线性就换后的浓缩表示。
[0055]
更进一步的,所述步骤s4具体包括:
[0056]
s4.1对综合语义表示执行一个平均池化操作,得到评语句子的最终情感表示z,计算过程如下:
[0057][0058]
其中,zi表示z中的第i个元素,计算过程如下:
[0059][0060]
其中,表示中第i行、第j列的元素;
[0061]
s4.2评语句子的最终情感表示z被输入到一个执行softmax(
·
)的线性变换层,进行情感极性的概率计算,并得出最终的情感极性,计算过程如下:
[0062]
o=mz
t
+b
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(21)
[0063][0064][0065]
其中,是情感极性的表示矩阵,z
t
表示对z进行转置,是一个偏置向量,dk是情感极性类别的个数,y是情感极性类别的集合,y是一个情感极性,是表示所有情感极性置信分数的向量,p(y|z,θ)表示给定评语句子的最终情感表示z在情感极性y上的预测概率,y
*
为最终评定的情感极性,表示返回使得 p(y|z,θ)为最大值的情感极性,θ是所有可学习的参数集合,exp(
·
)表示以e为底的指数函数。
[0066]
进一步的,所述bert神经网络的损失函数采用如下的交叉熵损失误差:
[0067][0068]
其中,ω是方面级情感分类任务的训练句子的集合,|ω|表示集合ω的大小,yi是ω中第i个训练句子的情感极性标签,zi是ω中第i个训练句子的情感表示。
[0069]
训练目标是按公式(24)最小化ω中所有训练句子的交叉熵损失误差。
[0070]
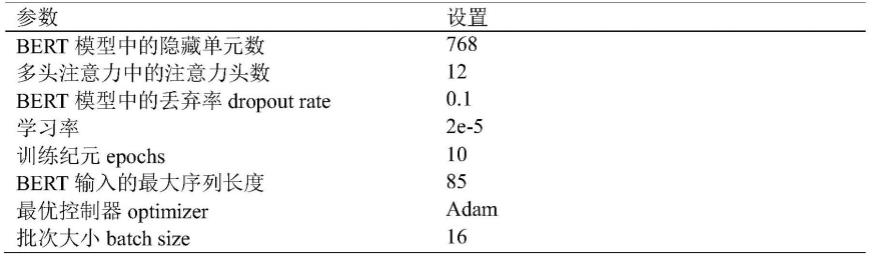
本发明具有以下优点:
[0071]
(1)充分利用bert模型广泛的预训练和后训练,为模型获取知识丰富的初始化参数,使模型只需在一个小的语料库上微调即可快速适应absa任务;
[0072]
(2)提出了一个基于bert的多语义学习框架,包括左语义学习、右语义学习、全局语义学习和方面目标语义学习,为生成强大的情感语义表征创造了条件;
[0073]
(3)提出了一种基于bert和多头注意力机制的方面感知增强方法,解决了捕获每个上下文词和方面目标之间语义依赖性的问题;
[0074]
(4)模型遵循bert中的transformer结构,使用轻量级的多头自注意力和线性变换
层进行编码,使模型更容易训练和成型。
附图说明
[0075]
图1是本发明的方法流程示意图。
[0076]
图2是本发明的语义融合模块结构示意图。
[0077]
图3是具体实施例给出的一个全局序列示意图。
[0078]
图4是具体实施例给出的一个左序列和一个右序列示意图。
[0079]
图5是具体实施例给出的一个方面目标序列示意图。
具体实施方式
[0080]
以下结合具体实施例对本发明作进一步说明,但本发明的保护范围不限于以下实施例。
[0081]
对于评语句子s和s中的方面目标a,按照图1所示的本发明方法流程图,通过以下步骤分析s关于方面目标a的情感:
[0082]
s1.将待评测的评语句子分为左序列、右序列、全局序列和方面目标序列,并将左序列、右序列和全局序列分别输入到一个参数共享的bert神经网络模型中进行处理,得到相应的左语义、右语义和全局语义的隐藏表示,以及将方面目标序列输入到一个参数独立的bert模型中进行处理,得到方面目标语义的隐藏表示;
[0083]
s2.对方面目标语义的隐藏表示进行平均池化处理,得到平均方面语义向量,并将平均方面语义向量与左语义、右语义和全局语义中的每一个隐藏状态相连接,并分别在左语义、右语义和全局语义上通过线性变换和多头注意力合并处理,得到方面感知增强的左语义、右语义和全局语义表示;
[0084]
s3.使用基于线性变换和多头注意力的二级语义融合,每个语义融合模块结构如图2所示,将方面感知增强的左语义、右语义和全局语义进行合并,得到最终的综合语义表示;
[0085]
s4.对综合语义表示进行平均池化,得到评语句子的最终情感表示,并将评语的最终情感表示通过线性变换计算评语在所有情感极性上的预测得分和概率,根据概率的高低确定评语句子关于指定方面目标的情感极性;
[0086]
所述bert神经网络是指googleailanguage提出的bidirectionalencoderrepresentationsfromtransformers(bert)语言模型。
[0087]
进一步的,所述步骤s1具体包括:
[0088]
s1.1以方面目标词为中心将待评测的评语句子分为左序列、右序列、全局序列和方面目标序列,并以bert的分类符[cls]作为开始符号、以bert的分离符[sep]作为分隔符和结束符形成输入表示;
[0089]
其中,全局序列sg的结构为:“[cls]+评语句子+[sep]+方面目标词+[sep]”,且dw为bert神经网络模型中字词编码的维度,n为全局序列的字词长度,所述“字词”是指文本经bert的分词器tokenzier分离出的语言片段;左序列s
l
为位于方面目标词左侧且包含方面目标词在内的评语字词子序列,并且根据全局序列的长度,在右侧补充多个结束符[sep],使得左序列的字词长度与全局序列的字词长度相等,即右序列sr为位于方面目标词右侧且包含方面目标词在内的评语字词子序列,并且根据评语句子的字词长度,在左侧补充多个分类符[cls],使得右序列的字词长度与评语句子的字词长度相等,然后再根据全局序列的长度,在右侧补充多个结束符[sep],使得右序列的字词长度与全局序列的字词长度相等,即方面目标序列s
t
的结构为:“[cls]+方面目标词+[sep]”,且m为方面目标序列的字词长度;
[0090]
s1.2将左序列s
l
、右序列sr、全局序列sg分别输入到一个参数共享的bert模型进行学习和编码,得到左语义、右语义和全局语义的隐藏表示h
l
、hr和hg,计算过程如下:
[0091][0092][0093][0094]
其中,sharedbert(
·
)表示一个参数共享的bert模型,d是bert模型中隐藏单元的数量;
[0095]
s1.3将方面目标序列s
t
输入到一个参数独立的bert模型进行学习和编码,得到方面目标的隐藏表示h
t
,计算过程如下;
[0096][0097]
其中,indiebert(
·
)表示一个参数独立的bert模型。
[0098]
进一步的,所述步骤s2具体包括:
[0099]
s2.1对方面目标语义的隐藏表示h
t
使用平均池化操作,生成平均方面语义向量计算过程如下:
[0100][0101]
其中,avepooling(
·
)表示平均池化操作,表示中的第i个元素,计算过程如下:
[0102][0103]
其中,average(
·
)表示求平均值的函数,表示中第i行、第j列的元素;
[0104]
s2.2计算方面感知增强的全局语义表示过程如下:
[0105]
(1)将平均方面语义向量与全局语义的隐藏表示hg中的每一个隐藏状态相连接,得到与方面目标相连的全局语义表示h
gt
,计算过程如下:
[0106][0107]
其中,[x1:x2]表示矩阵按行拼接,是一个有着n个1的向量,是一个将重复n次的线性变换,[;]表示连接操作;
[0108]
(2)通过一个线性变换层,将与方面目标相连的全局语义表示h
gt
进行浓缩,得到与
方面目标相融的全局语义表示计算过程如下:
[0109][0110]
其中,是线性变换层中的权重矩阵,是线性变换层中的偏置向量;
[0111]
(3)使用一个多头注意力共同关注中不同位置的信息,得到方面感知增强的全局语义表示计算过程如下:
[0112][0113]
其中,表示输入的多头注意力mha(q,k,v),多头注意力mha(q,k,v)的计算过程如下:
[0114]
mha(q,k,v)=tanh([head1;head2;...;headh]wr)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(10)
[0115]
headi=attention(qi,ki,vi)=attention(qwq,kwk,vwv)
ꢀꢀꢀꢀꢀꢀꢀ
(11)
[0116][0117]
其中,是多头注意力的三个输入,headi表示多头注意力中的第i个头, tanh(
·
)表示双曲正切函数,是可学习的参数矩阵dk=dv=d
÷
h,h是多头注意力中头的数量,上标t表示矩阵的转置操作;
[0118]
s2.3分别使用h
l
和hr代替hg,重复步骤s2.2中的(1)、(2)、(3)步,得到方面感知增强的左语义表示和方面感知增强的左语义表示
[0119]
更进一步的,所述步骤s3具体包括:
[0120]
s3.1组合左语义和右语义得到合并的局部语义计算过程如下:
[0121][0122][0123][0124]
其中,公式(13)表示将和按行列拼接,公式(14)表示一个线性变换层的计算过程,公式(15)表示输入的多头注意力mha(q,k,v)的调用,是线性变换层中的权重矩阵,是线性变换层中的偏置向量,h
lrt
是左语义和右语义的连接表示,是将h
lrt
通过线性就换后的浓缩表示;
[0125]
s3.2组合合并的局部语义和全局语义得到最终的综合语义表示计算过程如下:
[0126]
[0127][0128][0129]
其中,公式(16)表示将和按行拼接,公式(17)表示一个线性变换层的计算过程,公式(18)表示输入的多头注意力mha(q,k,v)的调用,是线性变换层中的权重矩阵,是线性变换层中的偏置向量,h
lrgt
是合并的局部语义和全局语义的连接表示,是将h
lrgt
通过线性就换后的浓缩表示。
[0130]
更进一步的,所述步骤s4具体包括:
[0131]
s4.1对综合语义表示执行一个平均池化操作,得到评语句子的最终情感表示z,计算过程如下:
[0132][0133]
其中,zi表示z中的第i个元素,计算过程如下:
[0134][0135]
其中,表示中第i行、第j列的元素;
[0136]
s4.2评语句子的最终情感表示z被输入到一个执行softmax(
·
)的线性变换层,进行情感极性的概率计算,并得出最终的情感极性,计算过程如下:
[0137]
o=mz
t
+b
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(21)
[0138][0139][0140]
其中,是情感极性的表示矩阵,z
t
表示对z进行转置,是一个偏置向量,dk是情感极性类别的个数,y是情感极性类别的集合,y是一个情感极性,是表示所有情感极性置信分数的向量,p(y|z,θ)表示给定评语句子的最终情感表示z在情感极性y上的预测概率,y
*
为最终评定的情感极性,表示返回使得 p(y|z,θ)为最大值的情感极性,θ是所有可学习的参数集合,exp(
·
)表示以e为底的指数函数。
[0141]
进一步的,所述bert神经网络的损失函数采用如下的交叉熵损失误差:
[0142][0143]
其中,ω是方面级情感分类任务的训练句子的集合,|ω|表示集合ω的大小,yi是ω中第i个训练句子的情感极性标签,zi是ω中第i个训练句子的情感表示。
[0144]
训练目标是按公式(24)最小化ω中所有训练句子的交叉熵损失误差。
[0145]
应用实例
[0146]
1.实例环境
[0147]
本实例采用结合广泛预训练和后训练的bert-pt模型。bert-pt模型由文献“xuh,liub,shul,philipsy,(2019)bertpost-trainingforreviewreadingcomprehensionandaspect-basedsentimentanalysis.inproceedingsnaaclhlt2019,pp2324-2335”所提出,实例的超参数如表1所示。
[0148]
表1实例的超参数
[0149][0150]
2.数据集
[0151]
本实例在四个基准数据集上评估本发明的模型,这四个数据集取自国际语义评估研讨会的三个连续任务,包括semeval-2014任务4中的14lap和14rest、semeval2015任务12中的15rest和semeval2016任务5中的16rest,如表2所示。
[0152]
表2评测数据集
[0153][0154]
3.对比方法
[0155]
本实例将本发明的模型与8种方面级别情感分类方法进行比较,包括4种非bert的方法和4种基于bert的方法,如下所示:
[0156]
(1)非bert的方法
[0157]
·
mennet[1]使用多层记忆网络结合注意力来捕获每个上下文词对方面极性分类的重要性
[0158]
·
ian[2]使用两个lstm网络分别提取特定方面和上下文的特征,然后交互生成它们的注意力向量,最后将这两个注意力向量连接起来进行方面极性分类
[0159]
·
tnet-lf[3]采用cnn层从基于双向lstm层的转换的单词表示中提取显着特征,并提出基于相关性的组件来生成句子中单词的特定目标表示,该模型还采用了位置衰减技术
[0160]
·
mcrf-sa[4]提出了一种基于多个crf的简洁有效的结构化注意力模型,该模型可以提取特定于方面的意见跨度,该模型还采用了位置衰减和方面连接技术
[0161]
(2)基于bert的方法
[0162]
·
bert-base[5]是googleai语言实验室开发的bert-base版本,它使用单句输入方式:“[cls]+评语句子+[sep]”进行方面极性分类
[0163]
·
aen-bert[6]采用基于bert的多头注意力来建模上下文和方面目标
[0164]
·
bert-spc[6]采用句子对分类(spc)的输入结构:“[cls]+评语句子+[sep]+方面目标t+[sep]”。
[0165]
·
lcf-apc[7]提出了一种基于bert的位置衰减和动态掩码的局部上下文聚焦(lcf)机制,并将局部上下文特征与基于bert-spc的全局上下文特征相结合,用于方面极性分类
[0166]
参考文献:
[0167]
[1]tangd,qinb,liut(2016)aspectlevelsentimentclassificationwithdeepmemorynetwork.in:empiricalmethodsinnaturallanguageprocessing,pp214
–
224
[0168]
[2]mad,lis,zhangx,wangh(2017)interactiveattentionsnetworksforaspect-levelsentimentclassification.in:proceedingsofthe26thinternationaljointconferenceonartificialintelligence,melbourne,australia,19-25august2017,pp4068-4074
[0169]
[3]lix,bingl,lamw,shib(2018)transformationnetworksfortarget-orientedsentimentclassification.inproceedingsofacl,pp946-956
[0170]
[4]xul,bingl,luw,huangf(2020)aspectsentimentclassificationwithaspect-specificopinionspans.inproceedingsofemnlp2020,pp3561-3567
[0171]
[5]devlinj,changmw,leek,toutanovak(2019)bert:pre-trainingofdeepbidirectionaltransformersforlanguageunderstanding.in:proceedingsofthe2019conferenceofnaacl,pp4171
–
4186
[0172]
[6]songy,wangj,jiangt,liuz,raoy(2019)attentionalencodernetworkfortargetedsentimentclassification.in:arxivpreprintarxiv:1902.09314
[0173]
[7]yangh,zengb,yangj,songy,xur(2021)amulti-tasklearningmodelforchinese-orientedaspectpolarityclassificationandaspecttermextraction.neurocomputing,419:344-356
[0174]
4.实例对比结果
[0175]
表3实例对比结果
[0176][0177]
[0178]
表3的结果表明,本实例所实现的本发明提出的模型在准确率与m-f1值两方面显著优于各种非bert的方面级情感分类方法和基于bert的方面级情感分类方法,这充分证明了本发明所提出的基于bert与多语义学习的方面级情感分析方法是可行与优秀的。
[0179]
5.示例
[0180]
对于评语句子:"prices are higher to dine in and their chicken tikka marsala is quite good",该评语关于方面目标"chicken tikka marsala"的全局序列如图3所示,左序列、右序列如图4 所示,方面目标序列如图5所示,经本实例模型分析后得到方面目标"chicken tikka marsala" 的情感极性为“正面”。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1