基于多角度语义理解与自适应双通道的视觉问答方法
1.本发明属于计算机视觉和自然语言处理领域结合的跨模态任务技术领域,具体涉及一种基于多角度语义理解与自适应双通道的视觉问答方法。
背景技术:
2.视觉问答技术是一项需要同时理解视觉内容、语义信息及跨模态关系的课题。过去已有大量的工作在单一的机器视觉或自然语言处理领域中开发了各自的主干模型,并具有深远的意义。在结合机器视觉与自然语言处理两个领域后,作为跨模态领域分支之一的视觉问答技术对视觉导航和远程监控等广泛应用具有巨大的潜在影响。
3.目前,各类图像算法应用到视觉问答领域中已体现出优异的性能,其中主流的方法大致分为两类:基于多模态融合的算法和基于注意力机制的算法。多模态融合算法是基于cnn-rnn结构,将视觉特征和文本特征融合至统一的表示中用于预测答案。注意力机制算法的出现是为区分出图像中与问题相关的有效信息,解决视觉与语言的交互问题。然而,多模态融合与注意力机制的方法并不能有效的结合文本信息与图像信息;并且现有视觉问答模型无法关注图片的对象关系信息同时缺乏对高层次语义信息的获取能力,视觉问答任务面临着回答不同类型的问题及如何从图片中提取有效语义信息的挑战。模型应该更注重图片的对象关系信息同时也能够根据问题从字幕中前向匹配到相应的答案,并且模型应该更注重图片的高层次语义的信息,能够根据字幕匹配答案时具有较强的健壮性。
技术实现要素:
4.本发明的目的是克服上述背景技术的不足,提供一种基于多角度语义理解与自适应双通道的视觉问答方法,该方法能够使得训练出来的模型更具有鲁棒性;面对更复杂的视觉场景也具有较强的泛化能力;以提升答案的语义性同时提升视觉问答模型的准确率。
5.本发明采用的技术方案是,基于多角度语义理解与自适应双通道的视觉问答方法,包括以下步骤:
6.步骤1;对输入的图像进行预处理,通过使用对象检测模块提取输入图像中显著区域的视觉特征与几何特征;
7.步骤2;对于问题文本的嵌入,使用空格与标点符号的方法将句子分割成单词(数字或基于数字的单词也被当做是一个单词);接下来采用预训练的词向量模型将单词执行向量化表示;最后将词向量表示通过长短时记忆网络,获取最后一个时间步上的状态,得到问题特征;
8.步骤3;对于图像字幕与密集字幕文本的嵌入,同样利用空格与标点符号将句子分割成单词;然后将得到的多个字幕特征级联,转化为文本段落的形式;最后使用长短时记忆网络编码文本段落,最后一层的输出则为编码后的词向量序列;
9.步骤4;对步骤1与步骤2得到的视觉特征与问题特征使用注意力机制,获取与问题相关的注意力特征;将步骤1与步骤2得到的视觉特征、几何特征与问题特征通过关系推理
模块,输出关系特征;最后将注意力特征与关系特征融合产生视觉特征表示;
10.步骤5;将步骤2与步骤3得到的词向量序列与问题特征输入至多角度语义模块,来产生多角度语义特征;
11.步骤6;将步骤4与步骤5产生的视觉特征与多角度语义特征送入视觉语义选择门,通过特征融合的方式控制视觉通道与语义通道对预测答案的贡献;答案的预测将通过多分类器选出概率最高的答案作为最终答案。
12.本发明的特征还在于:
13.所述的步骤1中,使用对象检测模块具体是指:采用faster r-cnn模型来获得对象检测框,并选择最相关的k个检测框(一般为k=36)作为重要视觉区域;对于每个选定的区域i,vi是一个d维的视觉对象向量,则输入的图像最终表示为v={v1,v2,
…
,vk}
t
,此外,还记录输入图像的几何特征,记为b={b1,b2,
…
,bk}
t
,其中(xi,yi),wi,hi分别表示选定区域i的中心坐标、宽度与高度;w,h分别表示输入图像的宽度与高度。
14.步骤2具体按照以下步骤实施:
15.首先将每个输入问题q修剪到最多14个单词,简单丢弃超过14个单词的额外单词,同时不足14个单词的问题用0向量填补;然后将包含14个单词的问题转变为glove词向量,由此产生的单词嵌入序列大小为14
×
300,并将其依次通过隐藏层为dq维的长短时记忆网络(lstm);最后使用的最终隐藏状态为输入问题q的问题嵌入表示。
16.所述的步骤3中的文本嵌入实施步骤,除不包括将图像字幕与密集字幕级联外,其余均与步骤2的文本嵌入步骤相同。
17.所述步骤4)中的注意力机制具体是指:引入自上向下的注意机制并用软注意力方法作为注意力模块引入到网络结构中突出与问题相关的视觉对象,输出注意力特征;其中所有视觉区域及相应的注意力特征的加权求和表示为:
[0018]vat
=a
t
·v[0019]
其中a=[ω1,ω2,
…
,ωk]
t
是注意力的映射矩阵。
[0020]
所述的步骤4)中的关系推理模块具体是指:通过双卷积流的方式实现编码图像区域之间的关系,并生成两种不同类型的关系特征分别为二元关系特征与多元关系特征。关系推理模块由三部分组成:特征融合,二元关系推理,多元关系推理。特征融合模块负责将视觉特征、几何特征与问题特征通过升维与降维的方式融合产生视觉区域特征的成对组合;二元关系推理模块负责挖掘视觉区域间的成对视觉关系通过三个连续的1
×
1卷积层的方式生成二元关系特征;多元关系推理模块则负责挖掘视觉区域间的组内视觉关系通过三个连续的3
×
3空洞卷积层的方式生成多元关系特征。最后将二元关系特征与多元关系特征组合得到关系特征。
[0021]
所述特征融合的步骤是:首先本发明将图像k个视觉区域的对象特征与几何特征,将二者级联生成视觉区域特征v
co
=concat[v,b];其次将视觉区域特征v
co
与问题特征映射到低维的子空间中:
[0022][0023]
其中wv与wq是学习参数,bq与bv是偏置。其中ds是子空间的维度。
[0024]
将视觉区域成对组合,扩展视觉区域特征的维度,并将其与转置的相加,得到视觉区域特征的成对组合v
fu
。
[0025]
所述二元关系推理的步骤是:采用三个连续的1
×
1卷积层,并且在每层卷积层后采用relu激活层。这三个1
×
1卷积层的通道数分别为ds,以及将视觉区域组合特征v
fu
输入到二元关系推理模块中,则在最后一层的输出为再将与其转置相加获得对称矩阵,最后通过softmax生成二元关系r
p
,具体公式如下:
[0026][0027]
所述多元关系推理的步骤是:采用三个连续的3
×
3的空洞卷积层,并且在每层卷积层后采用relu激活层。三个空洞卷积层的空洞分别是1,2和4。所有卷积的步长均为1,并且为使每次卷积的输出与输入的尺寸相同采用零边缘填充;将视觉区域成对组合v
fu
输入到多元关系推理模块中,在最后一个卷积层与relu激活层的输出是与二元关系推理同理,将与其转置相加得到一个对称矩阵,最后经过softmax生成多元关系rg,公式如下:
[0028][0029]
步骤4的具体实施步骤如下:
[0030]
首先,按照多模态融合:
[0031][0032]
其中1∈rd是元素均为1的向量,而表示逐元素相乘。
[0033]
其次,对所有图像区域采用相同的映射矩阵和
[0034][0035]
其中p∈rd是学习参数;为获取注意力映射矩阵,对于图像区域i的注意力权重ωi如下式:
[0036][0037]
因此所有视觉区域及相应的注意力特征的加权求和表示为:
[0038]vat
=a
t
·v[0039]
其中a=[ω1,ω2,
…
,ωk]
t
是注意力的映射矩阵。
[0040]
所述步骤5)中的多角度语义模块是将问题特征与字幕特征关联;具体方法是:首
先利用余弦相似度的方法遍历计算字幕ti与问题qj的相关性,选取与问题qj最相关的文本特征;其次将权重系数ri与字幕特征ti相结合,使与问题更相关的语义信息得到更多的关注,即其中表示权重字幕特征;然后采用双向lstm(bilstm)编码字幕的每个单词,同时也采用bilstm编码问题的每个单词;最后采用完全融合、平均池化融合、注意力融合及最大注意力融合四种方法提升模型理解语义信息的泛化能力。
[0041]
步骤5具体按以下步骤实施:
[0042]
步骤5.1:将问题特征与字幕特征关联,首先利用余弦相似度的方法遍历计算字幕ti与问题qj的相关性,选取与问题qj最相关的文本特征;其次将权重系数ri与字幕特征ti相结合,使与问题更相关的语义信息得到更多的关注,即其中表示权重字幕特征。然后采用双向lstm或bilstm编码字幕的每个单词,同时也采用bilstm编码问题的每个单词;最后采用了完全融合、平均池化融合、注意力融合及最大注意力融合四种方法提升模型理解语义信息的泛化能力;
[0043]
步骤5.2:采用双向lstm或bilstm编码字幕的每个单词,同时也采用bilstm编码问题的每个单词:
[0044][0045][0046][0047][0048]
其中分别表示字幕的正向与反向lstm在第i个时间步上的隐藏状态。分别表示问题的正向与反向lstm在第j个时间步上的隐藏状态;
[0049]
步骤5.3:分别采用完全融合、平均池化融合、注意力融合及最大注意力融合四种融合策略以捕捉高级语义信息。
[0050]
所述完全融合,是将字幕段落的每个前向和反向词向量分别与整个问题的前向和反向的最终状态传入f函数中进行融合,具体公式如下:
[0051][0052][0053]
其中为l维的向量,分别表示第i个字幕词向量的前向及反向的完全融合特征;
[0054]
所述平均池化融合,将字幕段落的前向(或反向)词向量特征与每个时间步上的前向(或反向)问题特征传入f函数中进行融合,再执行平均池化操作,具体公式如下:
[0055][0056][0057]
其中为l维的向量,分别表示第i个字幕词向量的前向及反向的平均池化融合特征;
[0058]
所述注意力融合,首先通过余弦相似度函数计算字幕上下文嵌入与问题上下文嵌入间的相似程度系数,再将相似程度系数视为权重,与问题的每个前向(或反向)词向量嵌入相乘并求均值,具体公式如下:
[0059][0060][0061][0062][0063]
其中分别表示前向与反向的相似程度系数,分别对应第i个字幕词向量前向与反向的注意力向量,表示问题整体与该词的相关性。
[0064]
最后,将注意力向量与字幕上下文嵌入传入f函数中进行融合,得到第i个字幕词向量的前向及反向的注意力融合特征,上述过程如下式:
[0065][0066][0067]
所述最大注意力融合,直接将具有最大相似程度系数的问题嵌入作为注意力向量,最后再将注意力向量与字幕嵌入传入f函数中进行融合;具体公式如下:
[0068][0069][0070]
[0071][0072]
所述步骤5)的四种融合策略,将生成的8个特征向量级联获得的第i个字幕的综合融合特征,记为
[0073]
将综合融合特征输入到双向lstm(bilstm)中,并获取两个方向上的最终隐藏状态,公式如下所示:
[0074][0075][0076]
其次,将首尾两处的最终隐藏状态级联生成多角度语义特征其次,将首尾两处的最终隐藏状态级联生成多角度语义特征最后,为便于多模态特征融合,将多角度语义特征映射至与视觉表示相同的维度,公式如下:
[0077][0078]
其中为可学习的权重矩阵,bs为偏置。
[0079]
本发明具有的有益效果是:
[0080]
1.本发明基于多角度语义理解与自适应双通道模型,它可以同时捕捉图像的视觉线索与语义线索,并在后期融合阶段加入门控以自适应的选择视觉信息与语义信息来回答问题,使得训练出来的模型更具有鲁棒性。
[0081]
2.本发明在视觉通道采用视觉关系推理模块,其中包括二元关系推理与多元关系推理,加强模型对视觉内容的理解能力,面对更复杂的视觉场景也具有较强的泛化能力。
[0082]
3.本发明在语义通道中采用多角度语义模块生成语义特征,其中多角度语义模块包括完全融合、平均池化融合、注意力融合及最大注意力融合方法,以提升答案的语义性同时提升视觉问答模型的准确率。
附图说明
[0083]
图1为本发明所述方法的网络模型结构图。
[0084]
图2为本发明所述方法中的关系推理模块的示意图。
[0085]
图3为本发明所述方法中的多角度语义模块的示意图。
具体实施方式
[0086]
下面结合附图所示的实施例(以孩子的衣着为题)对本发明作进一步说明。
[0087]
本发明基于多角度语义理解与自适应双通道的视觉问答方法,包括以下步骤:
[0088]
步骤1:对输入的图像进行预处理,通过使用对象检测模块提取输入图像中显著区域的视觉特征与几何特征。使用预训练resnet-101提取网格特征,配合faster-rcnn模型探索对象区域并提取2048维的目标区域特征,并选择最相关的k个检测框(一般为k=36)作为重要视觉区域。对于每个选定的区域i,vi是一个d维的视觉对象向量,则输入的图像最终表
示为v={v1,v2,
…
,vk}
t
,此外,还记录输入图像的几何特征,记为b={b1,b2,
…
,bk}
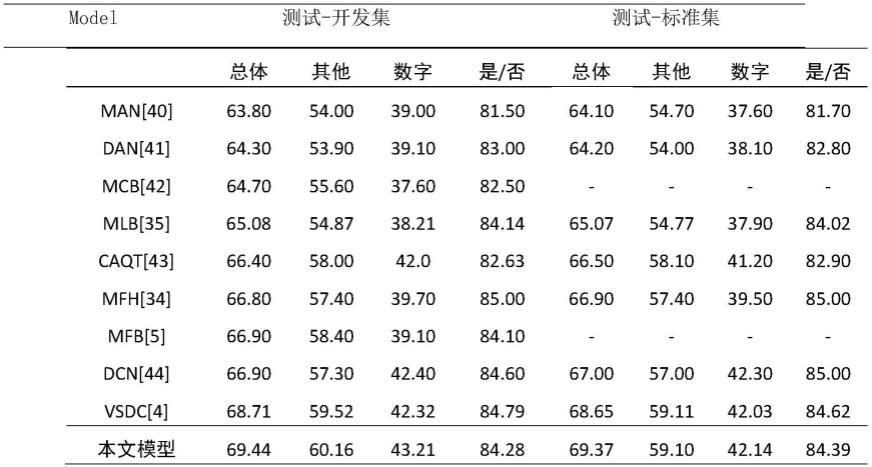
t
,其中其中(xi,yi),wi,hi分别表示选定区域i的中心坐标、宽度与高度。w,h分别表示输入图像的宽度与高度。
[0089]
步骤2:对于问题文本的嵌入,使用空格与标点符号的方法将句子分割成单词(数字或基于数字的单词也被当做是一个单词);接下来采用预训练的词向量模型将单词执行向量化表示;最后将词向量表示通过长短时记忆网络,获取最后一个时间步上的状态,得到问题特征;
[0090]
实施方法是:将每个输入问题q修剪到最多14个单词,简单丢弃超过14个单词的额外单词,同时不足14个单词的问题用0向量填补。然后将包含14个单词的问题转变为glove向量,由此产生的单词嵌入序列大小为14
×
300,并将其依次通过隐藏层为dq维的长短时记忆网络(lstm)。最后使用的最终隐藏状态为输入问题q的问题嵌入表示。
[0091]
步骤3:对于图像字幕与密集字幕文本的嵌入,同样利用空格与标点符号将句子分割成单词,句子长度同样设置为14;然后本发明采用前6个密集字幕(根据标题分布的平均值)作为文本输入,将得到的多个字幕特征级联,转化为文本段落的形式;最后使用长短时记忆网络编码文本段落,最后一层的输出则为编码后的词向量序列。
[0092]
步骤4;对步骤1与步骤2得到的视觉特征与问题特征使用注意力机制,获取与问题相关的注意力特征;将步骤1与步骤2得到的视觉特征、几何特征与问题特征通过关系推理模块,输出关系特征;最后将注意力特征与关系特征融合产生视觉特征表示;
[0093]
所述注意力机制具体是指:引入自上向下的注意机制并用软注意力方法作为注意力模块引入到网络结构中突出与问题相关的视觉对象,输出注意力特征;其中所有视觉区域及相应的注意力特征的加权求和表示为:
[0094]vat
=a
t
·v[0095]
其中a=[ω1,ω2,
…
,ωk]
t
是注意力的映射矩阵。
[0096]
所述关系推理模块由三部分组成:特征融合,二元关系推理,多元关系推理;(采用关系推理模块,这是本发明的一个创新点)。
[0097]
所述特征融合的步骤是:首先本发明将图像k个视觉区域的对象特征与几何特征,将二者级联生成视觉区域特征v
co
=concat[v,b]。其次将视觉区域特征v
co
与问题特征映射到低维的子空间中:
[0098][0099]
其中wv与wq是学习参数,bq与bv是偏置。其中ds是子空间的维度。
[0100]
为将视觉区域成对组合,扩展视觉区域特征的维度,并将其与转置的相加,得到视觉区域特征的成对组合v
fu
。
[0101]
所述二元关系推理的步骤是:采用三个连续的1
×
1卷积层,并且在每层卷积层后
采用relu激活层。这三个1
×
1卷积层的通道数分别为ds,以及将视觉区域组合特征v
fu
输入到二元关系推理模块中,则在最后一层的输出为再将与其转置相加获得对称矩阵,最后通过softmax生成二元关系r
p
,具体公式如下:
[0102][0103]
所述多元关系推理的步骤是:采用三个连续的3
×
3的空洞卷积层,并且在每层卷积层后采用relu激活层。三个空洞卷积层的空洞分别是1,2和4。所有卷积的步长均为1,并且为使每次卷积的输出与输入的尺寸相同采用零边缘填充。将视觉区域成对组合v
fu
输入到多元关系推理模块中,在最后一个卷积层与relu激活层的输出是与二元关系推理同理,将与其转置相加得到一个对称矩阵,最后经过softmax生成多元关系rg,公式如下:
[0104][0105]
所述步骤4的具体实施步骤如下:
[0106]
首先,按照最简单的双线性多模态融合为将wi替换为两个较小的矩阵h
igit
,其中以及
[0107][0108]
其中1∈rd是元素均为1的向量,而表示逐元素相乘;
[0109]
其次,对所有图像区域采用相同的映射矩阵和
[0110][0111]
其中p∈rd是学习参数;为获取注意力映射矩阵,对于图像区域i的注意力权重ωi如下式:
[0112][0113]
因此所有视觉区域及相应的注意力特征的加权求和表示为:
[0114]vat
=a
t
·v[0115]
其中a=[ω1,ω2,
…
,ωk]
t
是注意力的映射矩阵。
[0116]
步骤5的具体实施步骤如下:
[0117]
步骤5.1:将问题特征与字幕特征关联,首先利用余弦相似度的方法遍历计算字幕ti与问题qj的相关性,选取与问题qj最相关的文本特征。其次将权重系数ri与字幕特征ti相结合,使与问题更相关的语义信息得到更多的关注,即其中表示权重字幕特征。然后采用双向lstm(bilstm)编码字幕的每个单词,同时也采用bilstm编码问题的每个单词;最后采用了完全融合、平均池化融合、注意力融合及最大注意力融合四种方法提升模
型理解语义信息的泛化能力。
[0118]
步骤5.2:采用双向lstm(bilstm)编码字幕的每个单词,同时也采用bilstm编码问题的每个单词:
[0119][0120][0121][0122][0123]
其中分别表示字幕的正向与反向lstm在第i个时间步上的隐藏状态。分别表示问题的正向与反向lstm在第j个时间步上的隐藏状态。
[0124]
步骤5.3:本发明分别采用完全融合、平均池化融合、注意力融合及最大注意力融合四种融合策略以捕捉高级语义信息;(这是本发明的又一个创新点)。
[0125]
其中的完全融合策略,是将字幕段落的每个前向和反向词向量分别与整个问题的前向和反向的最终状态传入f函数中进行融合,具体公式如下:
[0126][0127][0128]
其中为l维的向量,分别表示第i个字幕词向量的前向及反向的完全融合特征。
[0129]
其中的平均池化融合策略,是将字幕段落的前向(或反向)词向量特征与每个时间步上的前向(或反向)问题特征传入f函数中进行融合,再执行平均池化操作,具体公式如下:
[0130][0131][0132]
其中为l维的向量,分别表示第i个字幕词向量的前向及反向的平均池化融合特征。
[0133]
其中的注意力融合策略,首先是通过余弦相似度函数计算字幕上下文嵌入与问题上下文嵌入间的相似程度系数,再将相似程度系数视为权重,与问题的每个前向(或反向)词向量嵌入相乘并求均值,具体公式如下:
[0134][0135][0136][0137][0138]
其中分别表示前向与反向的相似程度系数,分别对应第i个字幕词向量前向与反向的注意力向量,表示问题整体与该词的相关性。
[0139]
最后,将注意力向量与字幕上下文嵌入传入f函数中进行融合,得到第i个字幕词向量的前向及反向的注意力融合特征,上述过程如下式:
[0140][0141][0142]
其中的最大注意力融合策略,是直接将具有最大相似程度系数的问题嵌入作为注意力向量,最后再将注意力向量与字幕嵌入传入f函数中进行融合,具体公式如下:
[0143][0144][0145][0146][0147]
上述4种融合方法,将生成的8个特征向量级联获得第i个字幕的综合融合特征,记为将综合融合特征输入到双向lstm(bilstm)中,并获取两个方向上的最终隐藏状态,公式如下所示:
[0148][0149]
[0150]
其次,将首尾两处的最终隐藏状态级联生成多角度语义特征其次,将首尾两处的最终隐藏状态级联生成多角度语义特征最后,为便于多模态特征融合,将多角度语义特征映射至与视觉表示相同的维度,公式如下:
[0151][0152]
其中为可学习的权重矩阵,bs为偏置。
[0153]
步骤6:将步骤4与步骤5产生的视觉特征与多角度语义特征送入视觉语义选择门,通过特征融合的方式控制视觉通道与语义通道对预测答案的贡献。答案的预测将通过多分类器选出概率最高的答案作为最终答案。
[0154]
综上,本发明基于vqa 1.0与vqa 2.0数据集,在视觉通道利用r-cnn-lstm框架结合注意力机制与关系推理方法,采用faster r-cnn编码图像中的视觉特征向量与几何特征向量,将视觉特征向量与几何特征向量输入到视觉通道生成视觉模态表示;在语义通道采用lstm网络编码拼接后的全局标题与局部标题,经过多角度语义模块输出语义模态表示。最后将得到的视觉模态表示与语义模态表示输入到自适应选择门控以决定采用哪种模态的线索来预测答案。
[0155]
其中的创新点:一是在视觉通道采用关系推理模块,其中包括二元关系推理与多元关系推理,可加强模型对视觉内容的理解能力,面对更复杂的视觉场景也具有较强的泛化能力。二是在语义通道中采用多角度语义模块生成语义特征,其中多角度语义模块包括完全融合、平均池化融合、注意力融合及最大注意力融合方法,可在提升答案的语义性同时提升视觉问答模型的准确率。
[0156]
模拟实验及实验结果表征:
[0157]
1.数据集
[0158]
该模型在两个视觉问答公开的数据集上进行实验,分别为vqa 1.0与vqa 2.0数据集。vqa 1.0是基于mscoco图像数据集[38]建立的,数据集中的训练集包含248 349个问题与82 783张图片,验证集包含121 512个问题与40 504个图片,测试集则包含244 302个问题与81 434个图片。vqa 2.0是vqa 1.0的迭代版本,相比于vqa 1.0,它增加了更多的问题样本使语言偏见方面更加平衡。vqa 2.0数据集的训练集包含443 757个问题与82 783张图片,验证集包含214 354个问题与40 504个图片,测试集则包含447 793个问题与81 434个图片。问题共有三种类型:是/否,数字和其他。其中,其他类型的样本数量大约占总样本数的一半。本发明提出的模型在训练集与验证集上进行训练,为保证与其他工作进行公平的比较,在测试-开发集(test-dev)与测试-标准集(test-standard)上报告测试结果。
[0159]
2.实验环境
[0160]
本发明在pytorch库中实现了提出的模型,并在gup服务器上完成了测试实验。该服务器的配置为256g ram,同时拥有4块nvidia 1080ti gpu,共计显存64gb。本发明使用adam优化器对模型进行训练,最大迭代轮数为40,batch大小设置为256。采用学习率预热的方法,在第一个训练周期将学习率设置为1e-3,在第二个训练周期将学习率设置为2e-3,在第三个训练周期将学习率设置为3e-3,一直保持到第十个训练周期,之后学习率每两个周期衰减一次,衰减率为0.5。为防止梯度爆炸,本发明还采用了梯度修剪法,将每个周期的梯度值更新为原来的四分之一。为了防止过拟合,在每个全连接层之后采用dropout层,
dropout率为0.5。
[0161]
3.实验结果与分析
[0162][0163]
表1 vqa 1.0测试-开发集与测试-标准集中各模型的表现
[0164]
如表1所示,主要展示各类先进模型与本文模型的性能对比,表中所示结果均由模型在训练集与验证集中训练后获得。可以看出,在大多数指标上,本发明模型的性能明显优于其他模型,在测试-开发集与测试-标准集中的总体准确率分别达到了69.44%与69.37%。在测试-开发集中,相比于采用记忆增强神经网络的man模型,在总体精度上有5.64%的提升,而相比于表现最好的vsdc模型则有0.73%的提升。vsdc模型同样采用语义指导预测的思想,在语义方面采用注意力机制获取与问题相关的语义信息。而本发明除采用语义注意力机制外,还增加三类融合方法以提升模型多角度语义理解的能力,实验结果表明语义通道中的多角度语义模块对提高预测精度具有重要意义。在测试-标准集中,本发明提出的模型也具有同样的表现。
[0165][0166]
表2 vqa 2.0测试-开发集与测试-标准集中各模型的表现
[0167]
如表2所示,本发明进一步验证模型在vqa 2.0数据集上的性能,其中包括测试-开发集与测试-标准集。通过与先进方法的比较,可以看出,本发明提出的模型在总体精度等指标上具有不错的表现。相较于murel[49]模型,本发明的总体准确率在测试-开发集与测试-标准集中分别提升1.22%与0.89%。murel模型为目前多模态关系建模方法中较为突出的模型,是一种采用残差特性学习端到端推理的网络结构。而本发明的表现优于该模型是由于语义通道对答案预测的指导作用,使模型能够利用大量的语义信息提升预测精度。此外,相比于采用强化学习与监督学习并行方式的vctree模型,该模型作为目前具有较好表现的视觉问答方法,本发明在总体精度等指标上也具有明显的优势。综上所述,
[0168]
通掘过与上述先进方法的对比,本发明提出的模型能够在理解图像内容的基础上更好地挖掘语义信息,提升模型对答案预测的准确率。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1