一种基于序列图像分割的SLAM方法
一种基于序列图像分割的slam方法
技术领域
1.本发明涉及一种基于序列图像分割的slam方法,属于空间定位技术领域。
背景技术:
2.同步定位和建图(simultaneous localization and mapping,slam)是近年来关注度非常高的研究方向,其目的主要是解决从多幅图像中检测到的一组特征对应,同时估计摄像机位置姿态和场景的三维结构的问题,通过检测动态目标,完成动态环境中的定位与建图任务。
3.目前,许多现有的通用框架和算法还存在一些问题:第一,许多算法专注于不同时空下图像的几何关系,而忽略了环境中关键目标的语义信息,这不利于环境的理解。第二,许多算法仅仅在静态环境下能取得优良的定位和建图结果,但当试验环境中出现未知数量、未知种类的动态目标时,定位和建图精度会大大降低。为了解决这两方面问题,即如何在动态环境下的slam中减少动态目标特征提取过程中带来影响,采用将分割算法融入到slam过程中。例如公布号 cn111797688a名为“一种基于光流和语义分割的视觉slam方法”的专利中,对输入的多帧图像采用mask r-cnn网络进行分割,通过分割结果进行动态特征提取,将去除动态影响后的特征点用于后续的slam系统中,可以很好地消除动态物体对slam定位和制图的影响。但该专利对每一帧图像都进行分割,得到每一帧图像的静态区域和预测动态区域,而slam主要是剔除动态区域的特征点,对每帧图像全部进行分割,导致分割数据量过大,使得图像分割速度也不高,严重影响了slam效率。
技术实现要素:
4.本发明的目的是提供了一种基于序列图像分割的slam方法,以解决现有技术中序列图像分割数据量大导致slam效率低的问题。
5.本发明提出的一种基于序列图像分割的slam方法,该方法包括以下步骤:
6.1)利用深度相机获取目标区的序列图像、以及序列图像中每帧图像对应时刻下相机的位姿信息和每帧图像的orb特征点;
7.2)将获取的序列图像分成多个子序列,对每个子序列中的第一帧图像分别进行实例分割,得到各子序列中第一帧图像中目标检测框信息;利用该图像中目标检测框信息、深度信息、对应时刻的相机位姿信息,计算所述第一帧图像中目标检测框的位置信息和尺寸;
8.3)根据第一帧图像中目标检测框的位置信息和尺寸、第一帧与第二帧相机的位姿信息,计算第二帧图像中目标检测框的概略位置;子序列中其他任一帧图像的目标检测框的位置均是利用当前帧的相机位姿信息与前若干帧中任意一帧的相机位姿信息、目标检测框的位置信息和尺寸确定;
9.4)根据每一帧图像中的目标检测框的概略位置,提取每一帧图像中目标检测框内的图像作为每一帧图像中的目标图像,将所述目标图像叠加放入设定尺寸的空白图像中,得到设定尺寸的目标图像;对设定尺寸的目标图像进行实例分割,将实例分割结果放入对
应帧的原始图像中,得到每一帧图像的实例分割目标;
10.5)利用光流检测法和每一帧图像的实例分割目标,判断获取的orb特征点是否为动态特征点,并移除动态特征点,将剩余特征点用于跟踪与建图。
11.本发明将序列图像分成多个子序列,对每个子序列中第一帧图像进行实例分割,得到该图像下的目标检测框,并根据该图像下目标检测框的位置信息和尺寸及两帧图像下相机的对应位姿信息,确定下一帧或之后任意一帧图像中目标检测框的概略位置;每一帧图像的目标检测框的概略位置均是利用当前帧的相机位姿信息与前若干帧中任意一帧的相机位姿信息、目标检测框的位置信息和尺寸确定的;本发明采用这种方式,得到每一帧图像中目标检测框的概略位置,以此得到每一帧图像中对应目标检测框内的图像,即目标信息,再对目标检测框内的图像进行实例分割,相比于现有技术中对每一帧中整幅图像均进行分割处理,明显减少了分割图像的数据量,有效提高了图像实例分割速度,提高了工作效率;最后基于实例分割结果采用光流检测法剔除动态特征点,提高了后续目标区的同步定位和建图的效率。
12.进一步地,每一子序列中包含按时间顺序排列的若干帧图像,其中第一帧为各子序列中时间最早的图像。
13.每个子序列中的若干帧图像均是按照时间先后顺序排列的,利用图像之间时间的关联性,根据前面帧的目标检测框位置,能方便估计出后一帧中目标检测框的位置。
14.进一步地,对每一子序列中的第一帧图像采用mask r-cnn网络进行实例分割。
15.进一步地,所述步骤4)中将所提取的目标图像放置在设定尺寸空白图像的中心位置,生成设定尺寸的目标图像。
16.进一步地,每一子序列中的设定尺寸的目标图像均采用mask r-cnn网络进行实例分割,其中选择所述设定尺寸的目标图像的中心区域作为mask r-cnn网络中锚点的选择区域。
17.将所提取的目标图像均放置在设定尺寸空白图像的中心位置,方便后续图像实例分割时的锚点区域的选择,不再需要对整幅图像进行分割,将中心区域作为 mask r-cnn中锚点的选择区域,可以减少较少锚点的数量,同时减少生成锚框的数量,提高分割效率。
18.进一步地,所述步骤3)中是通过点位映射方法确定下一帧图像中目标检测框的位置。
19.通过点位映射可以快速确定当前帧图像中的点位在下一帧图像的位置。
20.进一步地,orb动态特征点的确定方法如下:若检测特征点不包含在实例分割目标内,特征点为静态特征点;若特征点包含在实例分割目标内,且目标是静态的,特征点为静态特征点;若特征点包含在实例分割目标内,且目标是动态的,特征点为动态特征点。
21.通过上述过程确定orb特征点与分割目标的关系,特征点不包含在目标内的为背景特征点,可用于跟踪与重建;特征点包含在目标内且目标是静态的,可用于跟踪和目标重建,不可用于场景重建;特征点包含在目标内且目标是动态的,不可用于跟踪和重建,将其剔除。
附图说明
22.图1是本发明基于序列图像分割的slam系统流程图;
23.图2是本发明序列图像分割方法流程图;
24.图3(a)是原始rpn锚点生成示意图;
25.图3(b)是本发明rpn锚点生成示意图;
26.图4(a)是本发明试验例中所采用的第一锚点生成策略示意图;
27.图4(b)是本发明试验例中所采用的第二锚点生成策略示意图;
28.图4(c)是本发明试验例中所采用的第三锚点生成策略示意图;
29.图4(d)是本发明试验例中所采用的第四锚点生成策略示意图。
具体实施方式
30.下面结合附图对本发明的具体实施方式作进一步地说明。
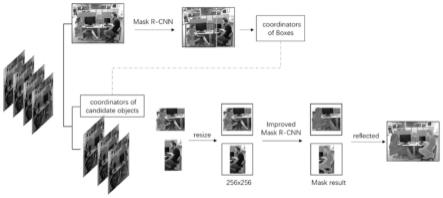
31.本发明提出一种基于序列图像分割的slam方法,具体如图1所示。本发明在orb-slam3系统的基础上实现整个流程,首先获取目标区的序列图像及对应时刻下的相机位姿,并获取每帧图像的orb特征;然后将序列图像分成多个子序列,对每个子序列的第一帧图像进行实例分割,获取得到的目标检测框信息及不同时刻下相机的位姿确定其余每帧图像的目标图像,并对每帧图像的目标图像进行分割,得到最终所有图像的实例分割结果。在获取序列分割结果后,通过光流检测法对动态特征点进行剔除,然后再将剔除后的特征点传入到后续的跟踪及建图过程中。为了保证整个系统能鲁棒地运行,如图1所示,除了optical flowconsistency check和screening feature points这两个过程,其余过程仍使用 orb-slam3系统的过程和相应算法,与orb-slam3保持一致。
32.步骤1.获取数据
33.通过安装在固定载体(无人机或无人车)上的深度相机获取目标区域的序列图像。其中深度相机可以是单目相机、双目立体相机或rgb-d相机。同时根据载体上安装的imu可以估算出每一时刻下的传感器的位姿。还需要获取每一帧图像上的orb特征点,该orb特征点利用图1中的orb extract模块获取,可以通过orb特征提取方法(例如fast+brief算法)实现。
34.步骤2.实例分割
35.对获取的序列影像进行实例分割,目的为确定图像中的实例目标。如图2 所示,序列图像分割方法分为以下几个步骤:
①
将序列图像分成几个子序列;
②
对每个子序列的第一帧图像进行实例分割,得到目标检测框信息和掩码信息;
③
利用相机的位姿信息、深度信息以及检测框信息,计算当前帧中目标检测框的位置和尺寸;
④
读取子序列中下一帧图像,利用计算得到的位置和尺寸信息以及前后帧相机位姿信息计算目标在当前帧图像中的检测框概略位置;
⑤
对每一帧图像提取对应目标检测框下的目标图像,并将其放置在一个设定尺寸的空白图像中,生成设定尺寸的目标图像;
⑥
将之后每一帧的设定尺寸的目标图像输入到改进的分割网络中进行分割,得到最终的检测框信息和目标掩码结果。
36.在步骤
①
中,将序列图像按照时间排列顺序分成多个子序列,每一子序列中包含按时间顺序排列的若干帧图像,第一帧图像为各子序列中时间最早的图像。在本实施例中,每个子序列包含有10幅图像。作为其他实施方式,每个子序列中的图像个数可以根据实际获取的序列图像的数量确定。
37.在步骤
②
中,对每个子序列中的第一帧图像进行实例分割,得到该图像的目标检
测框信息,如图2中所示,得到两个实例目标所在的矩形框。在本实施例中,采用mask r-cnn进行实例分割。作为其他实施方式,还可以采用deep snake、 transformer等进行实例分割。
38.在步骤
③
中通过相机的位姿信息、深度信息以及检测框信息,计算当前帧中目标检测框的位置和尺寸,如公式(1)和公式(2)所示,可以得到当前帧目标检测框的角点坐标,以此来确定检测框的位置和尺寸,例如通过左上角点和右下角点坐标来确定,或者通过左下角点和右上角点坐标来确定。
39.在步骤
④
中,利用点位映射的方法确定后续帧中目标检测框的概略位置。已知前后帧相机的位姿信息,通过点位映射,由前一帧的点位信息以及前后帧相机的位姿信息,计算得到该点在当前帧图像中的点位估计值。例如p1和p2分别代表在前一帧和当前帧图像中的同一点:
40.p1=[u1,v1,d1],p2=[u2,v2,d2]
ꢀꢀ
(1)
[0041]
其中u,v代表图像像素坐标,d代表对应深度值。根据相机内参和公式(2),可以计算得到该点在两个相机位姿下的相机坐标:
[0042][0043]
其中(xc,yc)为相机的主点,f
x
和fy为相机的焦距,和分别代表该点在两个相机位姿下的相机坐标。两个相机位姿之间的关系可以通过公式(3)表示:
[0044][0045]
其中r代表旋转矩阵,t代表平移矩阵,r和t可以由前后帧相机的位姿外参求得。
[0046]
例如,第一帧图像检测分割得到的检测框box1(l1,r1),假设l1(u
l1
,v
l1
)和 r1(u
r1
,v
r1
)分别代表第一帧图像中目标检测框的左上角和右下角的像素坐标,由公式(1)-(3)可以求得目标检测框在第二帧图像中的概略位置box2((l2,r2)), l2(u
l2
,v
l2
)和r2(u
r2
,v
r2
)分别代表第二帧图像中目标检测框的左上角和右下角的像素坐标。同理,为了求解第i帧图像中目标检测框的概略位置,利用第i帧图像对应相机的位姿信息和前若干帧中任意一帧的相机位姿信息、目标检测框的位置信息和尺寸来确定,例如第5帧图像的目标检测框概略位置,可以利用第一帧至第四帧图像中任一帧图像来确定。再例如,除第一帧外所有图像的目标检测概略位置均用第一帧图像来确定,或者相邻上一帧图像来确定。
[0047]
在步骤
⑤
中,根据步骤
④
计算出每一帧图像的目标检测框的概略位置,提取出对应位置下的目标图像,如图2中所示,每一帧图像均能提取出两个目标图像;再将提取出的目标图像放入一个设定尺寸的空白图像中,在本实施例中,空白图像的尺寸为256像素
×
256像素,作为其他实施方式,该空白图像的尺寸也可以根据实际情况来定。在本实施例中,
将每一帧提取出的目标图像放置在256像素
×
256像素空白图像的中间位置,得到每一帧256像素
×
256像素的目标图像。作为其他实施方式,也可以放置在左上角或者右上角等位置处。
[0048]
在步骤
⑥
和步骤
②
中,本实施例均是采用mask r-cnn进行实例分割,maskr-cnn是一种two-stage检测方法。two-stage方法生成的锚框会映射到特征图 (feature map)的区域,然后将该区域重新输入到全连接层中进行分类和回归。由于生成锚框的数量较多,每个锚框都需要进行映射并通过全连接层分类和回归,所以two-stage方法比较耗时,不能满足slam过程中对序列图像处理时效的要求。因此在步骤
⑥
中,不再对每一帧整幅图像进行实例分割,而是直接对步骤
⑥
中设定尺寸的目标图像利用mask r-cnn网络中rpn层生成候选建议框,来减少初始锚点的数量以及候选建议框的数量,进而减少了候选建议框映射、分类和回归过程所消耗的时间,提高了分割的效率。
[0049]
如图3(a)是mask r-cnn网络中rpn层基本结构,它的输入是特征图,输出的是候选区域,通过坐标数据(x,y,w,h)来表示,x和y表示候选框左上角点的坐标,w和h则表示矩形框的宽和高。原始的mask r-cnn中选定了五种不同的尺寸以及三种长宽比的矩形框作为初始候选框,图3(a)中的点称为锚点 (anchors),其本质上指的是特征图上当前滑窗的中心在原像素空间的映射点。遍历resnet中p2-p6五个特征层,以一定步长在每个特征层上选择锚点,并以所在特征层所对应的尺寸,为每个锚点生成长宽比例分别为2:1、1:1、1:2的3 个anchor锚框,而后对生成的所有anchor锚框进行分类和回归操作,类别分为前景或背景两种,k个anchor锚框会生成2k个分数,而回归操作则回归得到4k 个分数,分别对应x、y、w和h。最后再用iou(intersection over union)值筛选出128个正样本和128个负样本,使用其对应的分数来计算交叉熵损失函数,进而用于网络训练。在原始网络中,搜索锚点的步长为1,也就意味着对于每一个特征层上的每一个点都会作为一个锚点去生成anchor锚框。以p2层为例,若输入的原图大小为512x512,则p2层特征图的大小即为128x128,那么在该特征层上相对于原图的步长为4,在该特征层上的anchor锚框数量为128x128x3,锚框大小由特征层对应的缩放尺寸来决定。
[0050]
为了减少生成anchors锚框的数量,提高网络的速率,考虑到序列图像中潜在动态目标的特性:
①
序列图像中各帧图像获取的时间间隔,动态目标在各帧之间的移动范围有限;
②
由于相机和动态目标同时在运动,且运动的范围有限,因此动态目标在后一帧的尺寸也会发生变化,变化范围也有限。然后针对潜在运动目标的运动特性,本发明仅对设定尺寸的目标图像的中心区域生成锚框,即只针对步骤
⑤
中设定尺寸的目标图像生成锚框,若设定尺寸的目标图像在空白图像的中心区域,则只针对中心区域进行处理。如图3(b)所示,图中展示了在输入图像大小为512x512时,p6、p5、p4特征层的锚点选取区域,由中心黑色部分表示(因为网格数量,未对p3、p2特征层进行展示)。p2-p6层特征图大小依次为 128x128、64x64、32x32、16x16和8x8,采用新的选取锚点规则,anchor锚框的数量减少到了原来的1/8。五个特征层取的anchor锚框尺寸分别为24、48、96、 192和384。作为其他实施方式,每一层anchor锚框的数量可根据实际情况来定,只需要覆盖设定尺寸的目标图像即可。
[0051]
将得到的实例分割结果直接通过平移的方式放入对应帧的原始图像中,得到每一子序列下每帧图像的实例分割结果,也就是目标信息。
[0052]
步骤3.光流动态分析
[0053]
在检测出图中的目标后,为了实现后续目标同步定位与制图,需要判断步骤 1中的orb特征点是否为动态特征点。特征点与实例分割后目标之间的关系可以分为以下几类:
①
特征点不包含在目标内,特征点为背景特征点,可用于跟踪与重建;
②
特征点包含在目标内,且目标是静态的,特征点可用于跟踪和目标重建,不可用于场景重建;
③
特征点包含在目标内,且目标是动态的,特征点不可用于跟踪和重建,应予以剔除。
[0054]
本发明采用光流法来对特征点的运动情况进行分析,首先确定运动点的动态情况,如果在目标内包含了一定数量以上的特征点,则判断目标为动态目标。金字塔lk光流法基于三个假设:亮度恒定、相邻帧间物体运动较小以及邻域内光流一致性。第一步是计算光流金字塔,得到各特征点在x和y方向上的运动速度;分别计算背景区域内和目标区域内特征点的平均运动速度;若背景区域和目标区域内特征点的平均运动速度差值超过一定数值,则判断目标为动态。
[0055]
使用i
l
和j
l
表示图像i和j的第l层金字塔图像,u=[u
x
,uy]
t
为i中跟踪的像素坐标,则在i
l
中坐u
l
=[u
xl
,u
yl
]
t
=u/2
l
金标金字塔光流法的思想是首先在最高层计算光流大小,而后把其结果作为下一层光流的初始值,在计算该层的光流大小,以此类推直至计算出最后一层图像的光流大小作为最终结果。假设l+1 层的光流大小值,即第l层光流大小的初始值为g
l
=[g
xl
,g
yl
]
t
,需要在图像j 中找到像素v
l
=u
l
+d
l
=[u
xl
+d
xl
+d
yl
]
t
,点使两者的灰度值差值最小。则可以将d
l
=[d
xl
,d
yl
]
t
定义为光流。
[0056]
为了求解光流,将求解过程转化为优化问题,使公式(4)中的优化函数最小:
[0057][0058]
其中ε
l
(d
l
)表示灰度值差值,即目标函数,w
x
,wy表示邻域范围,可求解得:
[0059]dl
=g
l-1bl
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(5)
[0060][0061][0062]
其中分别表示图像在x方向和y方向的梯度,δi
l
(x,y)=i
l
(x,y)-j
l
(x,y)表示图像差异。在计算得到l层的光流大小d
l
后,将该值作为l-1层的初值,计算l-1层光流大小,依次类推。
[0063]
本发明通过上述序列影像的实例分割和光流动态分析,利用图1中的opticalflow consistency check和screening feature points剔除了orb动态特征点,将剩余的orb静态特征点输入到图1中的orb-slam3系统中,进行后续局部地图跟踪(track local map)、关键帧决策(new key frame decision),实现局部建图、回环、地图融合以及全局地图优化,完成场景地图重建。其中,本发明使用orb-slam3系统框架新增了optical flow consistency check和 screening feature points这两个过程,其余过程仍与orb-slam3系统的一致,且对应算法也未发生改变,因此这里就不再对该系统进行详细介绍。
[0064]
为了更好地说明本发明的效果,现对本发明的slam方法进行试验验证。
[0065]
从tum数据集中选取两组序列图像进行试验,每组100帧。图像中的主要对象是人和椅子。本试验测试了锚点生成策略的选择以及所提出的序列图像联合分割方法的有效性,并比较了四种生成锚的策略。以一张8
×
8的featuremap为例,四种不同的策略如图4(a)、图4(b)、图4(c)和图4(d)所示。为了验证所提出的序列图像联合分割方法的有效性,测试了三组序列图像,并分析了目标分割的准确性和速度。
[0066]
结果如表1所示,本发明提出的序列图像分割方法比原始的mask r-cnn快近3倍;此外,在准确性方面也有改善,证明了所提策略的有效性。图4(d)所示的锚点生成策略可以达到最高的分割准确率84.5%,但需要更多的时间。图4(c) 中锚点生成策略分割时间最短,但准确率较低。此外,图4(a)和图4(b)中锚点生成策略的分割精度相似,但图4(b)中锚点生成策略的分割时间较小。因此, 4(b)为最优策略。
[0067]
表1
[0068]
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1