一种基于多特征融合的端到端图像去雾方法
1.本发明属于有雾图像处理技术领域,涉及一种基于多种特征融合的图像去雾的方法。
背景技术:
2.随着信息化时代的到来,各种智能视觉系统被广泛应用于智能交通、智能安防和军事侦察等领域。它们以图像作为传递信息的基础载体并对其进行智能处理和分析,例如目标检测、识别和跟踪等等,但这些高级视觉任务对图像的质量有一定的要求。在雾霾天气下,由于空气中大量的悬浮粒子对物体反射光和大气光的吸收和散射作用,导致拍摄的图像质量大幅度下降,出现对比度降低、颜色失真和清晰度下降等问题,这些问题会严重图像在高级视觉任务中的应用,导致智能视觉系统出错。所以图像去雾已经成为计算机视觉中的重要研究课题,其旨在通过去除图像雾气来将有雾图像恢复为无雾图像,恢复其清晰度,对保障高级视觉任务的性能和智能视觉系统的稳定使用具有重大意义。
3.现有的图像去雾方法主要可以分为2类,一是基于图像先验特征的方法,这类方法以大气散射模型为基础,利用图像先验特征估计出透射率图和全球大气光值,然后代入进大气散射模型,求得清晰图像。he等人提出了暗通道先验特征,用于估计透射率图,但会在天空区域及白色区域失效;zhu等人提出了颜色衰减先验,通过建立图像亮度、饱和度与场景深度的线性模型求解出深度图,然后推导出透射率图,但其会导致在近景区域会有部分白色。先验信息一般基于真实图像数据统计,在真实场景下往往非常有效,但具有局限性,无法通用于所有场景。
4.二是基于深度学习的方法,可以通过神经网络估计透射率图和全球大气光值,再代入大气散射模型求解出清晰图像,但这样会造成误差叠加,最终误差增大,所以目前是通过神经网络直接从有雾图像预测出清晰图像的方法占主流。但是这类方法也存在着问题,要训练这样的神经网络需要大量的有雾/清晰图像对,但这种数据的获取异常困难,虽然ntire组织了几次去雾挑战并介绍了几个小规模的真实世界数据集,但它是稀少的、不全面的,也无法训练出通用性很高的模型。所以目前使用的训练图像一般是合成图像,有雾图像是通过在真实清晰图像上根据大气散射模型进行加雾处理而形成的。由于神经网络在合成数据集上进行训练,合成数据与真实数据存在一定的差异性,就导致模型迁移到真实场景下的去雾效果往往没有那么好。
技术实现要素:
5.针对上述现有技术存在的缺陷或不足,本发明的目的在于,提供一种基于先验特征与深度特征融合的图像去雾方法,该方法解决了模型在真实场景下通用性与有效性不能兼顾的问题,提高了深度学习模型在真实场景下的去雾效果;并且模型较为轻量,能实现快速去雾。
6.为了实现上述目的,本发明所采用的技术方案如下:
7.一种基于多特征融合的端到端图像去雾方法,具体包括以下步骤:
8.步骤一,获取样本数据集:分别使用合成数据集和真实世界数据集训练和测试网络模型;合成数据集和真实世界数据集均包括有雾/清晰图像对;
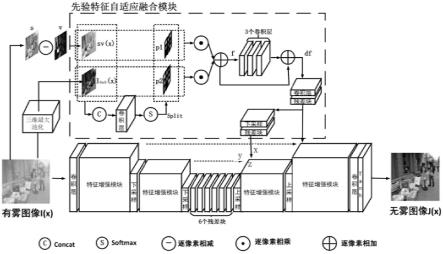
9.步骤二,搭建基于多特征融合的端到端图像去雾网络模型:包括以全局特征融合注意力模块为核心的基础网络、支持反向传播的先验特征提取模块和先验特征自适应融合模块;其中,支持反向传播的先验特征自适应融合模块得到的暗通道先验特征和颜色衰减先验特征进入先验特征自适应融合模块进行融合,再与以全局特征融合注意力模块为核心的基础网络得到的深度学习特征进行融合;
10.步骤三,构建损失函数;
11.步骤四,训练基于多特征融合的端到端图像去雾网络模型:设置训练参数、初始化网络模型参数,数据集训练样本中的有雾图像作为网络模型的输入,然后把网络模型的输出与有雾图像对应的真实清晰图像代入损失函数计算损失,利用反向传播算法更新网络模型参数,得到训练好的去雾网络模型;
12.步骤五,利用训练好的模型对待处理图像进行去雾处理,得到去雾后的图像。
13.进一步的,所述步骤1中的合成数据集包括msbdn所使用的reside训练集和ots测试集,真实世界数据集包括o-haze数据集和nh-haze数据集。
14.进一步的,所述步骤二中,所述的以全局特征融合注意力模块为核心的基础网络包括依次相连接的编码器、残差块和解码器,其中,编码器包括依次相连的卷积层、特征增强模块、下采样卷积层、特征增强模块、下采样卷积层;解码器包括依次相连的上采样卷积层、特征增强模块、上采样卷积层、特征增强模块、卷积层和tanh函数。
15.进一步的,所述以全局特征融合注意力模块为核心的基础网络中,第一层和最后一层的卷积层都使用7
×
7的卷积核,除了最后一层卷积层,其余卷积层后都有非线性relu函数,残差块内的卷积层后也有非线性relu函数;在残差块中,不使用任何归一化层,卷积层都使用3
×
3卷积;该基础网络包含三个尺度,在编码器中,使用stride-conv层进行1/2倍的下采样处理,得到的特征图为原来的1/2,每个尺度均由特征增强模块代表;在解码器中,使用transposed-conv层进行2倍的上采样处理。
16.进一步的,所述特征增强模块由两个残差块、全局特征融合注意力模块(gffa)和两个局部残差连接构成;所述特征增强模块用于实现如下功能:首先将输入数据依次采用两个残差块进行特征提取,从第一个残差块中输出数据还通过两个局部残差连接与第二个残差块的输出数据、gffa模块的输出数据分别逐像素相加,得到特征增强模块的输出数据;
17.在所述解码器中的特征增强模块的输入为所述先验特征自适应融合模块的输出x、编码器中高度相等的特征增强模块的输出y、上采样卷积层的输出z。
18.进一步的,所述全局特征融合注意力模块包含3个部分:全局上下文块、高效通道注意力块、简化像素注意力块;
19.所述全局上下文块用于实现如下计算过程:
[0020][0021]
δ=conv(relu(ln(conv(c))))
[0022]
gc=x+δ
[0023]
其中,x为gffa的输入,gc为全局上下文块的输出,ln代表layernorm;
[0024]
所述的高效通道注意力块用于实现如下计算过程:
[0025][0026]
eca=x
×
sigmoid(1dconv(c,k))
[0027]
其中,c代表通道数,|t|
odd
表示最近的奇数t,本实施例中将γ和b分别设置成2和1,k=5,eca为高效通道注意力块的输出;
[0028]
所述全局上下文块的输出gc和高效的通道注意力块的输出eca进行逐像素相加,输入简化像素注意力模块;
[0029]
所述简化像素注意力模块包括1个卷积层和relu函数,用于实现如下计算过程:
[0030]
spa=(eca+gc)
×
sigmoid(conv((eca+gc))。
[0031]
进一步的,所述步骤二中,所述的先验特征提取模块用于对有雾图像进行暗通道先验特征、颜色衰减先验特征的提取;其中:
[0032]
a、暗通道先验特征的提取
[0033]
使用三维最大池化对有雾图像i(x)进行暗通道先验特征的提取,如下式所示:
[0034]idark
(x)=1-maxpool3d(1-i(x));
[0035]
b、提取颜色衰减先验特征,公式如下:
[0036]
sv(x)=hsv(i(x))
s-hsv(i(x))v[0037]
其中,i(x)为有雾图像;
[0038]
进一步的,所述步骤二中,所述的先验特征自适应融合模块的实现如下式所示:
[0039]
p1,p2=split(softmax(conv(concat(i
dark
(x),sv(x)))))
[0040]
f=(p1
×idark
(x))+(p2
×
sv(x))
[0041]
df=f+conv(conv(conv(f)));
[0042]
得到的df再经过卷积层、残差块得到的结果分为两路,一路进入解码器的第2个特征增强模块,另一路经过下采样、残差块后进入解码器的第1个特征增强模块。
[0043]
进一步的,所述步骤三中,所述损失函数为:
[0044]
l=l
mse
+γl
p
[0045][0046][0047]
其中,l
all
表示总的损失,l
mse
表示均方误差损失,l
p
表示感知损失,γ控制感知损失的权重,设置为0.04;w和h分别代表图像的宽度和高度,j(x)和jg(x)分别表示网络输出的无雾图像和真实的无雾图像;φ代表vgg16的i层的特征图。
[0048]
进一步的,所述步骤四中,模型训练使用adam优化器,其中β1参数和β2参数分别设置为0.9和0.999,训练时batch-size设置为8,总共训练1
×
106次迭代;
[0049]
初始学习率设置为1
×
10-4
,然后采用余弦策略进行学习率下降调整;假设总训练迭代次数为t,η为初始学习率,然后在第t代,计算学习率:
[0050][0051]
与现有技术相比,本发明有以下有益效果:
[0052]
1、结合先验特征在真实场景的有效性和深度学习的通用性,通过融合2种先验特征和深度学习特征,提出基于多特征融合的单幅图像去雾网络,提高了模型在真实户外场景的去雾性能;
[0053]
2、选择被广泛使用的暗通道先验特征和颜色衰减先验特征,并采取了非常直接有效和支持反向传播的提取方式,使得模型依然是端到端的,有利于去雾模型更好的嵌入到高级视觉任务当中,为其服务。
[0054]
3、提出先验特征自适应融合模块,从2种先验特征中选择有效的特征进行融合,避免特征过于冗杂而影响到模型的性能。
附图说明
[0055]
图1是本发明的基于多特征融合的端到端图像去雾网络的整体结构图;
[0056]
图2是特征增强模块网络结构图;
[0057]
图3是全局特征融合模块网络结构图;
[0058]
图4是先验特征提取过程和自适应融合过程图,其中:
[0059]
(a)是有雾图像hazy;
[0060]
(b)是暗通道先验特征提取结果图i
dark
(x);
[0061]
(c)是颜色衰减先验特征提取结果图sv(x);
[0062]
(d)是有雾图像对应的清晰图像gt;
[0063]
(e)是暗通道先验特征对应的权重图p1;
[0064]
(f)是颜色衰减先验特征对应的权重图p2;
[0065]
(g)是暗通道先验特征和颜色衰减先验特征融合结果图f;
[0066]
(h)是先验特征融合结果的残差增强结果图df;
[0067]
图5是先验特征自适应融合模块网络结构图;
[0068]
图6是合成数据集上图像去雾结果对比图,其中:
[0069]
(a)是有雾图像及其方框的放大图;
[0070]
(b)是dcp模型的去雾结果及其方框的放大图;
[0071]
(c)是aod-net模型的去雾结果及其方框的放大图;
[0072]
(d)是dcpdn模型的去雾结果及其方框的放大图;
[0073]
(e)是ffa-net模型的去雾结果及其方框的放大图;
[0074]
(f)是msbdn模型的去雾结果及其方框的放大图;
[0075]
(g)是本发明模型的去雾结果及其方框的放大图;
[0076]
(h)是有雾图像对应的清晰图像及其方框的放大图;
[0077]
图7是真实世界数据集上图像去雾结果对比图;其中:
[0078]
(a)是有雾图像;
[0079]
(b)是dcp模型的去雾结果图;
[0080]
(c)是aod-net模型的去雾结果图;
[0081]
(d)是dcpdn模型的去雾结果图;
[0082]
(e)是ffa-net模型的去雾结果图;
[0083]
(f)是msbdn模型的去雾结果图;
[0084]
(g)是本发明模型的去雾结果图;
[0085]
(h)是有雾图像对应的清晰图像;
[0086]
图8是基于多特征融合的端到端图像去雾方法流程图。
[0087]
以下结合附图和实施例对本发明作进一步详细解释说明。
具体实施方式
[0088]
本实施例给出一种基于多特征融合的端到端图像去雾方法,包括以下步骤:
[0089]
步骤一,获取样本数据集:
[0090]
(1)合成数据集
[0091]
获取msbdn在reside数据集上进行数据增强后使用的数据集。msbdn从reside训练数据集中选择9000个室外有雾/清晰图像对和7000个室内有雾/清晰图像对作为训练集,方法是从相同场景中删除多余的图像。并且为了进一步增强训练数据,使用[0.5,1.0]范围内的三个随机比例调整每对图像的大小,从有雾图像中随机裁剪256
×
256图像块,然后将它们水平、垂直翻转为模型的输入。获取reside数据集中的ots子数据集作为测试集,其中包含500对户外合成图像。
[0092]
(2)真实世界数据集
[0093]
获取ntire2018dehazing challenge中的o-haze数据集和ntire2020 dehazing challenge中使用的nh-haze数据集。o-haze数据集包含45对室外有雾/清晰图像对,使用其中第1-40对来训练模型,使用第41-45对进行测试。nh-haze数据集包含55对室外有雾/清晰图像对,使用第1-50对来训练模型,使用第51-55对进行测试。在测试过程中,由于图像太大,在一些实验中对输入图像进行了裁剪,以防止内存不足。
[0094]
步骤二,搭建基于多特征融合的端到端图像去雾网络模型:包括以全局特征融合注意力模块为核心的基础网络、先验特征提取模块和先验特征自适应融合模块;
[0095]
如图1所示,为基于多特征融合的图像去雾网络的整体结构图。
[0096]
(1)以全局特征融合注意力模块为核心的基础网络
[0097]
基础网络采用具有跳层连接的编码器-解码器结构,这类体系结构已经在图像去雾任务中表现出良好的效果。本实施例中,以全局特征融合注意力模块为核心的基础网络包括依次相连接的编码器、残差块和解码器,其中,编码器包括依次相连的卷积层、特征增强模块、下采样卷积层、特征增强模块、下采样卷积层;解码器包括依次相连的上采样卷积层、特征增强模块、上采样卷积层、特征增强模块、卷积层和tanh函数。
[0098]
全局特征融合注意力模块为核心的基础网络中,第一层和最后一层的卷积层都使用7
×
7的卷积核,除了最后一层卷积层,其余卷积层后都有非线性relu函数,残差块内的卷积层后也有非线性relu函数。在残差块中,不使用任何归一化层,卷积层都使用3
×
3卷积。该基础网络包含三个尺度,在编码器中,使用stride-conv层进行1/2倍的下采样处理,得到的特征图为原来的1/2,每个尺度均由特征增强模块代表。在下采样之前对特征进行集中增强,有利于减少特征损失。在解码器中,使用transposed-conv层进行2倍的上采样处理,上
采样后的特征增强有利于图像信息的恢复。
[0099]
编码器-解码器的基础模块为特征增强模块,如图2所示,其由两个残差块、全局特征融合注意力模块(gffa)和两个局部残差连接构成。特征增强模块用于实现如下功能:首先将输入数据依次采用两个残差块进行特征提取,从第一个残差块中输出数据还通过两个局部残差连接与第二个残差块的输出数据、gffa模块的输出数据分别逐像素相加,得到特征增强模块的输出数据。从而利用局部残差连接和全局特征融合注意力模块对提取的特征进行增强,局部残差连接可以让网络绕过不重要的信息,全局特征融合注意力模块用于让网络关注更加有用的信息并加入全局信息,以提升模型性能。
[0100]
图2所示,在编码器与解码器中的特征增强模块的输入不同,解码器中特征增强模块的输入为先验特征自适应融合模块的输出x、编码器中高度相等的特征增强模块的输出y、上采样卷积层的输出z。
[0101]
(2)全局特征融合注意力模块(gffa)
[0102]
如图3所示,全局特征融合注意力模块包含3个部分:全局上下文块、高效通道注意力块、简化像素注意力块。
[0103]
当浓雾遮挡住部分场景时,需要依靠全局上下文信息去复原清晰场景,所以全局信息对图像去雾很重要。通过堆叠卷积块、增大感受野的方式并不能完全捕获全局信息,并且会增大网络参数,本实施例中使用如下公式所示的全局上下文块捕获全局信息,并通过加入全局上下文块输出特征增强现有特征:
[0104][0105]
δ=conv(relu(ln(conv(c))))
[0106]
gc=x+δ
[0107]
其中,x为gffa的输入,gc为全局上下文块的输出,ln代表layernorm;上面第一个公式表示上下文建模过程:首先通过1
×
1卷积获得1
×h×
w的特征图,然后把尺寸变为hw
×1×
1,在hw的方向上利用softmax函数进行归一化,得到全局特征权重,最后把x变为c
×
hw,再与全局特征权重进行矩阵乘法操作得到全局上下文特征c(尺寸为c
×1×
1);上面第二和第三个公式表示对全局上下文特征c进一步处理得到的特征与gffa的输入x逐像素相加,得到全局上下文块的输出gc,从而实现把全局上下文块初步输出的特征再加回到原来的特征上,得到具有全局信息的增强特征。
[0108]
以前的通道注意力都是通过全局平均池化获取全局空间信息,并把特征图的尺寸从c
×h×
w变为c
×1×
1,但全局平均池化过程会损失大量信息。通道注意力与全局上下文块有着相似的结构,本实施例发现上下文建模过程拥有全局平均池化同样的作用,而且更为高效。所以本实施例使用上下文建模过程替代通道注意力中的全局平均池化,为了进一步简化网络,本实施例中采用让全局上下文块和高效通道注意力模块共享上下文建模过程。
[0109]
在捕获跨通道交互的过程,本实施例中使用高效通道注意力块,通过考虑每个通道及其k个邻居去捕获局部跨通道交互,得到通道权重。高效通道注意力块的过程通过一维卷积去实现,k的大小由与通道数相关的自适应函数确定,如下公式所示:
[0110][0111]
eca=x
×
sigmoid(1dconv(c,k))
[0112]
其中,c代表通道数,|t|
odd
表示最近的奇数t,本实施例中将γ和b分别设置成2和1,k=5,eca为高效通道注意力块的输出。
[0113]
以上技术方案中,由全局上下文块通过捕获所有通道交互来进行特征转换,通过逐像素加法进行特征融合,由高效通道注意力块通过捕获局部通道交互并使用逐像素乘法,最后本实施例将全局上下文块的输出gc和高效的通道注意力块的输出eca进行逐像素相加,以进一步增强特征,作为下一步的输入。
[0114]
简化像素注意力模块使用了2个卷积层和relu函数,经过实验发现仅使用一个卷积层效果更好,且进一步简化了网络,因此本实施例中,包括1个卷积层和relu函数,过程如下式:
[0115]
spa=(eca+gc)
×
sigmoid(conv((eca+gc))
[0116]
把高效通道注意力块的输出gc和上下文块的输出eca进行逐像素相加得到加和,送入1
×
1卷积和sigmoid激活函数,得到像素注意力特征图,特征图尺寸从c
×h×
w变为1
×h×
w,然后让加和与像素注意力特征图进行逐元素相乘,得到输出spa。
[0117]
(3)先验特征提取模块
[0118]
先验特征提取模块用于对有雾图像进行暗通道先验特征、颜色衰减先验特征的提取。
[0119]
a、暗通道先验特征的提取
[0120]
he统计了大量的无雾图像,发现一条规律:每一幅图像的每一个像素的rgb三个颜色通道中,总有一个通道的灰度值很低。他把这个值称之为暗通道值,表示如下:
[0121][0122]
其中c表示r、g、b三通道中的某一通道,得到的j
dark
(x)称之为暗通道图像,通过大量统计并观察发现,暗通道图像的灰度值是很低的,所以将整幅暗通道图像中所有像素的灰度值近似为0,即:
[0123]jdark
(x)
→0[0124]
对于神经网络而言,网络的输入为有雾图像,由于雾霾的存在,图像中白色区域增加,导致图像的暗通道值不在近似为0,所以对有雾图像i(x)求得的暗通道图像i
dark
(x)的像素值可以一定程度上代表图像的雾浓度。
[0125]
本实施例中,使用三维最大池化对有雾图像i(x)进行暗通道图像特征的提取,如下式所示:
[0126]idark
(x)=1-maxpool3d(1-i(x))
[0127]
结果如图4(b)所示,在近处无雾区域,暗通道图像几乎都是黑色的,可以很清楚的区分有雾区域和无雾区域。由于每个局部区域的暗通道值一样,所以它缺乏细节信息。
[0128]
b、颜色衰减先验特征的提取
[0129]
zhu等人通过对有雾图像的统计发现,无雾情况下,亮度和饱和度几乎没差,受雾的影响下,亮度和饱和度之差悬殊。并且雾越浓重,两者相差越悬殊,也就是说亮度和饱和
度之差和雾浓度正相关。本实施例用以下公式直接求得颜色衰减先验特征;
[0130]
sv(x)=hsv(i(x))
s-hsv(i(x))v[0131]
把有雾图像i(x)转化为hsv格式,然后直接使用s通道的值减v通道的值作本实施例的颜色衰减先验特征。如图4(c)所示,sv(x)的值在雾越浓的区域越大,并且由于本实施例直接的提取方式,sv(x)包含大量的细节信息。
[0132]
2种先验特征的计算过程全部是基于张量的,所以它可以支持反向传播,以此保证本实施例的网络依然是一个端到端的网络。
[0133]
(4)先验特征自适应融合模块
[0134]
上述两种先验都是基于对真实图像的统计,所以它们的加入会让模型捕获到更适用于真实场景的特征。本实施例对于先验特征的提取是简单直接的,可以提取到最原始的先验特征,但这两种先验特征都有它的不足之处,暗通道先验在白色或者天空区域会失效,颜色衰减先验在近景无雾区域也会有部分白色。这样的特征直接加入到网络中无疑会影响到网络的性能,所以,本实施例设计了先验特征自适应融合模块,如图5所示,利用注意力机制对2种先验特征进行自适应的选择性的融合,以获取最有效的特征,其过程如下:
[0135]
p1,p2=split(softmax(conv(concat(i
dark
(x),sv(x)))))
[0136]
f=(p1
×idark
(x))+(p2
×
sv(x))
[0137]
df=f+conv(conv(conv(f)))
[0138]
首先,把2个先验特征图i
dark
(x)和sv(x)concat,再经过一个3
×
3卷积、softmax函数,会得到一个2通道的注意力特征,再经过split操作,,也就是把每一个通道的特征图当作一个先验特征的注意力图,会得到2个注意力图p1和p2,然后将二者和对应的先验特征分别相乘后再相加,得到融合后的特征f;最后,让f经过三个卷积操作后再加上f,通过残差的形式对f进行特征增强,得到增强后的特征df。
[0139]
在图4中,p1和p2分别是i
dark
(x)和sv(x)的注意力图,可以看到,对于i
dark
(x)主要保留近景无雾区域,对于sv(x)主要保留有雾区域和近景区域的细节信息。f对于近景无雾区域的恢复效果较好,且对于有雾区域达到了一定的去雾效果,df在保留细节信息的同时,去除了更多的雾度,df会再经过卷积层、残差块得到的结果分为两路,一路进入解码器的第2个特征增强模块,另一路经过下采样、残差块后进入解码器的第1个特征增强模块。
[0140]
步骤三,构建损失函数:
[0141]
均方误差在图像去雾任务中被广泛使用,并被证明对像素信息的恢复非常有效果。本实施例同样使用了均方误差作为损失函数之一,定义如下:
[0142][0143]
其中,w和h分别代表图像的宽度和高度,j(x)和jg(x)分别表示网络恢复的无雾图像和真实的无雾图像。同时,本实施例加入了感知损失,目的是通过观察提取的高、低层次特征的组合来保持原始的图像结构和背景信息,如下公式所示:
[0144][0145]
其中,φ代表vgg16的i层的特征图,本实施例的i的取值为2、5和8,即本实施例分别把网络输出的无雾图像j(x)和真实无雾图像jg(x)送入vgg16并取出第2层、第5层和第8
层的特征图,并分别计算2个特征图之间的距离。
[0146]
综上所述,本实施例总损失函数为:
[0147]
l=l
mse
+γl
p
[0148]
其中l
all
表示总的损失,l
mse
表示均方误差损失,l
p
表示感知损失,γ控制感知损失的权重,本实施例设置为0.04。
[0149]
步骤四,训练基于多特征融合的端到端图像去雾网络模型。具体是:设置训练参数、初始化网络模型参数,数据集训练样本中的有雾图像作为网络模型的输入,然后把网络模型的输出与有雾图像对应的真实清晰图像代入损失函数计算损失,利用反向传播算法更新网络模型参数,得到训练好的去雾网络模型。
[0150]
模型训练使用adam优化器,其中β1参数和β2参数分别设置为0.9和0.999,训练时batch-size设置为8,总共训练1
×
106次迭代。
[0151]
初始学习率设置为1
×
10-4
,然后采用余弦策略进行学习率下降调整,让学习率逐步从初始值下降为0。假设总训练迭代次数为t,η为初始学习率,然后在第t代,计算学习率:
[0152][0153]
模型训练框架为pytorch,训练使用的显卡型号为nvidia gtx2080supper gpu,显卡容量8g。
[0154]
步骤五,利用训练好的模型对待处理图像进行去雾处理,得到去雾后的图像。
[0155]
本实施例分别在合成数据集ots和真实数据集o-haze、nh-haze上进行了图像去雾测试,对于图6(a)和图7(a)的有雾图像,使用本实施例训练好的模型进行去雾,结果如图6(g)和图7(g)所示,同时与其他先进模型的去雾结果进行对比,从图中6和图7可以看出,dcp模型去雾结果有明显的颜色失真,aod-net和dcpdn模型的去雾效果不好,ffa-net的去雾结果有部分区域没有完全去雾,msbnd去雾结果细节特征恢复不足。本发明的算法拥有最优的结果,并且有很好的色彩恢复和细节恢复能力。即使gt图像有雾,本实施例依然能得到更清晰图像,这也证明本实施例的模型具有强大的去雾能力,适用真实户外环境。
[0156]
为了更准确的评估本发明所提出的方法,本实施例还进行了定量的比较,使用psnr和ssim作为评价指标,在三个数据集上的比较结果如表1所示。在三个测试数据集上,本实施例的模型都具有最高的psnr和ssim,psnr的值分别比次优模型分别高0.48db、0.44db和0.14db。
[0157]
为了验证本发明所提取的这2种先验特征的融合是否有利于在合成数据集训练的模型能更好的迁移到真实场景,本实施例让模型在合成数据集reside上训练2
×
105次迭代,然后直接在ots、o-haze数据上进行测试,结果如表2所示,表中的先验特征融合都使用先验特征自适应融合模块。在合成数据集上颜色衰减先验并不适用,但2种先验特征都适用于真实数据集,psnr和ssim分别提升0.22db和0.05,证明本模型的设计可以提升模型的迁移能力,让模型能更好的直接迁移到真实世界数据上。并且通过先验特征自适应融合模块进行多特征融合,只有0.07m的参数增加,模型整体的参数量只有8.57m,这保证了模型的轻量性和运行效率,能更好的在真实场景达到快速去雾。
[0158]
表1在三个测试集上的定量对比实验结果
[0159][0160][0161]
表2先验特征对模型迁移能力的影响对比
[0162]
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1