一种古籍识别方法、装置、存储介质及设备与流程
1.本技术涉及图像处理技术领域,尤其涉及一种古籍识别方法、装置、存储介质及设备。
背景技术:
2.众所周知,我国古代的古籍浩如烟海,而古籍又有着特殊的历史背景,属于不可再生性的文化资源,除了具备重要的史料研究价值之外,其本身也是弥足珍贵的稀有文物和艺术品。为了能够在保护古籍文献的同时又可以实现对其的充分利用和学习,古籍数字化便适时地应运而生。
3.目前在进行古籍数字化时,首先是将古籍扫描成电子图像,然后采用单字检测识别技术对该图像进行识别,得到古籍的识别结果。但是由于古籍版式复杂,除了不同于如今书籍的先从左到左、再从上到下的常规排版方式外,在每行字中间还常常夹有批注,这就使得现有的图像识别方法对古籍图像的识别效果不佳。并且,由于目前采用的单字检测识别技术在检测时,又并未考虑各个单字之间的位置关系,也导致最终的识别结果不够准确,即,无法得到准确性更高的古籍识别结果。
技术实现要素:
4.本技术实施例的主要目的在于提供一种古籍识别方法、装置、存储介质及设备,能够通过将古籍图像中单字的位置和内容,与文本行的位置和文字阅读方向进行聚合,提高识别效果,进而得到准确性更高的古籍识别结果。
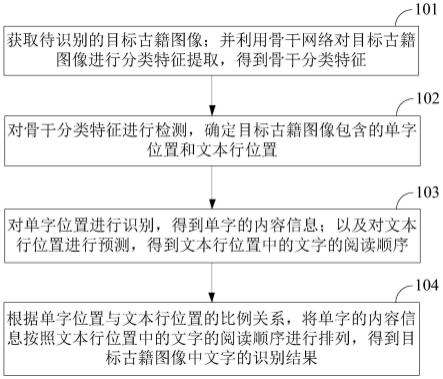
5.本技术实施例提供了一种古籍识别方法,包括:
6.获取待识别的目标古籍图像;并利用骨干网络对所述目标古籍图像进行分类特征提取,得到骨干分类特征;
7.对所述骨干分类特征进行检测,确定所述目标古籍图像包含的单字位置和文本行位置;
8.对所述单字位置进行识别,得到单字的内容信息;以及对所述文本行位置进行预测,得到所述文本行位置中的文字的阅读顺序;
9.根据所述单字位置与所述文本行位置的比例关系,将所述单字的内容信息按照所述文本行位置中的文字的阅读顺序进行排列,得到所述目标古籍图像中文字的识别结果。
10.一种可能的实现方式中,所述对所述骨干分类特征进行检测,确定所述目标古籍图像包含的单字位置,包括:
11.将所述骨干分类特征输入卷积层,得到单字概率特征图和背景阈值特征图;
12.根据所述单字概率特征图和背景阈值特征图,确定所述目标估计图像中每一像素点属于单字的概率和属于背景的概率;
13.根据所述每一像素点属于单字的概率和属于背景的概率,通过取连通域的方式,确定每个单字的最小外接矩形,作为每个单字对应的单字位置。
14.一种可能的实现方式中,所述对所述单字位置进行识别,得到单字的内容信息,包括:
15.从所述目标古籍图像中,裁剪出所述单字位置对应的单字图像区域;
16.利用神经网络分类器,对所述单字图像区域中的单字进行识别,得到单字对应的内容信息。
17.一种可能的实现方式中,所述对所述文本行位置进行预测,得到所述文本行位置中的文字的阅读顺序,包括:
18.对所述文本行位置进行预测,得到对应的文字区域掩膜图像;
19.根据所述文字区域掩膜图像,预测出所述文本行位置中文本区域内的文字的阅读顺序。
20.一种可能的实现方式中,所述对所述文本行位置进行预测,得到所述文本行位置中的文字的阅读顺序,包括:
21.将所述文本行位置切分成预设尺寸的正方形,并依次连接各个所述正方形的中点,得到所述文本行位置中文本区域内的文字的阅读顺序。
22.一种可能的实现方式中,所述根据所述单字位置与所述文本行位置的比例关系,将所述单字的内容信息按照所述文本行位置中的文字的阅读顺序进行排列,得到所述目标古籍图像中文字的识别结果,包括:
23.计算所述单字位置与所述文本行位置的交集面积;并计算所述交集面积与所述单字位置之间的比值;
24.当所述比值满足预设条件时,将所述单字位置中单字的内容信息按照所述文本行位置中的文字的阅读顺序进行排列,得到所述目标古籍图像中文字的识别结果。
25.一种可能的实现方式中,所述方法还包括:
26.接收对所述单字的内容信息的修正操作,得到单字对应的修正后的内容信息。
27.本技术实施例还提供了一种古籍识别装置,所述装置包括:
28.获取单元,用于获取待识别的目标古籍图像;并利用骨干网络对所述目标古籍图像进行分类特征提取,得到骨干分类特征;
29.检测单元,用于对所述骨干分类特征进行检测,确定所述目标古籍图像包含的单字位置和文本行位置;
30.识别单元,用于对所述单字位置进行识别,得到单字的内容信息;以及对所述文本行位置进行预测,得到所述文本行位置中的文字的阅读顺序;
31.排列单元,用于根据所述单字位置与所述文本行位置的比例关系,将所述单字的内容信息按照所述文本行位置中的文字的阅读顺序进行排列,得到所述目标古籍图像中文字的识别结果。
32.一种可能的实现方式中,所述检测单元包括:
33.输入子单元,用于将所述骨干分类特征输入卷积层,得到单字概率特征图和背景阈值特征图;
34.第一确定子单元,用于根据所述单字概率特征图和背景阈值特征图,确定所述目标估计图像中每一像素点属于单字的概率和属于背景的概率;
35.第一确定子单元,用于根据所述每一像素点属于单字的概率和属于背景的概率,
通过取连通域的方式,确定每个单字的最小外接矩形,作为每个单字对应的单字位置。
36.一种可能的实现方式中,所述识别单元包括:
37.裁剪子单元,用于从所述目标古籍图像中,裁剪出所述单字位置对应的单字图像区域;
38.识别子单元,用于利用神经网络分类器,对所述单字图像区域中的单字进行识别,得到单字对应的内容信息。
39.一种可能的实现方式中,所述识别单元包括:
40.第一预测子单元,用于对所述文本行位置进行预测,得到对应的文字区域掩膜图像;
41.第二预测子单元,用于根据所述文字区域掩膜图像,预测出所述文本行位置中文本区域内的文字的阅读顺序。
42.一种可能的实现方式中,所述识别单元具体用于:
43.将所述文本行位置切分成预设尺寸的正方形,并依次连接各个所述正方形的中点,得到所述文本行位置中文本区域内的文字的阅读顺序。
44.一种可能的实现方式中,所述排列单元包括:
45.计算子单元,用于计算所述单字位置与所述文本行位置的交集面积;并计算所述交集面积与所述单字位置之间的比值;
46.排列子单元,用于当所述比值满足预设条件时,将所述单字位置中单字的内容信息按照所述文本行位置中的文字的阅读顺序进行排列,得到所述目标古籍图像中文字的识别结果。
47.一种可能的实现方式中,所述装置还包括:
48.接收单元,用于接收对所述单字的内容信息的修正操作,得到单字对应的修正后的内容信息。
49.本技术实施例还提供了一种古籍识别设备,包括:处理器、存储器、系统总线;
50.所述处理器以及所述存储器通过所述系统总线相连;
51.所述存储器用于存储一个或多个程序,所述一个或多个程序包括指令,所述指令当被所述处理器执行时使所述处理器执行上述古籍识别方法中的任意一种实现方式。
52.本技术实施例还提供了一种计算机可读存储介质,所述计算机可读存储介质中存储有指令,当所述指令在终端设备上运行时,使得所述终端设备执行上述古籍识别方法中的任意一种实现方式。
53.本技术实施例提供的一种古籍识别方法、装置、存储介质及设备,首先获取待识别的目标古籍图像;并利用骨干网络对目标古籍图像进行分类特征提取,得到骨干分类特征,然后对骨干分类特征进行检测,确定目标古籍图像包含的单字位置和文本行位置;接着,对单字位置进行识别,得到单字的内容信息;以及对文本行位置进行预测,得到文本行位置中的文字的阅读顺序,进而可以根据单字位置与文本行位置的比例关系,将单字的内容信息按照文本行位置中的文字的阅读顺序进行排列,得到目标古籍图像中文字的识别结果。可见,由于本技术实施例是通过将古籍图像中单字的位置和内容,与文本行的位置和文字阅读方向进行聚合,从而提高识别效果,并且由于进行古籍图像识别时,充分考虑了各个单字之间的位置关系以及文本行中文字的阅读顺序,相比现有识别方法,大幅度提高了识别准
确率和识别效率。
附图说明
54.为了更清楚地说明本技术实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本技术的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
55.图1为本技术实施例提供的一种古籍识别方法的流程示意图;
56.图2为本技术实施例提供的文本行位置检测过程的示意图;
57.图3为本技术实施例提供的文本行位置中文字的阅读顺序预测过程的示例图之一;
58.图4为本技术实施例提供的文本行位置中文字的阅读顺序预测过程的示例图之二;
59.图5为本技术实施例提供的将单字的内容信息按照文本行位置中的文字的阅读顺序进行排列的示例图;
60.图6为本技术实施例提供的古籍识别的整体示例图;
61.图7为本技术实施例提供的一种古籍识别装置的组成示意图。
具体实施方式
62.目前在进行图像识别时,通常会采用光学字符识别(optical character recognition,简称ocr)识别技术,而现有的ocr识别技术主要是采用文本行的检测技术,以及基于crnn网络模型和transformer网络模型的文本行识别技术。虽然该技术能够实现对文本行较为准确的识别,但其针对的识别对象通常是常规排版方式的文字图像。而古籍中的文字版式通常较为复杂,除了不同于如今书籍的先从左到左、再从上到下的常规排版方式外,在每行字中间还常常夹有批注,这就使得现有的ocr识别技术对古籍图像的识别效果不佳,甚至失效。
63.由此,为了更好的实现古籍的数字化,目前采用的识别方案通常是单字检测识别技术,但该单字检测识别技术在进行古籍图像检测时,又并未考虑各个单字之间的位置关系,也导致最终的识别结果不够准确,即,无法得到准确性更高的古籍识别结果
64.为解决上述缺陷,本技术提供了一种古籍识别方法,首先获取待识别的目标古籍图像;并利用骨干网络对目标古籍图像进行分类特征提取,得到骨干分类特征,然后对骨干分类特征进行检测,确定目标古籍图像包含的单字位置和文本行位置;接着,对单字位置进行识别,得到单字的内容信息;以及对文本行位置进行预测,得到文本行位置中的文字的阅读顺序,进而可以根据单字位置与文本行位置的比例关系,将单字的内容信息按照文本行位置中的文字的阅读顺序进行排列,得到目标古籍图像中文字的识别结果。可见,由于本技术实施例是通过将古籍图像中单字的位置和内容,与文本行的位置和文字阅读方向进行聚合,从而提高识别效果,并且由于进行图像识别时,充分考虑了各个单字之间的位置关系以及文本行中文字的阅读顺序,相比现有识别方法,大幅度提高了识别准确率和识别效率。
65.为使本技术实施例的目的、技术方案和优点更加清楚,下面将结合本技术实施例
中的附图,对本技术实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本技术一部分实施例,而不是全部的实施例。基于本技术中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本技术保护的范围。
66.第一实施例
67.参见图1,为本实施例提供的一种古籍识别方法的流程示意图,该方法包括以下步骤:
68.s101:获取待识别的目标古籍图像;并利用骨干网络对目标古籍图像进行分类特征提取,得到骨干分类特征。
69.在本实施例中,将采用本实施例进行文本识别的任一古籍图像定义为目标古籍图像。并且,需要说明的是,本实施例不限制目标古籍图像的类型,比如,目标古籍图像可以是由红(r)、绿(g)、蓝(b)三原色组成的彩色图像、也可以是灰度图像等。
70.并且,本实施例对目标古籍图像的获取方式也不做限定,目标古籍图像可以根据实际需要,通过扫描、拍摄等方式获得,例如,可以将利用扫描设备将古籍扫描成的电子图像保存为目标古籍图像,或者可以将利用相机拍摄到的包含文字的古籍图像作为目标古籍图像等。
71.进一步的,在获取到目标古籍图像后,可以利用现有或未来出现的骨干网络(backbone),比如vgg(visual geometry group network)网络模型或深度残差网络(deep residual network,简称resnet)等,采用基于分割的方法,对目标古籍图像进行单字和文本行检测,以得到骨干分类特征(即利用backbone部分提取出的特征),再通过执行后续步骤s102-s104,实现对该目标古籍图像的精准识别。
72.s102:对骨干分类特征进行检测,确定目标古籍图像包含的单字位置和文本行位置。
73.在本实施例中,通过步骤s101获取到目标古籍图像对应的骨干分类特征后,为了能够更准确的将单字的位置和内容与文本行的位置和文字阅读方向进行聚合,以得到准确性更高的识别结果,进一步的,还需要再单字位置和文本行位置检测时,共享骨干分类特征,即,分别通过对骨干分类特征进行检测,确定出目标古籍图像包含的单字位置和文本行位置,用以执行后续步骤s103。
74.具体来讲,一种可选的实现方式是,本步骤s102中“对骨干分类特征进行检测,确定目标古籍图像包含的单字位置”的实现过程具体可以包括下述步骤a1-a3:
75.步骤a1:将骨干分类特征输入卷积层,得到单字概率特征图和背景阈值特征图。
76.在本实现方式是中,为了能够在进行目标古籍图像识别时,考虑到各个单字之间的位置关系,以提高最终识别结果的准确性,在获取到目标古籍图像的骨干分类特征后,还需要将其输入网络层,实现对目标古籍图像中各个单字的定位和分类,即判定出目标古籍图像中各个像素点是属于单字还是属于图像背景。具体来讲,可以将骨干分类特征输入卷积层(具体层数不限,可根据实际情况训练得到)进行预测,以得到单字概率特征图和背景阈值特征图,如图2上方的“单字位置检测过程”所示,将骨干分类特征输入卷积层后,可以预测出单字概率特征图“prob_map”和背景阈值特征图“thresh_map”,且其中特征图上方的n表示通过卷积层一次性处理的目标古籍图像的个数;1表示单字概率特征图“prob_map”和背景阈值特征图“thresh_map”所在的待识别特征向量对应的通道数(channel)为1维,h表
示该对应待识别特征向量的高度(height),w表示对应待识别特征向量的宽度(width)。
77.步骤a2:根据单字概率特征图和背景阈值特征图,确定目标估计图像中每一像素点属于单字的概率和属于背景的概率。
78.通过步骤a1将骨干分类特征输入卷积层,得到单字概率特征图和背景阈值特征图后,进一步可以通过对单字概率特征图和背景阈值特征图进行处理,遍历目标古籍图像上的每一个像素点,并分别确定出每一像素点属于“古籍单字”的概率和属于图像背景的概率,用以执行后续步骤a3。
79.步骤a3:根据每一像素点属于单字的概率和属于背景的概率,通过取连通域的方式,确定每个单字的最小外接矩形,作为每个单字对应的单字位置。
80.通过步骤a2确定出每一像素点属于“古籍单字”的概率和属于图像背景的概率后,进一步可以通过比较二者的大小,判断出每一像素点是属于“古籍单字”还是图像背景,即,当像素点属于“古籍单字”的概率大于属于图像背景的概率时,则判定像素点属于“古籍单字”;反之,当像素点属于图像背景的概率大于属于“古籍单字”的概率时,则判定像素点是属于图像背景的。
81.在此基础上,进一步可以采用取连通域的方式,确定出目标古籍图像中每个“古籍单字”的最小外接矩形,如图2上方图中所示的在进行连通域分析后得到的各个“小方块”,作为每个单字对应的单字位置,用以执行后续步骤s103。
82.类似的,为了提高最终识别结果的准确性,在获取到目标古籍图像的骨干分类特征后,还需要将其输入与单字位置检测时类似的网络层,但是区别在于更强调对文本行粒度的学习,所以需要增加一个文本行粒度的输出网络层,实现对目标古籍图像中各个文本行的定位和分类,即判定出目标古籍图像中各个像素点是属于文本行位置还是属于图像背景。具体来讲,可以将骨干分类特征输入卷积层(具体层数不限,可根据实际情况训练得到)进行预测,以得到文本行概率特征图和背景阈值特征图,如图2下方的“文本行位置检测过程”所示,将骨干分类特征输入卷积层后,可以预测出文本行概率特征图“prob_map”和背景阈值特征图“thresh_map”,同理,其中特征图上方的n表示通过卷积层一次性处理的目标古籍图像的个数;1表示文本行概率特征图“prob_map”和背景阈值特征图“thresh_map”所在的待识别特征向量对应的通道数(channel)为1维,h表示该对应待识别特征向量的高度(height),w表示对应待识别特征向量的宽度(width)。具体实现过程也可参照上述步骤a1-a3实现,在此不再赘述。需要说明的是,相比于传统的只采用单字检测识别的技术,本技术整体识别过程增加的耗时较少,仅约为20%左右,但却提供了文本行粒度的位置信息和,从而在通过后续步骤处理后,能够大幅度提高古籍识别结果的准确性。
83.还需要说明的是,对于本步骤中确定目标古籍图像包含的单字位置和文本行位置的具体实现过程,均可采用预先训练好的单字检测网络模型和文本行位置检测网络模型来实现,且这两个模型在网络结构上可以完全一致,区别仅在于二者学习到的网络参数不同,具体模型训练过程在此不再赘述。
84.s103:对单字位置进行识别,得到单字的内容信息;以及对文本行位置进行预测,得到文本行位置中的文字的阅读顺序。
85.在本实施例中,通过步骤s102确定出目标古籍图像包含的单字位置和文本行位置后,为了能够更准确的将单字的位置和内容,与文本行的位置和文字阅读方向进行聚合,以
得到准确性更高的识别结果,进一步的,还需要对目标古籍图像中的单字位置进行识别,以确定出单字的内容信息;以及,对目标古籍图像中的文本行位置进行预测,以预测出文本行位置中的文字的阅读顺序(即阅读方向),用以执行后续步骤s104。
86.具体来讲,一种可选的实现方式是,本步骤s103中“对单字位置进行识别,得到单字的内容信息”的实现过程具体可以包括:首先,从目标古籍图像中,裁剪出单字位置对应的单字图像区域;然后再利用神经网络分类器,对单字图像区域中的单字进行识别,得到单字对应的内容信息。
87.在本实现方式中,为了提高识别结果的准确性。在获取到单字位置后,进一步可以利用现有或未来出现的单字检测方法,对获取的单字位置进行检测,具体为从目标古籍图像中裁剪(crop)出单字位置对应的单字图像区域,比如,可以从目标古籍图像中裁剪出如图2上方图中所示的通过连通域分析后得到的各个“小方块”。然后,再利用神经网络分类器,如卷积神经网络(convolutional neural networks,简称cnn)等,对每个裁剪图像中的单字进行识别,得到各个单字对应的内容信息,用以执行后续步骤s104。
88.另外,由于古籍中可能会存在一些现代人基本不会使用的字,或者是其他不符合常规标准的字,对此,一种可选的实现方式是,在利用识别模型识别出单字对应的内容信息后,为了提高识别结果的准确性,还可以接收专家人工对单字的内容信息的修正操作,得到单字对应的修正后的内容信息,然后再利用修正后的单字信息对识别模型进行重复训练,在经过多轮迭代训练后,可以得到准确率满足预设需求(可根据实际情况进行设定,比如可以设定为识别准确率达到90%以上等)的识别模型,用以识别出更高的单字对应的准确性更高的内容信息。
89.另一种可选的实现方式是,上述步骤s103中“对文本行位置进行预测,得到文本行位置中的文字的阅读顺序”的实现过程具体可以包括:首先,对文本行位置进行预测,得到对应的文字区域掩膜(mask)图像;然后再根据文字区域掩膜图像,预测出文本行位置中文本区域内的文字的阅读顺序。其中,可以认为文字区域掩膜(mask)图像是利用涂抹和复原引擎分离出来的文本行的前景图像。
90.在本实现方式中,为了提高识别结果的准确性。在获取到文本行位置后,进一步可以利用现有或未来出现的获取文本行的文字区域掩膜图像的方法,对获取的单字位置进行处理,比如,可以利用涂抹和复原引擎分离出文本行的前景图像作为文本行的文字区域掩膜图像,进而可以根据文字区域掩膜图像的识别结果,预测出对应文本行位置中文本区域内的文字方向,即文字的阅读顺序,用以执行后续步骤s104。
91.并且,一种可选的实现方式是,还可以将文本行位置切分成预设尺寸的正方形,并依次连接各个正方形的中点,得到文本行位置中文本区域内的文字的阅读顺序,如图3所示,图中的箭头指示方向代表了该文本行中文字的阅读顺序。同时,在实际的预测网络中,还需要预测出文本行中的文字方向偏移量,且该偏移量的标注是根据文本行标注生成的,如图4所示,结合文字方向偏移量,可以更为准确的预测出该文本行中文字的阅读顺序。
92.s104:根据单字位置与文本行位置的比例关系,将单字的内容信息按照文本行位置中的文字的阅读顺序进行排列,得到目标古籍图像中文字的识别结果。
93.需要说明的是,由于古籍中文字并不是完全按照从上至下的排列方式进行排列,所以对于单字的检测直接进行规则上的位置排序得到的不一定是符合正确语义的结果。所
以,在本实施例中,在通过步骤s103确定出单字的内容信息和文本行位置中的文字的阅读顺序后,进一步可以将单字的内容信息和文本行位置及文字的阅读顺序进行融合识别,以得到准确性更高的古籍识别结果。
94.具体来讲,一种可选的实现方式是,步骤s104的具体实现过程可以包括下述步骤b1-b2:
95.步骤b1:计算单字位置与文本行位置的交集面积;并计算交集面积与单字位置之间的比值。
96.在本实现方式是中,为了能够提高最终识别结果的准确性,在确定出目标古籍图像的单字位置与文本行位置后,进一步可以通过对二者的位置关系进行处理,以确定出单字位置是否属于该文本行位置,即,确定出单字位置中的单字是否属于该文本行,具体的,可以先计算出单字位置与文本行位置的交集面积,然后再计算出该交集面积与单字位置所在面积之间的比值,用以执行后续步骤b2。
97.步骤b2:当比值满足预设条件时,将单字位置中单字的内容信息按照文本行位置中的文字的阅读顺序进行排列,得到目标古籍图像中文字的识别结果。
98.通过步骤b1计算出单字位置与文本行位置的交集面积,与单字位置之间的比值后,进一步可以判断该比值是否满足预设条件,其中,预设条件的具体取值可根据实际情况进行设定,本技术实施例不进行限定,比如可以将预设条件设定为比值不小于0.5等。这样,当判断出该比值满足预设条件时,如该比值大于0.5时,表明该单字位置是属于该文本行位置的,进而可以将单字位置中单字的内容信息按照文本行位置中的文字的阅读顺序进行排列,得到该文本行中的文字识别结果,进而可以得到目标古籍图像中所有文字按照文本行进行排序的识别结果。
99.举例说明:如图5所示,通过上述步骤s102-s103,可以确定出左侧图中的“某”、“虢”、“官”、“船”、“舷”这5个单字对应的单字位置所在的“小方框”,以及可以确定出文本行位置所在的“长方框”。并且还可以确定出该文本行位置中的文字的阅读顺序如右侧图中的箭头所示方向。进而可以计算出这5个单字各自所在的“小方框”与该文本行位置所在的“长方框”之间的交集面积。接着,再通过判断该交集面积与单字位置之间的比值是否满足预设条件,来确定出该单字位置是否属于该文本行。
100.例如,假设预设条件为当单字位置与文本行位置的交集面积,与单字位置之间的比值不小于0.5时,可以确定单字位置是属于该文本行位置的,并可以将属于该文本行位置的单字位置中单字的内容信息,按照该文本行位置中的文字的阅读顺序进行排列。此时,若计算出“某”、“虢”、“官”、“船”、“舷”这5个单字对应的单字位置所在的“小方框”与该文本行位置所在的“长方框”之间的交集面积,与各个单字位置的比值均大于0.5,即,比值均满足预设条件,则进一步的,可以将这5个单字按照该文本行位置中的文字的阅读顺序(即右侧图中的箭头所示方向)进行排列,即,将“某”、“虢”、“官”、“船”、“舷”这5个单字连接成“某虢官船舷”,作为图5所示目标古籍图像中文字的最终识别结果。
101.这样,在利用上述步骤s101-s104进行古籍图像识别时,充分考虑了图像中各个古籍单字之间的位置关系以及文本行中文字的阅读顺序,通过将目标古籍图像中单字的位置和内容,与文本行的位置和文字阅读方向进行聚合,使得属于同一个文本行的单字分到同一个文本行所在位置中,且单字的内容信息是按照文本行位置中的文字的阅读顺序进行排
列,从而能够得到准确性更高的识别结果。
102.举例说明:如图6所示,其示出了本技术实施例提供的古籍识别过程的整体示例图。在具体的识别过程中,首先,将目标古籍图像输入resnet和特征金字塔网络(fpn)结构(用于不同尺度特征的融合处理)构成的骨干网络中,得到骨干分类特征。然后,将该骨干分类特征分别输入单字检测网络和文本行位置检测网络模型,进行单字位置检测和文本行位置检测。接着,可以对检测出的单字位置进行识别,得到单字的内容信息,如图6中的“獨”、“感”、“夫”、“古”、“今”、“宙”、“之”、“變”。以对检测出的文本行位置进行预测,得到各个文本行位置中的文字的阅读顺序,如图6中的箭头所示。进而可以将识别得到的“獨”、“感”、“夫”、“古”、“今”、“宙”、“之”、“變”等单字内容信息按照各自所属文本行中文字的阅读顺序进行排列,得到融合识别结果,如图6最右侧下方图所示。具体识别实现过程可参见上述步骤s101-s104的详细介绍,在此不再赘述。
103.综上,本实施例提供的一种古籍识别方法,首先获取待识别的目标古籍图像;并利用骨干网络对目标古籍图像进行分类特征提取,得到骨干分类特征,然后对骨干分类特征进行检测,确定目标古籍图像包含的单字位置和文本行位置;接着,对单字位置进行识别,得到单字的内容信息;以及对文本行位置进行预测,得到文本行位置中的文字的阅读顺序,进而可以根据单字位置与文本行位置的比例关系,将单字的内容信息按照文本行位置中的文字的阅读顺序进行排列,得到目标古籍图像中文字的识别结果。可见,由于本技术实施例是通过将古籍图像中单字的位置和内容,与文本行的位置和文字阅读方向进行聚合,从而提高识别效果,并且由于进行古籍图像识别时,充分考虑了各个单字之间的位置关系以及文本行中文字的阅读顺序,相比现有识别方法,大幅度提高了识别准确率和识别效率。
104.第二实施例
105.本实施例将对一种古籍识别装置进行介绍,相关内容请参见上述方法实施例。
106.参见图7,为本实施例提供的一种古籍识别装置的组成示意图,该装置700包括:
107.获取单元701,用于获取待识别的目标古籍图像;并利用骨干网络对所述目标古籍图像进行分类特征提取,得到骨干分类特征;
108.检测单元702,用于对所述骨干分类特征进行检测,确定所述目标古籍图像包含的单字位置和文本行位置;
109.识别单元703,用于对所述单字位置进行识别,得到单字的内容信息;以及对所述文本行位置进行预测,得到所述文本行位置中的文字的阅读顺序;
110.排列单元704,用于根据所述单字位置与所述文本行位置的比例关系,将所述单字的内容信息按照所述文本行位置中的文字的阅读顺序进行排列,得到所述目标古籍图像中文字的识别结果。
111.在本实施例的一种实现方式中,所述检测单元702包括:
112.输入子单元,用于将所述骨干分类特征输入卷积层,得到单字概率特征图和背景阈值特征图;
113.第一确定子单元,用于根据所述单字概率特征图和背景阈值特征图,确定所述目标估计图像中每一像素点属于单字的概率和属于背景的概率;
114.第一确定子单元,用于根据所述每一像素点属于单字的概率和属于背景的概率,通过取连通域的方式,确定每个单字的最小外接矩形,作为每个单字对应的单字位置。
115.在本实施例的一种实现方式中,所述识别单元703包括:
116.裁剪子单元,用于从所述目标古籍图像中,裁剪出所述单字位置对应的单字图像区域;
117.识别子单元,用于利用神经网络分类器,对所述单字图像区域中的单字进行识别,得到单字对应的内容信息。
118.在本实施例的一种实现方式中,所述识别单元703包括:
119.第一预测子单元,用于对所述文本行位置进行预测,得到对应的文字区域掩膜图像;
120.第二预测子单元,用于根据所述文字区域掩膜图像,预测出所述文本行位置中文本区域内的文字的阅读顺序。
121.在本实施例的一种实现方式中,所述识别单元703具体用于:
122.将所述文本行位置切分成预设尺寸的正方形,并依次连接各个所述正方形的中点,得到所述文本行位置中文本区域内的文字的阅读顺序。
123.在本实施例的一种实现方式中,所述排列单元704包括:
124.计算子单元,用于计算所述单字位置与所述文本行位置的交集面积;并计算所述交集面积与所述单字位置之间的比值;
125.排列子单元,用于当所述比值满足预设条件时,将所述单字位置中单字的内容信息按照所述文本行位置中的文字的阅读顺序进行排列,得到所述目标古籍图像中文字的识别结果。
126.在本实施例的一种实现方式中,所述装置还包括:
127.接收单元,用于接收对所述单字的内容信息的修正操作,得到单字对应的修正后的内容信息。
128.进一步地,本技术实施例还提供了一种古籍识别设备,包括:处理器、存储器、系统总线;
129.所述处理器以及所述存储器通过所述系统总线相连;
130.所述存储器用于存储一个或多个程序,所述一个或多个程序包括指令,所述指令当被所述处理器执行时使所述处理器执行上述古籍识别方法的任一种实现方法。
131.进一步地,本技术实施例还提供了一种计算机可读存储介质,所述计算机可读存储介质中存储有指令,当所述指令在终端设备上运行时,使得所述终端设备执行上述古籍识别方法的任一种实现方法。
132.通过以上的实施方式的描述可知,本领域的技术人员可以清楚地了解到上述实施例方法中的全部或部分步骤可借助软件加必需的通用硬件平台的方式来实现。基于这样的理解,本技术的技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品可以存储在存储介质中,如rom/ram、磁碟、光盘等,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者诸如媒体网关等网络通信设备,等等)执行本技术各个实施例或者实施例的某些部分所述的方法。
133.需要说明的是,本说明书中各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似部分互相参见即可。对于实施例公开的装置而言,由于其与实施例公开的方法相对应,所以描述的比较简单,相关之处
参见方法部分说明即可。
134.还需要说明的是,在本文中,诸如第一和第二等之类的关系术语仅仅用来将一个实体或者操作与另一个实体或操作区分开来,而不一定要求或者暗示这些实体或操作之间存在任何这种实际的关系或者顺序。而且,术语“包括”、“包含”或者其任何其他变体意在涵盖非排他性的包含,从而使得包括一系列要素的过程、方法、物品或者设备不仅包括那些要素,而且还包括没有明确列出的其他要素,或者是还包括为这种过程、方法、物品或者设备所固有的要素。在没有更多限制的情况下,由语句“包括一个
……”
限定的要素,并不排除在包括所述要素的过程、方法、物品或者设备中还存在另外的相同要素。
135.对所公开的实施例的上述说明,使本领域专业技术人员能够实现或使用本技术。对这些实施例的多种修改对本领域的专业技术人员来说将是显而易见的,本文中所定义的一般原理可以在不脱离本技术的精神或范围的情况下,在其它实施例中实现。因此,本技术将不会被限制于本文所示的这些实施例,而是要符合与本文所公开的原理和新颖特点相一致的最宽的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1