基于机器视觉的塑件外观缺陷识别与定位方法与流程
1.本发明涉及工业产品外观缺陷识别与定位方法,涉及外观检测领域。
背景技术:
2.制造行业每天都要生产大量的工业产品。用户和生产企业对产品质量的要求越来越高,除要求满足使用性能外,还要有良好的外观,即良好的表面质量。但是,在制造产品的过程中,个别产品表面出现缺陷往往是不可避免的。人工检测是产品外观缺陷的传统检测方法,该方法拥有着抽检率低、准确性不高、实时性差、效率低、劳动强度大、受人工经验和主观因素的影响大等的缺点。随着深度学习的不断发展,卷积神经网络被不断地应用于工业生产之中,基于机器视觉的检测方法可以很大程度上克服人工检测的弊端,对于企业提高产品质量和生产效率有着十分重要的意义。
技术实现要素:
3.本发明的目的是为了解决现有外观缺陷检测手段效率低的问题,提出了基于机器视觉的塑件外观缺陷识别与定位方法。
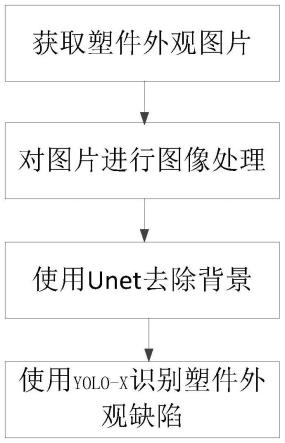
4.基于机器视觉的塑件外观缺陷识别与定位方法,所述方法包括以下步骤:
5.步骤1、对含有塑件的图像数据集进行处理,得到塑件和背景的边缘均光滑且塑件和背景上均无噪声的图像数据集;
6.步骤2、剔除步骤1得到的图像数据集中的背景,得到边缘光滑且无噪声的塑件图像数据集;
7.步骤3、将步骤2得到的边缘光滑且无噪声的塑件图像数据集和步骤1得到的图像数据集输入至unet中进行训练,得到训练好的unet模型;
8.步骤4、标注出边缘光滑且无噪声的塑件图像数据集中每个图像的外观缺陷位置及外观缺陷类别,得到标注后的文件;
9.步骤5、将边缘光滑且无噪声的塑件图像数据集和标注后的文件输入至yolo-x网络中进行训练,得到训练好的yolo-x模型;
10.步骤6、将待检测的含有塑件的图像数据集输入至训练好的unet模型中,输出待检测的边缘光滑且无噪声的塑件图像数据集;
11.步骤7、将待检测的边缘光滑且无噪声的塑件图像数据集输入至训练好的yolo-x模型中,输出塑件的外观缺陷位置及类别。
12.优选地,步骤5中,得到训练好的yolo-x模型,具体过程为:
13.步骤51、将边缘光滑且无噪声的塑件图像数据集和标注后的文件输入到cspdarknet网络中,标注后的文件包括多个xml文件,边缘光滑且无噪声的塑件图像数据集包括多个rgb图片;
14.每个rgb图片均为三通道,对应三个数组,采用隔行采样的方式,将每个通道拆分成四个新通道,一个rgb图片被拆分成十二个新通道,对每个rgb图片的每个新通道同时连
续进行四次卷积操作,取后三次卷积操作的输出,三次卷积操作的输出分别为f1、f2和f3;
15.步骤52、将f3经过一个1*1的卷积进行通道数的调整后,得到p3,将p3进行上采样操作,并与f2结合,再使用csplayer网络进行特征提取获得fp4,将fp4经过一个1*1的卷积进行通道数的调整后,得到p2,将p2与f1结合,得到fp1,作为第一个目标特征;
16.将fp1进行下采样之后,与p2结合,使用csplayer网络进行特征提取得到第二个目标特征fp2;
17.将fp2进行下采样之后,与p3结合,使用csplayer网络进行特征提取得到第三个目标特征fp3;
18.步骤53、对fp1、fp2和fp3分别进行处理,处理过程均为:先使用一个1*1的卷积层将fp1、fp2或fp3的通道数调整为256,构建两路256通道,对第一路的256通道进行两次参数不同的卷积操作后,再进行一次1*1的卷积层来调整通道数,得到一种预测结果;对第二路的256通道进行两次参数不同的卷积操作后,根据得到的结果构建两路结果,两路结果各进行一次1*1的卷积层来调整通道数,各得到一种预测结果;对fp1、fp2和fp3各自处理后各得到三种预测结果,对三种预测结果进行堆叠,获得一个预测框,fp1、fp2和fp3对应三个预测框,对三个预测框进行非极大值抑制,从三个预测框中筛选出最佳预测框,根据最佳预测框和一个xml文件对应的多个标注值得到一个loss值,loss值越接近0,则此时的yolo-x网络为训练好的yolo-x模型。
19.优选地,f1为(80,80,256),表示256个行数为80列数为80的数组;
20.f2为(40,40,512),表示512个行数为40列数为40的数组;
21.f3为(20,20,1024),表示1024个行数为20列数为20的数组。
22.优选地,步骤3中,得到训练好的unet模型,具体过程为:
23.步骤31、unet中包括下采样和上采样,下采样和上采样各包括多个维度,每个维度均包括多个卷积层,每个卷积层用于进行卷积处理;
24.将步骤2得到的边缘光滑且无噪声的塑件图像数据集输入至unet下采样中,在下采样中依次进入下采样的第一维度、第一个bn层、下采样的第二维度、第二个bn层、下采样的第三维度、第三个bn层、下采样的第四维度和下采样的第五维度,且在下采样的第一维度和下采样的第二维度中均进行了f+2次卷积处理,在下采样的第三维度中均进行了f+1次卷积处理,在下采样的第四维度和下采样的第五维度均进行了f次卷积处理,f为大于等于0的正整数;
25.步骤32、在下采样的第五个维度中进行f次卷积处理后,依次进入上采样中的第一维度、上采样中的第二维度、第四个bn层、上采样中的第三维度、第五个bn层、上采样中的第四维度和第六个bn层,且在上采样中的第一维度进行f次卷积处理,在上采样中的第二维度进行f+1次卷积处理,在上采样中的第三维度和第四维度均进行f+2次卷积处理,经过上采样中的第六个bn层处理后,使用softmax进行归一化处理,得到的数据集能够学习到步骤1得到的图像数据集具备去掉背景得到边缘光滑且无噪声的塑件图像数据集的能力,此时为训练好的unet模型。
26.本发明的有益效果是:
27.本技术分别得到训练好的unet模型和yolo-x模型,然后未知的图像数据集依次经过unet模型和yolo-x模型,从而识别出塑件的缺陷。
28.本技术提出了一种基于机器视觉检测塑件外观缺陷的方法,将语义分割网络unet与目标识别网络yolo-x相结合,对比仅使用yolo-x来说,在使用unet对背景进行去除之后,得到了更好的结果。并且本技术检测外观缺陷的效率与现有相比,效率要高,识别更准确。
附图说明
29.图1为基于机器视觉的塑件外观缺陷识别与定位方法的流程图;
30.图2为特征增强部分流程图。
具体实施方式
31.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
32.需要说明的是,在不冲突的情况下,本发明中的实施例及实施例中的特征可以相互组合。
33.下面结合附图和具体实施例对本发明作进一步说明,但不作为本发明的限定。
34.具体实施方式一:结合图1说明本实施方式,本实施方式所述的基于机器视觉的塑件外观缺陷识别与定位方法,所述方法包括以下步骤:
35.步骤1、对含有塑件的图像数据集进行处理,得到塑件和背景的边缘均光滑且塑件和背景上均无噪声的图像数据集;
36.步骤2、剔除步骤1得到的图像数据集中的背景,得到边缘光滑且无噪声的塑件图像数据集;
37.步骤3、将步骤2得到的边缘光滑且无噪声的塑件图像数据集和步骤1得到的图像数据集输入至unet中进行训练,得到训练好的unet模型;
38.步骤4、标注出边缘光滑且无噪声的塑件图像数据集中每个图像的外观缺陷位置及外观缺陷类别,得到标注后的文件;
39.步骤5、将边缘光滑且无噪声的塑件图像数据集和标注后的文件输入至yolo-x网络中进行训练,得到训练好的yolo-x模型;
40.步骤6、将待检测的含有塑件的图像数据集输入至训练好的unet模型中,输出待检测的边缘光滑且无噪声的塑件图像数据集;
41.步骤7、将待检测的边缘光滑且无噪声的塑件图像数据集输入至训练好的yolo-x模型中,输出塑件的外观缺陷位置及类别。
42.本实施方式中,图像其实是数字信号,在成像的过程中会出现噪声,在实际生活中就是所谓的噪点,噪声也就是背景上和塑件上的反光部分,除了背景上和塑件上的反光部分,其他部分的磨砂滤镜效果也是噪声。
43.本技术中的塑件指工业产品,步骤1是对含有塑件的图像数据集进行去噪声和边缘圆滑处理,含有塑件的图像数据集好比一张图片上既有塑件,又有带有太阳和地面图案的背景,还有除了背景和塑件之外的磨砂滤镜效果的噪声,步骤1先是将噪声、塑件上噪声和背景上噪声均去掉,留下背景和塑件;步骤2是使用imagej对步骤1得到的数据集进行人
工分割将背景从数据集中剔除,只留下塑件;步骤3是使unet学习步骤2得到的边缘光滑且无噪声的塑件图像数据集的去掉背景的分割方式,能够将步骤1得到的图像数据集的背景去掉时,我们认为unet训练好了;步骤4进行人工标注,标注成xml文件,标注的外观缺陷类别划痕、缺损、标签错误与污渍四种类型;步骤5将边缘光滑且无噪声的塑件图像数据集和人工标注的xml文件作为yolo-x的输入,对yolo-x进行训练,获得训练好的yolo-x模型;步骤6是用训练好的unet模型处理待处理的数据集,将该数据集的背景去掉;步骤7是用训练好的yolo-x模型识别步骤6去掉背景只剩下塑件的数据集中塑件的缺陷,及缺陷类别。
44.具体实施方式二:结合图2说明本实施方式,本实施方式是对具体实施方式一所述的基于机器视觉的塑件外观缺陷识别与定位方法进一步限定,在本实施方式中,步骤5中,得到训练好的yolo-x模型,具体过程为:
45.步骤51、将边缘光滑且无噪声的塑件图像数据集和标注后的文件输入到cspdarknet网络中,标注后的文件包括多个xml文件,边缘光滑且无噪声的塑件图像数据集包括多个rgb图片;
46.每个rgb图片均为三通道,对应三个数组,采用隔行采样的方式,将每个通道拆分成四个新通道,一个rgb图片被拆分成十二个新通道,对每个rgb图片的每个新通道同时连续进行四次卷积操作,取后三次卷积操作的输出,三次卷积操作的输出分别为f1、f2和f3;
47.步骤52、将f3经过一个1*1的卷积进行通道数的调整后,得到p3,将p3进行上采样操作,并与f2结合,再使用csplayer网络进行特征提取获得fp4,将fp4经过一个1*1的卷积进行通道数的调整后,得到p2,将p2与f1结合,得到fp1,作为第一个目标特征;
48.将fp1进行下采样之后,与p2结合,使用csplayer网络进行特征提取得到第二个目标特征fp2;
49.将fp2进行下采样之后,与p3结合,使用csplayer网络进行特征提取得到第三个目标特征fp3;
50.步骤53、对fp1、fp2和fp3分别进行处理,处理过程均为:先使用一个1*1的卷积层将fp1、fp2或fp3的通道数调整为256,构建两路256通道,对第一路的256通道进行两次参数不同的卷积操作后,再进行一次1*1的卷积层来调整通道数,得到一种预测结果;对第二路的256通道进行两次参数不同的卷积操作后,根据得到的结果构建两路结果,两路结果各进行一次1*1的卷积层来调整通道数,各得到一种预测结果;对fp1、fp2和fp3各自处理后各得到三种预测结果,对三种预测结果进行堆叠,获得一个预测框,fp1、fp2和fp3对应三个预测框,对三个预测框进行非极大值抑制,从三个预测框中筛选出最佳预测框,根据最佳预测框和一个xml文件对应的多个标注值得到一个loss值,loss值越接近0,则此时的yolo-x网络为训练好的yolo-x模型。
51.本实施方式中,标注值是人工标注的缺陷的预测框的坐标和类别。loss值越小,说明越接近人工标注。我们人工标注的xml文件,是用来在训练过程中进行评判结果好坏的,通过结果好坏来使网络自动调整参数,以达到我们想要的效果。
52.图2中,csplayer为一种结构,叫做csplayer结构,conv表示1*1的卷积。
53.yolo-x网络分为三部分,即特征提取、特征增强和预测特征点。在yolo-x网络训练的过程中,使用cspdarknet作为yolo-x特征提取部分的网络。将640*640的图片输入到cspdarknet[]中,对图片进行focus隔行采样拼接,使输入通道从三通道扩充到十二通道。
并在此基础上,进行了连续四次卷积操作,并在每次卷积操作后使用cspnet进行优化,通过适当地增加网络的深度来提高准确率,并在内部的残差块使用了跳跃连接,缓解了在深度神经网络中增加深度带来的梯度消失问题。在最后一次卷积操作中加入spp结构,通过不同池化核大小的最大池化进行特征提取,提高网络的感受野。并取后三次卷积操作的输出作为特征增强部分的输入,三次卷积操作的输出f1、f2、f3的shape分别为(80,80,256)、(40,40,512)、(20,20,1024)。
[0054]
在特征增强部分,使用了fpn特征金字塔来增强特征提取。将f3经过一个1*1的卷积进行通道数的调整后,得到p3。再进行一个上采样操作,并与f2结合,再次使用csplayer进行特征提取获得fp4。将fp4经过一个1*1的卷积进行通道数的调整后,得到p2。经过相同的操作与f1结合,得到fp1,从而得到特征增强的一个输出。将fp1进行下采样之后,与p2相结合,使用csplayer进行特征提取得到特征增强的第二个输出fp2。将fp2进行下采样之后,与p3相结合,使用csplayer进行特征提取得到特征增强的第三个输出fp3。
[0055]
最后对特征增强的结果进行预测,分为三个部分,即确定预测框、判断预测框中是否存在缺陷和辨别预测框中缺陷的种类。通过对与测测结果的解码,以得到却显得预测信息。
[0056]
具体实施方式三:本实施方式是对具体实施方式二所述的基于机器视觉的塑件外观缺陷识别与定位方法进一步限定,在本实施方式中,f1为(80,80,256),表示256个行数为80列数为80的数组;
[0057]
f2为(40,40,512),表示512个行数为40列数为40的数组;
[0058]
f3为(20,20,1024),表示1024个行数为20列数为20的数组。
[0059]
具体实施方式四:本实施方式是对具体实施方式一所述的基于机器视觉的塑件外观缺陷识别与定位方法进一步限定,在本实施方式中,步骤3中,得到训练好的unet模型,具体过程为:
[0060]
步骤31、unet中包括下采样和上采样,下采样和上采样各包括多个维度,每个维度均包括多个卷积层,每个卷积层用于进行卷积处理;
[0061]
将步骤2得到的边缘光滑且无噪声的塑件图像数据集输入至unet下采样中,在下采样中依次进入下采样的第一维度、第一个bn层、下采样的第二维度、第二个bn层、下采样的第三维度、第三个bn层、下采样的第四维度和下采样的第五维度,且在下采样的第一维度和下采样的第二维度中均进行了f+2次卷积处理,在下采样的第三维度中均进行了f+1次卷积处理,在下采样的第四维度和下采样的第五维度均进行了f次卷积处理,f为大于等于0的正整数;
[0062]
步骤32、在下采样的第五个维度中进行f次卷积处理后,依次进入上采样中的第一维度、上采样中的第二维度、第四个bn层、上采样中的第三维度、第五个bn层、上采样中的第四维度和第六个bn层,且在上采样中的第一维度进行f次卷积处理,在上采样中的第二维度进行f+1次卷积处理,在上采样中的第三维度和第四维度均进行f+2次卷积处理,经过上采样中的第六个bn层处理后,使用softmax进行归一化处理,得到的数据集能够学习到步骤1得到的图像数据集具备背景去掉得到边缘光滑且无噪声的塑件图像数据集的能力,此时为训练好的unet模型。
[0063]
本实施方式中,步骤2得到的边缘光滑且无噪声的塑件图像数据集和步骤1得到的
图像数据集一同作为unet的输入,当unet可以去除步骤1得到的图像数据集的背景时,我们认为完成unet模型的训练,此时unet为训练好的模型。这种使unet学习步骤2得到的边缘光滑且无噪声的塑件图像数据集的去掉背景的分割方式,能够将步骤1得到的图像数据集的背景去掉时,我们认为unet训练好了。
[0064]
现有的f为3。
[0065]
下采样的作用是学习步骤2得到的边缘光滑且无噪声的塑件图像数据集,能够提取塑件特征;上采样的作用是得到去除背景的塑件图像数据。
[0066]
本技术在现有的unet结构中,下采样部分,增加了前三个维度的卷积层数,并对每一个维度的卷积层后都加入了bn层。在上采样部分,增加了后三个维度的卷积层数,以保证与下采样部分保持一致,并同样在每个维度的卷积层后加入了bn层。增加卷积层的好处在于更精确的识别特征,以达到分割背景更准确。而加入bn层的好处是加快网络的训练和收敛的速度、控制梯度爆炸防止梯度消失和防止过拟合。
[0067]
具体实施方式五:本实施方式是对具体实施方式四所述的基于机器视觉的塑件外观缺陷识别与定位方法进一步限定,在本实施方式中,f为3。
[0068]
具体实施方式六:本实施方式是对具体实施方式一所述的基于机器视觉的塑件外观缺陷识别与定位方法进一步限定,在本实施方式中,步骤1中,对含有塑件的图像数据集进行处理的方式为腐蚀与膨胀处理。
[0069]
本实施方式中,进行腐蚀与膨胀处理后,塑件和背景的边缘会更加光滑,并消除部分来自相机的噪声。
[0070]
具体实施方式七:本实施方式是对具体实施方式一所述的基于机器视觉的塑件外观缺陷识别与定位方法进一步限定,在本实施方式中,外观缺陷类别包括划痕、缺损、标签错误或污渍。
[0071]
具体实施方式八:本实施方式是对具体实施方式一所述的基于机器视觉的塑件外观缺陷识别与定位方法进一步限定,在本实施方式中,步骤2中,使用图像处理软件剔除步骤1得到的图像数据集中的背景。
[0072]
虽然在本文中参照了特定的实施方式来描述本发明,但是应该理解的是,这些实施例仅仅是本发明的原理和应用的示例。因此应该理解的是,可以对示例性的实施例进行许多修改,并且可以设计出其他的布置,只要不偏离所附权利要求所限定的本发明的精神和范围。应该理解的是,可以通过不同于原始权利要求所描述的方式来结合不同的从属权利要求和本文中所述的特征。还可以理解的是,结合单独实施例所描述的特征可以使用在其他所述实施例中。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1