基于word2vec模型的班轮运输重点航线识别方法与流程
1.本发明属于水运交通领域,具体涉及一种基于word2vec模型的班轮运输重点航线识别方法。
背景技术:
2.得益于全球经济一体化进程的逐步推进和集装箱运输安全、便利的优点,集装箱班轮运输在国际贸易中的重要地位日益增长。尽管集装箱班轮运输的航线往往固定,但由全球不同公司经营的不同班轮航线所组成的国际集装箱班轮网络仍然巨大且复杂。因此,如何在复杂的国际集装箱班轮网络中识别出重点航线对于航线管理和班轮公司的运营有着重要的参考价值。
3.当前关于集装箱班轮重点航线识别的研究,主要从微观的角度出发,基于轨迹相似性对船舶轨迹数据进行聚类,并最终得到重点航线。但该方法对船舶轨迹数据的要求较高,且只适用于小范围重点航线识别,而在国际集装箱班轮网络中,班轮船舶轨迹数据的量级呈几何倍增长,对全球大范围的轨迹数据进行聚类需要消耗大量计算资源。同时,基于轨迹相似度的识别方法主要利用船舶轨迹在区域内的密度和频次进行聚类,而无法考虑到班轮前后挂靠港口的关联性,使得识别结果与实际的集装箱班轮运输重点航线存在差距。
4.针对上述问题,为了在集装箱班轮运输网络中,识别出考虑挂靠港口之间关联性的重点航线,利用word2vec模型对船舶在复杂网络中的挂港数据进行训练,并得到训练后生成的航段向量,结合聚类方法完成对集装箱班轮运输重点航线的识别。该方法使用挂靠港口数据,大大精简了运算内容,更适用于范围庞大的集装箱班轮运输网络,同时该方法利用word2vec模型,将挂靠前后港口间的潜在联系转化为向量之间的关联,使得聚类出的结果不仅仅是在某个区域内重合的航线,还是在网络中考虑整体关联性的全球航线。
技术实现要素:
5.本发明要解决的技术问题是:克服上述现有技术的不足,提出一种集装箱班轮运输重点航线识别方法。
6.本发明的技术方案为:
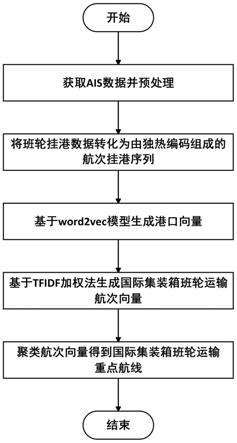
7.一种基于word2vec模型的班轮运输重点航线识别方法,包括以下步骤:
8.步骤一:获取ais数据并预处理
9.本步骤中的ais数据从集装箱班轮实际航行中获取,先利用ais解码算法对原始的ais数据进行解码,然后提取所需的ais数据,ais数据包括船舶名称、imo编号、经度、纬度、时间、航行速度等,数据预处理包括数据清洗、数据补全和挂靠港口识别。
10.步骤二:得到集装箱班轮航次挂港序列
11.将每条集装箱班轮的挂靠港口按航次和挂靠顺序排列,并将所有港口转换为独热编码,得到集装箱班轮的航次挂港序列。独热编码是一个长度为n的向量,n为所有序列中出现的港口数量总数,表示为v={0,0,
…
,1,
…
,0,0}。独热编码中,只有该港口对应的位置为
1,其余值全部为0,每一个港口对应一个不重复的独热编码。将所有航次的挂靠港口按顺序转化为独热编码,即得到每个航次的挂港序列:vi={v
i1
,v
i2
,
…
,v
ij
},其中,vi表示第i个航次的挂港序列,v
ij
表示第i个航次中第j个挂靠港口的独热编码。
12.步骤三:基于word2vec模型生成港口向量
13.该步骤中,将在步骤二中获取的集装箱班轮航次挂港序列输入word2vec模型,继而得到训练后的港口向量。模型共分为三层:输入层、投影层和输出层。在输入层中,挂港序列中的每个港口依次被作为中心港口,模型输入的是每个中心港口的前后各k个港口的独热编码,k为窗口大小。投影层是将输入的2k个独热编码进行累加求和。而投影层到输出层的连接边则是一个n*m的权重矩阵,m表示所要得到港口向量的长度,投影层累加后的向量与权重矩阵相乘,得到的结果输入输出层。而模型的输出层是一个softmax回归函数,用于计算2k个输入港口生成中心港口的概率p,计算公式如下:
[0014][0015]
式中,x
ij
表示第i个航次中第j个挂靠的港口,即中心港口,xk表示模型输入的港口中的第k个港口,v
ij
为港口x
ij
的独热编码,vk为港口xk的独热编码,d为该航次的挂港序列长度,即该航次中班轮挂靠港口总次数。
[0016]
模型的目标为最大化目标函数,目标函数通常取为如下的对数似然函数:
[0017][0018]
式中,c为数据中全部航次的数量。
[0019]
在模型训练结束后,得到最终的权重矩阵,将港口的独热编码与权重矩阵相乘,即得到长度为m的港口向量t。
[0020]
步骤四:获取集装箱班轮运输航次向量
[0021]
使用tfidf(term frequency-inverse document frequency)加权法将港口向量转化为航次向量。tfidf加权法利用港口在集装箱班轮网络中出行的频率来表示港口的重要性,港口的重要程度越高,港口向量在航次向量中的权重就越高。tfidf加权法可以将枢纽港在集装箱班轮航次中的重要影响进一步得到强化。tfidf加权法公式如下:
[0022][0023]
式中,tf
ij
为第i个航次中第j个挂靠的港口出现的频率,f
ij
为第i个航次中第j个挂靠的港口在数据中出现的频次,di为第i个航次的挂港序列长度。
[0024][0025]
式中,idf
ij
为第i个航次中第j个挂靠的港口的逆向频率,h
ij
为序列中包含该港口的航次的数量。
[0026]wij
=tf
ij
*idf
ij
[0027]
式中,w
ij
为第i个航次中第j个挂靠的港口tfidf权重。
[0028]
将每个航次中的港口向量t使用tfidf加权法累加,即得到了集装箱班轮运输的航
次向量u:
[0029][0030]
式中,ui为第i个航次的航次向量,t
ij
表示第i个航次中第j个挂靠港口的港口向量。
[0031]
步骤五:识别集装箱班轮运输重点航线
[0032]
将步骤四中得到的航次向量进行聚类,从而得到了最终的集装箱班轮运输重点航线。聚类步骤如下:
[0033]
1)将航次向量的n维向量看作是n维空间中的一个点,对n维空间的每一维度进行等量划分,最终将整个空间划分为互相不相交的若干个网格,每个网格的初始状态为“未标记”;
[0034]
2)计算每个网格的密度,根据给定的密度阈值δ来判断网格是否是稠密网格,先计算低维度上的稠密网格,若n-1维的空间上的网格是稠密的,则数据在n维空间中对应的网格可能是稠密的,反之,若在n-1维上的网格是不稠密的,则在n维空间中肯定不稠密,再计算高维度的可能稠密网格,直至最后一维度;
[0035]
3)遍历所有的网格,若网格为“未标记”状态,则转到4),若网格为“已标记”状态,则继续处理下一个网格,若所有网格均“已标记”,则转到8);
[0036]
4)将网格状态更改为“已标记”,若该网格为非稠密网格,则回到3),若该网格为密集网格,则赋予该网格新的簇标记,并创建一个集合,将该稠密网格放入集合中;
[0037]
5)判断集合中的网格是否均检查完毕,若有未检查的网格,转到6),若网格均已检查,则转到7);
[0038]
6)检查该网格所有相邻且“未标记”的网格,将其中的稠密网格状态更改为“已标记”,赋予当前的簇标记,并将其加入集合中,转到5);
[0039]
7)检查结束,将集合中的稠密网格组成目标簇,修改簇标记,回到3);
[0040]
8)遍历所有网格结束,输出目标簇。
[0041]
聚类后得到的聚类簇即集装箱班轮运输的重点航线。
[0042]
本发明的技术效果在于:
[0043]
本发明使用挂靠港口数据,精简了重点航线识别的运算内容,更适用于范围庞大的国际班轮运输网络,并深入挖掘了港口间的潜在关联,从而实现集装箱班轮运输重点航线的识别。本发明有助于交通管理部门和航运公司准确掌握集装箱班轮运输的重点航线,为交通管理部门制定管理政策,航运公司规划与管理海上航线提供有力支持。
附图说明
[0044]
图1是本发明提供的识别方法的整体流程框图。
[0045]
图2是本发明对航次向量进行聚类的流程框图
具体实施方式
[0046]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。
[0047]
实施例1。
[0048]
如图1、2所示,一种基于word2vec模型的班轮运输重点航线识别方法,包括以下步骤:
[0049]
步骤一:获取ais数据并预处理
[0050]
本步骤中的ais数据从集装箱班轮实际航行中获取,先利用ais解码算法对原始的ais数据进行解码,然后提取所需的ais数据,ais数据包括船舶名称、imo编号、经度、纬度、时间、航行速度等,数据预处理包括数据清洗、数据补全和挂靠港口识别。
[0051]
首先对ais数据进行清洗,将日期、数字等数据格式全部统一,对重复信息进行删除,去除不合理值,对明显错误数据进行更正。
[0052]
其次对ais数据进行补全,基于岸基、星基等其他数据源以及该船舶前后关联数据,对信息缺失数据进行插入和回补等补全处理。
[0053]
最后船舶挂靠港口进行识别,利用ais的位置、时间与速度信息和港口位置信息,当船舶处于港口挂靠范围内的停留时间和船舶航速都满足挂靠约束时,识别出该船舶挂靠该港口。
[0054]
步骤二:得到集装箱班轮航次挂港序列
[0055]
将每条集装箱班轮的挂靠港口按航次和挂靠顺序排列,并将所有港口转换为独热编码,得到集装箱班轮的航次挂港序列。独热编码是一个长度为n的向量,n为所有序列中出现的港口数量总数,表示为v={0,0,
…
,1,
…
,0,0}。独热编码中,只有该港口对应的位置为1,其余值全部为0,每一个港口对应一个不重复的独热编码。将所有航次的挂靠港口按顺序转化为独热编码,即得到每个航次的挂港序列:vi={v
i1
,v
i2
,
…
,v
ij
},其中,vi表示第i个航次的挂港序列,v
ij
表示第i个航次中第j个挂靠港口的独热编码。
[0056]
步骤三:基于word2vec模型生成港口向量
[0057]
该步骤中,将在步骤二中获取的集装箱班轮航次挂港序列输入word2vec模型,继而得到训练后的港口向量。模型共分为三层:输入层、投影层和输出层。在输入层中,挂港序列中的每个港口依次被作为中心港口,模型输入的是每个中心港口的前后各k个港口的独热编码,k为窗口大小。投影层是将输入的2k个独热编码进行累加求和。而投影层到输出层的连接边则是一个n*m的权重矩阵,m表示所要得到港口向量的长度,投影层累加后的向量与权重矩阵相乘,得到的结果输入输出层。而模型的输出层是一个softmax回归函数,用于计算2k个输入港口生成中心港口的概率p,计算公式如下:
[0058][0059]
式中,x
ij
表示第i个航次中第j个挂靠的港口,即中心港口,xk表示模型输入的港口中的第k个港口,v
ij
为港口x
ij
的独热编码,vk为港口xk的独热编码,d为该航次的挂港序列长度,即该航次中班轮挂靠港口总次数。
[0060]
模型的目标为最大化目标函数,目标函数通常取为如下的对数似然函数:
[0061][0062]
式中,c为数据中全部航次的数量t。
[0063]
在模型训练结束后,得到最终的权重矩阵,将港口的独热编码与权重矩阵相乘,即得到长度为m的港口向量。
[0064]
步骤四:获取集装箱班轮运输航次向量
[0065]
使用tfidf(term frequency-inverse document frequency)加权法将港口向量转化为航次向量。tfidf加权法利用港口在集装箱班轮网络中出行的频率来表示港口的重要性,港口的重要程度越高,港口向量在航次向量中的权重就越高。tfidf加权法可以将枢纽港在集装箱班轮航次中的重要影响进一步得到强化。tfidf加权法公式如下:
[0066][0067]
式中,tf
ij
为第i个航次中第j个挂靠的港口出现的频率,f
ij
为第i个航次中第j个挂靠的港口在数据中出现的频次,di为第i个航次的挂港序列长度。
[0068][0069]
式中,idf
ij
为第i个航次中第j个挂靠的港口的逆向频率,h
ij
为序列中包含该港口的航次的数量。
[0070]wij
=tf
ij
*idf
ij
[0071]
式中,w
ij
为第i个航次中第j个挂靠的港口tfidf权重。
[0072]
将每个航次中的港口向量t进行加权累加,即得到了集装箱班轮运输的航次向量u:
[0073][0074]
式中,ui为第i个航次的航次向量,t
ij
表示第i个航次中第j个挂靠港口的港口向量。
[0075]
步骤五:识别集装箱班轮运输重点航线
[0076]
将步骤四中得到的航次向量进行聚类,从而得到了最终的集装箱班轮运输重点航线。聚类步骤如下:
[0077]
1)将航次向量的n维向量看作是n维空间中的一个点,对n维空间的每一维度进行等量划分,最终将整个空间划分为互相不相交的若干个网格,每个网格的初始状态为“未标记”;
[0078]
2)计算每个网格的密度,根据给定的密度阈值δ来判断网格是否是稠密网格,先计算低维度上的稠密网格,若n-1维的空间上的网格是稠密的,则数据在n维空间中对应的网格可能是稠密的,反之,若在n-1维上的网格是不稠密的,则在n维空间中肯定不稠密,再计算高维度的可能稠密网格,直至最后一维度;
[0079]
3)遍历所有的网格,若网格为“未标记”状态,则转到4),若网格为“已标记”状态,则继续处理下一个网格,若所有网格均“已标记”,则转到8);
[0080]
4)将网格状态更改为“已标记”,若该网格为非稠密网格,则回到3),若该网格为密集网格,则赋予该网格新的簇标记,并创建一个集合,将该稠密网格放入集合中;
[0081]
5)判断集合中的网格是否均检查完毕,若有未检查的网格,转到6),若网格均已检
查,则转到7);
[0082]
6)检查该网格所有相邻且“未标记”的网格,将其中的稠密网格状态更改为“已标记”,赋予当前的簇标记,并将其加入集合中,转到5);
[0083]
7)检查结束,将集合中的稠密网格组成目标簇,修改簇标记,回到3);
[0084]
8)遍历所有网格结束,输出目标簇。
[0085]
聚类后得到的每一个聚类簇即构成了集装箱班轮运输的重点航线。
[0086]
以上所述,仅为本发明较佳的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,根据本发明的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1