一种人脸验证攻击方法和装置
一种人脸验证攻击方法和装置
·
技术领域
1.本发明属于深度学习下的对抗攻击领域,具体涉及一种人脸验证攻击方法和装置。
·
背景技术:
2.随着硬件技术的算力增长和算法的不断更迭,以卷积神经网络为代表的深度学习技术被广泛应用在了许多机器学习的任务中,如计算机视觉的图像分类、目标检测、语义分割,自然语言处理和博弈论等等。得利于深度学习模型的不断发展,人脸识别系统已经能够超越人类的识别能力,在基准数据集上实现高达99%的准确率。然而,研究者们发现现有的深度学习技术存在着严重的安全隐患:攻击者可以向良性的数据样本中添加精心设计的噪声从而欺骗深度学习模型。“对抗样本”的概念最早是由szegedy等人提出,他们发现训练好的模型会给添加细微干扰的图片以高置信度的错误分类结果。不仅仅是关于安全方面的风险,对抗样本同时也给深度学习的可解释性带来了一定的挑战。随着模型的复杂化,我们对模型的可解释性大大降低。它揭示出深度神经网络和人类的认知仍有一定的差距。anh nguyen等人提出一些人类完全无法识别的样本,会使得深度学习模型以高置信度分类错误。这代表深度学习的模型的学习机制与人类大脑并不相同,仍有一定的不可解释性。对抗样本的存在无疑制约着深度学习技术进一步的大规模应用。
3.由于人脸识别系统在日常生活中的广泛使用,其高效性和可靠性也成为了应用于现实生活场景当中的考虑因素。在人脸识别技术的应用过程中,仅仅考虑提高人脸识别模型的识别的效率是不够的,人脸识别模型还需要能够经受住潜在的对抗攻击。人脸识别模型的主要任务分为以下两种:1)人脸识别,根据输入的图像返回对应的预测对象身份;2)人脸验证,判断用户输入的图像对是否为同一人。尽管已经涌现出了许多针对人脸验证任务的对抗攻击方法,但是大多数方法都不可避免地存在以下三类问题中的部分问题:
4.1)生成对抗样本需要较长的时间。比如在白盒攻击中基于梯度的迭代方法中,pgd方法对抗样本生成需要经过数十次的迭代优化才能最终得到对抗样本,平均每张人脸图像生成对应的对抗样本需要约8s;
5.2)攻击无法有效迁移到更多的模型上。白盒攻击需要了解所攻击的目标模型的结构和参数。白盒攻击方法仅能有效地攻击白盒的人脸识别模型,若使用针对特定白盒模型生成的对抗样本用于攻击其他未知的人脸识别模型时,其对抗攻击效果很差,无法实现很好的迁移攻击。
6.3)图像质量较差。为了使得生成的对抗样本能够误导更多未知的人脸识别模型,实现更好的攻击迁移效果,添加的对抗扰动往往较多并非常明显,容易被肉眼观察到这种修改,降低对抗攻击的隐蔽性,使得对抗样本变得不真实自然。从图像恢复评价指标上而言,图像质量较差;从图像感知指标上而言,会引起人的怀疑。
7.·
术语解释
8.白盒人脸识别模型:指能够获取到所有模型信息和结构的目标人脸识别模型;
9.黑盒人脸识别模型:指无法获取到目标模型信息和结构的人脸识别模型;
10.本地白盒人脸识别模型:指在本方法的训练阶段,利用模型进行特征提取辅助网络训练的白盒人脸识别模型。
·
技术实现要素:
11.本发明旨在针对现有人脸验证对抗样本生成技术的不足,提供一种能够快速生成高质量可迁移的灰盒人脸验证攻击方法。
12.本发明的具体实现方法步骤如下:
13.步骤一、对被攻击者的原始人脸图像x
original
进行预处理,得到预处理后的图像x;
14.对于给定的250*250像素的人脸图像先通过mtcnn(multi-task cascade convolutional neural network)进行人脸关键点的检测,用得到的五类关键点进行一种近似变换得到对齐后的人脸图像,再裁剪至160*160像素。再将每个像素点的像素值减去127.5后除以128进行正则化,得到预处理后的图像x;并随机选取一张与原始人脸图像x属于同一对象的其他人脸图像作为非定向攻击的目标图像y;
15.步骤二、将预处理后的图像x输入到注意力生成器g得到对抗噪声g(x);再对对抗噪声g(x)使用服从二维高斯分布的卷积核进行卷积操作,即对图像进行高斯滤波操作得到对抗噪声g(x)'
original
,将高斯模糊后的对抗噪声g(x)'
original
进行裁剪操作,将图像的像素值控制在有效范围内,得到对抗噪声g(x)';最后将对抗噪声g(x)'加入到预处理操作前的原始人脸图像x
original
上,形成对抗样本x
adv
;
16.x
adv
=x
original
+g(x)'
ꢀꢀꢀ
(1)
17.步骤三、注意力生成器g为使得生成的对抗样本尽可能是真实自然的,需要通过约束对添加的扰动进行控制,根据对抗噪声g(x)'计算扰动损失l
perturbation
,其计算方法如下:
18.l
perturbation
=e
x
[max(ε,||g(x)
′
||2)]
ꢀꢀꢀ
(2)
[0019]
其中||
·
||2表示l2范数,ε为设置的对抗噪声扰动上限,e
x
表示与处理后的整张图像x的期望值;
[0020]
步骤四、将对抗样本x
adv
传输给样本判别器d1,样本判别器d1用于对被攻击者的输入人脸图像与其对应生成的对抗样本之间进行图像真实性的判断,并以此计算生成对抗网络的对抗损失l
gan
,其公式如(3)所示:
[0021]
l
gan
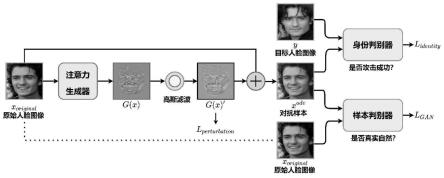
=e
x
[logd1(x)]+e
x
[log(1-d1(x
adv
))]
ꢀꢀꢀ
(3)
[0022]
式中d1(x)表示样本判别器d1对被攻击者人脸图像x的判别结果;d1(x
adv
)表示对对抗样本x
adv
的判别结果;
[0023]
步骤五、将对抗样本x
adv
传输到由本地白盒人脸识别模型作为身份判别器的d2,由本地白盒人脸识别模型对对抗样本x
adv
和目标人脸图像y提取特征,再对特征计算余弦相似度,并以此计算身份判别损失l
identity
,如公式(4)所示;
[0024]
l
identity
=e
x
[(f(x
adv
,y))]
ꢀꢀꢀ
(4)
[0025]
其中,f(x
adv
,y)表示由图像y和对抗样本x
adv
的特征向量计算余弦相似度;
[0026]
步骤六、根据步骤三、四、五得到的损失l
perturbation
、l
gan
、l
identity
和对应的权重,累加得到总损失l,如公式(5)所示;然后通过模型的反向传播,以最小化总损失l为生成对抗网络训练的最终目标,对注意力生成器g和样本判别器d1的参数进行更新,而不对身份判别
器d2的参数进行更新;
[0027]
l=l
gan
+λil
identity
+λ
p
l
perturbation
ꢀꢀꢀ
(5)
[0028]
式中,λi和λ
p
分别是身份判别损失l
identity
和扰动损失l
perturbation
的权重系数;
[0029]
步骤七、利用步骤六反向传播更新后的注意力生成器g和样本判别器d1,重复步骤二至六,进行下一次的迭代训练;模型的训练将不停迭代优化总损失函数l,直至达到预设的迭代次数;
[0030]
步骤八、向注意力生成器g载入经过步骤七最终训练得到的最优攻击成功率的模型参数,根据输入的不同被攻击者人脸图像,生成对应的对抗样本x
adv
;
[0031]
步骤九、使用步骤八生成的对抗样本x
adv
攻击黑盒人脸识别模型的人脸验证任务,实现高质量可迁移的灰盒人脸验证攻击;作为优选,本攻击方法中的注意力生成器g包括:
[0032]
1)7*7,步长为1,filters=64的卷积块;
[0033]
2)4*4,步长为2,filters=128的卷积块;
[0034]
3)4*4,步长为2,filters=256的卷积块;
[0035]
4)三个残差模块,每个残差模块都包含了2个3*3的卷积层和跳跃连接操作。此外,每个残差模块的第二个3*3卷积层后不采用激活函数,且均在跳跃连接处使用了通道注意力se模块。
[0036]
5)图像尺寸放大2倍的上采样和5*5,步长为1,filters=128的卷积层;
[0037]
6)图像尺寸放大2倍的上采样和5*5,步长为1,filters=64的卷积层;
[0038]
7)7*7,步长为1,filters=3的卷积块(激活函数为tanh)。
[0039]
上述的每个卷积块均由一个卷积层、instance norm层和relu的激活函数组成。
[0040]
作为优选,本攻击方法中的样本判别器d1依次包括:1)4*4,步长为2,filters=32的卷积块;
[0041]
2)4*4,步长为2,filters=64的卷积块;
[0042]
3)4*4,步长为2,filters=128的卷积块;
[0043]
4)4*4,步长为2,filters=256的卷积块;
[0044]
5)4*4,步长为2,filters=512的卷积块。
[0045]
上述的每个卷积块依次包括一个卷积层、batch norm层和leakyrelu激活函数。
[0046]
在样本判别器d1的最后还添加了1*1,步长为1,filters=3的卷积层用于计算patch-based的对抗损失l
gan
。
[0047]
作为优选,在gan网络模型训练的过程中,注意力生成器g和样本判别器d1采用n:1的交替训练方式,即首先根据总损失函数l更新一次样本判别器d1的参数,然后在接下去的多次迭代中都只对注意力生成器g的参数进行更新。
[0048]
作为优选,所述的通过服从二维高斯分布的卷积核进行卷积实现高斯滤波操作的具体过程如式(5)所示:
[0049]
g(x)
′
original
=τk*g(x)
ꢀꢀꢀ
(5)
[0050]
式中,τk表示核大小为k的高斯核;*表示用k*k的高斯核对生成的噪声g(x)进行卷积操作。
[0051]
作为优选,所述的本地白盒人脸识别模型为应用最为广泛的facenet人脸识别模型。
[0052]
作为优选,针对公式(4)中所述的扰动损失权重λ
p
=1,身份判别损失权重λi采用自动调整策略而非固定的默认值λi=10,根据图像x与对抗样本x
adv
特征向量之间的余弦相似度,对应调整身份判别损失权重λi,其对应关系如表1所示:
[0053]
表1自动调整策略的余弦相似度取值与身份判别损失权重λi对应关系
[0054]
余弦相似度范围[-1,-0.4][-0.4,-0.2][-0.2,0.2][0,0.2][0.2,0.4][0.4,0.6][0.6,1]身份判别损失λi16.14115.37314.64113.3112.11110
[0055]
若对抗样本x
adv
与攻击目标图像y之间的余弦相似度∈[0.6,1],则将λi设为10,若余弦相似度∈[0.4,0.6],则将λi设为11,,以此类推
[0056]
本发明的另一个目的是提供一种计算设备,包括存储器和处理器,所述存储器中存储有可执行代码,所述处理器执行所述可执行代码时,实现上述的方法。
[0057]
本发明具有的有益效果是:
[0058]
1、本发明提出了一种基于生成对抗网络的针对人脸验证任务的灰盒对抗攻击方法,相比于白盒攻击方法,对抗样本的生成速度更快,大大减少了计算开销。提出的灰盒攻击更加符合人脸识别模型的现实应用,并取得了较好的攻击迁移性。
[0059]
2、本发明提出的方法将高斯滤波操作沿用至人脸验证任务的攻击上,对对抗噪声进行高斯平滑,提高了对抗样本的攻击迁移性,使其在攻击黑盒模型时也能取得较高的攻击成功率。
[0060]
3、本发明在生成器中残差模块的跳跃连接操作中引入了注意力机制,根据不同通道特征的贡献重新分配特征权重,提高了生成器对人脸图像的特征提取能力,进一步提高了对抗样本的迁移性。
[0061]
4、本发明提出了一种根据facenet白盒人脸识别模型计算所得余弦相似度而自动调整身份判别损失权重的策略,按照人脸验证图像对之间的不同余弦相似度取值,自动调节身份判别损失在总损失中的权重,进一步提高对抗样本的白盒攻击成功率和迁移性。
[0062]
4、本发明提出的方法生成的对抗样本图像质量优于同类方法,肉眼难以察觉这种对抗攻击,保证了对抗样本的真实自然。
·
附图说明
[0063]
图1是本发明方法流程图
[0064]
图2是本发明方法中的注意力生成器结构图
[0065]
图3是本发明方法对人脸验证任务的攻击效果
[0066]
图4是本发明方法和其他方法生成的对抗样本
·
具体实施方式
[0067]
下面结合具体实施对本发明做进一步分析。
[0068]
如图1为一种人脸验证攻击方法,包括以下步骤:
[0069]
步骤一、本发明用于训练的图像数据为公开数据集casia-webface经过一定数据清洗后的包含10,575个名人的45,3401张图像。将图片输入到注意力生成器g之前,首先将对250*250的人像图像通过mtcnn对的10个landmark坐标进行检测,包括:2个眼睛,1个鼻子和2个嘴角的坐标(0—9其中0和5表示左眼,1和6表示右眼,2和7表示鼻子,3和8表示作嘴
角,3和9表示右嘴角的椭圆)。检测后通过近似的仿射变换将人脸图像进行对齐,使得图像具有良好的角度,并将图像resize到160*160,得到图像x
original
。此外,选择经过预训练的facenet模型,作为本地白盒人脸识别模型,用于提取人脸图像的特征,计算比较图像对之间的余弦相似度,在本攻击方法的训练阶段判断对抗样本对人脸验证任务的攻击是否成功。
[0070]
步骤二、将经过预处理后的被攻击者的人脸图像x,每个像素点的像素值减去127.5后除以128进行正则化;针对每张人脸图像x随机选择一张与其属于同一对象的其他图像作为非定向攻击的目标图像y;将正则化后的图像再输入到注意力生成器g中得到对抗噪声g(x);对生成的对抗噪声g(x)经过二维卷积核进行卷积,即对图像的高斯滤波操作,得到对抗噪声g(x)'
original
,再将其进行clip裁剪到合理的像素值区间,得到对抗噪声g(x)'。最后将对抗噪声g(x)'加入到预处理操作前的原始人脸图像x
original
上,形成对抗样本x
adv
;
[0071]
步骤三、根据对抗噪声g(x)'计算扰动损失l
perturbation
,其计算方法如下:
[0072]
l
perturbation
=e
x
[max(ε,||g(x)'||2)]
ꢀꢀꢀ
(6)
[0073]
其中||
·
||2表示l2范数,即对向量各元素先求平方和后再求平方根,使得扰动的像素修改尽可能小,防止过拟合;ε为设置的对抗噪声扰动上限,本例中ε取值为3;e
x
表示与处理后的整张图像x的期望值。
[0074]
步骤四、将对抗样本x
adv
传输给样本判别器d1,样本判别器d1用于对被攻击者的输入人脸图像与其对应生成的对抗样本之间进行图像真实性的判断,并以此计算生成对抗网络的对抗损失l
gan
,其公式如(7)所示::
[0075]
l
gan
=e
x
[logd1(x)]+e
x
[log(1-d
l
(x
adv
))]
ꢀꢀꢀ
(7)
[0076]
式中d1(x)表示对原始人脸图像x的判别结果;d1(x
adv
)表示对对抗样本x
adv
的判别结果;判别结果的范围为[0,1],0为假,1为真。对图像x进行判别时,我们希望样本判别器d1的判别结果越接近于1越好,故最小化l
gan
时,其损失函数为log d1(x);对于生成的对抗样本x
adv
,希望判别器的判别结果d(x
adv
)越接近于0越好,故其损失函数为log(1-d1(x
adv
))。
[0077]
步骤五、将对抗样本x
adv
传输到由本地白盒人脸识别模型facenet作为身份判别器的d2,由facenet对对抗样本x
adv
和目标人脸图像y提取特征,再计算余弦相似度,并以此获得身份判别损失l
identity
,如公式(8)所示。
[0078]
l
identity
=e
x
[(f(x
adv
,y))]
ꢀꢀꢀ
(8)
[0079]
上式中的f(
·
)表示由图像y和对抗样本x
adv
的特征向量计算余弦相似度;
[0080]
步骤六:根据步骤三、四、五得到的损失l
perturbation
、l
gan
、l
identity
及其权重系数,累加得到总损失l,如公式(9)所示。然后通过模型的反向传播,以最小化总损失l为生成对抗网络训练的最终目标,对注意力生成器g和样本判别器d1的参数进行更新,而不对白盒人脸识别模型facenet作为的身份判别器d2的参数进行更新;
[0081]
l=l
gan
+ail
identity
+λ
p
l
perturbation
ꢀꢀꢀ
(9)
[0082]
式中,λi和λ
p
分别是身份判别损失l
identity
和扰动损失l
perturbation
的权重系数。
[0083]
步骤七、利用步骤六反向传播更新后的注意力生成器g和样本判别器d1,重复步骤二至六,进行下一次的迭代训练。模型的训练将不停迭代优化总损失函数l,直至达到预设的迭代次数;
[0084]
步骤八、向注意力生成器g载入经过步骤七最终训练得到的最优攻击成功率的模
型参数,根据输入的不同被攻击者人脸图像,生成对应的对抗样本x
adv
;
[0085]
步骤九、使用步骤八生成的对抗样本x
adv
攻击黑盒人脸识别模型的人脸验证任务,实现高质量可迁移的灰盒人脸验证攻击。
[0086]
图2是本发明中的注意力生成器结构图。所述的注意力生成器g依次包括:
[0087]
1)7*7,步长为1,filters=64的卷积块;
[0088]
2)4*4,步长为2,filters=128的卷积块;
[0089]
3)4*4,步长为2,filters=256的卷积块;
[0090]
4)三个残差模块,每个残差模块都包含了2个3*3的卷积层、跳跃连接和注意力机制。此外,每个残差模块的第二个3*3卷积层后不采用激活函数,且均在跳跃连接处使用了通道注意力se模块。
[0091]
5)图像尺寸放大2倍的上采样和5*5,步长为1,filters=128的卷积层;
[0092]
6)图像尺寸放大2倍的上采样和5*5,步长为1,filters=64的卷积层;
[0093]
7)7*7,步长为1,filters=3的卷积块(激活函数为tanh)。
[0094]
上述的每个卷积块依次包括一个卷积层、instance norm层和relu的激活函数。
[0095]
se模块主要包括压缩和激活两部分。压缩部分首先对输入为h*w*c的特征图通过一次全局平均池化操作,为每个大小为w*h的二维特征图生成1*1*c的实数,代表当前特征图的全局特征响应权重。激活部分再将表示所有通道之间相互关联度的实数通过先降维再恢复维度的两次全连接操作,增加非线性的处理拟合通道之间的相关性,学习多个通道之间的非互斥关系,再借助sigmoid函数激活后转换为[0,1]之间的数值与特征图全乘重新分配不同通道的权重。
[0096]
se模块通常被添加在残差模块的第二个卷积层后,而在此处选择添加在残差模块的跳跃连接操作中,以进一步提高生成器的特征提取能力,进而提高对抗样本的迁移性。
[0097]
所述的样本判别器d1依次包括:1)4*4,步长为2,filters=32的卷积块;
[0098]
2)4*4,步长为2,filters=64的卷积块;
[0099]
3)4*4,步长为2,filters=128的卷积块;
[0100]
4)4*4,步长为2,filters=256的卷积块;
[0101]
5)4*4,步长为2,filters=512的卷积块。
[0102]
上述的每个卷积块依次包括一个卷积层、batchnorm层和leakyrelu激活函数。
[0103]
在样本判别器d1的最后还添加了1*1,步长为1,filters=3的卷积层用于计算patch-based的对抗损失l
gan
。
[0104]
在网络模型的训练过程中,注意力生成器g和样本判别器d1采用n:1的交替训练方式,即首先根据总损失函数l更新一次样本判别器d1的参数,然后在接下去的多次迭代中都只对注意力生成器g的参数进行更新。
[0105]
所述的使用二维卷积核进行卷积实现高斯滤波,是指使用一定大小卷积尺寸的服从二维高斯分布的高斯核对生成的噪声g(x)进行卷积,用于去除图像中的高频分量信息,保留图像中的低频分量信息。通过高斯滤波操作可以对生成的噪声g(x)作高斯滤波处理,使得噪声g(x)'
original
更加平滑。经过处理后的噪声经裁剪操作再加到原图x上,形成的对抗样本x
adv
能具有更有效的攻击的性能和迁移性。高斯滤波操作如式(10)所示:
[0106]
g(x)
′
original
=τk*g(x)
ꢀꢀꢀ
(10)
[0107]
式中,τk表示核大小为k*k的高斯核,在本例中k取值为7;g(x)'
original
表示用k*k的高斯核对生成的噪声g(x)进行卷积操作来进行高斯平滑处理后得到的对抗噪声。
[0108]
为验证本发明的有效性,将现有的多种针对人脸识别模型的对抗攻击方法包括:flm、gflm、pgd、fgsm等进行实验比较。实验采用的数据集为lfw(labled faces in thewild)数据集。该数据集由5749个身份组成,其中1680人有两张或更多张图像数据。由于人脸验证任务需要根据至少两张图像的类别的图像对衡量成功率,我们对lfw数据集进行了筛选,仅考虑包含两张或更多张的1680个类别的9164张图像用于人脸验证任务的评价。
[0109]
为了验证本发明提出的攻击方法的有效性,选择攻击成功率(attack success rate,asr)作为评价指标,它表示对抗攻击能够成功误导目标人脸识别模型的人脸验证任务情况。本文共采用7种sota人脸识别模型作为人脸特征匹配器进行试验。其中公开的模型包括facenet,sphereface,insightface和vgg-face。为更好地将本文研究工作拓展到现实应用场景中去,选择3种商用人脸识别模型的api接口:百度,旷视,讯飞进行测试。训练阶段仅使用facenet作为本发明提出方法的第三方模型作为身份判别器辅助训练。推理阶段便可以根据不同图像自动生成对抗样本,再将其他几个模型作为目标黑盒攻击模型进行测试。对于目标人脸识别模型而言,一定的far值下都存在基于余弦相似度的固定阈值作为判断人脸验证任务的阈值τ。当图像对的特征向量之间的余弦相似度大于该阈值τ,即可判断二者属于同一人,反之二者不属于同一人。本发明方法对facenet的人脸验证攻击效果如图3。facenet中人脸验证任务的判定阈值为0.45,原始图像与目标图像之间的余弦相似度均大于该阈值,而进行攻击后生成的对抗样本与目标图像之间的余弦相似度均小于该阈值,实现了人脸验证攻击。
[0110]
而对于非定向攻击而言,攻击目标是使得同一人的图像对在经过对抗攻击后,二者特征向量之间的余弦相似度小于该阈值t,故攻击成功率计算方式如式(11):
[0111][0112]
式中,和yi分别代表第i组对抗样本和非定向目标图像,n表示人脸验证任务的图像总数,τ表示facenet在1%far值计算下得到的判别阈值,f(
·
)表示根据特征向量计算余弦相似度。当对抗样本和定向目标之间的余弦相似度小于阈值,则表示攻击成功。asr∈[0,1],asr越高代表对抗样本的攻击效果越好。
[0113]
攻击者由于无法获取所有的人脸识别模型信息,为使得能够对多种模型都具有攻击性,对抗样本的可迁移性无疑是最重要的。在此,本文假设所有的对抗攻击方法均只能获取facenet的白盒信息,而无法获取其他人脸识别模型的信息。白盒攻击方法只能针对facenet模型生成对抗样本,将生成的对抗样本攻击其他人脸识别模型。本发明方法与各攻击方法在不同人脸识别模型和api上的实验结果如表2所示。
[0114]
表2本发明方法与各攻击方法对人脸识别模型的攻击成功率(%)
[0115]
methodfacenetspherefaceinsightfacevgg-faceapi-baiduapi-face++api-xfyunpgd99.9052.9552.5432.6794.5756.2516.95fgsm91.6026.7628.2218.2674.8126.747.62flm100.0024.0116.4018.1374.8520.325.24gflm99.8333.5126.4023.0789.6242.4811.78
advface99.7226.7316.1629.6367.2317.224.65ours99.9878.5958.2273.4798.3774.2228.14
[0116]
根据实验结果,各方法均能够在白盒模型上实现较高的攻击成功率,其中flm和本发明方法效果最好,分别实现了100%和99.98%的攻击成功率。而针对未知的黑盒模型而言,pgd、fgsm、flm、gflm的白盒方法生成的对抗样本都无法实现高效迁移,其中通过梯度多步迭代优化的pgd方法迁移效果较好。同为灰盒攻击的advface表现出较差的迁移性,而本发明方法能够有效迁移到黑盒模型中,分别在sphereface和face++上实现了78.59%和74.22%的攻击成功率。
[0117]
对抗样本图像质量越高,越接近原始图像,人肉眼便越难以发现这种对抗攻击,才能使得攻击更为隐蔽和有效。为了衡量本发明方法与各攻击方法生成对抗样本的图像质量,采用图像恢复评价指标的结构相似性指数ssim、峰值信噪比psnr,图像感知评价指标的学习感知图像块相似度lipis,图像质量评价结果见表3,图4是本发明提出的方法和其他方法的生成的对抗样本。
[0118]
表3本发明方法与各攻击方法生成对抗样本的时间和图像质量评价结果
[0119]
methodpgdfgsmflmgflmadvfaceours
↑
ssim0.75
±
0.030.82
±
0.070.82
±
0.050.62
±
0.100.97
±
0.0130.92
±
0.027
↑
psnr(db)29.23
±
0.4118.99
±
3.2423.25
±
1.8119.50
±
2.3434.40
±
4.8229.80
±
4.08
↓
lpips0.086
±
0.0210.072
±
0.0410.033
±
0.0100.058
±
0.0250.005
±
0.0020.020
±
0.007
↓
time(s)7.860.010.120.530.010.01
[0120]
结合表3与图4,fgsm和pgd方法生成的对抗样本由于分别出现了明显的波纹和白雾,很容易引起感知上的察觉,故lpips较高,图像恢复质量也较差。基于图像进行几何变换的flm和gflm方法相比,由于二者在不同程度上都对人脸图像进行扭曲,其中gflm扭曲程度更甚,所以二者的图像恢复质量较差。对于面部关键点的位移也使得面部特征发生变化,使得感知评价lpips略高,与原始图像之间存在一定的特征偏差。同样采用gan的advface生成了高质量的对抗样本,图像真实自然,但这种对抗样本却不具有实现攻击的可迁移性。相比之下,本发明方法实现了高质量可迁移的对抗样本生成,虽然在图像恢复质量和lpips感知评价上略低于advface,但仍能够保持肉眼感知上的真实自然。
[0121]
为了衡量本发明方法生成对抗样本的时间,选用测试集生成对抗样本的均值作为衡量攻击方法的时间成本的评价指标,结果见表3。基于梯度的白盒攻击方法fgsm和pgd,由于pgd需要进行更多的迭代次数寻求最优扰动,故生成对抗样本需要大量的时间。基于人脸图像关键点进行几何变换的flm和gflm方法,二者均需要对关键点的位移场进行数次的迭代,故相比基于梯度的单步骤fgsm方法,需要较长时间,但同时又优于迭代次数较多的pgd方法。gflm将人脸关键点依照特征属性进行分组几何变换,相对于对每个人脸关键点独立的flm方法,需要更多的生成时间。基于生成对抗网络的advface和本发明方法,则能够以与fgsm相同的时间生成对抗样本,高效生成对抗样本。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1