一种基于深度学习的岩心CT图像去噪方法与流程
一种基于深度学习的岩心ct图像去噪方法
技术领域
1.本发明涉及图像去噪处理技术领域,具体地说,涉及一种基于深度学习的岩心ct图像去噪方法。
背景技术:
2.地层储层岩心岩石物理结构的研究对于提高采收率具有重大意义,由于地层储层内部岩心结构复杂,早期二维图像的检测远远不能满足当前工业生产的需求。岩石的油气参数常常通过传统的岩石物理实验计算得出,该方法成本过高且周期过长。如今,运用数字岩心技术成为研究岩心内部结构的重要手段之一,随着数值模拟技术以及计算机硬件的飞速发展,目前数字岩心技术已经成为岩石物理研究的最佳方法之一。由于实际岩心的非均质性,仅通过简单的二维ct图像和简单的算法建立的岩心难以反映出实际岩心的真实情况,无法准确描述其内部复杂的孔隙结构。基于岩心二维信息,基于ct扫描法得到岩心序列图像,在建立岩心的过程中,常常通过阈值算法来划分骨架和孔隙结构,这样单纯的计算,常常会产生一些对于实际实验中不具备参考价值的无效点,俗称噪点。如何使用更有效的方法去除噪点,让建立的数字岩心能与真实岩心具有相似的孔隙结构具有重要价值。
技术实现要素:
3.本发明的内容是提供一种基于深度学习的岩心ct图像去噪方法,其能够克服现有技术的某种或某些缺陷。
4.根据本发明的一种基于深度学习的岩心ct图像去噪方法,其包括以下步骤:
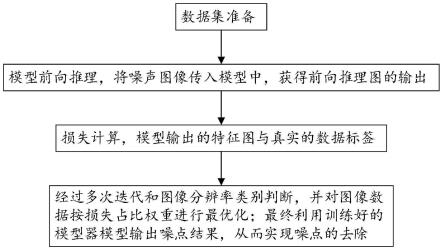
5.一、数据集准备;
6.二、模型前向推理,将噪声图像传入模型中,获得前向推理图的输出;
7.三、损失计算,模型输出的特征图与真实的数据标签;
8.四、重复步骤二和三,经过多次迭代和图像分辨率类别判断,并对图像数据按损失占比权重进行最优化;最终利用训练好的模型器模型输出噪点结果,从而实现噪点的去除。
9.作为优选,步骤一中,通过岩心三维数字化方式,对岩心ct进行可视化;对岩心进行随机的噪声增加,利用切片手法,得到岩心的单张图片,通过增加椒盐、高斯白噪声获取标准的128*128噪声图和与之对应的标准原图,将噪声点标记为1,原图标记为0,通过命名的方式分组,得到完整数据集;再将数据集按训练集:测试集:验证集=7:2:1进行,至此,数据准备阶段完成。
10.作为优选,步骤二中,模型按如下步骤进行:
11.a)输入图像imagegt格式为(n,c,h,w),分别代表图像的批次、通道、宽度、高度;通过ira模块进行卷积计算;
12.b)stage1层特征获取:经过ira,设置输出的通道分别为3,16,16,获取到stage1层特征;
13.c)将stage1特征进行maxpooling最大池化,池化核为2*2,再经过3个ira操作,输
出通道为32,32,32;最终获取stage2特征;
14.d)将stage2特征进行maxpooling最大池化,池化核为2*2,再经过3个ira操作,输出通道为64,64,64;最终获取stage3特征;
15.e)将stage3特征进行maxpooling最大池化,池化核为2*2,再经过3个ira操作,输出通道为128,128,128;最终获取stage4特征;
16.f)将stage4特征进行maxpooling最大池化,池化核为2*2,再经过3个ira操作,输出通道为256,256,256;最终获取stage5特征;
17.g)将stage5特征通过反卷积上采样,输出通道设置为256,宽度和高度缩短为之前的2倍,并且与copied的stage4特征进行拼接;再经过3个ira操作,输出通道为128,128,128;最终获取stage4_1特征;
18.h)将stage4_1特征通过反卷积上采样,输出通道设置为128,宽度和高度缩短为之前的2倍,并且与copied的stage3特征进行拼接;再经过3个ira操作,输出通道为64,64,64;最终获取stage3_1特征;
19.i)将stage3_1特征通过反卷积上采样,输出通道设置为32,宽度和高度缩短为之前的2倍,并且与copied的stage2特征进行拼接;再经过3个ira操作,输出通道为32,32,32;最终获取stage2_1特征;
20.j)将stage2_1特征通过反卷积上采样,输出通道设置为16,宽度和高度缩短为之前的2倍,并且与copied的stage1特征进行拼接;再经过3个ira操作,输出通道为16,16,16;最终获取stage1_1特征;
21.k)将stage1_1特征,再经过3个ira操作,输出通道为16,1,1;得到最终特征图image
pred
。
22.作为优选,步骤a)中,ira模块计算步骤如下:
23.1)ira模块由conv+bn+relu+conv+bn+relu+conv+bn+cbam模块组成,其中conv为常规卷积,3个conv的核分别为1*1,3*3,1*1,步长默认为1;模块中设置有expansion系数,用来控制ira中3*3模块的放大通道倍数;ira为一个倒残差注意力结构,输出与输入同型,中间通道数变换为c*expansion,大小均为(n,c,h,w),分别代表图像的批次、通道、宽度、高度;
24.2)输入图像先经过conv模块,输入通道为c,输出通道为c,参数中核为1*1,步长为1*1,padding默认为1,bias设置为flase;
25.3)特征图经过bn模块,通道数为c;
26.4)特征图经过relu模块,进行激活;
27.5)输入图像先经过conv模块,输入通道为c,输出通道为c*expansion,参数中核为3*3,步长为1*1,padding默认为1,bias设置为flase;
28.6)特征图经过bn模块,通道数为c*expansion;
29.7)特征图经过relu模块,进行激活;
30.8)输入图像先经过conv模块,输入通道为c*expansion,输出通道为c*expansion,参数中核为1*1,步长为1*1,padding默认为1,bias设置为flase;
31.9)特征图经过bn模块,通道数为c*expansion;
32.10)特征图经过cbam模块,计算获取到注意力特征;
33.11)将原始特征与注意力特征经过加和操作得到最终结果;形状为(n,c,h,w),由此一个ira操作完成。
34.作为优选,cbam模块包含2个独立的子模块,分别为通道注意力模块和空间注意力模块,分别进行通道与空间上的attention;cbam模块计算的步骤如下:
35.a)将输入的特征图f(h
×w×
c)分别经过基于width和height的global max pooling全局最大池化和global average pooling全局平均池化,得到两个1
×1×
c的特征图,合并特征送入下一层;
36.b)将它们分别送入一个两层的conv2d,第一层通道数为输入为c,输出为c/r核为1,stride为1,bias=false,激活函数为relu,;第二层通道数为输入为c/r,输出为c,核为1,stride为1,bias=false,这个两层的神经网络是共享的;
37.c)经过sigmoid激活操作,生成最终的channel attention feature,即m_c;
38.d)将m_c和输入的特征图f做element-wise乘法操作,生成spatial attention模块需要的输入特征;
39.e)将channel attention模块输出的特征图f作为模块的输入特征图;做一个基于channel的global max pooling和global average pooling,得到两个h
×w×
1的特征图;
40.f)将这2个特征图基于channel做concat操作;
41.g)经过一个7
×
7卷积操作;
42.h)降维为1个channel,即h
×w×
1;经过sigmoid生成spatial attention feature,即m_s;
43.i)将该feature和模块的输入feature做乘法,得到最终生成的注意力特征。
44.作为优选,步骤三中,训练损失计算如下:
45.计算真实原始图片与模型计算所得高分图片之间的损失代价衡量,其中loss计算如下:
46.①
mse loss计算:
[0047][0048]
代表总的mse损失,为真实图片对应的分类值;经过模型计算后的对应宽高图片对应的分类值;w,h分别代表宽度和高度;x,y代表目标位置索引;
[0049]
②
perceptual loss计算:
[0050][0051]
代表感知损失,cj为通道,w,h分别代表图像的宽度和高度;φj(x)
h,w,c
为真实图像在已训练resnet50残差网络中的第11层、24层、42、50层模型推理计算出来的感知特征图;φj(x)
h,w,c'
为对应去噪图像在已训练resnet50模型推理计算出来的感知特征图。
[0052]
本发明提供了一种适用于岩心ct图片的去噪方法,该方法利用编解码模型能够实
现对噪声图像图像经过训练得到所需去噪原始图像数据,采用残差50网络的不同特征计算模块,利用边缘模块信息建立特征图信息作为先验损失,获得更为准确的去噪图像。同时为了避免了以往方法中出现的重建结果只存有较高的信噪比psnr,高频信息缺少,过度平滑纹理的出现等问题,在cbam注意力模块与多尺度的感知损失的加持下,本发明方法所获得的去噪图像与真实的图像无论是低层次的像素值上,还是高层次的抽象特征上,或是整体概念和风格上都与真实图像数据相当接近。在风格重建时具有以下优点高层特征、全局结构、纹理明显。去噪时图像底层特征、边缘、颜色等细节信息较多,效果更好。
附图说明
[0053]
图1为实施例1中一种基于深度学习的岩心ct图像去噪方法的流程图;
[0054]
图2为实施例1中模型示意图;
[0055]
图3为实施例1中ira模块示意图;
[0056]
图4为实施例1中cbam模块示意图。
具体实施方式
[0057]
为进一步了解本发明的内容,结合附图和实施例对本发明作详细描述。应当理解的是,实施例仅仅是对本发明进行解释而并非限定。
[0058]
实施例1
[0059]
如图1所示,本实施例提供了一种基于深度学习的岩心ct图像去噪方法,其包括以下步骤:
[0060]
一、数据集准备;通过岩心三维数字化方式,对岩心ct进行可视化;对岩心进行随机的噪声增加,利用切片手法,得到岩心的单张图片,通过增加椒盐、高斯白噪声获取标准的128*128噪声图和与之对应的标准原图,将噪声点标记为1,原图标记为0,通过命名的方式分组,得到完整数据集;再将数据集按训练集:测试集:验证集=7:2:1进行,至此,数据准备阶段完成。
[0061]
二、模型前向推理,将噪声图像传入模型中,获得前向推理图的输出;
[0062]
模型按如下步骤进行:
[0063]
a)输入图像imagegt格式为(n,c,h,w),分别代表图像的批次、通道、宽度、高度;通过ira模块进行卷积计算;
[0064]
ira模块计算步骤如下:
[0065]
1)ira模块由conv+bn+relu+conv+bn+relu+conv+bn+cbam模块组成,其中conv为常规卷积,3个conv的核分别为1*1,3*3,1*1,步长默认为1;模块中设置有expansion系数,用来控制ira中3*3模块的放大通道倍数;ira为一个倒残差注意力结构,输出与输入同型,中间通道数变换为c*expansion,可以提取更多的语义信息,并对语义信息进行总结,更为直接的是倒残差结构设计可以让内存效率提高更多,并且还可以提升梯度在反向传播中的能力,便于训练;大小均为(n,c,h,w),分别代表图像的批次、通道、宽度、高度;
[0066]
2)输入图像先经过conv模块,输入通道为c,输出通道为c,参数中核为1*1,步长为1*1,padding默认为1,bias设置为flase;
[0067]
3)特征图经过bn模块,通道数为c;
[0068]
4)特征图经过relu模块,进行激活;
[0069]
5)输入图像先经过conv模块,输入通道为c,输出通道为c*expansion,参数中核为3*3,步长为1*1,padding默认为1,bias设置为flase;
[0070]
6)特征图经过bn模块,通道数为c*expansion;
[0071]
7)特征图经过relu模块,进行激活;
[0072]
8)输入图像先经过conv模块,输入通道为c*expansion,输出通道为c*expansion,参数中核为1*1,步长为1*1,padding默认为1,bias设置为flase;
[0073]
9)特征图经过bn模块,通道数为c*expansion;
[0074]
10)特征图经过cbam模块,计算获取到注意力特征;
[0075]
11)将原始特征与注意力特征经过加和操作得到最终结果;形状为(n,c,h,w),由此一个ira操作完成。
[0076]
cbam模块包含2个独立的子模块,分别为通道注意力模块和空间注意力模块,分别进行通道与空间上的attention;这样不只能够节约参数和计算力,并且保证了其能够做为即插即用的模块集成到现有的网络架构中去。cbam模块计算的步骤如下:
[0077]
a)将输入的特征图f(h
×w×
c)分别经过基于width和height的global max pooling(全局最大池化)和global average pooling(全局平均池化),得到两个1
×1×
c的特征图,合并特征送入下一层;
[0078]
b)再将它们分别送入一个两层的conv2d,第一层通道数为输入为c,输出为c/r(r为减少率)核为1,stride为1,bias=false,激活函数为relu,;第二层通道数为输入为c/r,输出为c,核为1,stride为1,bias=false,这个两层的神经网络是共享的;
[0079]
c)再经过sigmoid激活操作,生成最终的channel attention feature,即m_c;
[0080]
d)最后,将m_c和输入的特征图f做element-wise乘法操作,生成spatial attention模块需要的输入特征;
[0081]
e)将channel attention模块输出的特征图f作为本模块的输入特征图;首先做一个基于channel的global max pooling和global average pooling,得到两个h
×w×
1的特征图;
[0082]
f)然后将这2个特征图基于channel做concat操作(通道拼接);
[0083]
g)然后经过一个7
×
7卷积(7
×
7比3
×
3,7x7卷积拥有更大的感受野,效果要好)操作;
[0084]
h)降维为1个channel,即h
×w×
1;再经过sigmoid生成spatial attention feature,即m_s;
[0085]
i)最后将该feature和该模块的输入feature做乘法,得到最终生成的注意力特征。
[0086]
b)stage1层特征获取:经过ira,由于ira不改变特征形状,这里不再赘述,设置输出的通道分别为3,16,16,获取到stage1层特征;
[0087]
c)将stage1特征进行maxpooling最大池化,池化核为2*2,再经过3个ira操作,输出通道为32,32,32;最终获取stage2特征;
[0088]
d)将stage2特征进行maxpooling最大池化,池化核为2*2,再经过3个ira操作,输出通道为64,64,64;最终获取stage3特征;
[0089]
e)将stage3特征进行maxpooling最大池化,池化核为2*2,再经过3个ira操作,输出通道为128,128,128;最终获取stage4特征;
[0090]
f)将stage4特征进行maxpooling最大池化,池化核为2*2,再经过3个ira操作,输出通道为256,256,256;最终获取stage5特征;
[0091]
g)将stage5特征通过反卷积上采样,输出通道设置为256,宽度和高度缩短为之前的2倍,并且与copied(复制)的stage4特征进行拼接。再经过3个ira操作,输出通道为128,128,128;最终获取stage4_1特征;
[0092]
h)将stage4_1特征通过反卷积上采样,输出通道设置为128,宽度和高度缩短为之前的2倍,并且与copied的stage3特征进行拼接。再经过3个ira操作,输出通道为64,64,64;最终获取stage3_1特征;
[0093]
i)将stage3_1特征通过反卷积上采样,输出通道设置为32,宽度和高度缩短为之前的2倍,并且与copied的stage2特征进行拼接。再经过3个ira操作,输出通道为32,32,32;最终获取stage2_1特征;
[0094]
j)将stage2_1特征通过反卷积上采样,输出通道设置为16,宽度和高度缩短为之前的2倍,并且与copied的stage1特征进行拼接。再经过3个ira操作,输出通道为16,16,16;最终获取stage1_1特征;
[0095]
k)将stage1_1特征,再经过3个ira操作,输出通道为16,1,1;得到最终特征图image
pred
。
[0096]
三、损失计算,模型输出的特征图与真实的数据标签;对生成器图像数据进行训练损失计算作为最优化目标,这样转化的高分辨率图像更加真实;
[0097]
训练损失计算如下:
[0098]
计算真实原始图片与模型计算所得高分图片之间的损失代价衡量,其中loss计算如下:
[0099]
①
mse loss计算:
[0100][0101]
代表总的mse损失,为真实图片对应的分类值;经过模型计算后的对应宽高图片对应的分类值;w,h分别代表宽度和高度;x,y代表目标位置索引;
[0102]
②
perceptual loss计算:
[0103]
原代价函数mse使去噪结果具有较高的信噪比psnr,但是缺少了高频信息和过度平滑纹理的出现;经过perceptual loss先验的加入,去噪后的图像与真实的图像相比无论是低层次的像素值上,还是高层次的抽象特征上,还是在整体概念和风格上都相当接近;
[0104][0105]
代表感知损失,cj为通道,w,h分别代表图像的宽度和高度;φj(x)
h,w,c
为
真实图像在已训练resnet50残差网络中的第11层、24层、42、50层模型推理计算出来的感知特征图;φj(x)
h,w,c'
为对应去噪图像在已训练resnet50模型推理计算出来的感知特征图。
[0106]
四、重复步骤二和三,经过多次迭代和图像分辨率类别判断,并对图像数据按损失占比权重(实验占比为8:2,也就是权重为0.8和0.2)进行最优化;最终利用训练好的模型器模型输出噪点结果,从而实现噪点的去除。
[0107]
本实施例只采用两个模块,算法更为简单直观,利用编解码模型能够实现对噪声图像图像经过训练得到所需去噪原始图像数据,采用残差50网络的不同特征计算模块,利用边缘模块信息建立特征图信息作为先验损失,获得更为准确的去噪图像。
[0108]
本实施例避免了以往方法中出现的重建结果有较高的信噪比psnr,高频信息缺少,过度平滑纹理的出现等问题。本实施例所获得的去噪图像与真实的图像无论是低层次的像素值上,还是高层次的抽象特征上,或是整体概念和风格上都与真实图像数据相当接近。在风格重建时具有以下优点高层特征、全局结构、纹理明显。去噪时图像底层特征、边缘、颜色等细节信息较多,效果更好。
[0109]
以上示意性的对本发明及其实施方式进行了描述,该描述没有限制性,附图中所示的也只是本发明的实施方式之一,实际的结构并不局限于此。所以,如果本领域的普通技术人员受其启示,在不脱离本发明创造宗旨的情况下,不经创造性的设计出与该技术方案相似的结构方式及实施例,均应属于本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1