一种结合图像增强与图像融合的暗图像复原迭代神经网络方法
1.本发明涉及低光照图像增强和复原的多媒体技术领域,特别是指一种结合图像增强与图像融合的暗图像复原迭代神经网络方法,尤其适用于光照不均匀的低光照图像。
背景技术:
2.随着低光照图像增强和复原技术的发展,其中非均匀低光照图像以其难以恢复的特点逐渐被重视。目前大多数图像增强方法大多集中在全局亮度增强上,而忽略了偏色和局部过曝的问题,这难以满足人眼视觉感受和机器进行进一步操作的要求。
3.在社会安全管理方面,低光照图像增强处理也应用到交通监控中,通过电视跟踪技术锁定目标位置,比如对夜间图像、交通事故的分析等,为相关部门提供了强有力的技术支持。近年来,自动驾驶、智能交通技术的研发成为一大热门方向,摄像监控设备和传感器所获得的图像的清晰度是决定此类技术稳定性和可靠性的重要因素。现实世界中的光照环境十分复杂,尤其是在室外,不同物体间甚至同个物体的不同区域的光照不一致往往会给传感设备传递错误的信息。因此一个高效的针对非均匀光照恢复和增强方法的提出十分有必要,将具有非常好的应用前景。
技术实现要素:
4.本发明首先模拟现实世界中的光照,提出了一种结合图像增强与图像融合的暗图像复原迭代神经网络方法。本发明通过基于超像素的成对非均匀低光照图像数据集的制作流程和基于深度学习的增强融合迭代网络框架用于低照度图像增强。
5.本发明采用的方案如下:
6.一种结合图像增强与图像融合的暗图像复原迭代神经网络方法,包括如下步骤:
7.步骤一:训练数据生成:基于超像素块,制作成对非均匀低光照图像数据集;制作流程如下:
8.1)将输入的长为h、宽为w的正常光照图像i
normal
,通过超像素分割算法得到同尺寸的单通道超像素标签图i
label
;pi∈[1,n]代表超像素标签图i
label
中第i个像素的标签值,i=1,2,3,...,h
×
w,n是设定的超像素块数量;
[0009]
超像素标签图i
label
中相同标签值的像素会形成连通区域,即超像素块;
[0010]
2)根据正常光照图像i
normal
对超像素标签图i
label
中的超像素块进行合并:计算超像素标签图i
label
中的每个超像素块在正常光照图像i
normal
中对应像素的颜色平均值,具体公式如下:
[0011]
[0012]
其中代表正常光照图像i
normal
中第j个超像素块的像素颜色均值,ci表示正常光照图像i
normal
第j个超像素块中第i个像素的颜色值,nj代表第j个超像素块中的像素数量,j=1,2,3,...,n;
[0013]
根据阈值τ对相邻的超像素块进行合并:如果在图像空间中相邻超像素块的像素颜色均值的差值小于阈值τ,将它们所包含的像素在超像素标签图i
label
上的标签值设为相同值;通过遍历所有的超像素块完成超像素块的合并过程,合并后的超像素标签图i
label
中有n
new
个超像素块;
[0014]
3)对合并后的超像素块进行随机亮度调整;将正常光照图像i
normal
由rgb颜色空间转换为hsv颜色空间,分别遍历合并后的n
new
个超像素块并对其执行如下亮度调整操作:
[0015][0016]
其中,vn代表正常光照图像i
normal
中第n个超像素块的v亮度通道,v
′n代表经过随机亮度调整后第n个超像素块的亮度通道v,||表示或运算符;q是取值范围在[0,2]的随机数,当q=0时,执行调亮操作,表示对vn进行伽马校正,其中γ1∈[0.55,0.8];当q=1或q=2时,执行调暗操作,表示先对vn进行伽马校正,其中γ2∈[1.5,1.6],再通过线性因子r∈[0.3,0.55]进一步进行线性调整;γ1、γ2、r均服从随机均匀分布;对所有的超像素块进行亮度调整后,得到调整后的亮度通道v
′
;
[0017]
4)对随机亮度调整后的亮度通道v
′
进行引导滤波操作,公式如下:
[0018]v′
gf
=gf(v
′
,v
normal
,64,0.0001)
[0019]
其中,v
′
gf
表示经过引导滤波后的亮度通道,gf(
·
,
·
,
·
,
·
)表示引导滤波操作,正常光照图像i
normal
的亮度通道v
normal
作为引导滤波参考图像,64是引导滤波核的边长,0.0001是正则化参数;
[0020]
5)将经过引导滤波后的亮度通道v
′
gf
与正常光照图像i
normal
的色度通道h
normal
、饱和度通道s
normal
进行合并,并从hsv颜色空间转换到rgb颜色
[0021]
空间,得到非均匀低光照图像i
dark
:
[0022]idark
=hsv2rgb(h
normal
,s
normal
,v
′
gf
)
[0023]
hsv2rgb(
·
,
·
,
·
)代表将hsv颜色空间转换到rgb颜色空间;
[0024]
步骤二:网络框架设计。本发明通过模拟低光照图像到正常光照图像的映射关系来实现图像的光照增强和复原,其实施步骤为:
[0025]
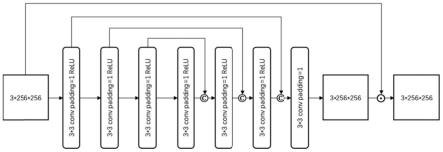
(1)参照图1,设计基于7层卷积层和激活函数的轻量级拉伸系数估计网络n1:
[0026]
其中在n1的第一层和第七层、第二层和第六层、第三层和第五层之间加入了跳跃链接,采用的激活函数为relu,公式为:
[0027]
k=n1(i
dark
)
[0028]
k为拉伸系数估计网络n1得到的拉伸系数图。
[0029]
(2)通过点乘的方式将输入图像i
dark
和拉伸系数图k进行结合,得到初始增强结果,公式为:
[0030]
e=k
⊙idark
[0031]
e为本次迭代的初始增强结果,
⊙
是点乘算子。
[0032]
(3)将初始增强结果e和输入图像i
dark
输入融合网络n2,如图2。融合网络n2首先通过权重共享的编码器en获取初始增强结果e和输入图像i
dark
的潜层特征,再通过解码器de得到本次迭代的最终增强结果,公式如下:
[0033]e′
=n2(i
dark
,e)
[0034][0035]
其中,e
′
是本次迭代的最终增强结果,n2(
·
,
·
)为融合网络的表达形式,en(
·
)和de(
·
)分别为编码器和解码器的表达形式,表示特征堆叠。
[0036]
(4)使用本次迭代得到的最终增强结果e
′
代替输入图像i
dark
,作为下一次迭代的输入图像,重复步骤(1)至(3)共n次,得到本发明的最终增强结果e
′n。整个网络的流程可以表示为:
[0037][0038]
本发明将迭代次数n设置为3。
[0039]
步骤三:图像预处理:将正常光照图像i
normal
作为非均匀低光照图像i
dark
的真实标签图像;将非均匀低光照图像i
dark
及其对应的真实标签图像i
normal
作为训练数据,将其rgb三通道的颜色值归一化至[0,1]的范围,截取规定大小的图像块作为训练样本;
[0040]
步骤四:训练参数设置:在训练阶段只针对最后一轮的结果加以损失函数约束,训练时使用的优化器为adam,学习率设置为0.0001,总共训练400轮次,样本批处理的参数设置为8;
[0041]
步骤五:训练模型:将步骤一合成的训练图像对输入模型,并输出增强后的图像,通过损失函数计算损失,进行模型参数调优;
[0042]
所述步骤五是在深度学习框架pytorch上实现和训练的;
[0043]
所述模型解码器de的输出为与输入低光照图像对应的增强结果,这些增强结果具有和训练输入图像相同的尺寸(256
×
256),每个输出受与之相对应的损失函数的约束,整个网络的损失函数表达式为:
[0044][0045]
其中表示网络整体的损失函数,和分别表示重建损失、感知损失、结构损失和颜色损失;
[0046]
为基于平均绝对误差的重建损失函数,公式为:
[0047][0048]
其中e
′n和i
normal
分别为最终增强结果和其对应的真实标签图像,|
·
|1为平均绝对误差函数;
[0049]
为感知损失,本发明根据预训练vgg-16网络的relu激活层的输出定义了感知损失,具体形式如下:
[0050][0051]
其中φ
ij
(
·
)表示使用预训练vgg-16网络中第i个卷积块第j个卷积层提取图像的特征图,w
ij
、h
ij
和c
ij
为特征图φ
ij
在x、y和z三个维度上的长度,||
·
||2为均方误差函数;
[0052]
为结构损失,具体形式为:
[0053][0054]
其中,ssim(
·
,
·
)为结构相似性算子,即
[0055][0056]
其中μ(e
′n)和μ(i
normal
)分别是最终增强结果e
′n和其对应真实标签图像i
normal
的平均像素颜色值;σ(e
′n)2和σ(i
normal
)2分别是最终增强结果e
′n和其对应真实标签图像i
normal
的像素颜色方差,σ(e
′n,i
normal
)是最终增强结果e
′n和其对应真实标签图像i
normal
的像素颜色协方差;c1和c2是防止分母为零的两个常数,设置为0.000001;
[0057]
为颜色损失,用于保持增强图像的颜色,具体形式如下:
[0058][0059]
其中(e
′n)
p
和(i
normal
)
p
分别为最终增强结果e
′n及其对应的真实标签图像i
normal
上第p个像素的颜色值,m为像素总数;∠(
·
,
·
)是一个算子,它将像素的rgb颜色视为三维向量,计算两个像素颜色向量之间的夹角大小;
[0060]
步骤五得到的结果通过深度学习框架库提供的反向传播算法进行网络参数更新;
[0061]
步骤五输出的结果收敛时,步骤五停止;
[0062]
步骤六:对低光照图像进行测试,得到与输入图像大小一致的增强图像,将其重新映射到[0,255]之间,得到增强结果图。
[0063]
其中:
[0064]
所述步骤三中,将颜色值归一化至[0,1]的范围的方法是将颜色值除以255;规定大小是指截取得到的图像分辨率为256
×
256,选取截取区域的方法为无重叠的顺序采样。
[0065]
所述步骤五是在深度学习框架pytorch上实现和训练的。
[0066]
所述的步骤六中的输入图像是真实低光照图像。
[0067]
本发明的有益效果是:通过探究真实环境光照的特点,合成了非均匀光照图像数据集,避免了人工数据集和实拍数据集存在的问题,并且针对之前的基于深度学习的低光照图像增强算法所遇到的问题,在深度学习模型中提出了相对应的策略,以先粗略增强后融合细化的方式,同时结合迭代增强的思想,将输入的低光照图像逐步增强和恢复其光照。
附图说明
[0068]
图1是基于7层卷积层和激活函数的轻量级拉伸系数估计网络。
[0069]
图2是融合网络。
具体实施方式
[0070]
在实现有低光照图像的增强和复原过程中,直接使用本发明即可。
[0071]
步骤一:训练数据生成。基于超像素块的成对非均匀低光照图像数据集的制作流程,
[0072]
1)将输入的长为h、宽为w的正常光照图像i
normal
,通过超像素分割算法得到同尺寸的单通道超像素标签图i
label
。pi∈[1,n]代表超像素标签图i
label
中第i个像素的标签值,i=1,2,3,...,h
×
w,n是设定的超像素块数量。超像素标签图i
label
中相同标签值的像素会形成连通区域,即超像素块。
[0073]
2)根据正常光照图像i
normal
对超像素标签图i
label
中的超像素块进行合并:计算超像素标签图i
label
中的每个超像素块在正常光照图像i
normal
中对应像素的颜色平均值,具体公式如下:
[0074][0075]
其中代表正常光照图像i
normal
中第j个超像素块的像素颜色均值,ci表示正常光照图像i
normal
第j个超像素块中第i个像素的颜色值,nj代表第j个超像素块中的像素数量,j=1,2,3,...,n。
[0076]
根据阈值τ对相邻的超像素块进行合并:如果在图像空间中相邻超像素块的像素颜色均值的差值小于阈值τ,将它们所包含的像素在超像素标签图i
label
上的标签值设为相同值。通过遍历所有的超像素块完成超像素块的合并过程,合并后的超像素标签图i
label
中有n
new
个超像素块。
[0077]
3)对合并后的超像素块进行随机亮度调整。将正常光照图像i
normal
由rgb颜色空间转换为hsv颜色空间,分别遍历合并后的n
new
个超像素块并对其执行如下亮度调整操作:
[0078][0079]
其中,vn代表正常光照图像i
normal
中第n个超像素块的v亮度通道,v
′n代表经过随机亮度调整后第n个超像素块的亮度通道v,||表示或运算符。q是取值范围在[0,2]的随机数,当q=0时,执行调亮操作,表示对vn进行伽马校正,其中γ1∈[0.55,0.8];当q=1或q=2时,执行调暗操作,表示先对vn进行伽马校正,其中γ2∈[1.5,1.6],再通过线性因子r∈[0.3,0.55]进一步进行线性调整。γ1、γ2、r均服从随机均匀分布。对所有的超像素块进行亮度调整后,得到调整后的亮度通道v
′
。
[0080]
4)对随机亮度调整后的亮度通道v
′
进行引导滤波操作,公式如下:
[0081]v′
gf
=gf(v
′
,v
normal
,64,0.0001)
[0082]
其中,v
′
gf
表示经过引导滤波后的亮度通道,gf(
·
,
·
,
·
,
·
)表示引导滤波操作,正常光照图像i
normal
的亮度通道v
normal
作为引导滤波参考图像,64是引导滤波核的边长,0.0001是正则化参数。
[0083]
5)将经过引导滤波后的亮度通道v
′
gf
与正常光照图像i
normal
的色度通道h
normal
、饱和度通道s
normal
进行合并,并从hsv颜色空间转换到rgb颜色空间,得到非均匀低光照图像i
dark
:
[0084]idark
=hsv2rgb(h
normal
,s
normal
,v
′
gf
)
[0085]
hsv2rgb(
·
,
·
,
·
)代表将hsv颜色空间转换到rgb颜色空间。
[0086]
步骤二:网络框架设计。本发明通过模拟低光照图像到正常光照图像的映射关系来实现图像的光照增强和复原,其实施步骤为:
[0087]
(1)参照图1,设计基于7层卷积层和激活函数的轻量级拉伸系数估计网络n1:
[0088]
其中在n1的第一层和第七层、第二层和第六层、第三层和第五层之间加入了跳跃链接,采用的激活函数为relu,公式为:
[0089]
k=n1(i
dark
)
[0090]
k为拉伸系数估计网络n1得到的拉伸系数图。
[0091]
(2)通过点乘的方式将输入图像i
dark
和拉伸系数图k进行结合,得到初始增强结果,公式为:
[0092]
e=k
⊙idark
[0093]
e为本次迭代的初始增强结果,
⊙
是点乘算子。
[0094]
(3)将初始增强结果e和输入图像i
dark
输入融合网络n2,如图2。融合网络n2首先通过权重共享的编码器en获取初始增强结果e和输入图像i
dark
的潜层特征,再通过解码器de得到本次迭代的最终增强结果,公式如下:
[0095]e′
=n2(i
dark
,e)
[0096][0097]
其中,e
′
是本次迭代的最终增强结果,n2(
·
,
·
)为融合网络的表达形式,en(
·
)和de(
·
)分别为编码器和解码器的表达形式,表示特征堆叠。
[0098]
(4)使用本次迭代得到的最终增强结果e
′
代替输入图像i
dark
,作为下一次迭代的输入图像,重复步骤(1)至(3)共n次,得到本发明的最终增强结果e
′n。整个网络的流程可以表示为:
[0099][0100]
本发明将迭代次数n设置为3。
[0101]
步骤三:图像预处理。将正常光照图像i
normal
作为非均匀低光照图像i
dark
的真实标签图像。将非均匀低光照图像i
dark
及其对应的真实标签图像i
normal
作为训练数据,将其rgb
三通道的颜色值归一化至[0,1]的范围,截取规定大小的图像块作为训练样本;
[0102]
所述步骤三中,将颜色值归一化至[0,1]的范围的方法是将颜色值除以255;规定大小是指截取得到的图像分辨率为256
×
256,选取截取区域的方法为无重叠的顺序采样。
[0103]
步骤四:训练参数设置。在训练阶段只针对最后一轮的结果加以损失函数约束,训练时使用的优化器为adam,学习率设置为0.0001,总共训练400轮次,样本批处理的参数设置为8;
[0104]
步骤五:训练模型。将步骤一合成的训练图像对输入模型,并输出增强后的图像,通过损失函数计算损失,进行模型参数调优;
[0105]
所述步骤五是在深度学习框架pytorch上实现和训练的。
[0106]
所述模型解码器的输出为与输入低光照图像对应的增强结果,这些增强结果具有和训练输入图像相同的尺寸(256
×
256),每个输出受与之相对应的损失函数的约束,整个网络的损失函数表达式为:
[0107][0108]
其中表示网络整体的损失函数。和分别表示重建损失、感知损失、结构损失和颜色损失。
[0109]
为基于平均绝对误差的重建损失函数,公式为:
[0110][0111]
其中e
′n和i
normal
分别为最终增强结果和其对应的真实标签图像。|
·
|1为平均绝对误差函数。
[0112]
为感知损失,本发明根据预训练vgg-16网络的relu激活层的输出定义了感知损失,具体形式如下:
[0113][0114]
其中φ
ij
(
·
)表示使用预训练vgg-16网络中第i个卷积块第j个卷积层提取图像的特征图,w
ij
、h
ij
和c
ij
为特征图φ
ij
在x、y和z三个维度上的长度。||
·
||2为均方误差函数。
[0115]
为结构损失,具体形式为:
[0116][0117]
其中,ssim(
·
,
·
)为结构相似性算子,即
[0118][0119]
其中μ(e
′n)和μ(i
normal
)分别是最终增强结果e
′n和其对应真实标签图像i
normal
的平均像素颜色值。σ(e
′n)2和σ(i
normal
)2分别是最终增强结果e
′n和其对应真实标签图像i
normal
的像素颜色方差,σ(e
′n,i
normal
)是最终增强结果e
′n和其对应真实标签图像i
normal
的像素颜色协方差。c1和c2是防止分母为零的两个常数,设置为1e-6。
[0120]
为颜色损失,用于保持增强图像的颜色,具体形式如下:
[0121][0122]
其中(e
′n)
p
和(i
normal
)
p
分别为最终增强结果e
′n及其对应的真实标签图像i
normal
上第p个像素的颜色值,m为像素总数。∠(
·
,
·
)是一个算子,它将像素的rgb颜色视为三维向量,计算两个像素颜色向量之间的夹角大小。
[0123]
所述的步骤五得到的结果通过深度学习框架库提供的反向传播算法进行网络参数更新。
[0124]
所述步骤五输出的结果收敛时,步骤五停止。
[0125]
步骤六:对低光照图像进行测试,得到与输入图像大小一致的增强图像,将其重新映射到[0,255]之间,得到增强结果图。
[0126]
所述的步骤六中的输入图像是真实低光照图像。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1