基于域不变特征的泛化人脸伪造检测方法
1.本发明涉及多媒体的技术领域,尤其是指一种基于域不变特征的泛化人脸伪造检测方法。
背景技术:
2.随着信息技术的不断发展,使得图像、视频、音频等成为信息传播的主要载体,但是,随着深度学习的发展,让图像和视频的伪造也变得更加容易。人们只需要使用一些先进的深度学习工具如对抗生成网络等,就可以轻松的创造出肉眼难以识别的伪造图片或视频。由于人脸信息非常重要,于是出现了一系列人脸伪造图像,从而起到欺骗他人、传播谣言等目的。因此,如何有效的检测人脸伪造图像成了图像取证领域的热门研究方向。
3.人脸伪造检测任务可以看作是一个二分类任务,即通过提取输入图像中存在的篡改痕迹来判断图像是否为人脸伪造图像。受益于深度学习的发展,目前大多数人脸伪造检测方法都是基于深度学习的的方法。这些方法通常都是使用特征变换网络来提取输入图像的篡改痕迹,再通过一个分类器得到二分类结果即输入人脸是否为伪造人脸。当训练集和测试集都来自于相同的人脸伪造技术时,这些方法可以实现不错的检测效果。但是当训练集和测试集由不同的人脸伪造技术生成时,不同人脸伪造技术可能会留下不同的篡改痕迹,所以这些人脸伪造检测方法的性能都出现了不同程度的大幅下降。最近,也出现了一些工作致力于解决人脸伪造检测的泛化问题。这些结合域迁移或者域泛化的思想的方法在一定程度上提高了模型的泛化性能,但是还存在着很大的进步空间。因此,如何更好的利用多个已知源域的数据集,并去消除它们数据分布之间的偏差来学习共有的判别特征用于进一步提高模型的泛化能力仍是一个很大的挑战。
技术实现要素:
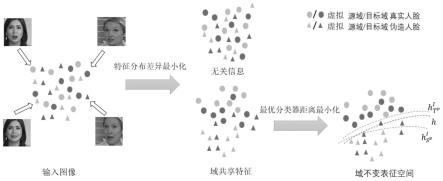
4.本发明的目的在于克服现有技术的缺点与不足,提出了一种基于域不变特征的泛化人脸伪造检测方法,该方法架构中包括特征分布差异最小化网络fddm和最优分类器距离最小化网络ocdm。先通过将多个已知的源域数据集模拟划分为虚拟源域和虚拟目标域,再使用fddm用于最小化虚拟源域和虚拟目标域之间的特征分布差异来学习域共享特征,紧接着通过ocdm对域共享特征空间进行调整以减小虚拟源域和虚拟目标域之间的最优分类器距离。通过不断迭代的随机划分虚拟源域和虚拟目标域,以及使用fddm和ocdm,就可以学习到合适的域不变表征以及可以大幅提升模型在未知目标域上的泛化性能。
5.为实现上述目的,本发明所提供的技术方案为:基于域不变特征的泛化人脸伪造检测方法,包括以下步骤:
6.1)构建训练图像集
7.获取大量的由不同的人脸伪造方法生成的人脸伪造图像和对应的正常人脸图像,将其都缩放到同一个尺寸并按照生成的人脸伪造方法的不同将这些人脸伪造图像和对应的正常人脸图像划分到不同的源域数据集中;将这些不同源域数据集归纳起来就得到了训
练图像集;
8.2)用步骤1)中构建的训练图像集来训练构建的域不变特征表征学习的人脸伪造检测网络,并得到最优的域不变特征表征学习的人脸伪造检测网络的权重参数;其中所述人脸伪造检测网络包括特征分布差异最小化网络fddm和最优分类器距离最小化网络ocdm;先将构建的训练图像集中的多个源域数据集模拟划分为虚拟源域和虚拟目标域,接着fddm通过解耦的方式从划分的虚拟源域和虚拟目标域中学习到共享的域共享特征,而ocdm对学习到的域共享特征做进一步调整使得其转为域不变特征,通过不断迭代的随机划分虚拟源域和虚拟目标域,以及使用fddm和ocdm,从而获取一个合适的域不变特征表征来进行泛化人脸伪造检测;
9.3)应用步骤2)中构建的域不变特征表征学习的人脸伪造检测网络和最优的域不变特征表征学习的人脸伪造检测网络的权重参数对待测的输入图像给出预测结果,即输入图像是否为人脸伪造图像。
10.进一步,在步骤1)中,对于获取到的大量的由不同的人脸伪造方法生成的人脸伪造图像和对应的正常人脸图像,将其都缩放到h
×
w大小的尺寸,其中h和w分别为图像的长度和宽度;并按照生成的人脸伪造方法的不同将这些人脸伪造图像和对应的正常人脸图像划分到不同的源域数据集中,对于得到的m个源域数据集s={si|i=1,2,...m},其中si代表第i个源域数据集,它包含numi张图像。
11.进一步,所述步骤2)包括以下步骤:
12.2.1)将构建的训练图像集中的m个源域数据集s模拟划分为虚拟源域sv和虚拟目标域tv;
13.2.2)构建域不变特征表征学习的人脸伪造检测网络中的特征分布差异最小化网络fddm,该特征分布差异最小化网络fddm包括特征提取器ge、解码器特征选择gs、类判别器d
ψ
、分类器c和m个域判别器d
μi
,i∈{1,2,...,m};特征提取器ge和解码器均由多个卷积模块堆叠而成,不同的是,特征提取器ge的每个卷积模块后都跟着一个最大池化层,而解码器的每个卷积模块后都跟着一个上采样层;特征选择gs为一步特征划分的操作,不包含具体的网络结构;类判别器d
ψ
和域判别器d
μi
的网络结构相同,它们均由多个卷积模块堆叠而成;分类器c则是由多个卷积模块、一个平均池化层和一个全连接层组成;
14.对于从虚拟源域sv和虚拟目标域tv随机得到的第j张输入图像xj,特征z_exj是通过特征提取器ge从输入图像xj提取到的特征,并将特征z_exj输入到解码器来得到重构图像,以及通过最小化输入图像和重构图像之间的均方误差损失l
rec
对其进行约束,使得特征提取器提取到输入图像的完整信息:
[0015][0016]
式中,n表示这次从虚拟源域和虚拟目标域中选取的样本数量;特征z_exj通过特征选择gs划分为特征z_irj和特征z_dsj;特征z_dsj作为分类器c的输入来预测输入图像的标签,并通过最小化输入图像的预测结果和输入图像的标签之间的交叉熵损失l
cls
来约束特征z_dsj代表类相关特征:
[0017][0018]
式中,yj代表第j张输入图像的标签;而特征z_irj则作为类判别器d
ψ
的输入也来预测输入图像的标签,并且通过最小化输入图像的预测结果和输入图像的标签之间的负交叉熵损失l
cdis
来约束特征z_irj代表类无关特征:
[0019][0020]
接着利用对抗训练的方法将特征z_irj和特征z_dsj均作为类判别器的输入来预测输入图像的标签,并最小化输入图像的预测结果和输入图像的标签的交叉熵损失l
ent
来训练类判别器d
ψ
将特征z_irj和特征z_dsj两者相互解耦开来:
[0021][0022]
式中,1代表指示函数,k代表分类类别,即该预测任务为二分类任务,域判别器d
μi
不考虑虚拟源域和虚拟目标域而直接去最小化来自源域数据集每个域的特征z_dsj的分布差异,使得特征z_dsj为m个源域数据集共享的域共享特征;对于第i个域判别器d
μi
,用于判别特征z_dsj是否属于第i个源域数据集,其对应的损失函数l
disi
表示为:
[0023][0024]
式中,z_ds
ji
代表来自第i个域的第j张输入图像的特征,相应的,z_ds
jr
代表来自第r个域的第j张输入图像的特征,且r≠i;结合m个域判别器的损失函数,就使得来自第i个域的特征z_ds
ji
与剩下的m-1个源域数据集的特征分布差异最小;m个判别器的损失函数l
dis
表示为:
[0025][0026]
fddm整体优化目标的损失函数l
fddm
为:
[0027]
l
fddm
=l
rec
+l
cdis
+l
cls
+l
dis
ꢀꢀꢀ
(7)
[0028]
2.3)构建域不变特征表征学习的人脸伪造检测网络中的最优分类器距离最小化网络ocdm,该最优分类器距离最小化网络ocdm由特征提取器ge、特征选择器gs和分类器h组成,其中特征提取器ge、特征选择器gs都来自于特征分布差异最小化网络fddm,分类器h由多个卷积模块、一个平均池化层和一个全连接层组成;ocdm网络通过两阶段更新的方法调整最优的虚拟源域分类器和最优的虚拟目标域分类器之间的距离来调整学习到的域共享特征,从而得到域不变特征;
[0029]
在第一阶段,对于从虚拟源域sv随机得到的第j张输入图像将其作为ocdm的输入去预测输入图像的标签,并最小化输入图像的预测结果和输入图像的标签的交叉熵损失l
meta-train
:
[0030]
[0031]
式中,l代表交叉熵损失函数,φ(ge,h)代表ocdm中特征提取器ge和分类器h的权重参数,而为输入图像相对应的标签;ocdm相对于损失函数l
meta-train
的梯度为通过该梯度将ocdm中特征提取器ge和分类器h的权重参数更新为其中α代表这一步更新的步长;
[0032]
在第二阶段,对于从虚拟源域tv随机得到的第j张输入图像将其作为第一阶段更新的ocdm的输入来预测输入图像的标签,并最小化输入图像的预测结果和输入图像的标签的交叉熵损失l
meta-test
:
[0033][0034]
式中,为输入图像相对应的标签;
[0035]
ocdm整体优化目标的损失函数l
ocdm
为:
[0036][0037]
式中,β代表比例参数来平衡ocdm两个阶段的损失函数的比例;
[0038]
2.4)初始化域不变特征表征学习的人脸伪造检测网络中特征分布差异最小化网络fddm和最优分类器距离最小化网络ocdm中各个部分的权重参数,包括特征提取器ge的权重参数解码器的权重参数类判别器d
ψ
和m个域判别器d
μi
的权重参数和分类器c和分类器h的权重参数wc和wh;初始化迭代次数e=1;
[0039]
2.5)将构建的训练图像集中的m个源域数据集s随机划分为虚拟源域sv和虚拟目标域tv;初始化迭代次数t=1;
[0040]
2.6)固定fddm中类判别器d
ψ
和m个域判别器d
μi
的权重参数;从虚拟源域sv和虚拟目标域tv中随机选取n个样本构成训练对,并去计算fddm整体优化目标的损失函数l
fddm
;根据计算得到的fddm整体优化目标的损失函数l
fddm
来分别计算fddm中特征提取器ge、解码器和分类器c的梯度并反向传播更新各个部分的权重参数:
[0041][0042][0043][0044]
在公式(11)、(12)和(13)中,η为给定的学习率,和分别代表特征提取器ge、解码器和分类器c的梯度;
[0045]
2.7)固定fddm中特征提取器ge的权重参数;从虚拟源域sv和虚拟目标域tv中随机选取n个样本构成训练对,并去计算公式(4)的损失函数l
ent
和公式(5)的m个域判别器d
μi
的损失函数l
disi
;根据损失函数l
ent
计算fddm中类判别器d
ψ
的梯度并反向传播更新类判别器d
ψ
的权重参数:
[0046][0047]
式中,为类判别器d
ψ
的梯度;因为有m个域判别器d
μi
,即需要分别对每一个域判别器的权重参数进行更新,第i个域判别器d
μi
的权重参数更新过程表示为:
[0048][0049]
式中,为第i个域判别器d
μi
的梯度;
[0050]
2.8)从虚拟源域sv和虚拟目标域tv中随机选取n个样本构成训练对,并去计算ocdm整体优化目标的损失函数l
ocdm
;根据计算得到的ocdm整体优化目标的损失函数l
ocdm
来分别计算ocdm中特征提取器ge和分类器h的梯度并反向传播更新各个部分的权重参数:
[0051][0052][0053]
在公式(16)和(17)中,和分别代表特征提取器ge和分类器h的梯度;
[0054]
2.9)更新迭代次数t=t+1,并判断迭代条件是否满足其中和分别为虚拟源域sv和虚拟目标域tv的总样本数量,n为每次迭代的样本数;如满足条件,则转至步骤2.6);否则,进入步骤2.10);
[0055]
2.10)更新迭代次数e=e+1,并判断迭代条件是否满足e≤e,其中e代表训练的epoch数;如满足,则转至步骤2.5);否则,保存此时最优的域不变特征表征学习的人脸伪造检测网络的权重参数并退出迭代。
[0056]
本发明与现有技术相比,具有如下优点与有益效果:
[0057]
1、本发明提出了一种特征分布差异最小化网络fddm通过联合解耦和生成对抗训练的思想来最小化来自各个源域的特征分布差异,从而提取到多个源域共享的域共享特征。
[0058]
2、本发明提出了一种最优分类器距离最小化网络ocdm通过元学习的思想对给定的特征空间进行进一步调整,使得在这个特征空间上可以学习到一个理想分类器,它既是最优的虚拟源域分类器也是最优的虚拟目标域分类器。
[0059]
3、本发明通过结合fddm和ocdm可以从多个源域数据集中学习到一个合适的域不变特征表征,可以有效提升模型在未知的目标域上的泛化性能且优于现存的一系列人脸伪造检测方法。
附图说明
[0060]
图1为本发明方法的架构图。
[0061]
图2为特征分布差异最小化网络fddm的网络结构图。
[0062]
图3为最优分类器距离最小化网络ocdm的网络架构图。
具体实施方式
[0063]
下面结合实施例及附图对本发明作进一步详细的描述,但本发明的实施方式不限于此。
[0064]
参见图1所示,本实施例提供了一种基于域不变特征的泛化人脸伪造检测方法,具体包括以下主要技术步骤:
[0065]
1)构建训练图像集
[0066]
本实例选用目前最大的人脸伪造基准数据集faceforensics++作为实验数据集,faceforensics++数据集包含由四种不同的人脸伪造方法生成的数据集,即faceswap、deepfakes、face2face和neuraltextures。每种不同的人脸伪造方法生成的数据集都包含1000个伪造视频,还包含1000个真实视频。对于每个视频,我们都以相等的间隔提取30帧图像,并通过opencv dlib工具自动裁剪出每帧图像的脸部区域,且确保至少90%的人脸区域都被有效的裁剪出来了,从而得到大量由不同的人脸伪造方法生成的人脸伪造图像和对应的正常人脸图像。
[0067]
对于获取到的大量的由不同的人脸伪造方法生成的人脸伪造图像和对应的正常人脸图像,将其都缩放到128
×
128大小的尺寸。并按照生成的人脸伪造方法的不同将这些人脸伪造图像和对应的正常人脸图像划分到不同的数据集中,即可得到4个不同数据集。这四个不同的数据集,随机选择3个作为源域数据集,还有一个作为未知的目标域数据集。对于得到的3个源域数据集s={si|i=1,2,3},其中si代表第i个源域数据集,它包含numi张图像。
[0068]
2)用步骤1)中构建的训练图像集来训练构建的域不变特征表征学习的人脸伪造检测网络包括以下步骤:
[0069]
2.1)将构建的训练图像集中的m个源域数据集s模拟划分为虚拟源域sv和虚拟目标域tv。m在实施例中为3,且3个源域数据集中2个源域作为虚拟源域,1个源域作为虚拟目标域。
[0070]
2.2)构建域不变特征表征学习的人脸伪造检测网络中的特征分布差异最小化网络fddm,该特征分布差异最小化网络fddm包括特征提取器ge、解码器特征选择gs、类判别器d
ψ
、分类器c和m个域判别器d
μi
(i∈{1,2,...,m}),具体网络架构如图2所示。特征提取器ge和解码器均由3个卷积模块堆叠而成,不同的是,特征提取器ge的每个卷积模块后都跟着一个最大池化层,而解码器的每个卷积模块后都跟着一个上采样层。特征选择gs为一步特征划分的操作,不包含具体的网络结构。类判别器d
ψ
和域判别器d
μi
(i∈{1,2,...,m})的网络结构相同,它们均由4个卷积模块堆叠而成。分类器c则是由3个卷积模块、一个平均池化层和一个全连接层组成。
[0071]
对于从虚拟源域sv和虚拟目标域tv随机得到的第j张输入图像xj,特征z_exj是通过特征提取器ge从输入图像xj提取到的特征,并将特征z_exj输入到解码器来得到重构图像,以及通过最小化输入图像和重构图像之间的均方误差损失l
rec
对其进行约束使得特征
提取器提取到输入图像的完整信息:
[0072][0073]
式中,n表示这次从虚拟源域和虚拟目标域中选取的样本数量。特征z_exj通过特征选择gs划分为特征z_irj和特征z_dsj。特征z_dsj作为分类器c的输入来预测输入图像的标签,并通过最小化输入图像的预测结果和输入图像的标签之间的交叉熵损失l
cls
来约束特征z_dsj代表类相关特征:
[0074][0075]
式中,n表示这次从虚拟源域和虚拟目标域选取的样本数量,yj代表第j张输入图像的标签。而特征z_irj则作为类判别器d
ψ
的输入也来预测输入图像的标签,并且通过最小化输入图像的预测结果和输入图像的标签之间的负交叉熵损失l
cdis
来约束特征z_irj代表类无关特征:
[0076][0077]
式中,n表示这次从虚拟源域和虚拟目标域选取的样本数量。接着利用对抗训练的方法将特征z_irj和特征z_dsj均作为类判别器的输入来预测输入图像的标签,并最小化输入图像的预测结果和输入图像的标签的交叉熵损失l
ent
来训练类判别器d
ψ
将特征z_irj和特征z_dsj两者相互解耦开来:
[0078][0079]
式中,1代表指示函数,k代表分类类别,即该预测任务为二分类任务,yj代表第j
th
张输入图像的标签。域判别器d
μi
(i∈{1,2,...,m})不考虑虚拟源域和虚拟目标域而直接去最小化来自源域数据集每个域的特征z_dsj的分布差异使得特征z_dsj为m个源域数据集共享的域共享特征。对于第i个域判别器d
μi
,用于判别特征z_dsj是否属于第i个源域数据集,其对应的损失函数l
disi
表示为:
[0080][0081]
式中,z_ds
ji
代表来自第i个域的第j张输入图像的特征,相应的,z_ds
jr
代表来自第r个域的第j张输入图像的特征,且r≠i。结合m个域判别器的损失函数,就使得来自第i个域的特征z_ds
ji
与剩下的m-1个源域数据集的特征分布差异最小。m个判别器的损失函数l
dis
表示为:
[0082][0083]
fddm整体优化目标的损失函数为:
[0084]
l
fddm
=l
rec
+l
cdis
+l
cls
+l
dis
ꢀꢀꢀꢀ
(7)
[0085]
2.3)构建域不变特征表征学习的人脸伪造检测网络中的最优分类器距离最小化网络ocdm,该最优分类器距离最小化网络ocdm由特征提取器ge、特征选择器gs和分类器h组
成,具体的网络架构如图3所示,其中特征提取器ge、特征选择器gs都来自于特征分布差异最小化网络fddm。分类器h由3个卷积模块、一个平均池化层和一个全连接层组成。ocdm通过两阶段更新的方法调整最优的虚拟源域分类器和最优的虚拟目标域分类器之间的距离来调整学习到的域共享特征,从而得到域不变特征。
[0086]
在第一阶段,对于从虚拟源域sv随机得到的第j张输入图像将其作为ocdm的输入去预测输入图像的标签,并最小化输入图像的预测结果和输入图像的标签的交叉熵损失l
meta-train
:
[0087][0088]
式中,l代表交叉熵损失函数,φ(ge,h)代表ocdm中特征提取器ge和分类器h的权重参数,而为输入图像相对应的标签。ocdm相对于损失函数l
meta-train
的梯度为通过该梯度将ocdm中特征提取器ge和分类器h的权重参数更新为其中α代表这一步更新的步长,在实施例中被设置为0.0001。
[0089]
在第二阶段,对于从虚拟源域tv随机得到的第j张输入图像将其作为第一阶段更新的ocdm的输入来预测输入图像的标签,并最小化输入图像的预测结果和输入图像的标签的交叉熵损失l
meta-test
:
[0090][0091]
式中,为输入图像相对应的标签。
[0092]
ocdm整体优化目标的损失函数为:
[0093][0094]
式中,φ(ge,h)代表ocdm中特征提取器ge和分类器h的权重参数,β代表比例参数来平衡ocdm两个阶段的损失函数的比例,在实施例中,β被设置为1,代表ocdm相对于损失函数l
meta-train
的梯度。
[0095]
2.4)初始化域不变特征表征学习的人脸伪造检测网络中特征分布差异最小化网络fddm和最优分类器距离最小化网络ocdm中各个部分的权重参数,包括特征提取器ge的权重参数解码器的权重参数类判别器d
ψ
和m个域判别器d
μi
(i∈{1,2,...,m})的权重参数和分类器c和分类器h的权重参数wc和wh。初始化迭代次数e=1。
[0096]
2.5)将构建的训练图像集中的m个源域数据集s随机划分为虚拟源域sv和虚拟目标域tv。初始化迭代次数t=1。
[0097]
2.6)固定fddm中类判别器d
ψ
和3个域判别器d
μi
(i∈{1,2,3})的权重参数。从虚拟源域sv和虚拟目标域tv中随机选取n个样本构成训练对,在实施例中n被设置为96,并去计算fddm整体优化目标的损失函数l
fddm
。根据计算得到的fddm整体优化目标的损失函数l
fddm
来分别计算fddm中特征提取器ge、解码器和分类器c的梯度并反向传播更新各个部分的权重参数:
[0098][0099][0100][0101]
在公式(11)、(12)和(13)中,η为给定的学习率,在实施例中被设置为0.0001,和分别代表特征提取器ge、解码器和分类器c的梯度。
[0102]
2.7)固定fddm中特征提取器ge的权重参数。从虚拟源域sv和虚拟目标域tv中随机选取n个样本构成训练对,并去计算公式(4)的损失函数l
ent
和公式(5)的m个判别器d
μi
(i∈{1,2,...,m})的损失函数l
disi
(i∈{1,2,...,m})。根据损失函数l
ent
计算fddm中类判别器d
ψ
的梯度并反向传播更新类判别器d
ψ
的权重参数:
[0103][0104]
式中,η为给定的学习率,为类判别器d
ψ
的梯度。因为有m个判别器d
μi
(i∈{1,2,...,m}),即需要分别对每一个域判别器的权重参数进行更新,第i个域判别器d
μi
的权重参数更新过程表示为:
[0105][0106]
式中,η为给定的学习率,为第i个域判别器d
μi
的梯度。
[0107]
2.8)从虚拟源域sv和虚拟目标域tv中随机选取n个样本构成训练对,并去计算ocdm整体优化目标的损失函数l
ocdm
。根据计算得到的ocdm整体优化目标的损失函数l
ocdm
来分别计算ocdm中特征提取器ge和分类器h的梯度并反向传播更新各个部分的权重参数:
[0108][0109][0110]
在公式(16)和(17)中,η为给定的学习率,和分别代表特征提取器ge和分类器h的梯度。
[0111]
2.9)更新迭代次数t=t+1,并判断迭代条件是否满足其中和分别为虚拟源域sv和虚拟目标域tv的总样本数量,n为每次迭代的样本
数。如满足条件,则转至步骤2.6)。否则,进入步骤2.10)。
[0112]
2.10)更新迭代次数e=e+1,并判断迭代条件是否满足e≤e,其中e代表训练的epoch数,在实施例中被设置为200。如满足,则转至步骤2.5)。否则,保存此时最优的域不变特征表征学习的人脸伪造检测网络的权重参数并退出迭代。
[0113]
3)选用步骤1)中未知的目标域数据集作为测试集,对于待测的测试集的输入图像,应用步骤2)中构建的域不变特征表征学习的人脸伪造检测网络和最优的域不变特征表征学习的人脸伪造检测网络的权重参数给出预测结果,即输入图像是否为人脸伪造图像。
[0114]
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1