一种变电站工程选址知识图谱构建方法与流程
1.本发明涉及电力工程与知识工程技术领域,尤其涉及一种变电站工程选址知识图谱构建方法。
背景技术:
2.变电站规划是电网规划的重要环节,直接影响到规划区域电网的结构、投资及运行的经济性与可靠性。传统的变电站规划主要靠人工经验和实地勘察进行判断,不仅工作量大、工期长,还会受到很多主观因素的影响,很难全面地考虑影响变电站选址的因素,使得变电站的选址工作难度很大。在电网建设规模不断扩大及电网信息化快速发展的背景下,综合考虑电网规划业务发展方向,需要基于电力大数据、应用前沿信息技术、整合各专业信息资源、深入挖掘数据潜在价值,研究实现变电站的智能选址。
技术实现要素:
3.本部分的目的在于概述本发明的实施例的一些方面以及简要介绍一些较佳实施例。在本部分以及本技术的说明书摘要和发明名称中可能会做些简化或省略以避免使本部分、说明书摘要和发明名称的目的模糊,而这种简化或省略不能用于限制本发明的范围。
4.鉴于上述现有变电站工程选址存在的问题,提出了本发明。
5.因此,本发明目的是提供一种变电站工程选址知识图谱构建方法,适用于对变电站工程选址知识的结构化分解与知识图谱构建,改善现有变电站选址知识管理效能,辅助工程决策,进一步提高变电站工程选址的智能化。
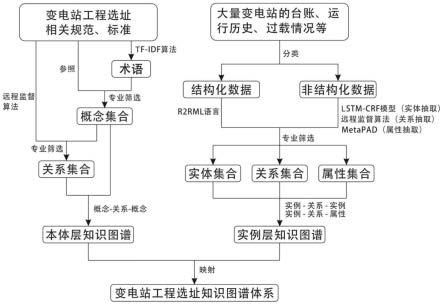
6.为解决上述技术问题,本发明提供如下技术方案:一种变电站工程选址知识图谱构建方法,此构建方法包括以下步骤,采集变电站工程选址的相关规范和标准,经术语抽取得到变电站工程选址知识图谱的关键术语;参照现有选址的相关规范和标准,结合关键术语,经筛选,得到变电站工程选址的概念集合和关系集合;根据概念集合和关系集合建立“概念-关系-概念”三元组,构建本体层知识图谱;采集现有变电站的运行资料,经知识抽取和筛选处理后得到变电站工程选址知识的实体集合、关系集合以及属性集合;通过实体集合、关系集合以及属性集合建立“实例-关系-实例”和“实例-关系-属性”三元组,构建实例层知识图谱;基于本体层知识图谱和实例层知识图谱以及相互之间的映射关系,构建用于变电站工程选址的知识体系。
7.作为本发明所述变电站工程选址知识图谱构建方法的一种优选方案,其中:所述采集变电站工程选址的相关规范和标准,经术语抽取得到变电站工程选址知识图谱的关键术语,包括以下步骤:术语抽取,首先使用阈值分类器抽取出语料中的双字候选词汇,然后再对候选词汇向左右两侧进行一定程度的扩充,筛选符合要求的多字候选词汇;使用tf-idf算法对所得候选词汇进行过滤以得到最终结果,即变电站工程选址知识图谱的术语。
8.作为本发明所述变电站工程选址知识图谱构建方法的一种优选方案,其中:所述使用tf-idf算法对所得候选词汇进行过滤以得到变电站工程选址知识图谱的术语,包括以
下步骤:
9.首先,计算词频tf
ij
,即:
[0010][0011]
其中,n
i,j
是该词在文件dj中出现的次数,n
k,j
分母则是文件dj中所有词汇出现的次数总和;
[0012]
然后,计算逆向文件频率idf,即:
[0013][0014]
其中,|d|是收集的变电站工程选址知识中的文件总数,|{j:ti∈dj}|表示包含该词语的文件总数(即n
i,j
≠0的文件总数)。
[0015]
最后,计算tf-idf,即:tf-idf=tf
×
idf
[0016]
其中,tf(tf
ij
)表示为词频,idf表示为逆向文件频率。
[0017]
作为本发明所述变电站工程选址知识图谱构建方法的一种优选方案,其中:所述参照现有选址的相关规范和标准,结合关键术语,经筛选,得到变电站工程选址的概念集合和关系集合,包括以下步骤:根据关键术语和采集的变电站选址相关规范、标准,经过筛选得到变电站工程选址知识图谱本体层概念集合;根据获取的概念集合,使用远程监督算法对采集的变电站工程选址相关规范、标准进行关系抽取,再经过筛选得到变电站工程选址知识图谱本体层关系集合。
[0018]
作为本发明所述变电站工程选址知识图谱构建方法的一种优选方案,其中:而在得到变电站工程选址知识图谱本体层关系集合的过程中,还包括以下步骤:根据得到的概念集合再结合知识库进行概念对比,对采集的变电站选址相关规范、标准等资料进行关系标注;根据获取的知识进行远程监督关系抽取模型训练,利用得到的模型进行关系抽取,得到变电站工程选址知识图谱本体层关系集合。
[0019]
作为本发明所述变电站工程选址知识图谱构建方法的一种优选方案,其中:对知识图谱本体层概念集合和关系集合进行检查和评估,包括两方面:一是核心概念的结构是否合理,二是每个概念的合理性、必要性以及相似概念间的辨析。
[0020]
作为本发明所述变电站工程选址知识图谱构建方法的一种优选方案,其中:所述采集现有变电站的运行资料,经知识抽取和筛选处理后得到变电站工程选址知识的实体集合、关系集合以及属性集合,包括以下步骤:对采集的现有变电站的运行资料进行分类,得到变电站工程选址的结构化知识与非结构化知识;其中,运行资料包括变电站的台账、运行历史和过载;对于结构化知识的知识抽取,采用r2rml语言将知识映射成rdf格式三元组,得到相应的实体、关系和属性;对于非结构化知识的知识抽取,结合构建的本体层知识图谱,采用lstm-crf(机器学习-深度学习)模型、远程监督算法和metapad(meta pattern discovery from massive text corpora,从海量文本语料库中发现元模式)分别进行实体抽取、关系抽取和属性抽取;将前两步骤得到的实体、关系、属性相结合,进行核查补缺后,得到初始变电站工程选址知识图谱的实体集合、关系集合和属性集合。
[0021]
作为本发明所述变电站工程选址知识图谱构建方法的一种优选方案,其中:对得
到的初始变电站工程选址知识图谱的实体集合、关系集合和属性集合进行同义词、近义词聚类,确定唯一规范表述,获得精简后的初始变电站工程选址知识图谱实体集合、关系集合和属性集合。
[0022]
作为本发明所述变电站工程选址知识图谱构建方法的一种优选方案,其中:对于实体抽取、关系抽取和属性抽取,包括以下步骤:根据获取的本体对采集的变电站的运行资料采用lstm-crf模型进行实体抽取,得到变电站工程选址知识图谱实体集合;根据获取的实体对采集的变电站的运行资料采用远程监督模型进行关系抽取,得到变电站工程选址知识图谱实例层关系集合;根据获取的实体对采集的变电站的运行资料采用metapad进行属性抽取,得到变电站工程选址知识图谱属性集合。
[0023]
本发明的有益效果:
[0024]
本发明构建较为完善的变电站选址知识图谱体系;可作为选址知识指南,为选址提供实际有效的指导;通过形成丰富的案例知识库,供新的工程检索和辅助决策;并可为电网规划决策提供数据支持与科学依据,实现精准规划,辅助相关技术人员进行决策,达到提升工作效率的目的。
附图说明
[0025]
为了更清楚地说明本发明实施例的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其它的附图。其中:
[0026]
图1为本发明变电站工程选址知识图谱构建方法的知识图谱构建流程示意图。
[0027]
图2为本发明变电站工程选址知识图谱构建方法的本体层知识图谱局部示意图。
[0028]
图3为本发明变电站工程选址知识图谱构建方法的实例层知识图谱局部示意图。
[0029]
图4为本发明变电站工程选址知识图谱构建方法的实例的属性示例图。
[0030]
图5为本发明变电站工程选址知识图谱构建方法的本体层和实例层映射关系示意图。
具体实施方式
[0031]
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合说明书附图对本发明的具体实施方式做详细的说明。
[0032]
在下面的描述中阐述了很多具体细节以便于充分理解本发明,但是本发明还可以采用其他不同于在此描述的其它方式来实施,本领域技术人员可以在不违背本发明内涵的情况下做类似推广,因此本发明不受下面公开的具体实施例的限制。
[0033]
其次,此处所称的“一个实施例”或“实施例”是指可包含于本发明至少一个实现方式中的特定特征、结构或特性。在本说明书中不同地方出现的“在一个实施例中”并非均指同一个实施例,也不是单独的或选择性的与其他实施例互相排斥的实施例。
[0034]
再其次,本发明结合示意图进行详细描述,在详述本发明实施例时,为便于说明,表示器件结构的剖面图会不依一般比例作局部放大,而且所述示意图只是示例,其在此不应限制本发明保护的范围。此外,在实际制作中应包含长度、宽度及深度的三维空间尺寸。
[0035]
通过对变电站工程选址领域知识的来源、内容、特性和应用需求等进行深入的分析,提出构建概念集合和关系集合,建立本体层知识图谱,存储技术规程等静态知识。基于本体对获取的与变电站工程选址相关的知识进行知识抽取,得到变电站工程选址知识实体集合、属性集合以及关系集合,建立实例层知识图谱,存储案例和专家经验等动态知识。
[0036]
实施例1
[0037]
参照图1~5,为本发明的第一个实施例,提供了一种变电站工程选址知识图谱构建方法,此图谱构建方法:包括以下步骤,
[0038]
s1:采集变电站工程选址的相关规范和标准,经术语抽取得到变电站工程选址知识图谱的关键术语。
[0039]
具体的,收集现有的与变电站工程选址相关规范和标准的词汇及术语,形成语料库及知识库,通过术语抽取从语料库中抽取出与变电站工程选址知识图谱直接相关的关键术语。
[0040]
进一步的,关键术语的获取采用术语抽取结合tf-idf算法的方式,具体如下步骤所示:
[0041]
s11:术语抽取,首先使用阈值分类器抽取出语料库中的双字候选词汇,然后再对候选词汇向左右两侧进行一定程度的扩充,筛选符合要求的多字候选词汇。
[0042]
s12:再通过tf-idf算法对所得候选词汇进行过滤以得到最终结果,即变电站工程选址知识图谱的关键术语。
[0043]
进一步的,tf-idf算法在具体使用时,首先,计算词频tf(tf
ij
),即:
[0044][0045]
词频(tf)等于某个词在文本中的出现次数/文本总词数,其中,n
i,j
是该词在文件dj中出现的次数,n
k,j
分母则是文件dj中所有词汇出现的次数总和。
[0046]
然后,计算逆向文件频率idf,即:
[0047][0048]
逆文档频率(idf)等于log(语料库的文档总数/包含该词的文档总数 +1),最常见的词(“的”、“是”、“在”、“中国”等)给予最小的权重,较少见的词(“变电站”、“某电力公司”)给予较大的权重。其中,|d|是收集的变电站工程选址知识中的文件总数,|{j:ti∈dj}|表示包含该词语的文件总数(即 n
i,j
≠0的文件总数),如果该词语不在语料库中,就会导致分母为零,因此一般情况下使用1+|{j:ti∈dj}|。
[0049]
最后,计算tf-idf,即:
[0050]
tf-idf=tfxidf
[0051]
其中,tf(tf
ij
)表示为词频,idf表示为逆向文件频率。
[0052]“词频(tf)”和“逆向文件频率(idf)”两个值相乘,得到了某个词的tf-idf值。某个词的重要性越高,那么它的tf-idf值就越大。即一般而言这个词在这篇文章的重要性会越高,所以通过计算文件中各个词的tf
‑ꢀ
idf,由大到小排序,排在最前面的几个词,就是该文章的关键词,从而实现对词汇过滤的目的。采用tf-idf算法对关键术语进行过滤,简单快
速,而且容易理解,术语提取的正确率提高了将近78%。
[0053]
s2:参照现有选址的相关规范和标准,结合关键术语,经筛选,得到变电站工程选址的概念集合和关系集合。
[0054]
具体的,依照现有的变电站工程选址的相关规范和标准,结合抽取得到的关键术语,经由变电站选址技术领域内的专业人士(专家)筛选,得出选址相关术语的概念集合和关系集合。
[0055]
具体的,包括以下步骤:
[0056]
s21:根据关键术语和采集的变电站选址相关规范、标准,经过筛选得到变电站工程选址知识图谱本体层概念集合;
[0057]
s22:根据获取的概念集合,使用远程监督算法对采集的变电站工程选址相关规范、标准进行关系抽取,再经过筛选得到变电站工程选址知识图谱本体层关系集合。
[0058]
进一步的,在得到变电站工程选址知识图谱本体层关系集合的过程中,进行了如下处理:
[0059]
s221:根据得到的概念集合再结合知识库进行概念对比,对采集的变电站选址相关规范、标准等资料进行关系标注;
[0060]
s222:根据上一步获取的知识进行远程监督关系抽取模型训练,利用得到的模型进行关系抽取,得到变电站工程选址知识图谱本体层关系集合;
[0061]
s223:对知识图谱本体层概念集合和关系集合进行检查和评估,包括两方面:一是核心概念的结构是否合理,二是每个概念的合理性、必要性以及相似概念间的辨析。
[0062]
s3:如图2中所示,根据步骤s2得到的概念集合和关系集合,建立“概念-关系-概念”三元组,构建本体层知识图谱。即将两个或多个概念术语之间通过映射关系匹配起来,形成本体层的知识图谱。
[0063]
进一步的,s4:采集现有变电站的运行资料,经知识抽取和筛选处理后得到变电站工程选址知识的实体集合、关系集合以及属性集合;其中,需要采集大量的现有选址及运行中变电站的运行数据,通过知识抽取后构建实例层的知识图谱实例层集合,具体的,包括以下步骤:
[0064]
s41:对采集的现有变电站的运行资料进行分类,得到变电站工程选址的结构化知识与非结构化知识。其中,运行资料包括变电站的台账、运行历史和过载情况等;
[0065]
s42:对于结构化知识的知识抽取,采用r2rml语言将知识映射成rdf 格式三元组,得到相应的实体、关系和属性;
[0066]
s43:对于非结构化知识的知识抽取,结合步骤s3中构建的本体层知识图谱,采用lstm-crf模型、远程监督算法和metapad分别进行实体抽取、关系抽取和属性抽取。
[0067]
对于实体抽取、关系抽取和属性抽取,采取以下处理步骤:
[0068]
s431:根据获取的本体对采集的变电站的运行资料采用lstm-crf模型进行实体抽取,得到变电站工程选址知识图谱实体集合;
[0069]
s432:根据获取的实体对采集的变电站的运行资料采用远程监督模型进行关系抽取,得到变电站工程选址知识图谱实例层关系集合;
[0070]
s433:根据获取的实体对采集的变电站的运行资料采用metapad进行属性抽取,得到变电站工程选址知识图谱属性集合。
[0071]
需要说明的是,metapad是一种上下文感知的分割方法,通过学习模式质量评估函数来仔细确定模式的边界;从多个方面识别和分组同义元模式,包括它们的类型、上下文和提取;检查每个模式组提取的实例中实体的类型分布,并寻找适当的类型级别,以使发现的模式精确。
[0072]
在本实施例中,根据得到的实体集合,标注每个词汇的类型,利用 metapad对海量的数据进行pattern(样品)抽取,并统计pattern频次,通过 trueie,筛选出描述实体属性的高质量语句pattern,并将其中的词语抽出,作为候选属性词。然后,将所有候选属性词生成词典,重新对刚才的语料进行分词,将所有属性词标记分类为“attribute”,进行第二次pattern抽取,只取与“attribute”类型有关的pattern,筛出其中的文本,作为属性值。对于属性值为句子的属性,直接截取相关语句作为答案。
[0073]
进一步的,s44:将步骤s42和步骤s43得到的实体、关系、属性相结合,进行核查补缺后,得到初始变电站工程选址知识图谱的实体集合、关系集合和属性集合。
[0074]
s45:对得到的初始变电站工程选址知识图谱的实体集合、关系集合和属性集合进行同义词、近义词聚类,确定唯一规范表述,获得精简后的初始变电站工程选址知识图谱实体集合、关系集合和属性集合。
[0075]
s5:如图3和图4中所示,通过获取的实体集合、关系集合以及属性集合建立“实例-关系-实例”和“实例-关系-属性”三元组,构建实例层知识图谱;用于存储案例和专家经验等动态知识。
[0076]
s6:如图5中所示,基于本体层知识图谱和实例层知识图谱以及相互之间的映射关系,构建用于变电站工程选址的知识体系,用于帮助在变电站工程选址时的检索学习和辅助决策。
[0077]
通过上述步骤能够构建完整的变电站选址知识图谱体系,可作为选址知识指南,为选址提供实际有效的指导;通过形成丰富的案例知识库,供新的工程检索和辅助决策;并可为电网规划决策提供数据支持与科学依据,实现精准规划,辅助相关技术人员进行决策,达到提升工作效率的目的。
[0078]
实施例2
[0079]
为了对本方法具有的技术效果加以验证说明,本实施例通过一个具体实例加以验证说明,结合附图2~4中所示。
[0080]
1、通过对收集到的变电站选址相关规范和标准进行词汇整理、筛选,形成语料库,并形成如图2中的本体层知识图谱局部示例。再对语料库进行术语抽取。
[0081]
对于术语抽取:最初的术语抽取工作主要是依靠人工来进行,工作量巨大而进展缓慢。其次,当代基于统计学方法,实现了一些自动术语抽取器,其中,具有代表性的是基于统计语料,与语言无关,即它能够针对不同语言 (如中文、英文)的语料进行抽取,但是单纯依靠统计学方法来处理语料,不考虑或较少考虑利用语法规则,这种方法获取的术语准确率比较低。
[0082]
本方案中通过阈值分类器抽取候选词汇,并进行词汇的双向扩充筛选,从而得到多字候选词汇,再通过tf-idf算法对所得候选词汇进行过滤,得到最终的关键术语。
[0083]
根据上述实施例中的算法步骤,针对变电站工程选址领域的语料进行了术语抽取实验,然后与人工抽取结果相对照,得到正确率为64.49%。对抽取结果进行分析之后发现:
抽取结果中存在大量“正确”的术语,但它们不是我们想要的变电站工程选址领域的术语,这是对于正确率最大的影响。紧接着我们采用tf-idf算法对术语进行过滤,然后与人工抽取结果相对照,正确率达正确率进一步提高到78%。
[0084]
2、对收集的大量变电站的台账、运行历史、过载情况等资料进行分类和对应,形成知识库,得到如图3和4中的实例层知识图谱局部示例。对知识库中的实例进行知识抽取。
[0085]
对于知识抽取:采用机器学习模型与深度学习相结合的方法(lstm
‑ꢀ
crf),为了衡量算法对实体的识别效果以及模型的泛化能力,本方法采用信息分类常用的指标:召回率(recall,记为rec);准确率(precision,记为 pre);f1-measure(综合评价指标,记为f1)。其中,pre和rec同时越大,则识别模型的效果越好,f1则是pre和rec的综合指标,同时采用pre、rec 和f1能更加客观合理地评估模型。
[0086]
为了检验出lstm-crf方法对于变电站工程选址领域实体的识别能力,进行了以下对比实验:lstm-crf、lstm、crf、hmm四种方法实体识别对比实验,分别比较四种方法的pre、rec和f1值,实验结果表明:hmm的识别效果最差,hmm三个指标都约为80%,crf和lstm的识别效果优于 hmm。lstm-crf的识别效果最好,三个指标都为93%,优于其他三种方法。该实验证明了lstm与crf的结合体lstm-crf更加适合变电站工程选址领域实体识别的任务。
[0087]
3、进一步的,通过对现有收集到的与变电站选址相关规范和标准进行术语抽取,以及对收集到的大量变电站的台账、运行历史、过载情况等资料进行知识抽取。现阶段得到的抽取数据结果如下表中所示:
[0088]
类型总数目概念21实例32234属性194232概念和概念之间的关系21概念和实例之间的关系32234实例和属性之间的关系194232
[0089]
此抽取数据中包含了21个概念,衍生有32234个实例,这些实例总共有 194232个属性。上述数据构成了一个完整的变电站选址知识图谱,进一步的,上述数据可在现有基础上添加或删除;且知识图谱存储的实例越多,其对选址决策的指导准确性越高(即知识图谱的价值越大)。
[0090]
应当说明的是,以上实施例仅用以说明本发明的技术方案而非限制,尽管参照较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明技术方案的精神和范围,其均应涵盖在本发明的权利要求范围当中。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1