一种基于语义分解的隐式篇章关系分析方法
1.本发明涉及一种基于语义分解的隐式篇章关系分析方法,属于自然语言处理应用技术领域。
背景技术:
2.篇章关系分析是自然语言处理中的一项重要任务,旨在对多句子文本中的句际关系进行识别与归类。有效识别并应用篇章关系,可以提升多种下游自然语言处理任务的效果,例如机器翻译,文本摘要等。
3.根据句间是否存在篇章连接词(如“但是”“所以”等),篇章关系可分为显式和隐式。其中,没有连接词的隐式篇章关系识别为主要难点。由于缺乏连接词的指示,隐式篇章关系只能通过理解文本中的深层语义来识别句间的逻辑关系。然而,当前的深度模型在深层语义挖掘方面,尚缺乏对真正有价值的语义信息进行筛选、理解的能力。
4.做出正确的隐式篇章关系分析,往往需要模型理解更深层次的语义。然而,并非所有的语义信息都是有用的。例如,在样例1中,“《论元1》its index inched up to 47.6%in october from 46%in september.《论元2》any reading below 50%suggests the manufacturing sector is generally declining.”,论元1所透露的九月和十月的具体指数,甚至九月、十月这些时间信息,对隐式篇章关系分类都没有实际价值。即,无论模型有没有捕捉到在哪个月有什么样的指数信息,都不会影响模型做出正确的隐式篇章关系判断。因此,在理解深层次语义时,模型还需要对这些语义信息加以区分,从而筛选和变换出对最终的隐式篇章关系分析真正有用的语义信息。
5.通过重现人类理解隐式篇章关系的过程,并分析了不同信息对模型分类的价值发现,整个论元的语义性质和论元所阐述的核心事件对隐式篇章关系分析更有价值。而论元涉及的主题、环境以及诸多的描述细节,对于最终的分类并没有什么帮助。
技术实现要素:
6.本发明的目的是针对现有的隐式篇章关系分析技术中存在没有区分语义信息的不同内容及价值的技术问题,提出了一种基于语义分解的隐式篇章关系分析方法。本方法通过语义分解,同时构建双网络分类器来实现深层语义的筛选、理解,从而提升隐式篇章关系分析的效果。
7.本发明的创新点在于:通过设计分流的网络结构和完整的流程,来分别处理论元中不同的语义信息,包括利用语义迁移网络和语义分解网络实现论元语义的信息分解。将对隐式篇章关系分析有用的信息流入任务相关型网络,对隐式篇章关系分析没有实际用处的信息流入任务无关型网络。以此提升模型对语义信息的筛选和理解的能力,达到提升隐式篇章关系分析的技术效果。
8.为实现上述目的,本发明采取如下技术方案。
9.一种基于语义分解的隐式篇章关系分析方法,首先,利用编码器对样本的两个论
元进行语义编码。然后,利用语义分解网络,将论元语义分解为对隐式篇章关系分析任务有用的任务相关语义和对该任务没有价值的任务无关语义。之后,将两个论元分解出的不同语义分别组成语义对,并分别送入任务相关型网络和任务无关型网络。通过搭配特有的数据构建方案和模型训练方法,使论元语义模型能够有效进行语义分解,让模型关注到对任务更有价值的语义信息。最后,使用论元语义模型对隐式篇章关系进行分析。
10.有益效果
11.本发明方法,与现有技术相比,具有以下优点:
12.1.本方法能够有效实现语义的分解、信息分流。在论元语义建模过程中,区分了不同语义信息的内容,以及不同语义信息在隐式篇章关系分析任务中提供的不同价值。
13.2.本方法能有效提升隐式篇章关系识别的效果。
14.3.本方法能够使用户快速、准确地获得隐式篇章关系的分析结果。
附图说明
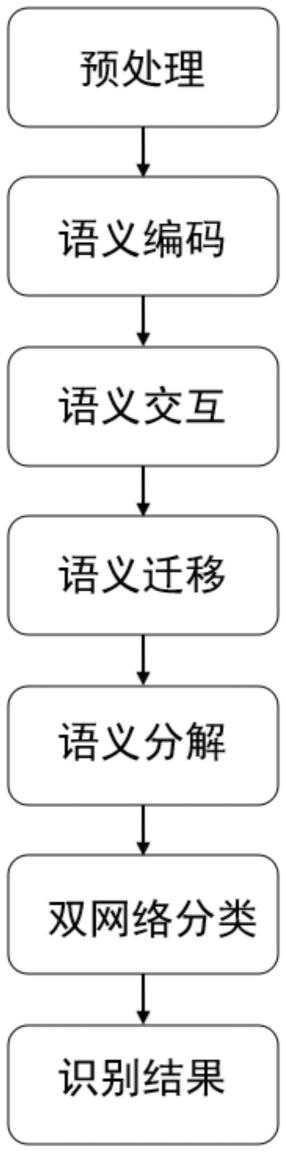
15.图1为本发明方法的流程图;
16.图2为本发明方法的系统架构图。
具体实施方式
17.下面结合附图和实施例对本发明方法做进一步详细说明。
18.如图1所示,一种基于语义分解的隐式篇章关系分析方法,包括如下步骤:
19.步骤1:利用编码器,对样本的两个论元进行语义编码,获取对应的语义表示。
20.具体地,包括以下步骤:
21.步骤1.1:对pdtb2.0语料库里的样本做预处理,将所有样本中的token转换为小写。
22.步骤1.2:利用编码器,对各个样本的两个论元(arg1,arg2)进行语义编码,获取对应的语义表示。
23.其中,语义表示包括状态向量(h
arg1
,h
arg2
)和句子向量(s
arg1
,s
arg2
)。其中,h
arg1
为论元1中的状态向量,m是论元1的token数量,表示arg1中每个token的向量表示,dh为状态向量的空间维度,r表示维度为m*dh的矩阵;h
arg2
为论元2中的状态向量,为论元2中的状态向量,n是论元2的token数量,表示arg2中每个token的向量表示。s
arg1
为论元1的句子向量,s
arg2
为论元2的句子向量。
24.步骤2:借助交互注意力机制进行语义交互操作,计算出两个论元中的各个token的权重分布(att1,att2),att1表示论元1的权重分布,att2表示论元2的权重分布,进而计算得到每个论元的最终加权表示(s
′
arg1
,s
′
arg2
),s
′
arg1
表示论元1的加权,s
′
arg2
表示论元2的加权。
25.具体方法如下:
26.步骤2.1:将论元2的句子向量s
arg2
和论元1的状态向量h
arg1
进行点乘,通过softmax
计算得到论元1的权重分布att1。
27.步骤2.2:将论元1的句子向量s
arg1
和论元2的状态向量h
arg2
进行点乘,通过softmax计算得到论元2的权重分布att2。
28.步骤2.3:对两个论元的权重分布(att1,att2)和状态向量(h
arg1
,h
arg2
)进行加权求和,计算得到最终的加权表示(s
′
arg1
,s
′
arg2
)。
29.步骤3:将论元语义分解为对隐式篇章关系分析任务有用的任务相关语义和对该任务没有价值的任务无关语义。
30.具体地,包括以下步骤:
31.步骤3.1:利用语义迁移网络(一种对称的mlp神经网络),对每个论元的最终加权表示(s
′
arg1
,s
′
arg2
)进行语义迁移,获取相对易于分解的高阶语义表示(q
arg1
,q
arg2
)。
32.首先,将各个论元的最终加权表示(s
′
arg1
,s
′
arg2
)做维度对半压缩,得到空间向量(p
arg1
,p
arg2
)。然后,将其还原至原有维度,得到高阶语义表示(q
arg1
,q
arg2
)。其中,p
arg1
表示论元1的空间向量,p
arg2
表示论元2的空间向量。q
arg1
表示论元1的高阶语义,q
arg2
表示论元2的高阶语义。
33.步骤3.2:使用语义分解网络,对各论元的高阶语义表示(q
arg1
,q
arg2
)进行语义分解。每个论元都会得到两个不同语义表述,并构成两组语义对。其中,论元1高阶语义分解得到论元2的高阶语义分解得到并构成两组语义对。
34.进一步地,可以采用以下方法构成语义对:
35.首先,利用映射矩阵m对(q
arg1
,q
arg2
)做空间映射,得到任务相关语义对其中,x表示任务相关,表示arg1的任务相关表示,表示arg2的任务相关表示。
36.然后,根据任务相关语义,计算得出任务无关语义对即即其中,y表示任务无关,表示arg1的任务无关语义,表示arg2的任务无关语义。
37.步骤4:将两个论元分解出的不同语义分别组成语义对,分别送入任务相关型网络和任务无关型网络。通过数据构建和模型训练,使论元语义模型能够有效进行语义分解,让模型关注到对任务更有价值的语义信息。如图2所示。
38.具体地,构建双网络分类器,将两个论元语义分解结果中的任务相关语义对进行拼接后,输入至任务相关型网络,判断两个论元的隐式篇章关系;同时,将两个论元语义分解结果中的任务无关语义对进行拼接,输入任务无关型网络,判断两个论元是否构成篇章关联。
39.其中,双网络分类器包括任务相关型网络和任务无关型网络。训练双网络分类器时,除利用存在篇章关联的论元对作为正样本之外,还要构建没有篇章关联的论元对作为负样本进行训练。训练时,使用交叉熵损失函数作为目标函数,采用adam梯度更新算法更新论元语义模型中的参数。
40.步骤5:使用论元语义模型对隐式篇章关系进行分析。
41.具体地,当双网络分类器训练结束后,将待识别的论元对输入到双网络分类器中,得到输出结果,包括任务相关型网络的输出结果和任务无关型网络的结果。将任务相关型网络的结果,记为本次篇章关系的识别结果。
42.实施例
43.本实施例描述了应用本发明方法对文本自动摘要处理的具体实施过程。
44.现有的文本自动摘要技术,只是对句子内容、句子之间的先后关系信息、以及段落信息进行了建模,对于句子之间内在的语义篇章关系并没有很好的建模。针对这个问题,通过利用本发明提出的篇章关系分析方法,来帮助下游的文本自动摘要技术提升效果。具体实施方式如下:
45.步骤1:对每一个文本样本,构建论元对。
46.首先,抽取每个整句内的前后子句作为候选论元对。然后,抽取前后整句作为候选论元对。通过构建的规则,从候选论元对中筛选有用的论元对,作为篇章分析的样本。
47.步骤2:针对步骤1中得到的论元对,应用本发明方法的篇章分析技术,得到每个论元对的篇章关系。
48.步骤3:在原有的文本自动摘要模型中,额外增加对篇章关系的建模,让模型更有效的理解不同子句之间、不同整句之间的语义关联,从而提升文本自动摘要的最终效果。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1