内容推荐方法、装置、设备及计算机存储介质与流程
1.本技术涉及计算机技术领域,尤其涉及内容推荐技术领域,提供一种内容推荐方法、装置、设备及计算机存储介质。
背景技术:
2.随着互联网技术的发展,通过互联网能够提供多种内容服务。与此对应的,服务提供商能够通过推荐系统来推荐可能感兴趣的内容,如商品、游戏以及优惠券等。因此,如何精准的进行推荐,是推荐系统比较关注的问题。
3.目前,在进行内容推荐时,基于协同过滤算法的推荐方法由于是基于推荐对象对于待推荐内容的评估矩阵(rating data)进行推荐,而无需相关的特征数据和标签数据,因而这种推荐方法能很好的解决推荐对象数据缺失问题以及新内容的推荐问题。
4.但是,该方法虽然能够解决推荐对象数据缺失问题以及新内容的推荐问题,但是由于该方法仅仅依赖于推荐对象针对某个推荐内容的评估值,在实际场景中的推荐准确率并不高。
技术实现要素:
5.本技术实施例提供一种内容推荐方法、装置、设备及计算机存储介质,用于提升内容推荐的准确率。
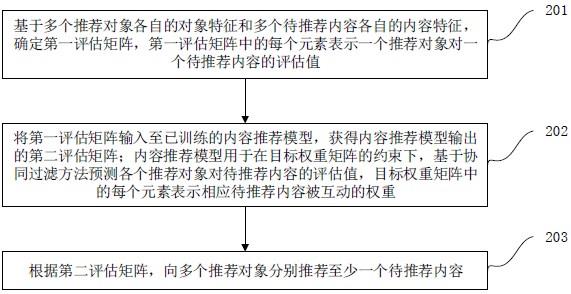
6.一方面,提供一种内容推荐方法,所述方法包括:基于多个推荐对象各自的对象特征和多个待推荐内容各自的内容特征,确定第一评估矩阵,所述第一评估矩阵中的每个元素表示一个推荐对象对一个待推荐内容的评估值;将所述第一评估矩阵输入至已训练的内容推荐模型,获得所述内容推荐模型输出的第二评估矩阵;所述内容推荐模型用于在目标权重矩阵的约束下,基于协同过滤方法预测各个推荐对象对待推荐内容的评估值,所述目标权重矩阵中的每个元素表示相应待推荐内容被互动的权重;根据所述第二评估矩阵,向所述多个推荐对象分别推荐至少一个待推荐内容。
7.一方面,提供一种内容推荐装置,所述装置包括:第一评估单元,用于基于多个推荐对象各自的对象特征和多个待推荐内容各自的内容特征,确定第一评估矩阵,所述第一评估矩阵中的每个元素表示一个推荐对象对一个待推荐内容的评估值;第二评估单元,用于将所述第一评估矩阵输入至已训练的内容推荐模型,获得所述内容推荐模型输出的第二评估矩阵;所述内容推荐模型用于在目标权重矩阵的约束下,基于协同过滤方法预测各个推荐对象对待推荐内容的评估值,所述目标权重矩阵中的每个元素表示相应待推荐内容被互动的权重;推荐单元,用于根据所述第二评估矩阵,向所述多个推荐对象分别推荐至少一个
待推荐内容。
8.可选的,训练单元,具体用于:基于所述初始权重矩阵和所述第三评估矩阵,对所述内容推荐模型进行初始化;基于初始化后的内容推荐模型,获得第四评估矩阵,所述第四评估矩阵中的一个元素表示在相应样本内容当前被互动的权重约束下,一个样本对象对该样本内容的评估值;基于所述第三评估矩阵与所述第四评估矩阵之间的差异值,构建所述内容推荐模型对应的损失函数;基于所述损失函数,采用梯度下降方法对所述内容推荐模型进行参数更新。
9.可选的,所述内容推荐模型的参数包括目标权重矩阵、对象评估矩阵和内容评估矩阵;则所述训练单元,具体用于:以所述初始权重矩阵初始化所述目标权重矩阵;对所述第三评估矩阵进行矩阵分解,获得初始对象特征矩阵和初始内容特征矩阵;以所述初始对象特征矩阵初始化所述对象评估矩阵,以及以所述初始内容特征矩阵初始化所述内容评估矩阵;基于初始化后的内容推荐模型,获得第四评估矩阵,包括:基于所述对象评估矩阵、所述内容评估矩阵以及所述目标权重矩阵,确定各个样本对象分别对各个样本内容的评估值,获得所述第四评估矩阵。
10.可选的,所述训练单元,具体用于:基于所述第三评估矩阵包括的所有评估值,确定整体评估参考值;基于所述第三评估矩阵中各个样本对象各自的至少一个评估值,确定各个样本对象各自对应的对象评估参考值;基于所述第三评估矩阵中各个样本内容各自的至少一个评估值,确定各个样本内容各自对应的内容评估参考值;基于所述对象评估矩阵、所述内容评估矩阵以及所述目标权重矩阵、所述整体评估参考值、对象评估参考值和所述内容评估参考值,确定各个样本对象分别对各个样本内容的评估值,获得所述第四评估矩阵。
11.可选的,所述第一评估单元,具体用于:基于概率预测模型对所述多个推荐对象的对象特征、多个待推荐内容的内容特征进行预测,得到第一预测信息,所述第一预测信息用于指示所述多个推荐对象对各个待推荐内容进行互动操作的概率;根据所述第一预测信息,确定所述第一评估矩阵。
12.可选的,所述训练单元,具体用于:对各个训练样本包括的样本对象各自的稀疏型特征分别进行特征提取,获得相应的对象特征向量,以及对各个训练样本包括的样本内容各自的稀疏型特征分别进行特征提取,获得相应的内容特征向量;基于各个样本对象各自的对象特征向量和稠密型特征以及各个样本内容各自的内容特征向量和稠密型特征,预测各个训练样本对应的预测概率值;
基于各个训练样本包括的互动概率标签和相应的预测概率值,构建所述概率预测模型对应的损失函数,并基于所述损失函数,对所述概率预测模型进行参数更新。
13.可选的,所述第一评估单元,具体用于:基于所述第一预测信息与设定的扩展常数值,获得第二预测信息,所述第二预测信息用于指示所述多个推荐对象对各个待推荐内容的评估值;基于所述第二预测信息进行评估值区间划分,获得多个评估值区间,每个评估值区间对应于一个评估值等级;基于所述多个评估值区间进行矩阵转化处理,获得所述第一评估矩阵。
14.一方面,提供一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现上述任一种方法的步骤。
15.一方面,提供一种计算机存储介质,其上存储有计算机程序指令,该计算机程序指令被处理器执行时实现上述任一种方法的步骤。
16.一方面,提供一种计算机程序产品或计算机程序,该计算机程序产品或计算机程序包括计算机指令,该计算机指令存储在计算机可读存储介质中。计算机设备的处理器从计算机可读存储介质读取该计算机指令,处理器执行该计算机指令,使得该计算机设备执行上述任一种方法的步骤。
17.本技术实施例中,在进行内容推荐时,基于多个推荐对象各自的对象特征和多个待推荐内容各自的内容特征,确定各个推荐对象对各个待推荐内容的第一评估矩阵,并将第一评估矩阵输入至已训练的内容推荐模型,获得第二评估矩阵,进而基于第二评估矩阵向多个推荐对象分别推荐至少一个待推荐内容。其中,内容推荐模型是用于在目标权重矩阵的约束下,基于协同过滤方法预测各个推荐对象对待推荐内容的评估值,目标权重矩阵中的每个元素表示相应待推荐内容被互动的权重,从而在各个推荐对象对各个待推荐内容的第一评估矩阵上,增加了待推荐内容侧被互动权重的约束,例如针对自身使用率较低的待推荐内容降低其所占的权重,降低这些待推荐内容被推荐给推荐对象的概率,有效提升实际推荐场景中的推荐准确率。
附图说明
18.为了更清楚地说明本技术实施例或相关技术中的技术方案,下面将对实施例或相关技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本技术实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据提供的附图获得其他的附图。
19.图1为本技术实施例提供的应用场景示意图;图2为本技术实施例提供的内容推荐方法的流程示意图;图3为本技术实施例提供的确定第一评估矩阵的流程示意图;图4为本技术实施例提供的概率预测模型的训练流程示意图;图5为本技术实施例提供的概率预测模型的模型结构示意图;图6为本技术实施例提供的得到第二评估矩阵的流程示意图;图7为本技术实施例提供的采用协同过滤方法填充前后的对比示意图;图8为本技术实施例提供的内容推荐模型的训练流程示意图;
图9为本技术实施例提供的得到初始权重矩阵的流程示意图;图10为本技术实施例提供的内容推荐完整方法的流程示意图;图11为本技术实施例提供的内容推荐装置的一种结构示意图;图12为本技术实施例提供的电子设备的组成结构示意图;图13为应用本技术实施例的另一种电子设备的组成结构示意图。
具体实施方式
20.为使本技术的目的、技术方案和优点更加清楚明白,下面将结合本技术实施例中的附图,对本技术实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本技术一部分实施例,而不是全部的实施例。基于本技术中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本技术保护的范围。在不冲突的情况下,本技术中的实施例及实施例中的特征可以相互任意组合。并且,虽然在流程图中示出了逻辑顺序,但是在某些情况下,可以以不同于此处的顺序执行所示出或描述的步骤。
21.可以理解的是,在本技术的下述具体实施方式中,涉及到对象特征等相关的数据,当本技术的各实施例运用到具体产品或技术中时,需要获得相关许可或者同意,且相关数据的收集、使用和处理需要遵守相关国家和地区的相关法律法规和标准。例如,在需要获得相关的数据时,可以通过招募相关志愿者并签署志愿者授权数据的相关协议,进而可以使用这些志愿者的数据进行实施;或者,通过在已授权允许的组织内部范围内进行实施,通过采用组织内部成员的数据实施下述的实施方式来向内部成员进行相关推荐;或者,具体实施时所采用的相关数据均为模拟数据,例如可以是虚拟场景中产生的模拟数据。
22.为便于理解本技术实施例提供的技术方案,这里先对本技术实施例使用的一些关键名词进行解释:协同过滤(collaborative filtering,cf)推荐算法:可以包括基于推荐对象的协同过滤推荐算法和基于待推荐内容的协同过滤推荐算法,两者原理上类似,以基于推荐对象的协同过滤推荐算法为例,是一种通过分析推荐对象的兴趣,在推荐对象群中找到指定推荐对象的相似推荐对象,综合这些相似推荐对象对某一待推荐内容的评估值,形成推荐系统对该指定推荐对象对此待推荐内容的喜好程度的预测,进而进行相关推荐的方法。
23.深度神经网络(deep neural networks,dnn):是一种具有多层网络架构的神经网络。
24.奇异值(singular value decomposition,svd)分解:是一种线性代数中的矩阵分解方法,svd分解是特征分解在任意矩阵上的推广,在信号处理、统计学等领域具有重要应用。例如针对一个m
×
n阶的矩阵m,其中的元素全部属于域k,也就是实数域或复数域,如此,则存在一个分解满足如下公式:其中,u是m
×
m阶酉矩阵,σ是m
×
n阶非负实数对角矩阵,而,即v的共轭转置,是n
×
n阶酉矩阵。
25.评估矩阵:评估矩阵的行为推荐对象,列为待推荐内容,行列交叉的评估值为该行
的推荐对象针对该列的待推荐内容的评估值,评估值表征该推荐对象对该待推荐内容的感兴趣程度。例如在商品推荐场景中,行为推荐对象,列为商品,行列交叉的评估值为推荐对象对商品的评估值,在需要向推荐对象推荐商品时,可以根据该评估矩阵中该推荐对象针对各个商品的评估值进行排序,进而向该推荐对象推荐评估值较高的商品。
26.权重矩阵:或称偏好权重矩阵,该矩阵中的每个元素表征一个或者一类待推荐内容的被互动的权重,该权重能够表征总体推荐对象对于一个或者一类待推荐内容的整体偏好,权重值越高,表征该待推荐内容被推荐对象偏好的可能性越大,即符合推荐对象的偏好需求的可能性更高。
27.模型测评指标:在针对一个模型进行训练后,通常需要采用测试样本对其进行测试,如果测评指标达标,则该模型可以投入到实际的应用过程中。通常而言,测评指标可以包括查准率(recall score)、查全率(precision score)、受试者工作特征(receiver operating characteristic curve,roc)曲线下与坐标轴围成的面积(area under curve,auc)等指标。
28.查准率是指对于模型判定的所有正样本中真正的正样本所占的比例,查全率是指真正的正样本中模型判定为正样本的比例,即:真正的正样本中模型判定为正样本的比例,即:其中,tp和fp分别表示true positive和false positive,即所谓的真正样本和假正样本,fn表示false nagetive,即假负样本。
29.auc(area under curve)被定义为roc曲线下与坐标轴围成的面积,显然这个面积的数值不会大于1,又由于roc曲线一般都处于y=x这条直线的上方,所以auc的取值范围在0.5和1之间,auc越接近1.0则真实性越高,等于0.5时,则真实性最低,无应用价值。举例来讲,若训练样本总共有(m+n)个,其中正样本m个,负样本n个,总共可以有mn个样本对,计数正样本预测为正样本的概率值大于负样本预测为正样本的概率值记为1,计数结果除以(mn)就是auc的值。
30.优惠加油:是指出行服务相关应用中的车主加油模块服务,该模块服务主要用于对符合推荐目标的推荐对象进行优惠加油券的推荐服务。
31.对象特征:本技术实施例中涉及到的对象可以是网络中进行互动行为的主体,例如可以是以推荐系统中的账户作为推荐对象进行推荐,对象特征可以由各个账户在业务中的行为记录及其数据进行提炼,例如可以包括:在业务中的点击、收藏、付费金额、付费次数、活跃时长以及活跃天数等。
32.内容特征:本技术实施例中涉及到的内容可以是网络中任意存在的内容,例如包括但不限于新闻、小说、图像、商品以及优惠券等,其可以包括实体物品,也可以包括网络中的虚拟资源。内容特征则可以由待推荐内容的属性及其数据进行提炼,例如可以包括:待推荐内容的点击率、费率、收藏、平均付费金额(总付费金额/付费人数)以及平均活跃时长(总活跃时间/活跃人数)等。
33.本技术实施例的技术方案涉及人工智能和机器学习技术,人工智能(artificial intelligence,ai)是利用数字计算机或者数字计算机控制的机器模拟、延伸和扩展人的智能,感知环境、获取知识并使用知识获得最佳结果的理论、方法、技术及应用系统。换句话
说,人工智能是计算机科学的一个综合技术,它企图了解智能的实质,并生产出一种新的能以人类智能相似的方式做出反应的智能机器。人工智能也就是研究各种智能机器的设计原理与实现方法,使机器具有感知、推理与决策的功能。
34.人工智能技术是一门综合学科,涉及领域广泛,既有硬件层面的技术也有软件层面的技术。人工智能基础技术一般包括如传感器、专用人工智能芯片、云计算、分布式存储、大数据处理技术、操作/交互系统、机电一体化等技术。人工智能软件技术主要包括计算机视觉技术、语音处理技术、自然语言处理技术以及机器学习/深度学习、自动驾驶、智慧交通等几大方向。
35.其中,机器学习是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。机器学习是人工智能的核心,是使计算机具有智能的根本途径,其应用遍及人工智能的各个领域。机器学习和深度学习通常包括人工神经网络、置信网络、强化学习、迁移学习、归纳学习、式教学习等技术。
36.随着人工智能技术研究和进步,人工智能技术在多个领域展开研究和应用,例如常见的智能家居、智能穿戴设备、虚拟助理、智能音箱、智能营销、无人驾驶、自动驾驶、无人机、机器人、智能医疗、智能客服、车联网、自动驾驶、智慧交通等,相信随着技术的发展,人工智能技术将在更多的领域得到应用,并发挥越来越重要的价值。
37.本技术实施例提供的方案涉及人工智能的机器学习技术。在本技术实施例提出的概率预测模型主要应用于对象对于内容进行互动的概率预测,以构建相应的评估矩阵,内容推荐模型则主要应用于在权重矩阵的影响下,预测各个对象对各个内容的评估值。概率预测模型或者内容推荐模型的训练和使用方法均可以分为两部分,包括训练部分和应用部分;其中,训练部分就涉及到机器学习这一技术领域,在训练部分中,通过机器学习这一技术训练概率预测模型或者内容推荐模型,并通过优化算法不断调整模型参数,直至模型收敛,包括训练样本通过概率预测模型后,获得相应的预测概率值,通过内容推荐模型后,获得相应的评估值等;应用部分用于通过使用在训练部分训练得到的概率预测模型获得预测概率值,从而基于预测概率值获得评估矩阵输入内容推荐模型后,获得相应的评估值等。另外,还需要说明的是,本技术实施例中人工神经网络模型可以是在线训练也可以是离线训练,在此不做具体限定,在本文中是以离线训练为例进行举例说明的。
38.下面对本技术实施例的设计思想进行简要介绍:基于协同过滤的推荐方法能很好的解决推荐对象数据缺失问题以及新内容的推荐问题,然而,基于协同过滤的推荐方法需要输入评估矩阵,而评估矩阵源于推荐对象对待推荐内容的评估值,而原始的评估值往往是推荐对象的主观评分,缺乏科学评分依据,并且该方法的推荐效果比较粗糙,并没有使用推荐对象和待推荐内容更丰富的特征数据,从而造成推荐效果不佳。
39.例如,在优惠加油推荐场景中,由于大量的优惠券都存在使用率、转化率较低的情况,而现有协同过滤推荐方法是针对全量的优惠券进行推荐,而没有对使用率、转化率较低的优惠券施加权重约束,会带来较大的无效计算,并且容易造成计算误差,从而导致在实际场景中的推荐准确率并不高。
40.鉴于此,本技术实施例提供一种内容推荐方法、装置、电子设备和存储介质。其中,
该方法在进行内容推荐时,基于多个推荐对象各自的对象特征和多个待推荐内容各自的内容特征,确定各个推荐对象对各个待推荐内容的第一评估矩阵,并将第一评估矩阵输入至已训练的内容推荐模型,获得第二评估矩阵,进而基于第二评估矩阵向多个推荐对象分别推荐至少一个待推荐内容。其中,内容推荐模型是用于在目标权重矩阵的约束下,基于协同过滤方法预测各个推荐对象对待推荐内容的评估值,目标权重矩阵中的每个元素表示相应待推荐内容被互动的权重,从而在各个推荐对象对各个待推荐内容的第一评估矩阵上,增加了待推荐内容侧被互动权重的约束,例如针对自身使用率较低的待推荐内容降低其所占的权重,降低这些待推荐内容被推荐给推荐对象的概率,有效提升实际推荐场景中的推荐准确率,同时增强推荐模型的泛化能力。
41.本技术实施例中,针对内容推荐模型进行训练时,权重矩阵的初始化采用获得的初始权重矩阵来进行,初始权重矩阵是根据样本对象(或推荐对象)对于样本内容(或待推荐内容)的初始权重采用秩排序方法确定的,从而能够减少随机初始化权重给排序效果带来的不稳定性,有效提高推荐效果。此外,本技术实施例中基于损失函数最小原理,并通过梯度下降法,确定样本对象(或推荐对象)对于样本内容(或待推荐内容)最终的偏好权重,能够有效通过对象特征及内容特征确定样本对象(或推荐对象)对于样本内容(或待推荐内容)的偏好权重向量,进而提高后续的推荐效果。
42.下面对本技术实施例的技术方案能够适用的应用场景做一些简单介绍,需要说明的是,以下介绍的应用场景仅用于说明本技术实施例而非限定。在具体实施过程中,可以根据实际需要灵活地应用本技术实施例提供的技术方案。
43.本技术实施例提供的方案可以适用于大多数内容推荐场景中,例如优惠加油推荐场景、歌曲推荐场景、视频推荐场景、新闻推荐场景以及购物平台商品推荐场景等,在此不再一一进行例举。如图1所示,为本技术实施例提供的一种应用场景示意图,在该场景中,可以包括终端设备101和服务器102。
44.终端设备101例如可以为手机、平板电脑(pad)、笔记本电脑、台式电脑、智能电视、智能车载设备以及智能可穿戴设备等。终端设备101可以安装有内容推荐应用,内容推荐应用可以为即时通信应用、音乐播放应用、视频播放应用、新闻应用、购物平台应用以及优惠加油应用等。本技术实施例涉及的应用可以是软件客户端,也可以是网页、小程序等客户端,服务器102则是与软件或是网页、小程序等相对应的后台服务器,不限制客户端的具体类型。例如可以是独立的物理服务器,也可以是多个物理服务器构成的服务器集群或者分布式系统,还可以是提供云服务、云数据库、云计算、云函数、云存储、网络服务、云通信、中间件服务、域名服务、安全服务、即内容分发网络(content delivery network,cdn)、以及大数据和人工智能平台等基础云计算服务的云服务器,但并不局限于此。
45.需要说明的是,本技术实施例中的内容推荐方法可以由终端设备101或服务器102单独执行,也可以由服务器102和终端设备101共同执行。例如,由服务器102基于多个推荐对象各自的对象特征和多个待推荐内容各自的内容特征,确定各个推荐对象对各个待推荐内容的第一评估矩阵,并将第一评估矩阵输入至已训练的内容推荐模型,获得第二评估矩阵,进而基于第二评估矩阵向多个推荐对象分别推荐至少一个待推荐内容。或者,由终端设备101执行上述步骤。再或者,由服务器102基于上述步骤获取第二评估矩阵,再由终端设备基于第二评估矩阵获取向当前推荐对象推荐的至少一个待推荐内容等,呈现相应的内容推
荐界面,本技术在此不做具体限定,下文主要是以服务器102为例进行举例说明的。
46.以服务器102执行上述步骤为例,服务器102可以包括一个或多个处理器1021、存储器1022以及与终端交互的i/o接口1023等。此外,服务器102还可以配置数据库1024,数据库1024可以用于存储对象特征数据、内容特征数据以及训练得到的模型参数等。其中,服务器102的存储器1022中还可以存储本技术实施例提供的内容推荐方法的程序指令,这些程序指令被处理器1021执行时能够用以实现本技术实施例提供的内容推荐方法的步骤,以实现内容推荐过程。
47.在一种可能的实施方式中,本技术实施例的方法可以应用于优惠加油推荐场景,那么为了实现向推荐对象实现优惠加油优惠券的推荐,可以请求推荐对象授权其在该推荐系统中推荐所需的对象数据,例如对象标识(identity,id)、历史优惠券使用数据和在优惠加油页面中的操作数据等,在推荐对象允许的情况下,获得相关的对象特征数据、优惠券特征数据,输入至本技术实施例提供的概率预测模型中,来获得各个推荐对象针对各个优惠券进行下载的概率值,并将基于概率值构建的第一评估矩阵输入至内容推荐模型中,使得内容推荐模型基于各个优惠券受到整体推荐对象的偏好权重的约束下,获得第二评估矩阵,第二评估矩阵中的评估值是在相应优惠券的偏好权重的约束下所得到的,从而能够有效的降低使用率、转化率较低的优惠券的权重,避免产生无效计算,提升优惠券的推荐准确性。
48.在一种可能的实施方式中,本技术实施例的方法可以应用于车联网的歌曲推荐场景,同样的,为了实现向推荐对象实现歌曲的推荐,可以请求推荐对象授权其在该推荐系统中推荐所需的对象数据,例如对象标识(identity,id)、历史听歌数据和搜歌数据等,在推荐对象允许的情况下,获得相关的对象特征数据、歌单列表中各个待推荐歌曲的特征数据,输入至本技术实施例提供的概率预测模型中,来获得各个推荐对象针对各个待推荐歌曲进行收听的概率值,并将基于概率值构建的第一评估矩阵输入至内容推荐模型中,使得内容推荐模型基于各个待推荐歌曲受到整体推荐对象的偏好权重的约束下,获得第二评估矩阵,第二评估矩阵中的评估值是在相应待推荐歌曲的偏好权重的约束下所得到的,而通过施加权重约束,能够有效的降低歌单列表中大量收听率低的歌曲权重,有效提升模型计算效率,提升歌曲的推荐准确性。
49.本技术实施例中,终端设备101和服务器102之间可以通过一个或者多个网络103进行直接或间接的通信连接。该网络103可以是有线网络,也可以是无线网络,例如无线网络可以是移动蜂窝网络,或者可以是无线保真(wireless-fidelity,wifi)网络,当然还可以是其他可能的网络,本发明实施例对此不做限制。
50.需要说明的是,图1所示只是举例说明,实际上终端设备和服务器的数量不受限制,在本技术实施例中不做具体限定。
51.下面结合上述描述的应用场景,参考附图来描述本技术示例性实施方式提供的内容推荐方法,需要注意的是,上述应用场景仅是为了便于理解本技术的精神和原理而示出,本技术的实施方式在此方面不受任何限制。
52.参见图2所示,为本技术实施例提供的内容推荐方法的流程示意图,这里是以服务器为执行主体为例进行举例说明的,该方法的具体实施流程如下:步骤201:基于多个推荐对象各自的对象特征和多个待推荐内容各自的内容特征,
确定第一评估矩阵,第一评估矩阵中的每个元素表示一个推荐对象对一个待推荐内容的评估值。
53.在本技术实施例中,推荐对象的对象特征可以包括如下数据中的一种或者多种的组合:(1)基础属性数据,例如可以包括对象标识(userid)、对象类型、年龄、地域等;(2)活跃属性数据,例如可以包括活跃天数(使用推荐系统的天数)、活跃时长、活跃功能数量(使用推荐系统功能的数量)、注册时长等;(3)使用推荐系统进行电子资源转移的属性数据,例如可以包括资源转移数量、资源转移次数、资源转移天数、首次资源转移距离当前时间天数间隔等;(4)内容互动属性数据,例如可以包括针对推荐系统的页面提供的功能的点击情况、历史推荐的内容的互动情况。可以理解的是,待推荐内容依据实际的推荐场景而设定,例如在优惠加油场景中,则待推荐内容具体可以为加油优惠券或者优惠券包;或者,在歌曲推荐场景中,则待推荐内容具体可以为待推荐的歌曲、歌手或者歌单;或者,在购物平台场景中,则待推荐内容具体可以为购物平台中的商品;当然,在其他内容推荐场景中,则待推荐内容可以相应设定,在此不再一一例举。
54.这里以优惠加油场景中的加油优惠券为例,则内容互动属性数据主要包括推荐对象在出行服务应用页面中的操作记录特征数据,点击情况可以是指针对该页面中的各个功能点的点击情况,历史推荐的内容的互动情况可以包括历史领取加油优惠礼包/礼券、使用加油优惠礼包/礼券、过期加油优惠礼包/礼券等优惠券互动属性,互动属性具体可以包括类型、数量、次数和价值等维度的数据。
55.在本技术实施例中,待推荐内容的内容特征可以包括内容的基础属性数据(如内容id(itemid))以及互动相关数据,例如点击率、下载率、曝光量、点击量等特征数据。同样以优惠加油场景中的加油优惠券为例,待推荐内容的内容特征可以包括优惠券id、优惠券额度、适用地域、适用期限、适用商户以及优惠券类型等基础属性数据,还可以包括历史下载次数和使用次数等被互动数据。当然,在其他内容推荐场景中,具体的内容特征可以依据实际场景进行选定,本技术实施例对此并不进行限定。
56.在本技术实施例中,评估值可以表征推荐对象对于待推荐内容的感兴趣程度,即反映出推荐对象对待推荐内容进行互动操作的可能性,通常而言,评估值越高,则表明推荐对象对待推荐内容进行互动操作的可能性更高,从而在向推荐对象进行内容推荐时,能够依据评估值衡量各个待推荐内容的推荐程度。
57.在一种可能的实施方式中,内容推荐可以具有周期性,即内容推荐过程可以周期性的进行,例如以一天、一周或者一月为一个推荐周期,在一个推荐周期内,可以基于当前获得的特征数据,重新计算推荐所需的评估矩阵,以保障推荐结果符合推荐对象近期的需求和习惯。
58.步骤202:将第一评估矩阵输入至已训练的内容推荐模型,获得内容推荐模型输出的第二评估矩阵;内容推荐模型用于在目标权重矩阵的约束下,基于协同过滤方法预测各个推荐对象对待推荐内容的评估值,目标权重矩阵中的每个元素表示相应待推荐内容被互动的权重。
59.在本技术实施例中,为了降低大量互动率低的待推荐内容的权重,在内容推荐模
型加入了待推荐内容侧的偏好权重约束,以在基于当前推荐周期的对象特征和内容特征得到的第一评估矩阵的基础上,增加偏好权重约束的影响,使得得到的第二评估矩阵能够更加符合实际推荐场景的需求。
60.此外,内容推荐模型采用了协同过滤方法对评估矩阵进行处理,以对缺失的评估值进行填充,得到推荐对象对没有评估值的待推荐内容的评估值数据,以便于按照评估值排序进行推荐。
61.在一种可能的实施方式中,内容推荐模型可以采用基于svd分解的协同过滤方法,即对评估矩阵进行矩阵分解,基于分解得到的对象特征矩阵和内容特征矩阵来填充原评估矩阵中的缺失数据。
62.步骤203:根据第二评估矩阵,向多个推荐对象分别推荐至少一个待推荐内容。
63.在本技术实施例中,在得到第二评估矩阵后,则可以按照第二评估矩阵中每个推荐对象针对各个待推荐内容的评估值进行降序排列,然后选择前n个待推荐内容向推荐对象进行个性化推荐。
64.本技术实施例通过在目标权重矩阵的约束下,基于协同过滤方法预测各个推荐对象对待推荐内容的评估值,目标权重矩阵中的每个元素表示相应待推荐内容被互动的权重,从而在各个推荐对象对各个待推荐内容的第一评估矩阵上,增加了待推荐内容侧被互动权重的约束,例如针对自身使用率较低的待推荐内容降低其所占的权重,降低这些待推荐内容被推荐给推荐对象的概率,有效提升实际推荐场景中的推荐准确率,同时增强推荐模型的泛化能力。
65.一种可能的实施方式中,可以按照如图3所示的流程图来实施201,其为本技术实施例提供的确定第一评估矩阵的流程示意图,包括如下步骤:s2011:基于概率预测模型对多个推荐对象的对象特征、多个待推荐内容的内容特征进行预测,得到第一预测信息,第一预测信息用于指示多个推荐对象对各个待推荐内容进行互动操作的概率。
66.在本技术实施例中,提供了概率预测模型,概率预测模型用于基于输入的对象特征和内容特征进行预测,来得到推荐对象对待推荐内容感兴趣的概率,概率越大,表征荐对象对待推荐内容感兴趣的可能性更高。因而,可以基于概率预测模型对上述获得的多个推荐对象的对象特征、多个待推荐内容的内容特征进行预测,得到多个推荐对象对各个待推荐内容进行互动操作的概率。
67.在具体实施时,概率预测模型是需要预先进行训练的,训练的过程将在后续过程总具体进行介绍,在此先不过多进行赘述。
68.在得到第一预测信息之后,则可以基于第一预测信息来确定得到相应的第一评估矩阵。
69.s2012:基于第一预测信息与设定的扩展常数值,获得第二预测信息,第二预测信息用于指示多个推荐对象对各个待推荐内容的评估值。
70.具体的,第一预测信息p可以表示为:其中,表示第i个概率区间,其包括部分推荐对象对待推荐内容进行互动的概率
值。
71.通常而言,概率值的取值的分布较为密集,因而便于后续进行概率区间的划分,可以将第一预测信息中各个概率值与设定的扩展常数值进行相乘来扩大概率值,得到第二预测信息。
72.s2013:基于第二预测信息进行评估值区间划分,获得多个评估值区间,每个评估值区间对应于一个评估值等级。
73.具体的,第二预测信息s可以表示为::其中,为推荐对象对待推荐内容的第i个等级的评分,i∈(1,
…
,m),即(1,
…
,m)表示推荐对象对待推荐内容的第1,
…
,m个等级的评分,表示第i个概率区间,c为扩展常数,其值可以根据经验值设定,也可以根据训练过程进行设定,本技术实施例对c的值不进行限制。
74.本技术实施例中,评估值区间划分可以按照等距方法进行。
75.s2014:基于多个评估值区间进行矩阵转化处理,获得第一评估矩阵。
76.在本技术实施例中,通过上述过程得到的第一评估矩阵的行表示推荐对象或者待推荐内容,列表示推荐对象或者待推荐内容,例如,当行为推荐对象时,则列为待推荐内容,行列交叉的rating data为该行的推荐对象对该列的待推荐内容的评估值。
77.一种可能的实施方式中,可以按照如图4所示的流程图来训练得到概率预测模型,其为本技术实施例提供的概率预测模型的训练流程示意图,包括如下步骤:步骤401:获取样本数据集,样本数据集中每个样本包括样本对象的对象特征、样本内容的内容特征和互动概率标签。
78.在本技术实施例中,样本数据集由样本对象的对象特征、样本内容的内容特征和互动概率标签构建而成,对象特征和内容特征可以包括前述的对象特征和内容特征中的任意一种,互动概率标签作为监督数据,对概率预测模型进行训练,其可以表征一个样本对象对一个样本内容进行互动操作的概率。
79.例如,以上述优惠加油场景为例,概率预测模型可以用于推荐对象对一个优惠券下载的概率,那么互动概率标签则可以是用于表征样本对象对优惠券是否会进行下载,例如标签值1可以表示点击且下载,那么标签值为1的样本可以称为正样本,标签值为0可以表示点击不下载,那么标签值为0的样本可以称为负样本。
80.在本技术实施例中,当采用周期性推荐的方式时,则可以利用历史推荐周期的特征数据构建样本数据,并按照一定比例a随即进行样本切分,划分为训练样本和测试样本,在进行切分时可以按照通用经验将样本随机切分,如按照训练样本:测试样本 = 8:2,即按8:2的比例随机切分训练样本和测试样本,进而通过训练样本对概率预测模型进行训练,以及通过测试样本测试训练得到的模型是否达标。
81.在一种可能的实施方式中,当前推荐周期记为t期时,上一个推荐周期记为t-1期,则可以采用t-1期的特征数据和t-1期的互动概率标签来构建训练样本和测试样本,每个样本可以包括一个样本对象和样本内容以及相应的互动概率标签,表征该样本对象对该样本
内容是否会进行互动操作。
82.在一种可能的实施方式中,为了扩充样本,还可以采用当期的互动概率标签一并进行样本构建,即在构建训练样本和测试样本时,可以采用t期的分类标签和t-1期的特征数据按照对象标识(userid)等关键字进行关联,得到训练样本和测试样本。
83.步骤402:对各个训练样本包括的样本对象各自的稀疏型特征分别进行特征提取,获得相应的对象特征向量(embedding),以及对各个训练样本包括的样本内容各自的稀疏型特征分别进行特征提取,获得相应的内容特征向量。
84.在本技术实施例中,特征数据包括稀疏型特征和稠密型特征,稀疏型特征例如可以包括userid、itemid等id类特征、性别特征以及年龄段等具备标记性的特征,稠密型特征例如可以包括天数、资源转移数量、资源转移次数、操作次数等连续型特征。
85.参见图5所示,为概率预测模型的模型结构示意图。其中,概率预测模型可以采用wide&deep模型结构,其包括wide部分和deep部分,训练样本中的稀疏型特征用于deep部分的训练,训练样本中的稠密型特征和互动概率标签用于wide部分的训练。与此同理,测试样本的特征也分为稀疏型特征和稠密型特征,稀疏型特征用于deep部分的模型测试,稠密型特征和互动概率标签用于wide部分的模型测试,此外,在预测阶段,将t期的对象特征、内容特征也可以分为稀疏型特征和稠密型特征,稀疏型特征用于deep部分的预测,稠密型特征用于wide部分的模型预测。
86.在本技术实施例中,在利用稀疏型特征对deep部分进行训练时,可以通过deep部分对各个样本对象的稀疏型特征分别进行特征提取,获得相应的对象embedding,以及对各个样本内容的稀疏型特征分别进行特征提取,获得相应的内容embedding,当deep部分训练完成后,则可以获得最终的对象embedding和内容embedding。
87.在一种可能的实施方式中,还可以在获得每个训练样本的对象embedding和内容embedding后,通过deep部分对对象embedding和内容embedding进行融合来得到该训练样本的融合embedding。
88.在另一种可能的实施方式中,还可以通过deep部分对每个训练样本包括的样本对象和样本内容的稀疏型特征一并进行特征提取,得到该训练样本的融合向量,用于后续该训练样本的概率预测。
89.在本技术实施例中,deep部分可以采用任意具备特征提取功能的神经网络来实现,例如,可以采用多层网络架构的dnn模型实现wide部分的功能。
90.在一种可能的实施方式中,例如可以采用5层网络架构的dnn模型,层数越多,训练难度越大,因而5层网络架构是本技术实施例通过权衡训练难度和精度后选取的层数,在满足特征提取精度的同时,能够尽可能使得训练难度能够接受。在采用5层网络架构时,dnn模型可以包括输入层、多个隐藏层和输出层。
91.步骤403:基于各个样本对象各自的对象特征向量和稠密型特征以及各个样本内容各自的内容特征向量和稠密型特征,预测各个训练样本对应的预测概率值。
92.在本技术实施例中,将dnn模型训练出来得到的embadding特征结合训练样本中的稠密型特征和互动概率标签使用wide部分进行训练。
93.在本技术实施例中,wide部分可以采用任意具备基于特征进行概率预测的网络来实现,例如,可以采用逻辑回归(logistic regression,lr)模型。
94.步骤404:基于各个训练样本包括的互动概率标签和相应的预测概率值,构建概率预测模型对应的损失函数,并基于损失函数,对概率预测模型进行参数更新。
95.在对wide部分进行训练时,通过将各个训练样本的embadding特征和稠密型特征输入至wide部分,得到相应的预测概率值,并基于互动概率标签和预测概率值构建概率预测模型对应的损失函数,当损失值达到阈值条件或者训练迭代次数达到设定次数时,则训练结束。
96.在模型仍不满足收敛条件时,可以通过梯度下降法更新得到模型权重参数,并以更新后的模型权重参数继续进行训练。其中,模型权重参数用于衡量特征x对y的贡献,特征x是指输入至wide部分的embadding特征和稠密型特征,y即为预测得到的概率值。
97.一种方式是deep部分和wide部分可以先后分别进行训练,例如可以先训练得到deep部分后,基于训练好的deep部分得到的embadding特征对wide部分进行训练。
98.另一种方式是deep部分和wide部分可以同时进行训练,即可以将整个概率预测模型作为一个整体,通过deep部分获得embadding特征后,继续通过wide部分预测概率值,并基于预测概率值对整个概率预测模型的模型参数进行调整,包括deep部分和wide部分的参数调整。
99.为了验证训练好的概率预测模型的效果,本技术实施例对训练好的概率预测模型使用测试样本进行测试,如果测评指标达到预设测评效果,则保存概率预测模型和训练样本得到的概率值、测试样本得到的概率值,这里的概率值可以是指最终一次迭代训练时得到的概率值。如果没有通过模型评估,则需要继续进行训练和测试,直至概率预测模型达到预设测评效果为止。
100.在一种可能的实施方式中,可以采用查全率、查准率、auc等指标中的一个或者多个指标作为测评指标,当查全率、查准率、auc满足相应的指标阈值时,则认为达到预设测评效果,否则,则认为尚未达到预设测评效果。
101.可以理解的是,由于采用t-1期的特征数据进行训练,并采用t期的数据进行预测,为了提升预测的准确性,在训练阶段所涉及到的样本对象可以是与预测阶段的待推荐对象是相同的,当然,在实际应用时,可能出现t期存在新增对象或者已注销对象的情况,那么当t-1期和t期存在重合的对象时,重合对象可以采用上述保存的概率值数据继续后续的推荐过程。同理,在训练阶段所涉及到的样本内容也可以是与预测阶段的待推荐内容是相同的,当然,在实际应用时,可能出现t期存在新增内容或者已注销内容的情况,那么当t-1期和t期存在重合的内容时,重合内容可以采用上述保存的概率值继续后续的推荐过程。
102.在一种可能的实施方式中,本技术实施例通过严格的数学推导重新构建带权重的svd分解的协同过滤算法模型,其可以表示如下:
其中,u表示对象评估矩阵,维度为n*h,ui表示第i个对象的特征向量(i=1,
…
,n);v表示内容评估矩阵,维度为h*m,vj表示第j个内容的向量序列(j=1,
…
,m);w表示目标权重矩阵,维度为1*m,wj表示第j个内容的权重;n表示对象数量,m表示内容数量;s表示对象对内容的评估矩阵,维度为n*m;表示整体评估参考值;bi表示对象评估参考值;bj表示内容评估参考值;ku表示对象的限制常量;kv表示内容的限制常量,上述的对象可以是样本对象,也可以是推荐对象,上述的内容可以是样本内容,也可以是推荐内容。
103.一种可能的实施方式中,可以按照如图6所示的流程图来实施202,其为本技术实施例提供的得到第二评估矩阵的流程示意图,包括如下步骤:步骤2021:基于内容推荐模型的对象评估矩阵、内容评估矩阵以及目标权重矩阵,确定各个样本对象分别对各个样本内容的评估值。
104.将对象评估矩阵、内容评估矩阵以及目标权重矩阵等参数值带入到上述模型公式中,得到新的预测评估矩阵。
105.步骤2022:判断预测评估矩阵是否满足设定条件。
106.在本技术实施例中,将第一评估矩阵与预测评估矩阵代入损失函数,以确定是否满足最小损失值条件,例如基于损失函数计算的损失值满足阈值条件,则确定预测评估矩阵满足设定条件,否则确定预测评估矩阵不满足设定条件。
107.步骤2023:若确定预测评估矩阵不满足设定条件,则对内容推荐模型进行参数更新,例如针对上述对象评估矩阵、内容评估矩阵以及目标权重矩阵等参数进行更新,并以更新后的参数待入到上述公式中重新计算新的预测评估矩阵,并跳转步骤2022进行判断,直至最新的评估矩阵满足条件。
108.步骤2024:若确定预测评估矩阵满足设定条件,则对预测评估矩阵基于协同过滤方法进行矩阵分解,并填充预测评估矩阵中的缺失数据,获得第二评估矩阵。
109.参见图7所示,为采用协同过滤方法填充前后的对比示意图,针对第一评分矩阵,在目标权重矩阵的约束下,采用协同过滤方法进行矩阵分解,得到对象评估矩阵和内容评估矩阵,从而基于对象评估矩阵和内容评估矩阵填充得到第二评分矩阵。在填充前部分对
象对于内容的评估值是缺乏的,通过协同过滤的方法进行填充后,所有对象针对各个内容的评估值均不再缺失,以便于后续作为推荐过程的参考依据。
110.在本技术实施例中,在基于内容推荐模型获得第二评估矩阵之前,需要对内容推荐模型进行训练,针对内容推荐模型训练的训练样本可以沿用前述概率预测模型训练时使用的训练样本,从而减小收集训练样本所耗费的工作和时间,提升整体流程的效率。
111.基于上述模型可见,本技术实施例中的内容推荐模型的参数包括对象评估矩阵、目标权重矩阵和内容评估矩阵,以及整体评估参考值、对象评估参考值和内容评估参考值,这些参数需要在训练过程中更新获得。
112.参照图8所示,为本技术实施例提供的内容推荐模型的训练流程示意图,包括如下步骤:步骤801:基于各个训练样本包括的样本内容各自对应的历史互动次数集合,确定初始权重矩阵,每个历史互动次数集合包括至少一个样本对象对相应样本内容进行互动的次数。
113.在一种可能的实施方式中,目标权重矩阵的初始化可以采用随机初始化的方式,即针对目标权重矩阵的各个元素进行随机赋值,继而在后续的训练过程中对其不断进行优化更新,获得最终的目标权重矩阵。
114.在另一种可能的实施方式中,还可基于实际的互动数据获得各个样本内容的初始权重,进而依次初始权重初始化目标权重矩阵,从而减少随机初始化权重给排序效果带来的不稳定性,有效提高推荐效果,同时提升模型收敛的速度,提升训练效率。
115.具体的,可以按照如图9所示的流程图来实施801,其为本技术实施例提供的得到初始权重矩阵的流程示意图,包括如下步骤:步骤8011:基于各个历史互动次数集合,对各个训练样本包括的样本内容进行聚类,获得至少一种内容类别,每种内容类别包括至少一个样本内容。
116.其中,每个历史互动次数集合包括的是一个样本内容被各个样本对象互动的次数,以内容为优惠券为例,可以是指优惠券被各个对象使用的次数或者被各个对象下载的次数等。
117.在一种可能的实施方式中,可以根据各个样本内容的历史互动次数集合采用k-均值(k-means)方法进行聚类。当然,也可以采用其他可能的聚类方法进行,本技术实施例对此不做限制。
118.步骤8012:基于至少一种内容类别各自对应的互动次数参考值按秩排序,每个互动次数参考值是根据相应内容类别包括的样本内容的历史互动次数集合确定的。
119.在本技术实施例中,一个内容类别的互动次数参考值例如可以是该类别包括的样本内容的历史互动次数的均值,当然,也可以采用历史互动次数之和等其他值进行表示。
120.可以理解的是,当设置聚类类别与样本内容的数量相同时,则一个类别实质上即为一个样本内容,而互动次数参考值则是该样本内容的历史互动次数的均值;当设置聚类类别小于与样本内容的数量时,则至少一个类别包括多个样本内容,那么互动次数参考值则是该类别内的所有样本内容的历史互动次数的均值。
121.步骤8013:基于秩排序结果,确定至少一种内容类别各自被互动的权重,并基于至少一种内容类别各自被互动的权重,确定初始权重矩阵。
122.在本技术实施例中,基于秩排序数据作为初始权重矩阵,表示为:其中,表示第i种样本内容的初始权重,n表示样本内容类别或者数量。
123.步骤802:基于各个训练样本各自包括的样本对象的对象特征和样本内容的内容特征,确定第三评估矩阵,第三评估矩阵中的每个元素表示一个样本对象对一个样本内容的评估值。
124.在本技术实施例中,将图4对应的实施例部分训练概率预测模型最终得到的各个概率值乘以扩展常数,并按照等距方法划分评估值区间,并将评估值区间转化为rating data矩阵,即得到第三评估矩阵。具体过程可参见前述部分的介绍,在此不再过多赘述。
125.上述获得初始权重矩阵以及第三评估矩阵后,则可以基于初始权重矩阵以及第三评估矩阵,对内容推荐模型进行训练,获得已训练的内容推荐模型,具体参见下述的介绍。
126.步骤803:基于初始权重矩阵和第三评估矩阵,对内容推荐模型进行初始化。
127.在本技术实施例中,内容推荐模型的初始化包括如下:(1)以上述得到的初始权重矩阵初始化目标权重矩阵。
128.(2)通过对第三评估矩阵进行矩阵分解,可以获得表示对象的初始对象特征矩阵和表示内容的初始内容特征矩阵,以初始对象特征矩阵初始化对象评估矩阵,以及以初始内容特征矩阵初始化内容评估矩阵。
129.(3)基于第三评估矩阵包括的所有评估值,确定整体评估参考值。例如,通过第三评估矩阵计算得到矩阵中所有数据的均值,作为整体评估参考值。
130.(4)基于第三评估矩阵中各个样本对象各自的至少一个评估值,确定各个样本对象各自对应的对象评估参考值。例如,计算矩阵中每个样本对象对所有样本内容的平均评估值,作为对象评估参考值。
131.(5)基于第三评估矩阵中各个样本内容各自的至少一个评估值,确定各个样本内容各自对应的内容评估参考值。例如,计算矩阵中每种样本内容的评估值均值,作为内容评估参考值。
132.步骤804:基于初始化/更新后的内容推荐模型,获得第四评估矩阵,第四评估矩阵中的一个元素表示在相应样本内容当前被互动的权重约束下,一个样本对象对该样本内容的评估值。
133.本技术实施例中,初始化后的内容推荐模型则具备了上述对象评估矩阵、目标权重矩阵和内容评估矩阵,以及整体评估参考值、对象评估参考值和内容评估参考值的初始值,则可以将这些参数代入上述模型公式中,从而得到各个样本对象各自对各个样本内容的评估值,获得第四评估矩阵。
134.可以理解的是,在第一次迭代时,内容推荐模型的各个参数均为初始值,但在后续的迭代过程中,内容推荐模型的参数得以优化更新,从而在每一次迭代时所使用的参数为当前最新的参数值。例如,当第一次迭代之后,模型由于尚未达成收敛条件,则需要对内容推荐模型的各个参数进行更新,则在第二次迭代计算评估矩阵时,则需要以更新后的参数值代入进行计算。
135.本技术实施例中,上述的各个参数值可以选择性的进行更新,即可以设置某些参数值固定,则该参数值在初始化之后则会保持初始值,不会进行迭代更新,例如上述的整体评估参考值、对象评估参考值和内容评估参考值可以不进行更新。
136.步骤805:基于第三评估矩阵与第四评估矩阵之间的差异值,构建内容推荐模型对应的损失函数。
137.本技术实施例中,参见上述模型公式中的s.t.部分,即为本技术实施例构建的损失函数。如下式为基于对象侧构建的损失函数:如下式为基于内容侧构建的损失函数:如下式为基于内容权重构建的损失函数:如下式用于限制内容的权重总和为1:在本技术实施例中,在传统svd协同过滤推荐算法的基础上,对内容侧特征加入权重偏好约束,并重新构建带权重约束的损失函数,能够有效提升推荐效果,增强推荐模型的泛化能力。
138.步骤806:判断内容推荐模型是否满足收敛条件。
139.具体,收敛条件可以包括损失函数达到预设的阈值,或者迭代次数达到最大迭代次数。
140.步骤808:基于损失函数,采用梯度下降方法对内容推荐模型进行参数更新。
141.在本技术实施例中,利用更新后的内容推荐模型继续进行后续的训练过程,直至收敛,从而得到目标权重矩阵、对象评估矩阵和内容评估矩阵的最终值。
142.本技术实施例的模型训练方法基于损失函数最小原理,并通过梯度下降法,确定对象对内容最终的偏好权重,能够有效通过对象特征及内容特征确定对象对内容的偏好权重向量。
143.为了验证训练好的内容推荐模型的效果,本技术实施例对训练好的内容推荐模型使用测试样本进行测试。
144.具体的,在进行测试时,将上述训练过程最终得到的目标权重矩阵、对象评估矩阵和内容评估矩阵,以及整体评估参考值、对象评估参考值和内容评估参考值输入至内容推
荐模型中的如下公式中:进而重新得到预测的第五评估矩阵,并基于第三评估矩阵p与第五评估矩阵构建测评指标,以验证上述内容推荐模型的测评指标是否达到预设测评效果。
145.在一种可能的实施方式中,基于第三评估矩阵p与第五评估矩阵构建评估方差mse,表示如下:其中,n表示内容总数,m表示对象数,p
ij
表示第i个对象对第j种内容的评估值测试集数据, 表示第i个对象对第j种内容的评分预测值。
146.如果评估方差符合经验法则,则模型通过测试评估,即认为测评指标达到预设测评效果,则可以保存目标权重矩阵、对象评估矩阵和内容评估矩阵,以及整体评估参考值、对象评估参考值和内容评估参考值等参数用于后续的预测推荐过程。否则,则重复内容推荐模型的训练过程,或者重复概率预测模型训练过程和内容推荐模型的训练过程,直到模型达到评估标准为止。其中,经验法则是指模型测评用到的指标达到一定阈值,例如auc、查全率、查准率等,一般而言,查全率90%左右,查准率85%左右则可以应用于实际的推荐场景了。
147.参见图10所示,其为本技术实施例提供的一种内容推荐完整方法的流程示意图,在该方法流程中,具体以出行服务中优惠加油流失预警优惠券干预业务场景为例进行示出,优惠加油流失预警优惠券干预业务场景是指针对每月或周流失的推荐对象发放优惠券包,每个包包含不同面值的优惠券,以提升平台的对象黏性。该方法的具体实施流程如下:步骤1001:在样本数据构建阶段,采集样本数据构建样本数据集,并进行数据预处理操作。
148.在本技术实施例中,所针对的样本/待推荐内容则可以为优惠券。在具体实施时,可以使用t-1期的对象特征、内容特征、分类标签构建样本,或者使用t-1期的对象特征、内容特征和t期的分类标签构建样本,针对已构建的样本按一定比例随机切分为训练样本和测试样本,以及使用当期也就是t期的对象特征、内容特征、分类标签进行预测。
149.其中,对象特征主要包括对象年龄、地域等基础属性数据,活跃天数、活跃时长、活跃功能数量、注册时间距离当前时间天数间隔等活跃属性数据,资源转移属性数据,功能点击、领取优惠券属性数据等。内容特征为出行服务中各功能点的点击率、优惠券下载率、曝光量、点击量等特征数据。在优惠券下载场景中的分类标签可以包括点击且下载的样本作为正样本,分类标签为1,点击不下载的样本作为负样本,分类标签为0。
150.步骤1002:在概率预测模型训练阶段,基于样本数据集的训练样本对概率预测模型进行训练,基于样本数据集的测试样本对已训练的概率预测模型进行测评。
151.在具体实施时,通过训练样本中的稀疏型特征进行dnn模型(deep部分)训练,将
dnn模型训练出来得到的embadding特征结合训练样本中的稠密型特征和分类标签使用wide部分进行训练,通过梯度下降法得到模型权重。此外,针对训练好的模型使用测试样本进行测试,如果测评指标达到设定的测评效果,则保存模型和训练样本得到的概率值、测试样本得到的概率值。如果没有通过模型评估,则重复这一步直到模型达到设定的测评效果为止。
152.其中,稀疏型特征包括对象特征中的稀疏型特征和内容特征中的稀疏型特征,例如可以包括userid和itemid等id特征;稠密型特征也包括对象特征中的稠密型特征和内容特征中的稠密型特征,例如可以包括天数、资源数量和次数等特征。
153.步骤1003:将上一步得到的概率值乘以扩展常数,并按照等距方法划分评估值区间,并将评估值区间转化为rating data矩阵。
154.其中,rating data矩阵的行表示对象,列表示优惠券,行列交叉的rating data为对象对优惠券的评估值。
155.步骤1004:在优惠券权重初始化阶段,计算优惠券的初始权重矩阵。
156.输入每个对象对每种优惠券的使用次数数据,并通过聚类方法,计算每种优惠券的平均使用次数,对每种优惠券的平均使用次数计算秩排序,将每种优惠券的秩排序数据作为输入的初始偏好权重序列向量,表示如下:其中,表示对象对第i种优惠券的初始权重,n表示优惠券数量或者种类。
157.步骤1005:在内容推荐模型推荐阶段,基于rating data矩阵和初始权重矩阵,对构建的带权重的svd分解下协同过滤模型(即内容推荐模型)进行训练。
158.输入步骤1003中的rating data矩阵数据,输入步骤1004的初始权重矩阵,将rating data矩阵数据与初始权重矩阵代入带权重的svd分解下协同过滤模型当中,通过梯度下降法得到目标权重矩阵w、对象评估矩阵u、内容评估矩阵v。
159.需要说明的是,步骤1003中的rating data矩阵数据可以包括训练样本对应的评估值和测试样本的评估值,当然,也可以按照训练样本和测试样本分别构建rating data矩阵。
160.步骤1006:基于rating data矩阵,确定优惠券总体平均评估值、对象评评估值均值、优惠券评估值均值。
161.输入步骤1003中的rating data矩阵数据,计算矩阵所有数据的均值作为优惠券总体平均评估值μ,计算矩阵中对象对所有优惠券的平均评估值得到对象对象评估值估值均值bi,计算矩阵中每种优惠券的评分均值得到优惠券的优惠券评估值均值bj。
162.步骤1007:在内容推荐模型测试阶段,对带权重的svd分解下协同过滤模型进行测试,则通过测试,保存目标权重矩阵、对象评估矩阵、内容评估矩阵,以及总体平均评估值、对象对象评估值估值均值、优惠券评估值均值。
163.输入步骤1005得到的目标权重矩阵、对象评估矩阵、内容评估矩阵,输入步骤1006的总体平均评估值μ、对象评估值均值bi、优惠券评估值均值b
j ,代入模型如下公式:
从而得到预测值矩阵。进而,输入步骤1003处理好的测试rating data矩阵数据p,从而,得到评估方差。其中,n表示优惠券总数,m表示对象数,p
ij
表示第i个对象对第j种优惠券的评分测试集数据,表示第i个对象对第j种优惠券的评分预估值。如果评估方差符合经验法则,则模型通过测试评估,否则,重复上述步骤1002~步骤1007,直到模型达到评估标准为止。
164.步骤1008、采用带权重的svd分解下协同过滤模型进行优惠券推荐。
165.输入目标权重矩阵w、对象评估矩阵u、内容评估矩阵v,总体平均评估值μ、对象对象评估值估值均值bi、优惠券评估值均值bj。将使用t期特征数据预测得到的概率值乘以扩展常数,划分评估值区间,并将评估值区间转化为rating data矩阵,使用带权重的svd分解下协同过滤模型计算预测评估值。对rating data缺失数据进行协同过滤进行矩阵分解,并填充rating data矩阵中的缺失数据,得到对象对没有评估值的优惠券的预估评估值数据,从而对各个对象按照评估值排序进行推荐。
166.综上所述,本技术实施例中,在基于svd分解的协同过滤推荐算法的基础上,对内容侧特征加入偏好权重约束,并重新构建带权重约束的损失函数,从而能够有效提升推荐效果,增强推荐模型的泛化能力。例如,对于优惠加油推荐场景而言,能有效大量使用率低的优惠券权重,或者对于车联网的歌曲推荐场景而言,能有效降低歌单列表中大量收听率低的优惠券权重,有效提升模型计算效率。此外,初始权重采用秩排序方法确定,减少随机初始化权重给排序效果带来的不稳定性,有效提高推荐效果,以及本技术实施例本方案通过损失函数最小原理,并通过梯度下降法,确定最终的偏好权重,能够有效通过对象特征及内容特征确定对象对内容的偏好权重向量。
167.并且,值得说明的是,本技术实施例提供的方法具有非常好的可扩展性,首先,在模型集成方面,可以与lr、svm、fm、deepfm、deepcoss、卷积神经网络等模型进行集成,得到更好的推荐效果;其次,还可以用于各种分类算法的业务场景,例如:推荐以及其他与分类算法相关的业务场景。
168.请参见图11,基于同一发明构思,本技术实施例还提供了一种内容推荐装置110,该装置包括:第一评估单元1101,用于基于多个推荐对象各自的对象特征和多个待推荐内容各自的内容特征,确定第一评估矩阵,第一评估矩阵中的每个元素表示一个推荐对象对一个待推荐内容的评估值;第二评估单元1102,用于将第一评估矩阵输入至已训练的内容推荐模型,获得内容推荐模型输出的第二评估矩阵;内容推荐模型用于在目标权重矩阵的约束下,基于协同过滤方法预测各个推荐对象对待推荐内容的评估值,目标权重矩阵中的每个元素表示相应待推荐内容被互动的权重;推荐单元1103,用于根据第二评估矩阵,向多个推荐对象分别推荐至少一个待推
荐内容。
169.可选的,该装置还包括训练单元1104,用于:基于各个训练样本包括的样本内容各自对应的历史互动次数集合,确定初始权重矩阵,每个历史互动次数集合包括至少一个样本对象对相应样本内容进行互动的次数;基于各个训练样本各自包括的样本对象的对象特征和样本内容的内容特征,确定第三评估矩阵,第三评估矩阵中的每个元素表示一个样本对象对一个样本内容的评估值;基于初始权重矩阵以及第三评估矩阵,对内容推荐模型进行训练,获得已训练的内容推荐模型。
170.可选的,训练单元1104还用于:基于各个历史互动次数集合,对各个训练样本包括的样本内容进行聚类,获得至少一种内容类别,每种内容类别包括至少一个样本内容;基于至少一种内容类别各自对应的互动次数参考值按秩排序,每个互动次数参考值是根据相应内容类别包括的样本内容的历史互动次数集合确定的;基于秩排序结果,确定至少一种内容类别各自被互动的权重,并基于至少一种内容类别各自被互动的权重,确定初始权重矩阵。
171.可选的,训练单元1104,具体用于:基于初始权重矩阵和第三评估矩阵,对内容推荐模型进行初始化;基于初始化后的内容推荐模型,获得第四评估矩阵,第四评估矩阵中的一个元素表示在相应样本内容当前被互动的权重约束下,一个样本对象对该样本内容的评估值;基于第三评估矩阵与第四评估矩阵之间的差异值,构建内容推荐模型对应的损失函数;基于损失函数,采用梯度下降方法对内容推荐模型进行参数更新。
172.可选的,内容推荐模型的参数包括目标权重矩阵、对象评估矩阵和内容评估矩阵;则训练单元1104,具体用于:以初始权重矩阵初始化目标权重矩阵;对第三评估矩阵进行矩阵分解,获得初始对象特征矩阵和初始内容特征矩阵;以初始对象特征矩阵初始化对象评估矩阵,以及以初始内容特征矩阵初始化内容评估矩阵;基于初始化后的内容推荐模型,获得第四评估矩阵,包括:基于对象评估矩阵、内容评估矩阵以及目标权重矩阵,确定各个样本对象分别对各个样本内容的评估值,获得第四评估矩阵。
173.可选的,训练单元1104,具体用于:基于第三评估矩阵包括的所有评估值,确定整体评估参考值;基于第三评估矩阵中各个样本对象各自的至少一个评估值,确定各个样本对象各自对应的对象评估参考值;基于第三评估矩阵中各个样本内容各自的至少一个评估值,确定各个样本内容各自对应的内容评估参考值;基于对象评估矩阵、内容评估矩阵以及目标权重矩阵、整体评估参考值、对象评估参考值和内容评估参考值,确定各个样本对象分别对各个样本内容的评估值,获得第四评
估矩阵。
174.可选的,第一评估单元1101,具体用于:基于概率预测模型对多个推荐对象的对象特征、多个待推荐内容的内容特征进行预测,得到第一预测信息,第一预测信息用于指示多个推荐对象对各个待推荐内容进行互动操作的概率;根据第一预测信息,确定第一评估矩阵。
175.可选的,训练单元1104,具体用于:对各个训练样本包括的样本对象各自的稀疏型特征分别进行特征提取,获得相应的对象特征向量,以及对各个训练样本包括的样本内容各自的稀疏型特征分别进行特征提取,获得相应的内容特征向量;基于各个样本对象各自的对象特征向量和稠密型特征以及各个样本内容各自的内容特征向量和稠密型特征,预测各个训练样本对应的预测概率值;基于各个训练样本包括的互动概率标签和相应的预测概率值,构建概率预测模型对应的损失函数,并基于损失函数,对概率预测模型进行参数更新。
176.可选的,第一评估单元1101,具体用于:基于第一预测信息与设定的扩展常数值,获得第二预测信息,第二预测信息用于指示多个推荐对象对各个待推荐内容的评估值;基于第二预测信息进行评估值区间划分,获得多个评估值区间,每个评估值区间对应于一个评估值等级;基于多个评估值区间进行矩阵转化处理,获得第一评估矩阵。
177.通过上述装置,可以在基于svd分解的协同过滤推荐算法的基础上,对内容侧特征加入偏好权重约束,并重新构建带权重约束的损失函数,从而能够有效提升推荐效果,增强推荐模型的泛化能力。例如,对于优惠加油推荐场景而言,能有效大量使用率低的优惠券权重,或者对于车联网的歌曲推荐场景而言,能有效降低歌单列表中大量收听率低的优惠券权重,有效提升模型计算效率。此外,初始权重采用秩排序方法确定,减少随机初始化权重给排序效果带来的不稳定性,有效提高推荐效果,以及本技术实施例本方案通过损失函数最小原理,并通过梯度下降法,确定最终的偏好权重,能够有效通过对象特征及内容特征确定对象对内容的偏好权重向量,提升准确性。
178.为了描述的方便,以上各部分按照功能划分为各单元模块(或模块)分别描述。当然,在实施本技术时可以把各单元(或模块)的功能在同一个或多个软件或硬件中实现。
179.所属技术领域的技术人员能够理解,本技术的各个方面可以实现为系统、方法或程序产品。因此,本技术的各个方面可以具体实现为以下形式,即:完全的硬件实施方式、完全的软件实施方式(包括固件、微代码等),或硬件和软件方面结合的实施方式,这里可以统称为“电路”、“模块”或“系统”。
180.该装置可以用于执行本技术各实施例中所示的方法,因此,对于该装置的各功能模块所能够实现的功能等可参考前述实施例的描述,不多赘述。
181.请参见图12,基于同一技术构思,本技术实施例还提供了一种计算机设备。在一种实施例中,该计算机设备可以为图1所示的服务器,该计算机设备如图12所示,包括存储器1201,通讯模块1203以及一个或多个处理器1202。
182.存储器1201,用于存储处理器1202执行的计算机程序。存储器1201可主要包括存储程序区和存储数据区,其中,存储程序区可存储操作系统,以及运行即时通讯功能所需的程序等;存储数据区可存储各种即时通讯信息和操作指令集等。
183.存储器1201可以是易失性存储器(volatile memory),例如随机存取存储器(random-access memory,ram);存储器1201也可以是非易失性存储器(non-volatile memory),例如只读存储器,快闪存储器(flash memory),硬盘(hard disk drive,hdd)或固态硬盘(solid-state drive,ssd);或者存储器1201是能够用于携带或存储具有指令或数据结构形式的期望的程序代码并能够由计算机存取的任何其他介质,但不限于此。存储器1201可以是上述存储器的组合。
184.处理器1202,可以包括一个或多个中央处理单元(central processing unit, cpu)或者为数字处理单元等等。处理器1202,用于调用存储器1201中存储的计算机程序时实现上述内容推荐方法。
185.通讯模块1203用于与终端设备和其他服务器进行通信。
186.本技术实施例中不限定上述存储器1201、通讯模块1203和处理器1202之间的具体连接介质。本技术实施例在图12中以存储器1201和处理器1202之间通过总线1204连接,总线1204在图12中以粗线描述,其它部件之间的连接方式,仅是进行示意性说明,并不引以为限。总线1204可以分为地址总线、数据总线、控制总线等。为便于描述,图12中仅用一条粗线描述,但并不描述仅有一根总线或一种类型的总线。
187.存储器1201中存储有计算机存储介质,计算机存储介质中存储有计算机可执行指令,计算机可执行指令用于实现本技术实施例的内容推荐方法。处理器1202用于执行上述各实施例的内容推荐方法。
188.在另一种实施例中,计算机设备也可以是其他计算机设备,如图1所示的终端设备。在该实施例中,计算机设备的结构可以如图13所示,包括:通信组件1310、存储器1320、显示单元1330、摄像头1340、传感器1350、音频电路1360、蓝牙模块1370、处理器1380等部件。
189.通信组件1310用于与服务器进行通信。在一些实施例中,可以包括电路无线保真(wireless fidelity,wifi)模块,wifi模块属于短距离无线传输技术,计算机设备通过wifi模块可以帮助收发信息。
190.存储器1320可用于存储软件程序及数据。处理器1380通过运行存储在存储器1320的软件程序或数据,从而执行终端设备的各种功能以及数据处理。存储器1320可以包括高速随机存取存储器,还可以包括非易失性存储器,例如至少一个磁盘存储器件、闪存器件、或其他易失性固态存储器件。存储器1320存储有使得终端设备能运行的操作系统。本技术中存储器1320可以存储操作系统及各种应用程序,还可以存储执行本技术实施例内容推荐方法的代码。
191.显示单元1330还可用于显示由用户输入的信息或提供给用户的信息以及终端设备的各种菜单的图形用户界面(graphical user interface,gui)。具体地,显示单元1330可以包括设置在终端设备正面的显示屏1332。其中,显示屏1332可以采用液晶显示器、发光二极管等形式来配置。显示单元1330可以用于显示本技术实施例中的各种内容推荐页面,例如出行服务页面、优惠加油券推荐页面。
192.显示单元1330还可用于接收输入的数字或字符信息,产生与终端设备的用户设置以及功能控制有关的信号输入,具体地,显示单元1330可以包括设置在终端设备正面的触摸屏1331,可收集用户在其上或附近的触摸操作,例如点击按钮,拖动滚动框等。
193.其中,触摸屏1331可以覆盖在显示屏1332之上,也可以将触摸屏1331与显示屏1332集成而实现终端设备的输入和输出功能,集成后可以简称触摸显示屏。本技术中显示单元1330可以显示应用程序以及对应的操作步骤。
194.摄像头1340可用于捕获静态图像,用户可以将摄像头1340拍摄的图像通过应用发布评论。摄像头1340可以是一个,也可以是多个。物体通过镜头生成光学图像投射到感光元件。感光元件可以是电荷耦合器件(charge coupled device,ccd)或互补金属氧化物半导体(complementary metal-oxide-semiconductor,cmos)光电晶体管。感光元件把光信号转换成电信号,之后将电信号传递给处理器1380转换成数字图像信号。
195.终端设备还可以包括至少一种传感器1350,比如加速度传感器1351、距离传感器1352、指纹传感器1353、温度传感器1354。终端设备还可配置有陀螺仪、气压计、湿度计、温度计、红外线传感器、光传感器、运动传感器等其他传感器。
196.音频电路1360、扬声器1361、传声器1362可提供用户与终端设备之间的音频接口。音频电路1360可将接收到的音频数据转换后的电信号,传输到扬声器1361,由扬声器1361转换为声音信号输出。终端设备还可配置音量按钮,用于调节声音信号的音量。另一方面,传声器1362将收集的声音信号转换为电信号,由音频电路1360接收后转换为音频数据,再将音频数据输出至通信组件1310以发送给比如另一终端设备,或者将音频数据输出至存储器1320以便进一步处理。
197.蓝牙模块1370用于通过蓝牙协议来与其他具有蓝牙模块的蓝牙设备进行信息交互。例如,终端设备可以通过蓝牙模块1370与同样具备蓝牙模块的可穿戴计算机设备(例如智能手表)建立蓝牙连接,从而进行数据交互。
198.处理器1380是终端设备的控制中心,利用各种接口和线路连接整个终端的各个部分,通过运行或执行存储在存储器1320内的软件程序,以及调用存储在存储器1320内的数据,执行终端设备的各种功能和处理数据。在一些实施例中,处理器1380可包括一个或多个处理单元;处理器1380还可以集成应用处理器和基带处理器,其中,应用处理器主要处理操作系统、用户界面和应用程序等,基带处理器主要处理无线通信。可以理解的是,上述基带处理器也可以不集成到处理器1380中。本技术中处理器1380可以运行操作系统、应用程序、用户界面显示及触控响应,以及本技术实施例的内容推荐方法。另外,处理器1380与显示单元1330耦接。
199.在一些可能的实施方式中,本技术提供的内容推荐方法的各个方面还可以实现为一种程序产品的形式,其包括程序代码,当程序产品在计算机设备上运行时,程序代码用于使计算机设备执行本说明书上述描述的根据本技术各种示例性实施方式的内容推荐方法中的步骤,例如,计算机设备可以执行各实施例的步骤。
200.程序产品可以采用一个或多个可读介质的任意组合。可读介质可以是可读信号介质或者可读存储介质。可读存储介质例如可以是但不限于电、磁、光、电磁、红外线、或半导体的系统、装置或器件,或者任意以上的组合。可读存储介质的更具体的例子(非穷举的列表)包括:具有一个或多个导线的电连接、便携式盘、硬盘、随机存取存储器(ram)、只读存储
器(rom)、可擦式可编程只读存储器(eprom或闪存)、光纤、便携式紧凑盘只读存储器(cd-rom)、光存储器件、磁存储器件、或者上述的任意合适的组合。
201.本技术的实施方式的程序产品可以采用便携式紧凑盘只读存储器(cd-rom)并包括程序代码,并可以在计算装置上运行。然而,本技术的程序产品不限于此,在本技术件中,可读存储介质可以是任何包含或存储程序的有形介质,该程序可以被命令执行系统、装置或者器件使用或者与其结合使用。
202.可读信号介质可以包括在基带中或者作为载波一部分传播的数据信号,其中承载了可读程序代码。这种传播的数据信号可以采用多种形式,包括但不限于电磁信号、光信号或上述的任意合适的组合。可读信号介质还可以是可读存储介质以外的任何可读介质,该可读介质可以发送、传播或者传输用于由命令执行系统、装置或者器件使用或者与其结合使用的程序。
203.可读介质上包含的程序代码可以用任何适当的介质传输,包括但不限于无线、有线、光缆、rf等等,或者上述的任意合适的组合。
204.可以以一种或多种程序设计语言的任意组合来编写用于执行本技术操作的程序代码,程序设计语言包括面向对象的程序设计语言—诸如java、c++等,还包括常规的过程式程序设计语言—诸如“c”语言或类似的程序设计语言。程序代码可以完全地在用户计算装置上执行、部分地在用户设备上执行、作为一个独立的软件包执行、部分在用户计算装置上部分在远程计算装置上执行、或者完全在远程计算装置或服务器上执行。在涉及远程计算装置的情形中,远程计算装置可以通过任意种类的网络包括局域网(lan)或广域网(wan)连接到用户计算装置,或者,可以连接到外部计算装置(例如利用因特网服务提供商来通过因特网连接)。
205.应当注意,尽管在上文详细描述中提及了装置的若干单元或子单元,但是这种划分仅仅是示例性的并非强制性的。实际上,根据本技术的实施方式,上文描述的两个或更多单元的特征和功能可以在一个单元中具体化。反之,上文描述的一个单元的特征和功能可以进一步划分为由多个单元来具体化。
206.此外,尽管在附图中以特定顺序描述了本技术方法的操作,但是,这并非要求或者暗示必须按照该特定顺序来执行这些操作,或是必须执行全部所示的操作才能实现期望的结果。附加地或备选地,可以省略某些步骤,将多个步骤合并为一个步骤执行,和/或将一个步骤分解为多个步骤执行。
207.本领域内的技术人员应明白,本技术的实施例可提供为方法、系统、或计算机程序产品。因此,本技术可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本技术可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。
208.尽管已描述了本技术的优选实施例,但本领域内的技术人员一旦得知了基本创造性概念,则可对这些实施例做出另外的变更和修改。所以,所附权利要求意欲解释为包括优选实施例以及落入本技术范围的所有变更和修改。
209.显然,本领域的技术人员可以对本技术进行各种改动和变型而不脱离本技术的精神和范围。这样,倘若本技术的这些修改和变型属于本技术权利要求及其等同技术的范围
之内,则本技术也意图包含这些改动和变型在内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1