基于多尺度信息融合的海面小目标检测方法、电子设备及计算机可读介质
1.本发明涉及人工智能和计算机视觉领域,具体涉及一种基于多尺度信息融合的海面小目标检测方法、电子设备及计算机可读介质。
背景技术:
2.目标检测是计算机视觉的核心任务之一,也是其他复杂视觉任务的基础,旨在预测每个感兴趣对象的一组边界框和类别标签。近几年,随着技术的不断成熟,主流目标检测算法对于中、大目标的检测已经取得了一个非常好的效果,但是小目标的检测依旧是限制目标检测算法精度提升的难点。
3.目前不同场景对于小目标的定义各不相同,主要采用两种标准:1)基于相对尺度的定义。这种定义标准是从目标和图像的相对大小出发,如目标的宽高与图像的宽高比例小于0.1,或者目标边界框的面积与图像总面积的比值平方根小于0.03等。2)基于绝对尺度的定义。这种定义标准是从目标的绝对像素大小出发。比较通用的定义来自公共数据集ms coco,其将小目标定义为分辨率小于像素的目标。而在航天图像数据集dota上,对小目标的定义进一步缩小到了10至50像素。
4.小目标检测的难点存在多个方面,如可用特征少,样本不均衡,目标聚集,网络能力差等问题。针对这些难点,目前方法主要从网络结构出发,通过提取多尺度特征,引入注意力机制等加强对小目标的检测。但是一方面这些方法依旧无法高效地利用包含更多小目标信息的低层信息;另一方面目前的公共数据集中存在一个重要缺陷,即小目标样本稀少。现有的数据集大多针对大/中尺度的目标,而对小目标关注较少。在公共数据集ms coco中,虽然小目标的占比达到31.62%,但是小目标分布极度不均匀,在整个样本集中,存在小目标的图像占比极小,这对于小目标的检测是非常不利。而在一些特定领域,例如海面目标检测,小目标又因为其分辨率低而存在标注困难,边界框标注不准确等问题。因此,开展利用仿真数据增强的、多尺度信息融合的海面小目标检测研究,具有非常重要的现实意义。
5.在海面小目标(船只)检测领域中,小目标的仿真数据增强主要存在以下两个问题:(1)如何选择小目标的嵌入位置;(2)如何将仿真小目标无缝融入海面场景之中。一方面海平面上的波浪起伏会导致船只的上下起伏,从而使嵌入位置的选择变得困难。另一方面,目前已有的无缝融合技术如泊松融合技术并不适用于小目标并且无法将目标融入前景中,如大雾,阴雨等天气场景。
技术实现要素:
6.为了解决上述现有技术中存在的问题,提高海面小目标检测的准确度,本发明提供一种基于多尺度信息融合的海面小目标检测方法、电子设备及计算机可读介质,本发明致力于海面小目标如船只等仿真数据的嵌入轨迹规划和无缝融合方式,同时在神经网络中结合多尺度与注意力机制提高海面小目标检测的准确率,研究和探索出一种适用于海面小
目标的高精度检测方法,通过构造海面小目标仿真数据集并进行数据增强,训练深度神经网络得到检测模型。
7.技术方案如下:
8.一种基于多尺度信息融合的海面小目标检测方法,步骤如下:
9.步骤s1,构建海面小目标仿真数据集:利用嵌入轨迹规划方法和无缝融合方法,使用所述数据集将船只渲染到场景中,从而根据嵌入位置标注得到准确的边界框和类别信息;
10.步骤s2,构建深度学习网络模型,所述模型包括主干网络、fpn网络、自上而下的transformer网络;所述主干网络用于特征提取,抽取所述主干网络的特征层并构建fpn网络用于多尺度特征融合,并且嵌入transformer模块,利用自上而下的解码方式使网络进一步加强关注小目标区域;其中使用可变形卷积实现transformer模块的注意力机制;
11.步骤s3,利用步骤s1构建的小目标仿真数据集对步骤s2构建的深度学习模型进行训练;在训练过程中,通过transformer模块解码和检测出海面小目标的位置和类别信息;
12.步骤s4,利用步骤s3训练好的模型进行其他场景下的海面小目标检测。
13.进一步地,所述步骤s1具体为:
14.步骤s1-1,收集m幅真实的不同种类的船只图像和n个不同天气状况下的海面视频;
15.步骤s1-2,海平面嵌入轨迹规划:针对每个海面视频,每间隔1s抽取其中一个视频帧,针对每个视频帧的海平面等间隔采集多个采样点,并根据视频海平面的起伏程度选择t次多项式,利用t次多项式曲线拟合的方式拟合完整海平面,该多项式含有t+1个参数;在得到整个海面视频的所有t次多项式拟合曲线后,针对多项式的每一项系数以时间为横坐标,系数为纵坐标同样使用多项式进行曲线拟合;总共得到t+1个参数拟合曲线;通过上述步骤得到系数随时间变化的t次多项式海面拟合曲线;
16.步骤s1-3,针对每个海面场景视频,给定嵌入船只的初始位置和移动速度;对每个视频帧,根据时间标签计算船只在每个海平面视频帧图像中的横坐标,并利用当前视频帧对应的时间求得t次多项式的当前系数,得到当前视频帧的海平面拟合曲线,进而根据横坐标计算出纵坐标,从而得到每帧视频图像的船只嵌入位置;
17.步骤s1-4,船只与海面的无缝融合:针对嵌入的图片,利用高斯滤波对前景船只图片进行模糊处理,之后将船只缩小,将得到的模糊小尺寸图片嵌入到步骤s1-3生成的位置,并在嵌入后再次使用高斯滤波对边缘进行平滑;
18.步骤s1-5,针对每个视频帧,以步骤s1-3中得到的每个视频帧的嵌入位置为中心,将步骤s1-4中得到的结果图片逐帧嵌入到海面场景图像;利用前景目标图像插入的位置和缩放后的大小构建目标检测的标注框。
19.步骤s1-6,针对每个海面视频,重复步骤s1-2到步骤s1-5,从而构建完整的海面小目标数据集。
20.进一步地,所述构建深度学习网络为一个多尺度信息融合的端到端网络;所述步骤s2具体为:
21.步骤s2-1,通过所述主干网络对图片进行特征提取;
22.步骤s2-2,将得到的多个不同尺度feature map输入fpn网络进行多尺度信息融
合;
23.步骤s2-3,将经过融合的多层feature map输入级联transformer模块进行反向解码,得到高精度的类别预测和边界框预测结果;所述transformer模块利用可变形卷积形成注意力机制,其中,transformer模块的decoder利用不同尺度特征图实现跨层注意力,同时利用自上而下的方式进行解码。
24.进一步地,所述步骤s2中主干网络使用resnet-50为基准网络。
25.进一步地,在步骤s2-3中,将得到的不同尺度特征输入分类分支,使用交叉熵损失作为分类损失:
[0026][0027]
其中,l
cls
(x,c)表示分类学习损失,i表示预测框序号,pos表示预测为正样本,n表示预测框的总个数,p表示类别,j表示真实框序号,表示第i个预测框与第j个真实框匹配,取值为{0,1},表示第i个预测框关于类别p的概率(通过使用softmax函数求出),neg表示预测为负样本(即不与任何一个真实框匹配,匹配背景),表示第i个预测框关于背景类的置信度(0代表背景类),表示预测类别为p的置信度。
[0028]
进一步地,在步骤s2-3中,将得到的不同尺度特征输入边界框预测分支,使用smoothl1损失作为边界框回归损失:
[0029][0030][0031][0032][0033][0034]
其中,l
loc
(x,l,g)表示边界框预测损失,边界框中心为(cx,cy),宽高分别为w和h,m表示表示边界框的每个参数,k表示类别,代表第i个预测框与第j个真实框关于类别k是否匹配,为预测框,为真实框,表示第j个真实框中心点的横坐标与第i个预测框初始锚框中心的横坐标的相对偏移量,表示第j个真实框中心点的横坐标,表示第i个预测框初始锚框中心的横坐标,表示第j个真实框中心点的横坐标与第i个预测框初始锚框中心的纵坐标的相对偏移量,表示第j个真实框中心点的纵坐标,表示第i个预测框初始锚框的纵坐标,表示第j个真实框的宽与第i个预测框初始锚框的宽的相对大小,表示第j个真实框的宽,表示第i个预测框初始锚框的宽,表示第j个真实框的
高与第i个预测框初始锚框的高的相对大小,表示第j个真实框的高,表示第i个预测框初始锚框的高。
[0035]
进一步地,以分类学习损失l
cls
(x,c)和/或边界框预测损失l
loc
(x,l,g)为目标,使用反向传播算法对步骤s2中网络结构进行训练。
[0036]
进一步地,利用步骤s3训练好的深度学习模型,将真实的海面图片输入网络得到分类置信度和边界框预测,根据置信度nms选取最终预测边界结果。
[0037]
本发明还包括一种电子设备,其特征在于,包括:
[0038]
一个或多个处理器;
[0039]
存储装置,用于存储一个或多个程序;
[0040]
当一个或多个程序被所述一个或多个处理器执行,使得所述一个或多个处理器实现如上列任一所述的方法。
[0041]
本发明还包括一种计算机可读介质,其上存储有计算机程序,所述程序被处理器执行时实现如上列任一所述的方法。
[0042]
本发明的有益效果:
[0043]
1.本发明创新性使用自上而下的transformer解码策略,对fpn中自上而下的不同尺度特征图采用可变形卷积的方式实现encoder中的自注意力机制,同时从高层的较小特征层开始通过在相邻两个特征层之间引入transformer模块进行解码预测边界框,自上而下通过不断引入包含更多小目标信息的低层特征来不断进行边界框修正,进而提高小目标检测准确率。
[0044]
2.本发明创新性使用时空动态变化的仿真方式规划小目标在海面的嵌入位置。同时通过对小目标进行渲染,提高了海面小目标嵌入的真实性。通过使用仿真数据进行数据增强,使图片中的小目标分布均衡且真实。利用构建的仿真数据集进行训练,提高了小目标检测准确率。
附图说明
[0045]
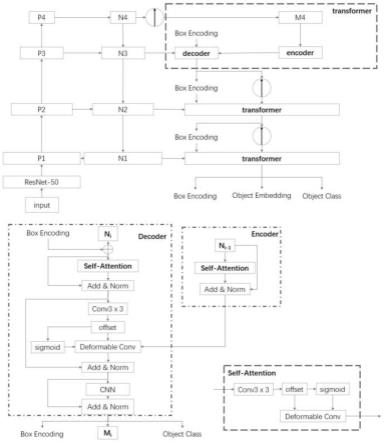
图1为本发明实施例的深度学习神经网络总体架构图;
[0046]
图2为本发明的系统流程图。
具体实施方式
[0047]
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。下面结合附图1-2对基于多尺度信息融合的海面小目标检测方法、电子设备及计算机可读介质做进一步说明。
[0048]
实施例1
[0049]
一种多尺度信息融合的海面小目标检测方法,包含以下步骤:
[0050]
步骤s1,构建海面小目标仿真数据集。所述数据集主要利用嵌入轨迹规划和无缝融合方式将船只渲染到场景中,从而根据嵌入位置标注得到准确的边界框和类别信息;
[0051]
步骤s2,构建深度学习网络模型,该模型包括主干网络、fpn网络、自上而下的transformer网络;其中,主干网络用于特征提取。为了尽可能保留小目标的特征,抽取主干
网络的特征层并构建fpn用于多尺度特征融合,并且嵌入transformer模块利用自上而下的解码方式使网络更加关注小目标区域。其中使用可变形卷积实现transformer模块的注意力机制;
[0052]
步骤s3,利用s1构建的小目标数据集对步骤s2构建的深度学习模型进行训练;在训练过程中,transformer模块能够很好的解码和检测出海面小目标的位置和类别信息。
[0053]
步骤s4,利用步骤s3训练好的模型进行其他场景下的海面小目标检测。
[0054]
所述步骤s1具体为:
[0055]
步骤s1-1,收集m幅真实的不同种类的船只图像和n个不同天气状况下的海面视频;
[0056]
步骤s1-2,海平面嵌入轨迹规划。针对每个海面视频,每间隔1s抽取其中一个视频帧,针对每个视频帧的海平面等间隔采集多个采样点,并根据视频海平面的起伏程度选择t次多项式,利用t次多项式曲线拟合的方式拟合完整海平面,该多项式含有t+1个参数。在得到整个海面视频的所有t次多项式拟合曲线后,针对多项式的每一项系数以时间为横坐标,系数为纵坐标同样使用多项式进行曲线拟合;总共得到t+1个参数拟合曲线。因为海面的时空连续性,通过这种方式我们就可以得到系数随时间变化的t次多项式海面拟合曲线。除多项式逼近外,对于不同海面场景我们可以选择不同的曲线拟合类型,如指数逼近,傅里叶逼近等。我们称之为时空动态变化的海平面轨迹规划;
[0057]
步骤s1-3,针对每个海面场景视频,我们给定嵌入船只的初始位置和移动速度。对每个视频帧,根据时间标签计算船只在每个海平面视频帧图像中的横坐标,并利用当前视频帧对应的时间求得t次多项式的当前系数,得到当前视频帧的海平面拟合曲线,进而根据横坐标计算出纵坐标,从而得到每帧视频图像的船只嵌入位置;
[0058]
步骤s1-4,船只与海面的无缝融合。针对嵌入的图片,我们利用高斯滤波对前景船只图片进行模糊处理,之后将船只缩小到合适的大小,如50像素,将得到的模糊小尺寸图片嵌入到s1-3生成的位置,并在嵌入后再次使用高斯滤波对边缘进行平滑。
[0059]
步骤s1-5,针对每个视频帧,以s1-3中得到的每个视频帧的嵌入位置为中心,将s1-4中得到的结果图片逐帧嵌入到海面场景图像。利用前景目标图像插入的位置和缩放后的大小构建目标检测的标注框。
[0060]
步骤s1-6,针对每个海面视频,重复步骤s1-2到s1-5,从而构建完整的海面小目标数据集。我们称这种方法为时空动态变化的数据仿真方法。
[0061]
步骤s1,构造的数据集是仿真的海面小目标数据集。
[0062]
所述步骤s2具体为:
[0063]
所述构建深度学习网络为一个多尺度信息融合的端到端网络;所述主干网络输入数据为图片进行特征提取。将得到的多个不同尺度feature map输入fpn网络进行多尺度信息融合。然后将经过融合的多层feature map输入级联transformer模块进行反向解码,最终得到高精度的类别预测和边界框预测结果;所述transformer模块利用可变形卷积形成注意力机制,其中,transformer模块的decoder利用不同尺度特征图实现跨层注意力,同时利用自上而下的方式进行解码,使网络不断聚焦于小目标区域,细化预测结果,提高了小目标的检测准确度;
[0064]
步骤s2-1,所述主干网络输入数据为图片进行特征提取。将得到的多个不同尺度
feature map。
[0065]
步骤s2-2,将得到的多个不同尺度feature map输入fpn网络进行多尺度信息融合。
[0066]
步骤s2-3,将经过融合的多层feature map输入级联transformer模块进行反向解码,最终得到高精度的类别预测和边界框预测结果;所述transformer模块利用可变形卷积形成注意力机制,其中,transformer模块的decoder利用不同尺度特征图实现跨层注意力,同时利用自上而下的方式进行解码,使网络不断聚焦于小目标区域,细化预测结果,提高了小目标的检测准确度;
[0067]
实施例2
[0068]
现有的小目标检测方法,应用于海面小目标的检测时,由于数据样本少,数据标注困难且不准确,检测准确率较低。本发明提出时空动态变化的仿真方式构建标注准确的仿真数据集,并利用多尺度信息融合和transformer解码的方式提高海面小目标的检测准确率。本方法利用主干网络进行特征提取,利用fpn网络提取多尺度信息,结合注意力机制进行语义增强,并利用transformer进行自上而下的逆向解码,提高了海面小目标的检测准确率。
[0069]
本发明提供的方法设计了一种小目标仿真数据集的构建方式,和一种新型的结合注意力机制的多尺度信息融合的深度学习网络模型,其总体结构参见图1。其具体实施例包含以下步骤:
[0070]
步骤s1,构建海面小目标仿真数据集。所述数据集主要利用嵌入轨迹规划和无缝融合方式将船只渲染到场景中,从而根据嵌入位置标注得到准确的边界框和类别信息。具体实施过程说明如下:
[0071]
步骤s1-1,收集20幅真实的不同种类的船只图像和15个不同天气状况下的海面视频;
[0072]
步骤s1-2,海平面嵌入轨迹规划。针对每个海面视频,每间隔1s抽取其中一个视频帧,针对每个视频帧的海平面等间隔采集10个采样点,并根据视频海平面的起伏程度最终选择10次多项式,利用10次多项式曲线拟合的方式拟合完整海平面,该多项式含有11个参数。在得到整个海面视频的所有10次多项式拟合曲线后,针对多项式的每一项系数以时间为横坐标,系数为纵坐标同样使用多项式进行曲线拟合;总共得到11个参数拟合曲线。因为海面的时空连续性,通过这种方式我们就可以得到系数随时间变化的10次多项式海面拟合曲线。
[0073]
步骤s1-3,针对每个海面场景视频,我们给定嵌入船只的初始位置和移动速度。对每个视频帧,根据时间标签计算船只在每个海平面视频帧图像中的横坐标,并利用当前视频帧对应的时间求得10次多项式的当前系数,得到当前视频帧的海平面拟合曲线,进而根据横坐标计算出纵坐标,从而得到每帧视频图像的船只嵌入位置;
[0074]
步骤s1-4,船只与海面的无缝融合。针对嵌入的图片,我们利用高斯滤波对前景船只图片进行模糊处理,之后将船只缩小到合适的大小,如50像素,将得到的模糊小尺寸图片嵌入到s1-3生成的位置,并在嵌入后再次使用高斯滤波对边缘进行平滑。
[0075]
步骤s1-5,针对每个视频帧,以s1-3中得到的每个视频帧的嵌入位置为中心,将s1-4中得到的结果图片逐帧嵌入到海面场景图像。利用前景目标图像插入的位置和缩放后
的大小构建目标检测的标注框。
[0076]
步骤s1-6,针对每个海面视频,重复步骤s1-2到s1-5,从而构建完整的海面小目标数据集,一个得到36段仿真视频,共计21278张图像。
[0077]
步骤s2,构建深度学习网络模型,该模型包括主干网络、fpn网络、自上而下的transformer网络;其中,主干网络用于特征提取。为了尽可能保留小目标的特征,抽取主干网络的特征层并构建fpn用于多尺度特征融合,并且嵌入transformer模块利用自上而下的解码方式使网络更加关注小目标区域。其中transformer模块的注意力机制我们使用可变形卷积实现。具体的步骤为:
[0078]
s2-1,将一个宽高为的包含小目标的图片输入主干网络,经过主干网络进行特征提取,并抽取多张不同尺度特征层得到feature map。
[0079]
s2-2,将上一步得到的feature map输入fpn网络进行多尺度信息融合,并从包含更多语义信息的高层特征层开始利用fpn中相邻的特征层输入到对应transformer模块中,自上而下的进行解码。
[0080]
s2-3,transformer模块中encoder和decoder分别需要输入一个特征层。将低层特征层(该特征层更大,包含更多的位置信息,更有利于小目标的检测)输入解码器进行边界框的解码预测。为使encoder输出结果大小和decoder一致,我们将高层特征层上采样后输入编码器进行编码。在利用可变形卷积形成注意力时,首先利用卷积得到每个特征点关注的其他位置,即注意力区域。对这些位置与当前位置使用乘法求和并利用sigmoid得到置信度,从而实现每个特征层的自注意力机制。encoder-decoder之间的注意力机制相似,不同点在于我们利用decoder自注意力后的结果进行卷积得到可变形卷积的offset,并将该offset作用于encoder的输出特征,进行跨层的可变形卷积,实现两者之间的跨层注意力机制。为了保持特征的平移不变性,我们将fnn替换成cnn,并预测边界框和类别。将decoder输出的特征层上采样后作为下一层encoder的输入。我们利用这种自上而下回溯解码的方式,不断利用包含更多小目标信息的低层特征层来修正边界框预测的结果,同时使用自注意力和跨层注意力机制增强语义信息,使边界框预测的结果更加精确。
[0081]
进一步的,所述步骤s2中主干网络使用resnet-50为基准网络;
[0082]
步骤s3,利用s1构建的小目标仿真数据集对步骤s2构建的深度学习模型进行训练;
[0083]
s3-1,在步骤s2-3中,将得到的不同尺度特征输入分类分支,使用交叉熵损失作为分类损失:
[0084][0085]
其中,l
cls
(x,c)表示分类学习损失,i表示预测框序号,pos表示预测为正样本,n表示预测框的总个数,p表示类别,j表示真实框序号,表示第i个预测框与第j个真实框匹配,取值为{0,1},表示第i个预测框关于类别p的概率(通过使用softmax函数求出),neg表示预测为负样本(即不与任何一个真实框匹配,匹配背景),表示第i个预测框关于背景类的置信度(0代表背景类),表示预测类别为p的置信度。
[0086]
在步骤s2-3中,将得到的不同尺度特征输入边界框预测分支,使用smoothl1损失作为边界框回归损失:
[0087][0088][0089][0090][0091][0092]
其中,l
loc
(x,l,g)表示边界框预测损失,边界框中心为(cx,cy),宽高分别为w和h,m表示表示边界框的每个参数,k表示类别,代表第i个预测框与第j个真实框关于类别k是否匹配,为预测框,为真实框,表示第j个真实框中心点的横坐标与第i个预测框初始锚框中心的横坐标的相对偏移量,表示第j个真实框中心点的横坐标,表示第i个预测框初始锚框中心的横坐标,表示第j个真实框中心点的横坐标与第i个预测框初始锚框中心的纵坐标的相对偏移量,表示第j个真实框中心点的纵坐标,表示第i个预测框初始锚框的纵坐标,表示第j个真实框的宽与第i个预测框初始锚框的宽的相对大小,表示第j个真实框的宽,表示第i个预测框初始锚框的宽,表示第j个真实框的高与第i个预测框初始锚框的高的相对大小,表示第j个真实框的高,表示第i个预测框初始锚框的高。
[0093]
进一步地,以分类学习损失l
cls
(x,c)和边界框预测损失l
loc
(x,l,g)为目标,使用反向传播算法对s-2中网络结构进行训练;
[0094]
步骤s4,利用步骤s3训练好的深度学习模型,将真实的海面图片输入网络得到分类置信度和边界框预测,根据置信度nms选取最终预测边界结果。
[0095]
本发明创新性使用自上而下的transformer解码策略,对fpn中自上而下的不同尺度特征图采用可变形卷积的方式实现encoder中的自注意力机制,同时从高层的较小特征层开始通过在相邻两个特征层之间引入transformer模块进行解码预测边界框,自上而下通过不断引入包含更多小目标信息的低层特征来不断进行边界框修正,进而提高小目标检测准确率。
[0096]
本发明创新性使用时空动态变化的仿真方式规划小目标在海面的嵌入位置。同时通过对小目标进行渲染,提高了海面小目标嵌入的真实性。通过使用仿真数据进行数据增强,使图片中的小目标分布均衡且真实。利用构建的仿真数据集进行训练,提高了小目标检测准确率。
[0097]
实施例3
[0098]
本实施例提供一种电子设备,包括:
[0099]
一个或多个处理器;
[0100]
存储装置,用于存储一个或多个程序;
[0101]
当一个或多个程序被所述一个或多个处理器执行,使得所述一个或多个处理器实现实施例1-实施例2中任一所述的方法。
[0102]
实施例4
[0103]
本实施例提供一种计算机可读介质,其上存储有计算机程序,所述程序被处理器执行时实现实施例1-实施例2中任一所述的方法。
[0104]
本文中所描述的具体实施例仅仅是对本发明精神作举例说明。本发明所属技术领域的技术人员可以对所描述的具体实施例做各种各样的修改或补充或采用类似的方式替代,但并不会偏离本发明的精神或者超越所附权利要求书所定义的范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1