一种基于时序卷积和关系建模的事件序列预测方法
1.本发明涉及一种事件序列预测方法,特别是一种基于时序卷积和关系建模的事件序列预测方法。
背景技术:
2.事件序列预测问题是时间序列分析领域重要的研究方向,早在20世纪70年代,就有相关学者对该领域开展相关的研究工作。在我们的日常生活中,事件序列数据无处不在,事件序列预测相关技术成果被应用于众多科学领域,例如社会科学,医学,地质学和物理学等领域领域。对事件序列相关数据进行分析和理解,对未来事件进行精准的预测,具有重要的社会价值,因此该领域受到学术界的广泛关注。
3.常规的事件序列数据是一组按照事件发生的先后顺序排列而成的数列,每个事件样本包含其发生的时间戳和额外的标记信息,事件序列预测问题的目标是利用历史事件序列预测未来将要发生事件的相关信息。目前处理该问题的方法主要分为两类,分别是基于传统机器学习的方法和基于深度学习的方法。
4.基于传统机器学习的方法是处理事件序列预测问题的早期方法,主要分为两类,分别为基于马尔可夫模型的方法和基于点过程模型的方法。其中基于马尔可夫模型的方法利用无向图构造一个非确定性模式的系统,并通过n阶马尔可夫性质建立当前事件与历史n个事件间的依赖关系。基于点过程模型的方法则在历史序列的基础上构建一个随机过程模型,因此可以更自然的建立序列中不同事件间的依赖关系,该类方法的核心是对条件强度函数进行建模,例如hawkes等人提出的hawkes点过程模型,利用条件强度函数描述历史事件对于未来事件的激励过程,并且考虑环境本身的基础强度的影响,具有良好的预测性能。参考文献:chen j,hawkes a g,scalas e,et al:performance of information criteria for selection of hawkes process models of financial data.in:quantitative finance,2018:225-235.
5.近年来,由于设备计算能力提升和人工智能技术的不断发展,基于深度学习的方法逐渐成为该领域的主流方法。目前基于深度学习的事件序列预测模型主要基于循环神经网络进行设计,由于深度学习模型可以自动学习数据中的复杂高阶特征,使得该类方法有能力处理大规模数据。其中典型的方法是nan du等人提出的rmtpp模型,利用长短期记忆网络和门控循环单元对事件序列进行特征编码,并同时考虑历史事件序列、当前事件和基础强度对未来事件的影响,使得模型性能显著提升。参考文献:du n,dai h,trivedi r,et al:recurrent marked temporal point processes:embedding event history to vector.in:22th acm sigkdd international conference on knowledge discovery and data mining.2016:1555-1564.
6.尽管基于循环神经网络的模型已经具有一定的预测精度,但是由于循环神经网络自身结构的特点,难以进行并行计算,因此在模型训练和推理过程中存在计算效率低的问题。并且循环神经网络虽然可以对序列数据进行编码表示,但是其本身无法直接描述序列
中不同事件之间的影响关系,因此相关模型不仅缺乏可解释性,而且没有对事件之间的影响关系进行充分的挖掘和分析,限制模型性能。
技术实现要素:
7.发明目的:本发明所要解决的技术问题是针对现有技术的不足,提供一种基于时序卷积和关系建模的事件序列预测方法。
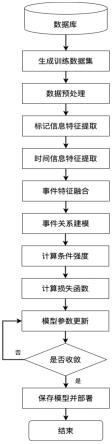
8.为了解决上述技术问题,本发明公开了一种基于时序卷积和关系建模的事件序列预测方法,包括以下步骤:
9.步骤1,从数据库中生成用于模型训练的历史事件序列数据集d
train
,即原始训练数据集d
train
,每个事件数据包含历史事件所发生的时间戳和标记信息,并构建事件序列预测模型;
10.步骤2,对原始训练数据集进行数据预处理,包括数据清洗和事件间隔时间计算;其中,数据清洗过程包括无效样本去除,异常样本修补以及数据归一化;
11.步骤3,利用标记特征编码器f
mark
对原始训练数据集d
train
中历史事件的标记信息进行特征提取,得到标记特征编码v
mark
;
12.步骤4,利用时序特征编码器f
time
对原始训练数据集d
train
中历史事件的时间戳信息进行特征提取,得到时间特征编码v
time
;
13.步骤5,对标记特征编码v
mark
和时间特征编码v
time
进行特征融合,得到对于单个事件的特征表示v
event
;
14.步骤6,基于历史事件序列中单个历史事件的特征编码,构造事件间的时序相关性图,并利用其对历史事件序列进行特征表示,得到序列特征si;
15.步骤7,利用序列特征si计算每种类型事件的条件强度函数λ,利用条件条件强度推理得到未来事件发生的时间戳和标记信息;
16.步骤8,计算事件序列预测模型的损失函数值,计算对应的梯度,并利用优化算法实现事件序列预测模型的反向传播,更新事件序列预测模型参数;
17.步骤9,判断事件序列预测模型的损失曲线是否收敛,若没有收敛,则返回步骤8继续对事件序列预测模型进行参数优化。
18.步骤10,完成基于时序卷积和关系建模的事件序列预测,保存已经训练好的事件序列预测模型,并将事件序列预测模型部署至服务器。
19.本发明步骤1中,从数据库中生成用于模型训练的历史事件序列数据集d
train
,其中包含n
t
个历史事件数据,每个历史事件数据包括历史事件发生的时间戳信息和该事件对应的标记信息;所述序列对事件进行排列,事件对应的编码从0开始递增;在训练数据集基础上,构建事件序列预测模型。
20.本发明步骤2中,将步骤1中生成的历史事件序列数据集作为训练集输入,并对原始训练数据集进行数据的清洗以及事件间隔时间的计算;
21.其中,数据清洗步骤包括:对d
train
中无效和重复样本进行统计和删减;使用局部异常因子算法(参考:yang j,zhong n,yao y,et al.:local peculiarity factor and its application in outlier detection.in:acm sigkdd international conference on knowledge discovery&data mining,2008:776-784)筛选d
train
中的异常值,利用历史事件
序列的平均值进行修正;使用最大最小值归一化方法对训练集中样本进行数据归一化,将数据分批进行整理,并使用batch normalization方法(参考:ioffe s,szegedy c:batch normalization:accelerating deep network training by reducing internal covariate shift.in:international conference on machine learning,2015:448-456.)对其进行批归一化。
22.本发明步骤3包括:
23.步骤3-1,定义一种时序注意力卷积网络作为标记特征编码器f
mark
,使用线性整流函数relu(参考:glorot x,bordes a,bengio y:deep sparse rectifier neural networks.in:proceedings of the 14th international conference on artificial intelligence and statistics.2011:315-323.)作为该网络的激活函数,使用凯明初始化kaiming initialization方法(参考:he k,zhang x,ren s,et al:delving deep into rectifiers:surpassing human-level performance on imagenet classification.in:international conference on computer vision 2015:1026—1034.)进行网络参数的初始化;
24.步骤3-2,针对d
train
中的历史事件序列,计算其对应的标记信息序列中不同历史事件标记信息之间的时序相关性矩阵:
[0025][0026][0027][0028][0029]
其中,m
1:t
表示历史序列中第1到t个事件所对应的标记信息所组成的序列,即标记信息序列,k
1:t
和q
1:t
表示m
1:t
对应的键值keys和查询query,和表示计算keys和query所使用的线性映射层,i和j表示历史事件步,ki和qj分别表示对应事件步的keys和query,dk表示特征向量的维度,w
i,j
表示序列的一般自相关性矩阵,wt
i,j
表示序列的时序相关性矩阵;
[0030]
步骤3-3,利用时序注意力结构对d
train
中历史事件序列对应的标记信息序列m
1:t
进行初步的特征提取;时序注意力ta的计算过程如下:
[0031][0032][0033]
其中,v
1:t
为m
1:t
所对应的重编码后的张量值values,为计算values所使用的线性映射层,softmax为归一化指数函数,为时序注意力结构所输出的标记信息的初步特征编码;
[0034]
步骤3-4,在的基础上,利用时序卷积结构对d
train
中历史事件序列对应的标记信息序列进行进一步的特征提取,时序卷积tc的计算过程如下:
intelligence.2017:1597—1603.),包括时间戳和标记信息
[0051]
本发明步骤8中,定义对数似然函数为模型的损失函数,并计算模型在d
train
上的损失函数值,计算对应的梯度,并利用adam优化算法(参考:kingma d p,ba j.adam:a method for stochastic optimization.in:3rd international conference on learning representations.2015.)实现模型的反向传播,优化模型参数。
[0052]
本发明步骤10中,保存已经训练好的模型,并将模型部署至服务器,并对外提供接口服务。
[0053]
有益效果:
[0054]
1、本发明设计一种时序注意力卷积网络,通过时序卷积中的因果卷积网络模拟循环神经神经网络的序列建模过程,并且计算过程可并行化,因此模型在进行训练和推理过程中的计算效率显著提升。
[0055]
2、由于本发明所提出的时序注意力卷积网络中设计了相关的注意力机制,因此模型可以建立当前事件与更早期历史事件之间的依赖性,扩大模型的感受野,丰富模型的表达能力。
[0056]
3、本发明通过构造时序相关性图,为事件序列相关数据提出一种直接建模事件间的影响关系的方法,使得模型具有一定可解释性,并且提升模型对于未来事件的预测性能。
附图说明
[0057]
下面结合附图和具体实施方式对本发明做更进一步的具体说明,本发明的上述和/或其他方面的优点将会变得更加清楚。
[0058]
图1为本发明流程示意图。
[0059]
图2为本发明所提出事件序列预测方法的整体计算框架图。
[0060]
图3为本发明所提出时序注意力卷积网络的模型结构图。
[0061]
图4为本发明所提出方法在2个事件序列预测数据集上进行实例验证时的测试结果示意图。
具体实施方式
[0062]
下面结合附图及实施例对本发明做进一步说明。
[0063]
如图1所示,一种基于时序卷积和关系建模的事件序列预测方法包括10个步骤:
[0064]
步骤1中,根据数据库的规模,在现有数据库中进行数据采样,生成用于模型训练的事件序列数据集d
train
,其中包含n
t
个被记录的历史事件数据,每个事件数据包括事件发生的时间戳信息和该事件对应的标记信息。对事件进行排列,事件对应的编码从0开始递增,在训练数据集基础上,构建事件序列预测模型。。
[0065]
步骤2中,将当前生成的事件序列数据作为训练集输入此算法,并对原始数据集进行数据的清洗以及事件间隔时间的计算。数据清洗步骤包括对于d
train
中无效和重复样本的统计和删减;使用局部异常因子算法筛选d
train
中的异常值,利用平均值进行修正;并使用最大最小值归一化方法对训练集中样本进行数据归一化。将数据分batch进行整理,并使用batch normalization方法对其进行批归一化。
[0066]
步骤3包括如下步骤:
[0067]
步骤3-1,定义一种时序注意力卷积网络作为标记特征编码器f
mark
,使用relu作为网络的激活函数,使用kaiming初始化方法进行网络参数的初始化。
[0068]
步骤3-2,针对d
train
中历史事件序列,计算其对应的标记信息序列中不同事件标记信息之间的时序相关性矩阵:
[0069][0070][0071][0072][0073]
其中m
1:t
表示历史序列中第1到t个事件所对应的标记信息所组成的序列,k
1:t
和q
1:t
表示m
1:t
对应的keys和query,和表示计算keys和query所使用的线性映射层,dk表示特征向量的维度,w
i,j
表示序列的一般自相关性矩阵,wt
i,j
表示序列的时序相关性矩阵。
[0074]
步骤3-3,利用时序注意力结构对d
train
中历史事件序列对应的标记信息序列m进行初步的特征提取。时序注意力ta的计算过程如下:
[0075][0076][0077]
其中v
1:t
为m
1:t
所对应的重编码后的values,为计算values所使用的线性映射层,softmax为归一化指数函数,为时序注意力结构所输出的标记信息的初步特征编码。
[0078]
步骤3-4,在的基础上,利用时序卷积结构对d
train
中历史事件序列对应的标记信息序列进行进一步的特征提取,时序卷积tc的计算过程如下:
[0079][0080][0081]
其中conv
cau
和conv
dil
分别表示因果卷积和空洞卷积,和v
mark
分别表示两种卷积的输出,v
mark
为所得到的历史事件标记特征编码。
[0082]
步骤4中,我们定义非线性映射层作为时序特征编码器f
time
,使用relu作为网络的激活函数,使用kaiming初始化方法进行网络参数的初始化。利用对d
train
中历史事件的时间戳信息进行特征提取,得到时间特征编码v
time
。
[0083]
步骤5中,我们对v
mark
和v
time
进行特征融合,特征融合过程如下:
[0084][0085]
其中和为用于融合的线性映射层,v
event
为所得到的单个事件特征表示。
[0086]
步骤6包括如下步骤:
[0087]
步骤6-1,我们利用滑动窗口方法对d
train
中的事件序列进行处理,对于每个事件序列,定义lw为窗口大小,在v
event
的基础上,生成基于窗口的事件特征序列s
ori
,并在每个窗口
上构造时序相关性图。
[0088]
步骤6-2,对于s
ori
,我们计算序列中不同事件间的相关性权重:
[0089][0090]
其中w
rel
表示神经网络的权重,nei表示事件在时序相关性图中的邻居节点。
[0091]
步骤6-3,我们利用相关性权重构造时序相关性图的邻接矩阵a
rel
,并在时序相关性图上进行节点信息聚合,实现对事件节点的重编码并进行拼接,得到得到序列特征si。
[0092]
步骤7中,我们为每类型的事件定义条件强度函数λ,并利用历史序列特征si计算不同类型事件的λ:
[0093]
λk(t)=exp(wv·
si+wd·
(t-tj)+be)
[0094]
其中wv和wd表示神经网络的权重,be表示基础强度,t表示当前时间,tj表示上一事件时间戳。利用强度函数输出对于未来事件的预测信息,包括时间戳和标记信息
[0095]
步骤8中,我们定义对数似然函数为模型的损失函数,并计算模型在d
train
上的损失函数值,计算对应的梯度,并利用adam优化算法实现模型的反向传播,优化模型参数。
[0096]
步骤9中,我们判断模型的损失曲线是否收敛,若曲线没有收敛,则返回步骤8继续对模型进行参数优化。
[0097]
步骤10中,我们保存已经训练好的模型,并将模型部署至服务器,提供restful api接口服务。
[0098]
实施例
[0099]
为了验证本发明的有效性,我们分别在两个真实场景下采集的事件序列预测任务数据集上进行实例验证,包括iptv数据集和mimic-ii数据集。其中iptv数据集是中国电信公司所提供的用户观看有线电视节目行为的事件序列数据,包含2967个用户的观看行为序列;mimic-ii数据集是医学中心所提供患者的医疗诊断相关事件序列数据,记录了去该医学中心就诊的53423名患者在2001至2008年间的就诊数据。本实施例现以iptv数据集中一个用于测试的事件序列数据为例,按照以下步骤进行事件预测:
[0100]
1、对该事件序列数据进行数据预处理,包含数据的清洗和间隔时间的计算。数据清洗过程包括无效样本的去除,异常样本的修补以及数据归一化。
[0101]
2、利用标记特征编码器f
mark
对该事件序列数据中历史事件的标记信息进行特征提取,得到标记特征编码v
mark
。
[0102]
3、利用时序特征编码器f
time
对该事件序列数据中历史事件的时间戳信息进行特征提取,得到时间特征编码v
time
。
[0103]
4、对利用步骤3得到的v
mark
和v
time
进行特征融合,得到对于单个事件的特征表示v
event
。
[0104]
5、利用步骤4得到的历史序列中单个事件的特征编码,构造事件间的时序相关性图,并利用其对历史序列进行特征表示,得到序列特征si。
[0105]
6、利用步骤5输出的历史序列特征si计算每种类型事件的条件强度函数λ,利用条件条件强度推理出未来事件发生的时间戳和标记信息,并将预测结果进行输出。
[0106]
经过测试,我们的方法在iptv数据集上达到了72.21%的预测准确率,均方根误差
(rmse)测试结果为12.632;在mimic-ii数据集上达到了84.33%的预测准确率,rmse测试结果为1.982。预测精度相比现有方法具有一定的提升,证明本发明所提出的基于时序卷积和关系建模的事件序列预测方法的有效性。
[0107]
如图2所示,展示了本发明中所提出的事件序列预测算法对于样本的整体计算框架图。可以明显的观察到我们的事件预测算法分为三个阶段,第一阶段为对于历史序列中每个事件进行特征编码,包括对于标记信息的特征编码和对于时间戳的特征编码;第二阶段为对于整个历史序列的特征编码;第三阶段为利用历史序列的特征表示预测未来事件的相关信息。在第一阶段中,我们使用所设计的时序注意力卷积网络对历史事件的标记信息进行特征编码,使用非线性映射层对历史事件的时间戳进行特征编码;在第二阶段中,我们在历史序列上构建时序相关性图,并利用此图结构实现对于历史序列的编码;在第三阶段中,我们定义并计算每种类型事件的条件强度,并根据条件强度对未来事件进行预测。
[0108]
如图3所示,展示了本发明所提出的时序注意力卷积网络的具体模型结构图。通过此图我们可以发现时序注意力卷积网络主要由三个模块构造而成,分别为时序注意力模块(temporal attention),时序卷积模块(temporal convolution)以及强化残差模块(enhanced residual)。其中时序注意力模块和时序卷积模块实现对于输入序列所进行的高效特征提取,强化残差模块的作用是利用时序注意力模块中所得到的权值,增大输入序列特征中不同序列点的差异性,加快模型在训练阶段的收敛速度。
[0109]
如图4所示,展示了本发明所提出方法在2个事件序列预测数据集(iptv数据集和mimic-ii数据集)上进行实例验证时的测试结果,并将所提出方法与现有方法进行对比,分别对比预测准确率和rmse。其中,表的第一列列出不同数据集,第二列列出进行对比的现有方法,其中每个数据集对应的最后一行为本发明所提出的方法。对比方法包括rmtpp模型(参考:du n,dai h,trivedi r,et al:recurrent marked temporal point processes:embedding event history to vector.in:22th acm sigkdd international conference on knowledge discovery and data mining.2016:1555-1564.),intensity-rnn模型(参考:xiao s,yan j,chu s m,et al:modeling the intensity function of point process via recurrent neural networks.in:proceedings of the 35th conference on artificial intelligence.2017:1597—1603.),nhp模型(参考:m,charpentier b,g
ü
nnemann s:uncertainty on asynchronous time event prediction.in:advances in neural information processing systems.2019,32.),fullynn-tpp(参考omi t,aihara k:fully neural network based model for general temporal point processes.in:advances in neural information processing systems,2019.)以及sahp模型(参考:zhang q,lipani a,kirnap o,et al:self-attentive hawkes process.in:international conference on machine learning.pmlr.2020:11183-11193.)。测试结果显示本发明在预测准确率和rmse上均优于所对比的模型,证明这套利用时序注意力卷积进行序列特征提取、利用时序相关性图进行历史序列中不同事件关系建模方法的可行性和有效性。
[0110]
本发明提供了一种基于时序卷积和关系建模的事件序列预测方法的思路及方法,具体实现该技术方案的方法和途径很多,以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以做出若干改
进和润饰,这些改进和润饰也应视为本发明的保护范围。本实施例中未明确的各组成部分均可用现有技术加以实现。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1