机器学习模型训练方法、业务数据处理方法、装置及系统与流程
本技术涉及人工智能,尤其涉及一种机器学习模型的训练方法、业务数据的处理方法、装置及系统
背景技术:
1、联邦学习(federated learning)是一种分布式机器学习技术。每个参与联邦学习的客户端(federated learning client,flc)设备,如联邦学习装置1、2、3……k,利用本地计算资源和本地网络业务数据进行模型训练,并将本地训练过程中产生的模型参数更新信息δω,如δω1、δω2、δω3……δωk,发送给联邦学习服务器(federated learningserver,fls)。联邦学习服务器基于δω采用融合算法进行模型融合,得到融合机器学习模型。融合机器学习模型作为联邦学习装置下一次执行模型训练的初始模型。联邦学习装置和联邦学习服务器多次执行上述模型训练过程,直到得到的融合机器学习模型满足预设条件时,停止训练。
2、联邦学习能够使参与联邦学习的客户端设备可以协作构建通用、更健壮的机器学习模型而不需要共享数据。在数据监管越来越严格的大环境下,联邦学习能够解决数据所有权、数据隐私、数据访问权等关键问题,具有极大的商业价值。
3、如何提升模型的训练效率成为需要解决的问题。
技术实现思路
1、本技术实施例提供机器学习模型的训练方法、业务数据的处理方法、装置及系统,通过本方案,在训练阶段,可以提升机器学习模型的训练效率,在推理阶段,可以提升机器学习模型的预测效率。
2、为达到上述目的,本技术实施例提供如下技术方案:
3、第一方面,本技术实施例提供一种机器学习模型的训练方法,应用于边侧服务器,边侧服务器归属于云侧服务器的管理域,其中,云侧服务器的管理域可以理解为该云侧服务器所管理的服务器或客户端设备的集合,或者说与该云侧服务器相连的边侧服务器,以及与这些边侧服务器相连的客户端设备组成的网络。边侧服务器归属于云侧服务器的管理域,可以理解为边侧服务器受该云侧服务器管理,或者边侧服务器与该云侧服务器相连,或者该边侧服务器与云侧服务器交互数据以及模型(比如,在第一方面,模型包括第一机器学习子模型或者第二机器学习子模型)。该方法包括:首先边侧服务器从云侧服务器获取第一机器学习子模型,第一机器学习子模型的数目可以是一个或者多个。第一机器学习子模型应用于边侧服务器的管理域,其中,边侧服务器的管理域为云侧服务器的管理域的子集,可以理解为边侧服务器所管理的客户端设备的集合。边侧服务器的管理域可以理解为与该边侧服务器相连的客户端设备组成的网络,边侧服务器与其管理域内的客户端设备可以交互数据以及模型(比如,在第一方面,模型包括第一机器学习子模型或者第二机器学习子模型)。然后,边侧服务器基于第一机器学习子模型和边侧服务器的管理域的本地业务数据,与边侧服务器的管理域中的多个客户端设备进行联邦学习,得到第二机器学习子模型。其中,边侧服务器的管理域的本地业务数据,可以包括与用户有关的数据或者是与网络有关的数据,具体的可能是边侧服务器的管理域内的客户端设备在运行过程中产生的数据,比如日志。再比如,可能是边侧服务器的管理域的客户端设备基于用户的操作而产生的数据,比如基于用户的语音输入操作,产生的语音数据,基于用户的文本输入操作,产生的文本数据,基于用户的拍摄操作,产生的图像数据等等。最后,边侧服务器向云侧服务器发送第二机器学习子模型。
4、该技术方案中,边侧服务器从云侧服务器中获取机器学习子模型,该机器学习子模型的参数规模小于云侧服务器保存的完整的机器学习模型的参数规模。由于机器学习子模型的参数规模更小,有利于提升边侧服务器与边侧服务器的管理域中的多个客户端设备基于该机器学习子模型进行联邦学习的效率。
5、另外,客户端设备不需要保存完整的机器学习模型,只需要保存小规模的机器学习子模型就可以实现其本地的业务需求,降低了对客户端设备的性能的需求。
6、再者,多个边侧服务器可以并行上传训练后的机器学习子模型至云侧服务器,由云侧服务器对多个训练后的机器学习子模型进行融合处理。相比于多个边侧服务器串行上传训练后的机器学习子模型至云侧服务器,多个边侧服务器并行上传训练后的机器学习子模型至云侧服务器的方式,可以缩短传输机器学习子模型所需时长,进一步提升机器学习模型的训练效率。
7、此外,每个客户端设备以及边侧服务器都未保存完整的机器学习模型,避免通过单个设备就可以获取完整的机器学习模型,提升机器学习模型的抗攻击性。
8、在第一方面的一种可能实现方式中,第一机器学习子模型用于执行用户业务中的子业务集合。比如,用户业务为分类任务,用户业务中的子业务可以包括对爬行动物的分类任务、对哺乳动物的分类任务等等。
9、在第一方面的一种可能实现方式中,云侧服务器的管理域是基于网络区域信息或者网络切片信息划分的。网络区域信息可以为物理区域信息(或者说地理位置信息),同一网络区域可以划分为一个管理域。网络切片信息可以包括网络切片选择辅助信息(networkslice selection assistance information,nssai),nssai包括一个或者多个单个网络切片选择辅助信息(single network slice selection assistance information,s-nssai),适用相同网络切片信息的网络可以划分为一个管理域。示例的,云侧服务器的管理域可以是电信运营商网络、虚拟运营商网络、边侧服务器的管理域可以是企业网络(如银行、政府、大型企业等行业的网络系统)和园区网络等。
10、在第一方面的一种可能实现方式中,第一机器学习子模型包括选择器和多个任务模型,从云侧服务器获取第一机器学习子模型,包括:从云服务器获取选择器;将边侧服务器的管理域的本地业务数据输入至选择器,以获取多个任务模型的标识id;向云侧服务器发送多个任务模型的id;接收云服务器发送的多个任务模型。在这种实施方式中,引入多个任务模型,其中,云侧服务器中保存全部的任务模型,边侧服务器根据不同的客户端设备获取到的数据的分布特征,利用选择器从云侧服务器中获取部分任务模型。通过这样的方式,客户端设备不需要保存全部的任务模型,只需要保存部分任务模型就可以实现其本地的业务需求,降低了对客户端设备的性能的需求。
11、在第一方面的一种可能实现方式中,基于第一机器学习子模型和边侧服务器的管理域的本地业务数据,与边侧服务器的管理域中的多个客户端设备进行联邦学习,得到第二机器学习子模型,包括:向多个客户端设备发送第一机器学习子模型,触发多个客户端设备利用各自的本地业务数据和选择器获取每个任务模型的输出对应的权重,以及触发多个客户端设备利用各自的本地业务数据和多个任务模型,以及多个客户端设备各自获取的权重获取多个客户端设备的本地业务数据对应的特征向量;接收多个客户端设备发送的聚类特征,聚类特征是多个客户端设备对各自获取到的特征向量进行聚类处理后获取的;对标签相同的聚类特征进行融合处理,以获取融合聚类特征;其中,本技术对特征向量(比如聚类特征)进行融合处理可以理解为对特征向量进行加权处理,或者可以理解为对特征向量进行聚类处理,本技术实施例对融合处理的具体手段并不进行限定。向多个客户端设备发送融合聚类特征,触发多个客户端设备利用特征向量和融合聚类特征之间的差异更新第一机器学习子模型的参数,更新后的第一机器学习子模型用于获取第二机器学习子模型。在这种实施方式中,在训练阶段利用客户端设备的本地数据、选择器和任务模型获取特征向量集合,并在训练阶段利用该特征向量集合对选择器和任务模型进行更新,再利用更新后的选择器和更新后的任务模型,对特征向量集合进行更新,如此反复,直至完成训练过程。通过这样的方式,仅利用少量的训练数据就可以快速的对机器学习子模型或者机器学习模型进行更新,有利于提升模型更新的效率。
12、在第一方面的一种可能实现方式中,融合聚类特征具有置信区间,融合聚类特征的置信区间是对多个客户端设备发送的标签相同的聚类特征的置信区间进行融合处理后获取的。
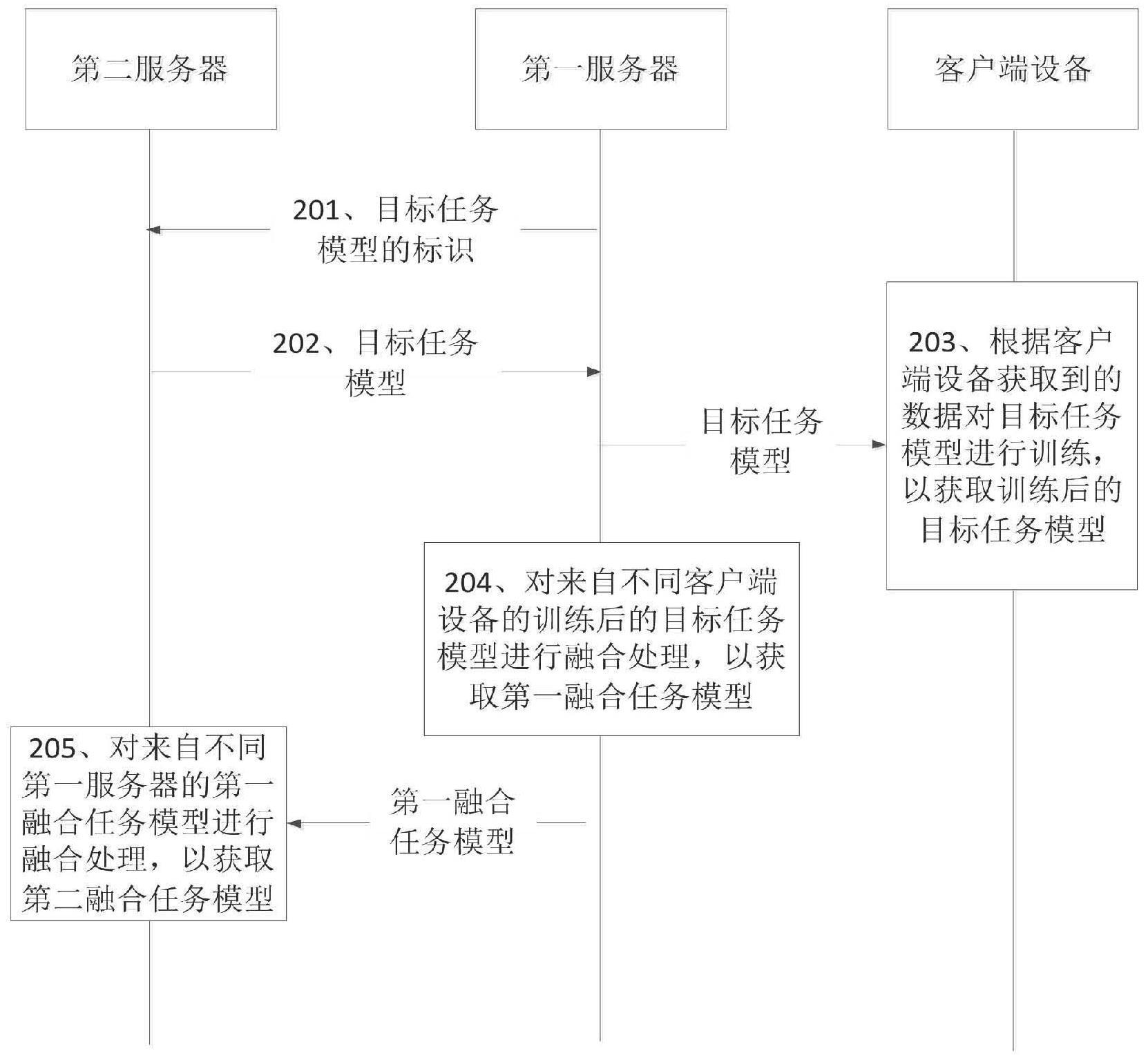
13、第二方面,本技术实施例提供一种机器学习模型的训练方法,应用于云侧服务器,第一边侧服务器的管理域为云侧服务器的管理域的第一子集,第二边侧服务器的管理域为云侧服务器的管理域的第二子集,方法包括:向第一边侧服务器发送第一机器学习子模型以及向第二边侧服务器发送第二机器学习子模型;从第一边侧服务器接收第三机器学习子模型以及从第二边侧服务器接收第四机器学习子模型,第三机器学习子模型为基于第一机器学习子模型和第一边侧服务器的管理域的本地业务数据,与第一边侧服务器的管理域中的多个客户端设备进行联邦学习得到,第四机器学习子模型为基于第二机器学习子模型和第二边侧服务器的管理域的本地业务数据,与第二边侧服务器的管理域中的多个客户端设备进行联邦学习得到;将第三机器学习子模型和第四机器学习子模型进行融合处理,得到机器学习模型。其中,本技术对模型(比如第三机器学习子模型和第四机器学习子模型)进行融合处理可以理解为对模型的参数进行加权处理,或者可以理解为利用本地数据以及待融合的模型进行模型蒸馏处理,本技术实施例对融合处理的具体手段并不进行限定。
14、在第二方面的一种可能实现方式中,第一机器学习子模型用于执行用户业务中的第一子业务集合。
15、在第二方面的一种可能实现方式中,第二机器学习子模型用于执行用户业务中的第二子业务集合。
16、在第二方面的一种可能实现方式中,云侧服务器的管理域是基于网络区域信息或者网络切片信息划分的。
17、在第二方面的一种可能实现方式中,第一机器学习子模型包括选择器和多个第一任务模型,第二机器学习子模型包括选择器和多个第二任务模型,向第一边侧服务器发送第一机器学习子模型以及向第二边侧服务器发送第二机器学习子模型,包括:向第一边侧服务器发送选择器以及向第二边侧服务器发送选择器;从第一边侧服务器接收多个第一任务模型的标识id以及从第二边侧服务器接收多个第二任务模型的id,多个第一任务模型的id是第一边侧服务器将第一边侧服务器的管理域的本地业务数据输入至选择器获取的,多个第二任务模型的id是第二边侧服务器将第二边侧服务器的管理域的本地业务数据输入至选择器获取的;向第一边侧服务器发送多个第一任务模型以及向第二边侧服务器发送多个第二任务模型。
18、在第二方面的一种可能实现方式中,该方法还包括:将云侧服务器的管理域的本地业务数据作为训练数据,将针对目标训练数据对应输出目标任务模型的id作为训练目标训练对初始的选择器进行训练,以得到选择器,目标训练数据是云侧服务器的管理域的本地业务数据中具有相同标签的业务数据,目标任务模型的id包括云侧服务器中存储的多个任务模型中的至少一个任务模型的id。在这种实施方式中,给出了一种具体的获取选择器的方式,增加了方案的多样性。
19、在第二方面的一种可能实现方式中,训练数据还包括辅助数据,辅助数据包括和云侧服务器的管理域的本地业务数据标签相同的数据。通过在训练过程中引入辅助数据,为训练选选择器提供更多的参考信息,有助于选择器针对输入做出更准确的预测,提升选择器的训练效率。
20、在第二方面的一种可能实现方式中,将云侧服务器的管理域的本地业务数据作为训练数据,将针对目标训练数据对应输出目标任务模型的id作为训练目标训练对初始的选择器进行训练,以得到选择器,包括:固定初始的选择器的部分参数,将云侧服务器的管理域的本地业务数据作为训练数据,将针对目标训练数据对应输出目标任务模型的id作为训练目标训练对初始的选择器进行训练,以得到选择器。在训练阶段,固定选择器的部分参数进行训练,有利于将来适用更多的场景,比如将来可能引入更多的任务模型。
21、在第二方面的一种可能实现方式中,选择器为n个自编码器,n个自编码器与云侧服务器中存储的n个任务模型一一绑定,n为大于1的正整数,方法还包括:以云侧服务器的管理域的本地业务数据中具有相同标签的业务数据为训练数据,对一个初始的自编码器进行训练,以获取一个自编码器,任意两个自编码器的训练数据的标签不同。在这种实施方式中,给出了一种具体的获取选择器的方式,增加了方案的多样性。
22、第三方面,本技术实施例提供一种机器学习模型的训练方法,应用于客户端设备,客户端设备归属于云侧服务器的管理域,客户端设备归属于云侧服务器的管理域,可以理解为客户端设备受该边侧服务器管理,或者客户端设备与该边侧服务器相连,或者该边侧服务器与边侧服务器交互数据以及模型(比如,在第三方面,模型包括第一机器学习子模型或者第二机器学习子模型)。方法包括:接收边侧服务器发送的第一机器学习子模型,第一机器学习子模型应用于边侧服务器的管理域,其中,边侧服务器的管理域为云侧服务器的管理域的子集;基于第一机器学习子模型和边侧服务器的管理域的本地业务数据,与边侧服务器、边侧服务器的管理域中其他客户端设备进行联邦学习,得到第二机器学习子模型。
23、在第三方面的一种可能实现方式中,第一机器学习子模型用于执行用户业务中的子业务集合。
24、在第三方面的一种可能实现方式中,云侧服务器的管理域是基于网络区域信息或者网络切片信息划分的。
25、在第三方面的一种可能实现方式中,基于第一机器学习子模型和边侧服务器的管理域的本地业务数据,与边侧服务器、边侧服务器的管理域中其他客户端设备进行联邦学习,得到第二机器学习子模型,包括:接收边侧服务发送的第一机器学习子模型;根据客户端设备的本地业务数据和第一机器学习子模型获取特征向量;对特征向量进行聚类处理后获取聚类特征;向边侧服务器发送聚类特征,触发边侧服务器对标签相同的聚类特征进行融合处理,以获取融合聚类特征;接收边侧服务发送的融合聚类特征;利用特征向量和融合聚类特征之间的差异更新第一机器学习子模型的参数,更新后的第一机器学习子模型用于获取第二机器学习子模型。
26、在第三方面的一种可能实现方式中,向边侧服务器发送聚类特征,触发边侧服务器对标签相同的聚类特征进行融合处理,以获取融合聚类特征,包括:向边侧服务器发送聚类特征以及聚类特征的置信区间,触发边侧服务器对标签相同的聚类特征进行融合处理,以获取融合聚类特征,以及对标签相同的聚类特征的置信区间进行融合处理后,以获取融合聚类特征的置信区间。
27、在第三方面的一种可能实现方式中,方法还包括:获取目标信息,目标信息用于指示边侧服务器的管理域的全部业务数据中不同标签的业务数据的占比;根据目标信息和不同标签的业务数据在客户端设备的全部业务数据中的占比,对客户端设备的全部业务数据进行采样,以获取客户端设备的本地业务数据,不同的客户端设备的本地业务数据用于获取边侧服务器的管理域的本地业务数据。客户端设备本地重要样本的采集可以通过边侧服务器联合其管理的多个客户端设备协同采样数据,兼顾各客户端数据量以及客户端掉线后重要数据的鲁棒性。
28、第四方面,本技术实施例提供一种业务数据的处理方法,包括:客户端设备获取第一业务数据,客户端设备归属于云侧服务器的管理域;客户端设备将第一业务数据输入到第二机器学习子模型中,以获取第一特征向量,第二机器学习子模型是客户端设备基于第一机器学习子模型和边侧服务器的管理域的本地业务数据,与边侧服务器、边侧服务器的管理域中其他客户端设备进行联邦学习得到的,第一机器学习子模型应用于边侧服务器的管理域,边侧服务器的管理域为云侧服务器的管理域的子集;客户端设备根据第一特征向量获取针对第一业务数据的预测结果。
29、在第四方面的一种可能实现方式中,第二机器学习子模型包括包括选择器和多个任务模型,客户端设备将第一业务数据输入到第二机器学习子模型中,以获取第一特征向量,包括:客户端设备将第一业务数据输入到选择器中以及输入到多个任务模型中,客户端设备根据选择器的输出获取每个任务模型对应的权重;客户端设备根据权重对多个任务模型的输出进行加权处理,以获取第一特征向量。
30、在第四方面的一种可能实现方式中,客户端设备根据第一特征向量获取针对第一业务数据的预测结果,包括:客户端设备根据第一特征向量和至少一个第一融合聚类特征之间的相似性以及至少一个第一融合聚类特征的标签,获取针对第一业务数据的预测结果。
31、在第四方面的一种可能实现方式中,客户端设备根据第一特征向量获取针对第一业务数据的预测结果,包括:客户端设备根据第一特征向量和至少一个第一融合聚类特征之间的相似性、至少一个第一融合聚类特征的置信区间以及至少一个第一融合聚类特征的标签,获取针对第一业务数据的预测结果。
32、在第四方面的一种可能实现方式中,第一特征向量和至少一个第一融合聚类特征之间的相似性低于第一阈值,或者第一特征向量没有在任意一个第一融合聚类特征的置信区间内,方法还包括:客户端设备在边侧服务器的管理域内广播第一特征向量或者广播第一业务数据。
33、在第四方面的一种可能实现方式中,方法还包括:客户端设备获取第二特征向量,第二特征向量和至少一个第一融合聚类特征之间的相似性低于第一阈值,或者第二特征向量没有在任意一个第一融合聚类特征的置信区间内;客户端设备根据第一特征向量获取针对第一业务数据的预测结果,包括:客户端设备根据第一特征向量和至少一个第一融合聚类特征之间的相似性、第一特征向量和第二特征向量之间的相似性、至少一个第一融合聚类特征的标签以及第二特征向量的标签获取针对第一业务数据的预测结果。
34、在第四方面的一种可能实现方式中,方法还包括:客户端设备从边侧服务器接收第二融合聚类特征,第二融合聚类特征和任意一个第一融合聚类特征之间的偏差超过第二阈值;客户端设备根据第一特征向量获取针对第一业务数据的预测结果,包括:客户端设备根据第一特征向量和至少一个第一融合聚类特征之间的相似性、第一特征向量和第二融合聚类特征之间的相似性、至少一个第一融合聚类特征的标签以及第二融合聚类特征的标签获取针对第一业务数据的预测结果。
35、在第四方面的一种可能实现方式中,方法还包括:客户端设备获取在第二融合聚类特征采用不同的置信区间时,针对第三特征向量的预测结果,第三特征向量和至少一个第一融合聚类特征之间的相似性低于第一阈值,或者第三特征向量没有在任意一个第一融合聚类特征的置信区间内;客户端设备根据预测结果,获取针对不同的置信区间的评价指标;客户端设备向边侧服务器发送不同的置信区间的评价指标,触发边侧服务器根据获取到的不同参考置信区间的评价指标获取第二融合聚类特征的置信区间;客户端设备接收边侧服务器发送的第二聚类特征的置信区间。
36、第五方面,本技术提供了一种边侧服务器。该边侧服务器用于执行上述第一方面以及第一方面提供的任一种可能的实施方式中边侧服务器执行的步骤。
37、在一种可能的设计方式中,本技术可以根据上述第一方面以及第一方面提供的任一种可能的实施方式,对边侧服务器进行功能模块的划分。例如,可以对应各个功能划分各个功能模块,也可以将两个或两个以上的功能集成在一个处理模块中。
38、示例性的,本技术可以按照功能将边侧服务器划分为收发模块和处理模块等。上述划分的各个功能模块执行的可能的技术方案和有益效果的描述均可以参考上述第一方面或其相应的可能的实施方式提供的技术方案,此处不再赘述。
39、在另一种可能的设计中,该边侧服务器包括:存储器和处理器,存储器和处理器耦合。存储器用于存储计算机指令,处理器用于调用该计算机指令,以执行如第一方面或其相应的可能的实施方式提供的方法。
40、第六方面,本技术提供了一种云侧服务器。该云侧服务器用于执行上述第二方面以及第二方面提供的任一种可能的实施方式中云侧服务器执行的步骤。
41、在一种可能的设计方式中,本技术可以根据上述第二方面以及第二方面提供的任一种可能的实施方式,对云侧服务器进行功能模块的划分。例如,可以对应各个功能划分各个功能模块,也可以将两个或两个以上的功能集成在一个处理模块中。
42、示例性的,本技术可以按照功能将云侧服务器划分为收发模块和处理模块等。上述划分的各个功能模块执行的可能的技术方案和有益效果的描述均可以参考上述第二方面或其相应的可能的实施方式提供的技术方案,此处不再赘述。
43、在另一种可能的设计中,该云侧服务器包括:存储器和处理器,存储器和处理器耦合。存储器用于存储计算机指令,处理器用于调用该计算机指令,以执行如第二方面或其相应的可能的实施方式提供的方法。
44、第七方面,本技术提供了一种客户端设备。该客户端设备用于执行上述第三方面以及第三方面提供的任一种可能的实施方式中客户端设备执行的步骤,或者用于执行上述第四方面以及第四方面提供的任一种可能的实施方式中客户端设备执行的步骤。
45、在一种可能的设计方式中,本技术可以根据上述第三方面以及第三方面提供的任一种可能的实施方式,或者根据上述第四方面以及第四方面提供的任一种可能的实施方式中客户端设备执行的步骤,对客户端设备进行功能模块的划分。例如,可以对应各个功能划分各个功能模块,也可以将两个或两个以上的功能集成在一个处理模块中。
46、示例性的,本技术可以按照功能将客户端设备划分为收发模块和处理模块等。上述划分的各个功能模块执行的可能的技术方案和有益效果的描述均可以参考上述第三方面或其相应的可能的实施方式提供的技术方案,或者参照上述第四方面以及第四方面提供的任一种可能的实施方式提供的技术方案,此处不再赘述。
47、在另一种可能的设计中,该客户端设备包括:存储器和处理器,存储器和处理器耦合。存储器用于存储计算机指令,处理器用于调用该计算机指令,以执行如第三方面或其相应的可能的实施方式提供的方法,或者用于执行上述第四方面以及第四方面提供的任一种可能的实施方式提供的方法。
48、第八方面,本技术提供了一种计算机可读存储介质,如计算机非瞬态的可读存储介质。其上储存有计算机程序(或指令),当该计算机程序(或指令)在计算机设备上运行时,使得该计算机设备执行如第一方面或其相应的可能的实施方式提供的方法,或者执行第二方面或其相应的可能的实施方式提供的方法,或者执行第三方面或其相应的可能的实施方式提供的方法,或者执行第四方面或其相应的可能的实施方式提供的方法。
49、第九方面,本技术提供了一种计算机程序产品,当其在计算机设备上运行时,使得如第一方面或其相应的可能的实施方式提供的方法被执行,或者使得第二方面或其相应的可能的实施方式提供的方法被执行,或者使得第三方面或其相应的可能的实施方式提供的方法被执行,或者使得第四方面或其相应的可能的实施方式提供的方法被执行。
50、第十方面,本技术提供了一种芯片系统,包括:处理器,处理器用于从存储器中调用并运行该存储器中存储的计算机程序,执行如第一方面或其相应的可能的实施方式提供的方法,或者执行如第二方面或其相应的可能的实施方式提供的方法,或者执行如第三方面或其相应的可能的实施方式提供的方法,或者执行如第四方面或其相应的可能的实施方式提供的方法。
51、可以理解的是,上述提供的任一种系统、装置、计算机存储介质、计算机程序产品或芯片系统等均可以应用于第一方面、第二方面、第三方面或第四方面提供的对应的方法。
52、第十一方面,本技术提供了一种机器学习模型的处理系统,该系统包括云侧服务器、第一边侧服务器、第二边侧服务器以及客户端设备,第一边侧服务器的管理域为云侧服务器的管理域的第一子集,第二边侧服务器的管理域为云侧服务器的管理域的第二子集,第一边侧服务器,用于从云侧服务器接收第一机器学习子模型,并基于第一机器学习子模型和第一边侧服务器的管理域的本地业务数据,与第一边侧服务器的管理域中的多个客户端设备进行联邦学习,得到第三机器学习子模型,第一机器学习子模型应用于第一边侧服务器的管理域;
53、第二边侧服务器,用于从云侧服务器接收第二机器学习子模型,并基于第二机器学习子模型和第二边侧服务器的管理域的本地业务数据,与第二边侧服务器的管理域中的多个客户端设备进行联邦学习,得到第四机器学习子模型,第二机器学习子模型应用于第二边侧服务器的管理域;云侧服务器,用于从第一边侧服务器接收第三机器学习子模型以及从第二边侧服务器接收第四机器学习子模型,并将第三机器学习子模型和第四机器学习子模型进行融合处理,得到机器学习模型。
54、在第十一方面的一种可能实现方式中,第一机器学习子模型用于执行用户业务中的子业务集合。
55、在第十一方面的一种可能实现方式中,第二机器学习子模型用于执行用户业务中的第二子业务集合。
56、在第十一方面的一种可能实现方式中,云侧服务器的管理域是基于网络区域信息或者网络切片信息划分的。
57、在第十一方面的一种可能实现方式中,第一机器学习子模型包括选择器和多个任务模型,边侧服务器,用于从云服务器获取选择器;将边侧服务器的管理域的本地业务数据输入至选择器,以获取多个任务模型的标识id;向云侧服务器发送多个任务模型的id;接收云服务器发送的多个任务模型。
58、在第十一方面的一种可能实现方式中,边侧服务器,具体用于向多个客户端设备发送第一机器学习子模型,触发多个客户端设备利用各自的本地业务数据和选择器获取每个任务模型的输出对应的权重,以及触发多个客户端设备利用各自的本地业务数据和多个任务模型,以及多个客户端设备各自获取的权重获取多个客户端设备的本地业务数据对应的特征向量;接收多个客户端设备发送的聚类特征,聚类特征是多个客户端设备对各自获取到的特征向量进行聚类处理后获取的;对标签相同的聚类特征进行融合处理,以获取融合聚类特征;向多个客户端设备发送融合聚类特征,触发多个客户端设备利用特征向量和融合聚类特征之间的差异更新第一机器学习子模型的参数,更新后的第一机器学习子模型用于获取第二机器学习子模型。
59、在第十一方面的一种可能实现方式中,融合聚类特征具有置信区间,融合聚类特征的置信区间是对多个客户端设备发送的标签相同的聚类特征的置信区间进行融合处理后获取的。
60、在第十一方面的一种可能实现方式中,云侧服务器,还用于将云侧服务器的管理域的本地业务数据作为训练数据,将针对目标训练数据对应输出目标任务模型的id作为训练目标训练对初始的选择器进行训练,以得到选择器,目标训练数据是云侧服务器的管理域的本地业务数据中具有相同标签的业务数据,目标任务模型的id包括云侧服务器中存储的多个任务模型中的至少一个任务模型的id。
61、在第十一方面的一种可能实现方式中,训练数据还包括辅助数据,辅助数据包括和云侧服务器的管理域的本地业务数据标签相同的数据。
62、在第十一方面的一种可能实现方式中,云侧服务器,具体哟用于固定初始的选择器的部分参数,将云侧服务器的管理域的本地业务数据作为训练数据,将针对目标训练数据对应输出目标任务模型的id作为训练目标训练对初始的选择器进行训练,以得到选择器。
63、在第十一方面的一种可能实现方式中,选择器为n个自编码器,n个自编码器与云侧服务器中存储的n个任务模型一一绑定,n为大于1的正整数,云侧服务器,还用于以云侧服务器的管理域的本地业务数据中具有相同标签的业务数据为训练数据,对一个初始的自编码器进行训练,以获取一个自编码器,任意两个自编码器的训练数据的标签不同。
64、在第十一方面的一种可能实现方式中,第一边侧服务器的管理域中的任意一个第一客户端设备,还用于获取目标信息,目标信息用于指示第一边侧服务器的管理域的全部业务数据中不同标签的业务数据的占比;根据目标信息和不同标签的业务数据在第一客户端设备的全部业务数据中的占比,对第一客户端设备的全部业务数据进行采样,以获取第一客户端设备的本地业务数据,不同的第一客户端设备的本地业务数据用于获取第一边侧服务器的管理域的本地业务数据。
65、在本技术中,上述任一种装置的名字对设备或功能模块本身不构成限定,在实际实现中,这些设备或功能模块可以以其他名称出现。只要各个设备或功能模块的功能和本技术类似,属于本技术权利要求及其等同技术的范围之内。
- 还没有人留言评论。精彩留言会获得点赞!