一种基于MPICH+OPENMP的国产化并行计算架构和方法与流程
一种基于mpich+openmp的国产化并行计算架构和方法
技术领域
1.本发明属于并行计算领域,具体涉及一种基于mpich+openmp的国产化并行计算架构和方法。
背景技术:
2.1986至2002年,微处理器的性能以平均每年50%的速度快速增长。自2002年开始性能提升速度下降到了20%。近年来,由于用空气冷却集成电路的散热能力到达极限,时钟频率的上限使得单个处理器的速度提升非常有限。处理器多核心的方向发展成为大部分主流cpu制造商的选择。
3.传统串行计算程序不能充分的利用多个处理器核心。因此需要编写专门的计算程序可以使每个处理器核心的算力被充分利用。
4.自棱镜门后,国家加大了对国产cpu产业加大了支持力度,中科龙芯、天津飞腾等国产cpu企业都有了长足的进步。由于国家对信息安全问题的逐步重视,对国产化的要求越来越高。因此需要对国产化平台进行软件适配。传统mpi并行稳定性与灵活性差,而openmp只支持单一计算节点。
技术实现要素:
5.(一)要解决的技术问题
6.本发明要解决的技术问题是如何提供一种基于mpich+openmp的国产化并行计算架构和方法,以解决传统mpi并行稳定性与灵活性差,而openmp只支持单一计算节点的问题。
7.(二)技术方案
8.为了解决上述技术问题,本发明提出一种基于mpich+openmp的国产化并行计算架构,该架构包括上位机客户端与并行计算节点;
9.上位机客户端包括qt图形界面模块和网络通信模块,用于与并行计算节点进行通讯,运行计算任务,通过向并行计算节点请求计算服务,获得计算结果,通过图形界面显示计算结果;
10.其中,qt图形界面模块实现了计算结果、计算时间、连接情况的图形化显示;
11.网络通信模块用于实现udp通信客户端的搭建,以及消息的打包、解包和转发;
12.并行计算节点包括多台国产并行计算节点,其中包括主计算节点与分支计算节点,每个计算节点包括网络服务器端、mpi粗粒并行计算模块、openmp细粒并行计算模块以及算法模块;用于接收计算服务、统计算力、计算工作分配、执行具体算法以及汇集计算结果;
13.网络服务器端实现了udp通信服务器端的搭建,与udp通信客户端建立通信,实现消息的打包、解包和转发;
14.mpi粗粒并行计算模块,用于区分主计算节点与分支计算节点,统计并行计算节点
的总数量,实现分支计算节点、主计算节点在并行计算时的通信与同步;
15.openmp细粒并行计算模块用于统计本节点cpu核数量,设置细粒并行计算使用的线程数量,将多组算法根据线程数量进行分组,由细粒并行计算线程实现细粒并行;
16.算法模块用于执行并行计算使用的算法,被openmp细粒并行计算线程调用执行,通过接口与细粒并行线程进行交互。
17.进一步地,各计算节点通过mpi并行网络通信。
18.进一步地,上行接口和下行接口使用不同的网络端口。
19.进一步地,计算请求包括算法类型目标数和坐标数据,计算结果包括结果数据及计算消耗的时间。
20.进一步地,所述计算节点采用飞腾2000+arm架构cpu、龙芯mpis架构cpu或intel/amdx86架构cpu,运行于支持mpich3.4.2、gcc9.2.0的国产linux操作系统。
21.进一步地,客户端可运行于windows或支持qt13.4以上的linux操作系统。
22.本发明还提供一种基于mpich+openmp的国产化并行计算方法,该方法包括如下步骤:
23.s11、并行计算节点通过接口接收来自客户端的计算请求;
24.s12、计算请求经转译发送给主计算节点,主计算节点根据请求实现并行计算节点间的mpi粗粒并行散播,将计算任务给各分支计算节点;
25.s13、各分支计算节点节点根据计算任务与节点硬件资源,分配并行任务执行openmp细粒并行计算;
26.s14、细粒并行计算结果经由mpi粗粒并行汇集到主计算节点;
27.s15、主计算节点经由上行接口将计算结果发送到客户端,客户端显示计算结果。
28.进一步地,在步骤s11之前还包括如下步骤:
29.s21、在所有节点安装银河麒麟操作系统;
30.s22、在所有节点安装gcc9.2.0编译器、openssh1.0.2和ssh-askpass;
31.s23、在所有节点配置ssh免密登录并在hosts文件中设置计算节点ip;
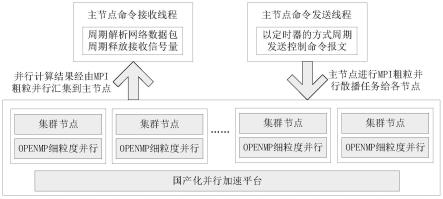
32.s24、在所有节点编译mpich并行计算环境;
33.s25、在所有节点使用mpich混合编译计算框架与算法代码。
34.本发明还提供一种基于mpich+openmp的国产化并行计算方法,该方法包括如下步骤:
35.s31、各计算节点系统启动初始化并行环境,统计计算节点数与计算节点计算资源;
36.其中,具体包括:对mpi、openmp并行环境的初始化,国产化平台服务器端并行计算缓冲区的初始化,统计并行计算节点数量和cpu内核的数量,基础变量初始化;
37.s32、并行计算主节点建立网络服务器线程,等待客户端发出的计算请求
38.并行计算主计算节点建立udp服务器等待来自客户端的消息,收到有效消息后重新打包转发到mpi并行计算的主线程;
39.s33、根据收到计算请求生成计算命令,之后散播到各分支计算节点
40.主计算节点根据收到的计算请求和节点数,生成计算命令散播到所有分支计算节点;计算命令目标数量的分配原则是基于节点数量与各节点cpu可以使用核的数量;计算命
令通过mpi并行网络散播到各分支计算节点;
41.s34、各分支计算节点接收到散播的命令后,开始调用算法执行细粒并行计算
42.各分支计算节点在接收到散播的计算命令后,根据cpu可用核数量设置openmp并行线程数量,并拆分根据线程数量拆分计算命令,根据计算命令调用需要做并行的算法生成循环后,使用openmp并行执行算法循环并将结果转存到国产化平台服务器端的缓冲区;每个可用的cpu内核执行并行拆分后的计算命令;
43.s35、汇集计算结果
44.利用mpi汇集操作将各分支计算节点的计算结果汇集到主计算节点的缓冲区;
45.s36、发送计算结果
46.主计算节点将缓冲区中的计算结果转为计算结果消息经上行接口发往客户端,客户端显示计算结果与计算时间。
47.进一步地,在步骤s31之前还包括如下步骤:
48.s21、在所有节点安装银河麒麟操作系统;
49.s22、在所有节点安装gcc9.2.0编译器、openssh1.0.2和ssh-askpass;
50.s23、在所有节点配置ssh免密登录并在hosts文件中设置计算节点ip;
51.s24、在所有节点编译mpich并行计算环境;
52.s25、在所有节点使用mpich混合编译计算框架与算法代码。
53.(三)有益效果
54.本发明提出一种基于mpich+openmp的国产化并行计算架构和方法,本发明基于mpi与openmp并行架构,可快速部署在银河麒麟、中标等国产操作系统、基于飞腾2000+arm架构cpu和龙芯mpis架构cpu等硬件平台上。客户端与并行计算主计算节点基于协议通信。该协议主要工作于udp协议之上。并行计算节点基于mpi并行计算协议直接通信,cpu核之间基于openmp并行计算协议通信。本发明可以根据并行计算节点系统资源自动调整并行线程数量实现分配并行线程实现算力的最大化利用,相比传统mpi并行拥有更好的稳定性与灵活性,同时弥补了openmp只支持单一计算节点的缺点。
附图说明
55.图1为本发明基于国产化高效能并行计算混合架构模型;
56.图2为基于mpich+openmp的国产化并行计算架构流程图;
57.图3为国产化高效能并行计算模块说明;
58.图4为国产化平台下并行架构算法及服务层级结构。
具体实施方式
59.为使本发明的目的、内容和优点更加清楚,下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。
60.本发明涉及一种基于mpich+openmp的国产化并行计算架构和方法,本发明基于mpich+openmp混合架构构建,通过实现对于计算算法的混合并行加速达到提高计算效率的效果。基于mpich并行架构的粗粒并行实现节点间的并行计算,包含节点间的任务分发,数据汇集同步等功能。基于openmp并行架构的细粒并行计算实现节点内部cpu核之间的算法
层面的并行计算。并行加速平台可灵活应用于飞腾、龙芯等国产硬件平台,中标麒麟、银河麒麟等国产操作系统。
61.本发明要解决的技术问题是如何在国产化平台实现对算法的并行计算加速。实现对多个节点处理器核心算力的利用最大化。
62.为了解决上述技术问题,本发明提出一种基于mpich+openmp的国产化并行计算架构,该架构分为两大部分,包括上位机客户端与并行计算节点;
63.上位机客户端包括qt图形界面模块和网络通信模块,用于与并行计算节点进行通讯,运行计算任务,通过向并行计算节点请求计算服务,获得计算结果,通过图形界面显示计算结果;
64.其中,qt图形界面模块实现了计算结果、计算时间、连接情况的图形化显示;
65.网络通信模块用于实现udp通信客户端的搭建,以及消息的打包、解包和转发;
66.并行计算节点包括多台国产并行计算节点,其中包括主计算节点与分支计算节点,每个计算节点包括网络服务器端、mpi粗粒并行计算模块、openmp细粒并行计算模块以及算法模块。用于接收计算服务、统计算力、计算工作分配、执行具体算法以及汇集计算结果;
67.网络服务器端实现了udp通信服务器端的搭建,与udp通信客户端建立通信,实现消息的打包、解包和转发;
68.mpi粗粒并行计算模块,用于区分主计算节点与分支计算节点,统计并行计算节点的总数量,实现分支计算节点、主计算节点在并行计算时的通信与同步;其中,各计算节点通过mpi并行网络通信。
69.openmp细粒并行计算模块用于统计本节点cpu核数量,设置细粒并行计算使用的线程数量,将多组算法根据线程数量进行分组,由细粒并行计算线程实现细粒并行;
70.算法模块用于执行并行计算使用的算法,被openmp细粒并行计算线程调用执行,通过接口与细粒并行线程进行交互。
71.本发明的基于mpich+openmp的国产化并行计算架构的构建方法,包括如下步骤:
72.s11、并行计算节点通过接口接收来自客户端的计算请求;
73.s12、计算请求经转译发送给主计算节点,主计算节点根据请求实现并行计算节点间的mpi粗粒并行散播,将计算任务给各分支计算节点;
74.s13、各分支计算节点节点根据计算任务与节点硬件资源,分配并行任务执行openmp细粒并行计算;
75.s14、细粒并行计算结果经由mpi粗粒并行汇集到主计算节点;
76.s15、主计算节点经由上行接口将计算结果发送到客户端,客户端显示计算结果。
77.为使本发明的目的、内容和优点更加清楚,下面结合附图1-4,对本发明的具体实施方式作进一步详细描述。
78.本发明的目的是提出一种基于mpich+openmp的国产化并行计算架构,该架构基于mpi并行计算框架与openmp并行计算框架,该架构基于银河麒麟、中标麒麟国产linux操作系统,支持对c/c++编写的算法实现分组并行加速。按框架要求编写算法就可以在不同的国产平台实现快速部署。
79.本发明的基于mpich+openmp的国产化并行计算架构包括两大部分:上位机客户端
与并行计算节点;
80.上位机客户端包括qt图形界面模块和网络通信模块,用于与并行计算节点进行通讯,运行计算任务,通过向并行计算节点请求计算服务,获得计算结果,通过图形界面显示计算结果。
81.其中,qt图形界面模块实现了计算结果、计算时间、连接情况的图形化显示。
82.网络通信模块用于实现udp通信客户端的搭建,以及消息的打包、解包和转发。
83.在某个实施例中,网络通信模块用于与并行计算节点的主计算节点服务器端建立udp通信,该模块提供了上行和下行的接口用于与主计算节点服务器端通讯,实现计算请求的发出与计算结果的接收。
84.其中,上下行接口使用不同的网络端口。
85.其中,计算请求包括算法类型目标数、坐标数据等计算所需的内容。计算结果包括结果数据及计算消耗的时间。
86.客户端可以同时实现与多个并行计算节点进行通信,不同节点使用不同网络端口。客户端可运行于windows或支持qt13.4以上的linux操作系统。
87.并行计算节点包括主计算节点与分支计算节点。从模块划分的角度讲每个计算节点包括网络服务器端、mpi粗粒并行计算模块、openmp细粒并行计算模块以及算法模块。每个计算节点还包括mpich、openmp并行环境。
88.网络服务器端实现了udp通信服务器端的搭建,提供上行和下行的接口,与udp通信客户端建立通信,实现消息的打包、解包和转发。上下行接口使用不同的网络端口,网络发送及网络接收接口可实现计算请求的发出与计算结果的接收。计算请求可包含算法类型目标数、坐标数据等计算所需的内容。计算结果包含结果数据及计算消耗的时间,其结果由发送线程发送给上位机客户端。服务器端同时只能为一个客户端提供服务。
89.mpi粗粒并行计算模块,用于区分主计算节点与分支计算节点,统计并行计算节点的总数量,实现分支计算节点、主计算节点在并行计算时的通信与同步。其中,各计算节点通过mpi并行网络通信。
90.openmp细粒并行计算模块用于统计本节点cpu核数量,设置细粒并行计算使用的线程数量,将多组算法根据线程数量进行分组,由细粒并行计算线程实现细粒并行。
91.算法模块用于执行并行计算使用的算法,被openmp细粒并行计算线程调用执行,通过接口与细粒并行线程进行交互。
92.计算节点支持采用飞腾2000+arm架构cpu、龙芯mpis架构cpu,以及intel/amdx86架构cpu。可运行于支持mpich3.4.2、gcc9.2.0的国产linux操作系统。
93.下面以目标飞行器波动性双节点并行计算在国产平台的部署为例说明并行框架部署流程。硬件平台为国产飞腾2000+64核cpu16gb内存64gb固态硬盘。
94.s21、在所有节点安装银河麒麟v4操作系统;
95.s22、在所有节点安装gcc9.2.0编译器、openssh1.0.2和ssh-askpass;
96.s23、在所有节点配置ssh免密登录并在hosts文件中设置计算节点ip;
97.s24、在所有节点编译mpich并行计算环境;
98.s25、在所有节点使用mpich混合编译计算框架与算法代码。
99.以目标飞行器波动性双节点并行计算为例说明并行框架计算流程。
100.s31、各计算节点系统启动初始化并行环境,统计计算节点数与计算节点计算资源
101.其中,包含对mpi、openmp并行环境的初始化,国产化平台服务器端并行计算缓冲区的初始化,统计并行计算节点数量和cpu内核的数量,基础变量初始化。
102.s32、并行计算主节点建立网络服务器线程,等待客户端发出的计算请求
103.并行计算主计算节点建立udp服务器等待来自客户端的消息,收到有效消息后重新打包转发到mpi并行计算的主线程。
104.s33、根据收到计算请求生成计算命令,之后散播到各分支计算节点
105.主计算节点根据收到的计算请求和节点数,生成计算命令散播到所有分支计算节点。计算命令目标数量的分配原则是基于节点数量与各节点cpu可以使用核的数量。计算命令通过mpi并行网络散播到各分支计算节点。
106.s34、各分支计算节点接收到散播的命令后,开始调用算法执行细粒并行计算
107.各分支计算节点在接收到散播的计算命令后,根据cpu可用核数量设置openmp并行线程数量,并拆分根据线程数量拆分计算命令,根据计算命令调用需要做并行的算法生成循环后,使用openmp并行执行算法循环并将结果转存到国产化平台服务器端的缓冲区。每个可用的cpu内核执行并行拆分后的计算命令。通常一个cpu内核会运行一个线程。
108.s35、汇集计算结果
109.利用mpi汇集操作将各分支计算节点的计算结果汇集到主计算节点的缓冲区。
110.s36、发送计算结果
111.主计算节点将缓冲区中的计算结果转为计算结果消息经上行接口发往客户端,客户端显示计算结果与计算时间。
112.至此并行计算节点侧的计算流程全部完成,客户端在下行接口接收到计算结果后显示计算结果与计算时间。
113.本发明发明基于mpi与openmp并行加速框架,支持mpich3.4.2,支持对arm/mpis/x86平台下的快捷部署,支持国产化操作系统。优化了对硬件资源的申请、分配及释放,保持了并行算法运行期间资源的动态平衡。
114.本发明提出一种基于mpich+openmp的国产化并行计算架构和方法。本发明基于mpi与openmp并行架构,可快速部署在银河麒麟、中标等国产操作系统、基于飞腾2000+arm架构cpu和龙芯mpis架构cpu等硬件平台上。客户端与并行计算主计算节点基于协议通信。该协议主要工作于udp协议之上。并行计算节点基于mpi并行计算协议直接通信,cpu核之间基于openmp并行计算协议通信。本发明可以根据并行计算节点系统资源自动调整并行线程数量实现分配并行线程实现算力的最大化利用,相比传统mpi并行拥有更好的稳定性与灵活性,同时弥补了openmp只支持单一计算节点的缺点。
115.以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明技术原理的前提下,还可以做出若干改进和变形,这些改进和变形也应视为本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1