一种基于锚框最优聚类的YOLOv5园林异常目标识别方法
一种基于锚框最优聚类的yolov5园林异常目标识别方法
技术领域
1.本发明涉及一种基于锚框最优聚类的yolov5园林异常目标识别方法,属于目标识别和计算机视觉领域。
背景技术:
2.为了保证园林的环境,提高游客的游园体验,需要对园林进行养护管理。但现有的园林管理系统中依靠于人力操作的环节过多。比如针对园林中的垃圾处理,一般由保洁人员对责任区域进行不间断的巡查,对垃圾进行清理,保证园林环境的整洁。但是由于园林的面积较大,要保证园林环境的时刻整洁需要投入大量的人力和物力,为了减少对人力和物力的浪费,现今大部分智慧园林都采用无人机对园林中的情况进行动态的监控,然后利用目标识别等算法对监控信息进行智能分析。随着深度学习在计算机视觉领域的飞速发展,目标识别技术作为计算机视觉领域的一部分也得到了突破性的发展。然而由于无人机采集的图片信息中,垃圾的尺寸与整张图片尺寸相比是非常小的,在标注时,手动标记的框与图片中真实目标之间有一定的差距,但是由于目标很小,此时仍然采用原始聚类方式(即距离由iou进行计算)来聚类锚框,标注时较小的差距会对聚类的结果造成很大的影响,因此识别效果并不好。当锚框过大时会导致将粘连目标识别成一个目标,甚至尺寸相差较大的两个目标发生粘连时,尺寸较小的目标根本不会被识别出来,导致召回率和准确率都比较低。
3.综上所述,如何在现有技术上提出准确的识别园林中的小目标成为了目前业内人士所亟待解决的问题。
技术实现要素:
4.本发明所要解决的技术问题是:提供一种基于锚框最优聚类的yolov5园林异常目标识别方法,解决了现有技术对园林中粘连的垃圾识别召回率和准确率低的问题。
5.本发明为解决上述技术问题采用以下技术方案:
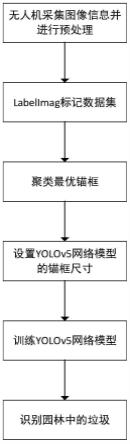
6.一种基于锚框最优聚类的yolov5园林异常目标识别方法,包括如下步骤:
7.步骤1,采集园林垃圾样本图像,并对园林垃圾样本图像进行标注,构建园林垃圾图像数据集;
8.步骤2,利用改进的k-means算法对园林垃圾图像数据集进行锚框聚类,得到最优的9个锚框;
9.步骤3,根据最优的9个锚框设置yolov5网络模型的锚框尺寸,并对 yolov5网络模型进行训练,得到训练好的yolov5网络模型,利用训练好的 yolov5网络模型实现园林垃圾识别。
10.作为本发明的一种优选方案,所述步骤1中,在对园林垃圾样本图像进行标注前,对园林垃圾样本图像进行平移、旋转和滤波预处理,再通过labelimg进行标注。
11.作为本发明的一种优选方案,所述步骤2的具体过程如下:
12.步骤2.1,对园林垃圾图像数据集中的每张图像进行去背景操作;
13.步骤2.2,对于去背景后的任意一张图像qm,根据以下公式找到图像的第一个聚类中心:
[0014][0015]
其中,p表示去除背景后,图像中的所有像素点的个数;hi表示第i个像素点pi的色调分量值;表示去背景操作前,对每张图像转换颜色空间后得到的图像中所有像素点的色调分量的平均值;
[0016]
步骤2.3,找到下一个聚类中心,具体如下:
[0017]
计算图像qm中每个像素点pi到目前已选出来的所有聚类中心的最短多维融合距离,计算公式如下:
[0018][0019][0020]
其中,d(pi)表示像素点pi到目前已选出来所有的聚类中心的最短多维融合距离,dk(pi)表示像素点pi到聚类中心ck的多维融合距离,k表示目前已选出来的所有聚类中心个数;hi、hk分别表示像素点pi的色调分量、聚类中心ck的色调分量,(xi,yi)表示像素点pi相对于整个图像的坐标,(xk,yk)表示聚类中心ck相对于整个图像的坐标,整个图像以左上角为坐标原点,宽为x轴,长为y轴,一个像素为一个单位;
[0021]
计算每个像素点pi成为下一个聚类中心的概率,其概率用p(pi)表示,计算公式如下:
[0022][0023]
按照概率的大小决定其概率范围的大小,并将所有的概率范围随机依次分布到0-1之间,在0-1范围内产生一个随机数,选取随机数所在的概率范围对应的像素点作为下一个聚类中心;
[0024]
步骤2.4,根据基于聚类评价系数的迭代终止条件判断是否需要选取新的聚类中心,如果需要则重复步骤2.3;
[0025]
定义聚类评价系数f,根据聚类评价系数来决定聚类中心的个数,聚类评价系数的公式如下:
[0026][0027][0028][0029]
其中,f(k)表示目前已选出k个聚类中心时的聚类评价系数;μk表示每个像素点pi到当前已有聚类中心之间的最短多维融合距离的均值;表示每个像素点pi到当前已有聚类中心之间的最短多维融合距离的方差;
[0030]
基于聚类评价系数的迭代终止条件分为以下三种情况:
[0031]
情况1,按照步骤2.3的过程增加一个聚类中心,增加后的聚类中心个数为k+1,增加后的聚类评价系数为f(k+1),增加后像素的聚合程度增加,说明增加后聚类效果更好,当增加的程度超过ε,即f(k)-f(k+1)≥ε时,需要继续增加,其中,ε为大于0的阈值;
[0032]
情况2,按照步骤2.3的过程增加一个聚类中心,增加后的聚类中心个数为 k+1,增加后的聚类评价系数为f(k+1),当增加后像素的聚合程度增加范围在 (0,ε)之间,即0<f(k)-f(k+1)<ε时,停止增加,最终的聚类中心个数为k+1;
[0033]
情况3,按照步骤2.3的过程增加一个聚类中心,增加后的聚类中心个数为 k+1,增加后的聚类评价系数为f(k+1),当f(k)-f(k+1)<0时,停止增加,最终的聚类中心个数为k;
[0034]
步骤2.5,找到所有的聚类中心后,计算图像中某像素点到各个聚类中心的多维融合距离,将该像素点分到最短多维融合距离所对应的聚类中心的类别中;
[0035]
步骤2.6,对于新增加像素点的类别重新计算聚类中心,具体为:设园林垃圾图像数据集s中最大垃圾标记的尺寸为w
max
、l
max
,则其对角线长度为新增加像素点的类别的聚类中心当前为c,若新增加的像素点到当前聚类中心c的欧氏距离大于r
max
,则更新后的聚类中心仍为c,若新增加的像素点到当前聚类中心的欧氏距离小于r
max
,则更新后的聚类中心为则更新后的聚类中心为分别为该类别中所有像素点横坐标与纵坐标的平均值,公式如下:
[0036][0037]
其中,n表示该类别当前像素点的个数,xn、yn分别为该类别中第n个像素点的横、纵坐标值;
[0038]
步骤2.7,重复步骤2.5和2.6,直到聚类中心的位置不再发生变化;
[0039]
步骤2.8,根据每个类别中所有像素点的坐标最值x
min
、x
max
、y
min
、y
max
,确定锚框的上下左右四个边界,得到锚框;
[0040]
步骤2.9,对去背景后的数据集q中每张图像进行步骤2.2到2.8操作,得到所有的锚框;
[0041]
步骤2.10,根据基于0-1模型的多帧锚框最优选择,得到最优的9个锚框。
[0042]
作为本发明的一种优选方案,所述步骤2.1的具体过程如下:
[0043]
将园林垃圾图像数据集s={s1,s2,...,sm}中每张图像sm的rgb三个颜色分量转换成hsv三个颜色分量,得到转换颜色空间后的图像,计算每张转换颜色空间后的图像中所有像素点的色调分量的平均值将转换颜色空间后的图像与掩膜进行运算得到感兴趣区域,即提取转换颜色空间后的图像中色调分量在范围之外的像素点,得到去背景后的数据集q={q1,q2,...,qm}, m=1,
…
,m,m为园林垃圾图像数据集中的图像数量。
[0044]
作为本发明的一种优选方案,所述步骤2.10的具体过程如下:
[0045]
将去背景后的数据集q中所有图像得到的锚框排列成一个集合 e={e1,e2,...,e
t
},e
t
表示第t个锚框,t表示所有锚框数量,以每个锚框为单位,以每个锚框的左上角为原点,向下为y轴,向右为x轴建立坐标系,得到框内所有聚类像素点的坐标;根据框内像素点的聚合度与锚框面积大小的均匀度建立 0-1模型求得要选择的最优锚框,0-1模型的公式
如下:
[0046][0047][0048]
其中,s
t
表示第t个锚框的面积大小;a
t
只有0、1两种取值;γ表示调节系数;d
t
表示第t个锚框的框内所有聚类像素点到锚框中心点的距离,其公式如下式所示:
[0049][0050][0051][0052]
其中,(xj,yj)、(xc,yc)分别表示锚框内第j个像素点的坐标和锚框中心点的坐标;l
t
和w
t
表示第t个锚框的长和宽;l表示锚框内所有聚类像素点的个数。
[0053]
本发明采用以上技术方案与现有技术相比,具有以下技术效果:
[0054]
1、本发明针对园林场景背景单一的特点,去除多余背景,减少迭代,提高聚类速度。
[0055]
2、本发明提出最优聚类方法,聚类yolov5模型的锚框尺寸,提高垃圾识别的准确率和召回率。
[0056]
3、本发明方法能够在智慧园林场景中将无人机拍摄的视频和图片信息中的垃圾精准的识别出来,大大减轻了园林中人力和物力的投入,减少了人工巡检的工作。
附图说明
[0057]
图1是本发明基于锚框最优聚类的yolov5园林异常目标识别方法的流程图;
[0058]
图2是yolov5-s网络结构图。
具体实施方式
[0059]
下面详细描述本发明的实施方式,所述实施方式的示例在附图中示出。下面通过参考附图描述的实施方式是示例性的,仅用于解释本发明,而不能解释为对本发明的限制。
[0060]
本发明提出的基于锚框最优聚类的yolov5园林异常目标识别方法流程图如图1所示,具体过程如下:
[0061]
步骤1、通过无人机采集园林垃圾样本图像,并对园林垃圾样本图像进行标注,构建园林垃圾图像数据集;
[0062]
步骤1中还包括在对数据集标记前,对数据集中图像进行平移、旋转、滤波等预处理;然后通过labelimag标记数据集。
[0063]
步骤2、利用改进的k-means算法对园林垃圾数据集进行锚框聚类;具体如下:
[0064]
(1)去除背景。在聚类之前首先对数据集中每张图片进行去除背景操作,将数据集s={s1,s2,...,sm}中每个图片的rgb三个颜色分量转换成hsv三个颜色分量,然后计算每个图像中的所有像素点的色调分量(h)的平均值数据集中图片的大小为w
p
×
l
p
;将转换颜色空间后的图像与掩模进行运算得到感兴趣区域,提取图片中像素的h分量在范围之外的像素点,得到处理后的数据集q={q1,q2,...,qm};
[0065]
(2)选取首个聚类中心。选取图片的第一个聚类中心点c1,该聚类中心由以下公式计算得到:
[0066][0067]
其中,p表示去除背景后,图片中的所有像素点的个数;hi表示第i个像素点的h分量值。
[0068]
(3)找到下一个聚类中心。计算图片中每个像素点pi到目前已经选出来的所有聚类中心的最短多维融合距离,计算公式如下:
[0069][0070][0071]
其中,用d(pi)表示图片中像素点pi到目前已经选出来所有的聚类中心的最短多维融合距离,k表示现在已有的聚类中心点个数。dk(pi)表示像素点pi到聚类中心ck的多维融合距离,hi,hk分别表示像素点pi的色调h分量、聚类中心 ck的色调h分量,(xi,yi),(xk,yk)分别表示像素点pi相对于整个图像的坐标,聚类中心ck相对于整个图像的坐标,整个图片以左上角为坐标原点,宽为x轴,长为y轴,一个像素为一个单位。
[0072]
根据图片中所有像素点的最短多维融合距离计算每个像素点成为下个聚类中心的概率,其概率用p(pi)表示,计算公式如下:
[0073][0074]
按照概率的大小决定概率范围的大小,并将其随机依次分布到0-1之间,然后在0-1范围内产生一个随机数,随机数落在哪个概率范围内,就选取该概率所对应的像素点作为新的聚类中心。
[0075]
(4)根据基于聚类系数的迭代终止条件进行判断,是否需要选取新的聚类中心,则重复(3),根据条件找到所有的聚类中心点,基于聚类系数的迭代终止条件如下:
[0076]
定义一种聚类评价系数f,根据聚类评价系数来决定聚类中心的个数。聚类中心评价系数的公式如下:
[0077][0078][0079]
[0080]
其中,f(k)表示当有k个聚类中心时的聚类评价系数;μk表示每个像素点 pi到当前已有聚类中心之间的最短多维融合距离的均值;表示每个像素点pi到当前已有聚类中心之间的最短多维融合距离的方差;当均值和方差越小的时候说明像素点的聚合度越高,聚类效果越好。
[0081]
据聚类中心评价系数提出一种基于聚类系数的迭代终止条件,根据聚类的效果,确定聚类中心的个数。迭代终止条件分为以下三种情况:
[0082]
1)按本发明提出的基于k-means的锚框最优聚类方法增加一个聚类中心,增加后的聚类中心个数为k+1,增加后像素的聚合程度增加,说明增加后聚类效果更好,当增加的程度超过ε时,说明需要继续迭代,其中,ε为大于0的阈值。
[0083]
f(k)-f(k+1)≥ε
[0084]
2)按本发明提出的基于k-means的锚框最优聚类方法增加一个聚类中心,增加后的聚类中心个数为k+1,增加后像素的聚合程度有增加但是增加的程度不大,即增加的范围在(0,ε)之间时,说明即使继续增加聚类中心,聚类效果也不会变化特别大。此时停止迭代,聚类中心个数为k+1。
[0085]
0<f(k)-f(k+1)<ε
[0086]
3)按本发明提出的基于k-means的锚框最优聚类方法增加一个聚类中心,增加后的聚类中心个数为k+1,增加后像素点的聚合程度反而减小,聚类的效果变差。则说明当有k个聚类中心时,像素点的聚合程度已经达到最好的效果。则在聚类中心为k个时停止迭代,聚类中心的个数为k。
[0087]
f(k)-f(k+1)<0
[0088]
(5)找到所有的聚类中心后,计算图像中每个像素点到各个聚类中心的多维融合距离,将该像素点分到最短多维融合距离所对应的聚类中心的类别中。
[0089]
(6)针对每个类别重新计算它的聚类中心。计算方法:设数据集s中最大垃圾标记的尺寸为w
max
、l
max
,则其对角线为若当前分到该类聚类中心c的像素点到当前聚类中心的欧氏距离大于r
max
,则更新后的聚类中心仍为c。若当前分到该类聚类中心c的像素点到当前聚类中心的欧氏距离小于r
max
,则更新后的聚类中心为,则更新后的聚类中心为分别为该类别当前像素点横坐标与纵坐标的平均值,公式如下:
[0090][0091][0092]
其中,n表示某类别当前像素点的个数。
[0093]
(7)重复(5)和(6)直到聚类中心的位置不再发生变化。
[0094]
(8)根据每个类别中所有像素点的坐标最值x
min
、x
max
、y
min
、y
max
确定框的上下左右四个边界,得到锚框。
[0095]
(9)对数据集q中每张图片进行(2)到(8)操作,得到所有的锚框。
[0096]
(10)根据基于0-1模型的多帧锚框最优选择,得到最优的9个锚框。基于 0-1模型的多帧锚框最优选择步骤如下:
[0097]
每张图片中选取的锚框个数不同,在建立0-1模型之前先进行数据处理。首先把所有图片选取的锚框排列成一个集合e={e1,e2,...,e
t
},然后以每个锚框为单位,以每个锚框的左上角为原点,向下为y轴,向右为x轴建立坐标系,得到框内所有聚类像素点的坐标。根据框内像素点的聚合度与锚框面积大小的均匀度建立0-1模型求得要选择的最优锚框。0-1模型的公式如下:
[0098][0099][0100][0101][0102][0103]
其中,d
t
表示第t个锚框的框内所有聚类像素点到锚框中心点的距离; (xj,yj)、(xc,yc)分别表示锚框内第i个像素点的坐标和锚框中心点坐标;l
t
和w
t
表示第t个锚框的长和宽;s
t
表示第t个锚框的面积大小;γ表示调节系数;a
t
只有0、1两种取值;l表示锚框内所有像素点。
[0104]
步骤3、根据聚类结果设置yolov5模型的锚框尺寸,训练网络模型,进行园林垃圾识别。
[0105]
设置yolov5网络模型的锚框尺寸,训练网络模型,yolov5有四种量级的网络结构,分别是yolov5-s、yolov5-m、yolov5-l和yolov5-x。yolov5-s 是四种结构中网络深度最浅且训练速度最快的网络,其他结构的网络层数依次增加。所以本发明选取yolov5-s进行训练,网络结构模型图如图2所示。
[0106]
以上实施例仅为说明本发明的技术思想,不能以此限定本发明的保护范围,凡是按照本发明提出的技术思想,在技术方案基础上所做的任何改动,均落入本发明保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1