一种基于事件要素交互与标签语义增强的事件论元抽取方法
1.本发明属于信息抽取技术领域,具体涉及一种基于事件要素交互与标签语义增强的事件论元抽取方法。
背景技术:
2.近年来,互联网迅猛发展,我国网民的规模也迅速增长,互联网对人们的生活和社会影响力也日益加深。与传统信息传播媒体相比,网络媒体信息具规模大、传播快、信息丰富、实时性强、参与度高等显著特点。网络媒体每天会产生大量的文本数据,面对日益增长的海量互联网信息,快速定位到公众讨论的具体事件变得至关重要。这不仅可以帮助舆情监管人员快速定位到具体事件,了解事件的具体要素,还可以将事件抽取结果提供给其他自然语言处理任务,以进行更深入的分析和应用。
3.事件论元抽取任务是事件抽取任务的一个关键子任务,由于该任务本身涉及更多要素和特征的交互,较为复杂,并且事件检测研究得到了较为快速的发展,因此近年来事件论元抽取也逐渐成为事件抽取系统性能的瓶颈。在抽取出文本句中的触发词和确定了事件类型的分类之后,事件论元抽取旨在识别出作为事件论元的实体,也即识别出文本中真正参与到事件的实体,并对它们在事件中扮演的角色进行分类。
4.近些年来,事件论元抽取吸引了许多研究学者的关注,取得了一定的进展。早期的研究学者们通常使用基于特征工程的方法,通过手工设计复杂的特征和启发式的规则来抽取事件论元。随着神经网络的发展,越来越多的研究学者们开始使用卷积神经网络和循环神经网络进行事件论元抽取,目的是为了利用神经网络自动提取句子的局部特征或全局序列特征的能力。自2018年以来,预训练语言模型bert因其在自然语言处理多个任务上的出色表现,逐渐进入研究学者们的视野。
5.尽管现有的方法取得了一定的进展,但它们仍然存在一些不足之处,这阻碍了事件论元抽取性能的进一步提升;例如,现有的事件论元抽取方法通常对每个候选论元分开考虑,忽略了论元与论元间的相互关系;现有的事件论元抽取方法忽略了对论元角色的标签语义信息的利用。因此,事件论元抽取技术仍然有许多需要研究的地方,于是本发明设计出一种基于事件要素交互与语义标签增强的事件论元抽取方法。
技术实现要素:
6.发明目的:本发明提供一种基于事件要素交互与标签语义增强的事件论元抽取方法,在事件检测任务已经完成的基础上,使用预训练语言模型bert、词嵌入技术和双向长短期神经网络、transformer模型、注意力机制,对事件论元进行抽取,具有良好的事件论元抽取性能。
7.技术方案:本发明提供一种基于事件要素交互与标签语义增强的事件论元抽取方法,包括以下步骤:
8.(1)对预先获取的数据集文本进行预处理,输出预处理好的文本句和论元角色集
合;
9.(2)采用预训练语言模型bert将文本向量化,输出单词的上下文表示,并同时使用词嵌入技术将论元角色标签向量化;
10.(3)利用双向长短期记忆网络和前馈神经网络识别出候选论元跨度;
11.(4)构建事件要素的跨度表示序列spans={触发词,先验事件类型,候选论元1,
…
,候选论元m},对触发词相关信息与所有候选论元进行联合建模,并借鉴transformer模型的multi-head self-attention机制,同时提取触发词相关信息-论元间的相关关系和论元-论元间的相关关系;
12.(5)设置一个注意力网络层att度量候选论元与论元角色标签之间的相关程度,从而将论元角色的标签语义特征显式地指导论元角色分类。
13.进一步地,所述步骤(1)包括以下步骤:
14.(11)根据预定义的事件本体提取所有论元角色类型,组织得到预处理好的论元角色集合;
15.(12)将数据集文本中的xml文档拆分为一个个文本句;
16.(13)根据xml文档中的标签对应关系,组织得到预处理好的每个文本句。
17.进一步地,所述步骤(2)包括以下步骤:
18.(21)将预处理好的文本句组织成《事件类型,文本句》句子对的形式,具体是{[cls],event_type,[sep],s,[sep]}的形式,其中[cls]和[sep]是特殊符号,event_type代表文本句的事件类型,s代表文本句自身;输入预训练语言模型bert将文本向量化;
[0019]
(22)将预处理好的论元角色集合利用word2vec技术,使用嵌入层embedding将论元角色标签向量化。
[0020]
进一步地,所述步骤(3)包括以下步骤:
[0021]
(31)将已经向量化的文本句输入双向长短期记忆网络bilstm,提取文本句的序列特征,输出经过序列特征提取的单词向量序列;
[0022]
(32)使用两个独立的带有sigmoid激活函数的前馈神经网络ffnn,每个单词表示xi,即bilstm输出的序列上下文特征向量中的第i个,分别经过两个前馈神经网络,然后分别使用sigmoid激活函数,表示为:
[0023]
ps(xi)=sigmoid(ffnns(xi))
[0024]
pe(xi)=sigmoid(ffnne(xi))
[0025]
根据ps(xi)和pe(xi)是否超过预先设定的概率阈值,从而判断该单词是否为候选论元跨度的开始位置或者结束位置,完成二元分类;
[0026]
采取最近的候选论元开始-候选论元结束对匹配原则,构成所有的候选论元跨度;采用二元交叉熵损失loss
start
和loss
end
作为论元跨度二元分类的目标函数,表示为:
[0027]
loss
start
=binarycrossentropy(ys,ps)
[0028]
loss
end
=binarycrossentropy(ye,pe)
[0029]
其中,ys代表文本句s中真实的论元跨度开始位置情况,ys中的1代表该单词是开始位置,0代表不是开始位置;ye代表文本句s中真实的论元跨度结束位置情况,其中1代表该单词是结束位置,0代表不是结束位置;ps和pe分别代表文本句s中各个单词被预测为开始位置和结束位置的概率。
[0030]
进一步地,所述步骤(4)基包括以下步骤:
[0031]
(41)根据候选论元开始-候选论元结束对提供的区间范围,使用经过预训练语言模型bert向量化的文本向量,对触发词、先验事件类型和所有候选论元进行跨度表征;对各个跨度区间范围的词向量使用加和平均;
[0032]
(42)将所有的跨度表示连接起来,得到输入序列spans,输入到transformer模型中;
[0033]
(43)借助于transformer模型的自注意力机制对输入序列spans的语义信息进行特征编码;
[0034]
(44)transformer模型输出论元i的特征表示hi。
[0035]
进一步地,所述步骤(5)包括以下步骤:
[0036]
(51)将论元向量表征和标签嵌入向量表征作为输入;
[0037]
(52)经过计算论元向量表征和标签嵌入向量表的注意力分数,得到该论元特定于每一种论元角色标签的注意力得分;具体来说,对于transformer模型输出的一个论元跨度表征hi,和论元角色标签嵌入表e
l
={l1,l2,
…
,l
|r|
},其中|r|代表论元角色的种类数量;注意力网络att以hi和e
l
为输入,计算hi对每一个标签lj的注意力权重系数αj,表示为:
[0038]
s(lj,hi)=v
t
tanh(wlj+uhi+bj)
[0039][0040]
其中,w和u为可学习的参数矩阵,bj是一个偏置项;模型选择归一化后注意力得分αj最高的类别作为该论元的论元角色;采用交叉熵损失loss
role
作为论元角色分类的目标函数,表示为:
[0041]
loss
role
=crossentropy(yr,pr)
[0042]
其中,yr代表文本句s中真实的论元角色,yr中的1代表该论元扮演了角色,0则代表没有;pr代表文本句s中各个单词被预测为各种论元角色的概率;训练的目标是最小化论元跨度识别的交叉熵损失loss
start
、loss
end
和论元角色分类的交叉熵损失loss
role
的总和;训练过程中使用adamw优化器更新模型的参数,并使用dropout机制防止过拟合。
[0043]
有益效果:与现有技术相比,本发明的有益效果:与传统的方法相比,本发明利用深度学习技术如预训练语言模型、神经网络等充分建模事件要素间的信息交互,并且利用了标签语义帮助论元角色分类,针对于现有基于深度学习的事件论元抽取方法对事件要素交互利用不足和对标签特征挖掘不足,导致抽取性能低的问题,能够有效地提取事件要素间的相关关系语义特征,并且有效地利用论元角色标签语义特征指导论元角色分类过程;本发明是事件论元抽取的有效方法,具有良好的事件论元抽取性能。
附图说明
[0044]
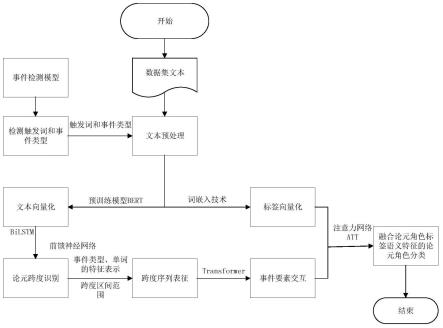
图1是本发明的流程图;
[0045]
图2为本发明中建立的事件论元抽取模型框架示意图;
[0046]
图3为本发明的注意力网络att计算示意图。
具体实施方式
[0047]
下面结合附图对本发明作进一步详细说明。
[0048]
本发明提出一种基于事件要素交互与标签语义增强的事件论元抽取方法,构建了如图2所示的事件论元抽取模型,包括编码模块、论元跨度识别模块、事件要素交互模块和标签语义增强模块;其中编码模块结合预训练语言模型bert将文本向量化,输出单词的上下文表示,并同时使用词嵌入技术将论元角色标签向量化;论元跨度识别模块利用双向长短期记忆网络和前馈神经网络识别出候选论元跨度;事件要素交互模块构建事件要素的跨度表示序列spans={触发词,先验事件类型,候选论元1,
…
,候选论元m},对触发词相关信息与所有候选论元进行联合建模,并借鉴transformer模型的multi-head self-attention机制,同时提取触发词相关信息-论元间的相关关系和论元-论元间的相关关系;标签语义增强模块设置一个注意力网络层att度量候选论元与论元角色标签之间的相关程度,从而将论元角色的标签语义特征显式地指导论元角色分类。如图1所示,具体包括以下步骤:
[0049]
s1:进行数据集文本的预处理,输出预处理好的文本句和论元角色集合。
[0050]
根据预定义的事件本体提取所有论元角色类型,组织得到预处理好的论元角色集合。以ace2005英文语料为例,事件本体中共定义了35种事件论元角色,则1-1预处理得到的论元角色集合是一个长度为35的列表:[attacker,time-at-beginning,seller,victim,
…
,sentence]。
[0051]
将数据集文本中的xml文档拆分为一个个文本句。根据xml文档中的标签对应关系,组织得到预处理好的每个文本句。一个个的文本句例如“british troops control the outskirts ofthe town,and today destroyed another building.”,根据标签对应关系预处理好的文本句将“destroyed”标识出来为触发词,事件类型为“conflict:attack”,标准论元包括:british troops、anotherbuilding和today,扮演的论元角色分别是attacker、target和time-within。
[0052]
s2:结合预训练语言模型bert将文本向量化,输出单词的上下文表示,并同时使用词嵌入技术将论元角色标签向量化,如图2编码模块所示。
[0053]
将预处理好的文本句组织成《事件类型,文本句》句子对的形式,具体是{[cls],event_type,[sep],s,[sep]}的形式,其中[cls]和[sep]是特殊符号,event_type代表文本句的事件类型,s代表文本句自身。输入预训练语言模型bert将文本向量化。以文本句“british troops control the outskirts ofthe town,and today destroyed another building.”为例,输入bert的文本将是{[cls],attack,sep],british,troops,control,the,outskirts,of,the,town,and,today,destroyed,another,building,[sep]}。
[0054]
将预处理好的论元角色集合利用word2vec技术,使用嵌入层embedding将论元角色标签向量化。例如,嵌入层embedding将要向量化的对象是事件本体中定义的35种事件论元角色[attacker,time-at-beginning,seller,victim,
…
,sentence]。
[0055]
s3:利利用双向长短期记忆网络和前馈神经网络识别出候选论元跨度,如图2论元跨度识别模块所示。
[0056]
将已经向量化的文本句输入双向长短期记忆网络bilstm,提取文本句的序列特征,输出经过序列特征提取的单词向量序列。以文本句“british troops control the outskirts ofthe town,and today destroyed anotherbuilding.”为例,经过本步骤得到
经过序列特征提取的单词向量序列为经过序列特征提取的单词向量序列为其中n代表文本句的长度,h
bilstm
代表文本句对应的经过bilstm输出的单词向量序列,h
t
代表文本句中触发词的向量表示,其余的hi(i∈[1,t)∪(t,n])代表文本句除了触发词之外的对应位置的单词向量表示。
[0057]
使用两个独立的带有sigmoid激活函数的前馈神经网络ffnn,每个单词表示xi(即bilstm输出的序列上下文特征向量中的第i个)分别经过两个前馈神经网络,然后分别使用sigmoid激活函数,表示为:
[0058]
ps(xi)=sigmoid(ffnns(xi))
[0059]
pe(xi)=sigmoid(ffnne(xi))
[0060]
最后根据ps(xi)和pe(xi)是否超过预先设定的概率阈值,从而判断该单词是否为候选论元跨度的开始位置或者结束位置,完成二元分类。采取最近的候选论元开始-候选论元结束对匹配原则,构成所有的候选论元跨度。采用二元交叉熵损失loss
start
和loss
end
作为论元跨度二元分类的目标函数,表示为:
[0061]
loss
starf
=binarycrossentropy(ys,ps)
[0062]
loss
end
=binarycrossentropy(ye,pe)
[0063]
其中,ys代表文本句s中真实的论元跨度开始位置情况,ys中的1代表该单词是开始位置,0代表不是开始位置。ye代表文本句s中真实的论元跨度结束位置情况,其中1代表该单词是结束位置,0代表不是结束位置。ps和pe分别代表文本句s中各个单词被预测为开始位置和结束位置的概率。例如,选取概率阈值为sigmoid函数的默认值0.5,候选论元的开始位置列表为(0,10,12),候选论元的结束位置列表为(1,10,13),采取的最近的候选论元开始-候选论元结束对匹配原则,最终得到3个候选论元跨度(0,1),(10,10)和(12,13),分别对应(british,troops),(today),(another building)。
[0064]
s4:构建事件要素的跨度表示序列spans={触发词,先验事件类型,候选论元1,
…
,候选论元m},对触发词相关信息与所有候选论元进行联合建模,并借鉴transformer模型的multi-head self-attention机制,同时提取触发词相关信息-论元间的相关关系和论元-论元间的相关关系,如图2事件要素交互模块所示。
[0065]
根据得到的候选论元开始-候选论元结束对提供的区间范围,使用经过预训练语言模型bert向量化的文本向量,对触发词、先验事件类型和所有候选论元进行跨度表征。对各个跨度区间范围内(区间左闭右闭)的词向量使用加和平均。
[0066]
这里找“候选论元”,是先找到所有合法的start(也就是开始位置)和end(结束位置),然后start和end需要配对,采用的配对原则是“就近配对”,也就是最近的一个start和最近的一个end会形成一个配对,其他的配对也都是按这个原则形成。
[0067]
将所有的跨度表示连接起来,得到输入序列spans,输入到transformer模型中。以文本句“british troops control the outskirts ofthe town,and today destroyed another building.”为例,得到的spans为{b(destroyed),b(attack),avg(b(british)+b(troops)),b(today),avg(b(another)+b(building))},其中b(
·
)代表预训练语言模型bert输出的单词特征表示,avg(
·
)代表加和平均操作。
[0068]
借助于transformer模型的自注意力机制对得到的输入序列spans的语义信息进
行特征编码;transformer模型输出论元i的特征表示hi。以文本句“british troops control the outskirts of the town,and today destroyed another building.”为例,输出三个论元的特征表示,分别是h
britishtroops
,h
today
,h
anotherbuilding
。
[0069]
s5:设置一个注意力网络层att度量候选论元与论元角色标签之间的相关程度,从而将论元角色的标签语义特征显式地指导论元角色分类,如图2标签语义增强模块所示。
[0070]
将论元向量表征和标签嵌入向量表征作为输入;以文本句“british troops control the outskirts of the town,and today destroyed another building.”为例,三个论元的特征表示,分别是h
british troops
,h
today
,h
another building
,以h
british troops
为例,和论元角色标签嵌入表e
l
一起作为输入。
[0071]
经过计算论元向量表征和标签嵌入向量表的注意力分数,得到该论元特定于每一种论元角色标签的注意力得分。具体来说,对于transformer模型输出的一个论元跨度表征hi,和论元角色标签嵌入表e
l
={l1,l2,
…
,l
|r|
},其中|r|代表论元角色的种类数量。如图3所示,注意力网络att以hi和e
l
为输入,计算hi对每一个标签lj的注意力权重系数αj,表示为:
[0072]
s(lj,hi)=v
t
tanh(wlj+uhi+bj)
[0073][0074]
其中,w和u为可学习的参数矩阵,bj是一个偏置项。模型选择归一化后注意力得分αj最高(也即概率最大)的类别作为该论元的论元角色。采用交叉熵损失loss
role
作为论元角色分类的目标函数,表示为:
[0075]
loss
role
=crossentropy(yr,pr)
[0076]
其中,yr代表文本句s中真实的论元角色,yr中的1代表该论元扮演了角色,0则代表没有;pr代表文本句s中各个单词被预测为各种论元角色的概率。
[0077]
训练的目标是最小化论元跨度识别的交叉熵损失loss
start
、loss
end
和论元角色分类的交叉熵损失loss
ro1e
的总和。训练过程中使用adamw优化器更新模型的参数,并使用dropout机制防止过拟合。
[0078]
以文本句“britishtroops control the outskirts of the town,and today destroyed another building.”为例,输出三个论元的特征表示,分别是:h
british troops
,h
today
,h
another bui1ding
,以h
british troops
为例,和论元角色标签嵌入表e1做注意力分数的计算,得到的注意力分数最高的αj是当j为0时,即对应的是attacker这个论元角色标签,因此最终为论元跨度(0,1)分配的论元角色标签为attacker,即“british troops”在这个“conflict:attack”事件实例中扮演的角色是“attacker”。另外,在训练中adamw优化器的学习率为0.00003,dropout率为0.2。
[0079]
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明技术原理的前提下,还可以做出若干改进和变形,这些改进和变形也应视为本发明的保护范围。可将本发明方法编为程序代码,通过计算机存储介质存储该代码,将程序代码传输给处理器,通过处理器执行本发明方法。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1