一种货车组协作控制方法、系统、设备及介质与流程
1.本发明涉及交通控制技术领域,特别涉及一种货车组协作控制方法、系统、设备及介质。
背景技术:
2.物联网在工业运输方面起到了巨大的作用,在公路运输任务中采用的公路货车队列,是一种在不进行大规模基础设施投资、不降低公路行业安全标准的情况下提高线路运力、增加公路网络容量的车辆编排方法,引入了传感器设备和定位模块等工业物联网设备,使得货车组运输速度更快、距离间隔更小,同时能够实现货车自主决策。然而这些特点使其安全性更加关键,工业物联网存在的可靠性、安全性问题在这种场景下更为突出,仅凭现有的技术不足以支持该场景的实际实现,所以设计一种可靠、安全的货车组协作控制性能方法具有很强的现实和理论意义。
3.当前货车组协作控制技术的优化方法主要通过两方面进行实现:一是通信,从有线频谱的合理分配角度,提出多智能深度强化学习的算法理论,从无缝无限的网络覆盖角度,提出“空-天-地”一体化车载网络的架构,以解决货车组间的通信问题;二是控制方面,传统方法包括人工势场法、模糊逻辑法和模拟退火法等等,并采用强化学习的方法,以解决路径规划效率低的问题。然而目前利用人工势场法进行路径规划与运动控制的研究存在易陷入局部最优、难以得到全局最优策略的问题,利用强化学习作为多智能体协作控制手段也存在先验知识不足而训练效率低下的情况,因而会带来更多问题。
技术实现要素:
4.针对现有技术中存在的易陷入局部最优,难以得到全局最优策略的问题,本发明提供一种货车组协作控制方法。
5.为实现上述目的,本发明技术方案如下:
6.第一方面,提供一种货车组协作控制方法,包括如下步骤:获取货车组的实际运行情况;将所述货车组的实际运行情况输入训练好的q网络中;通过所述q网络得到所述货车组执行每个动作对应的价值,并输出价值最高对应的动作。
7.进一步的,所述q网络的训练过程包括以下步骤:
8.根据所述货车组的实际运行情况构建货车组模型;根据人工势场法的控制律,设计所述货车组模型的奖励函数;基于所述货车组模型和奖励函数,并采用经验回放策略,训练所述q网络。
9.进一步的,所述根据所述货车组的实际运行情况构建货车组模型具体包括,采用领航跟随的编队方法,将所述货车组被分为领航者与跟随者。
10.进一步的,所述根据人工势场法的控制律,设计所述货车组模型的奖励函数具体包括:
11.所述人工势场法的控制律为:达到货车运行状态目标给予奖励,训练失败则给予
惩罚;
12.所述人工势场法中包括势力场函数,根据所述势力场函数导数的近似曲线,设计所述奖励函数。
13.进一步的,所述训练所述q网络具体包括:
14.根据所述货车组模型,获取货车组当前状态汇总为状态集,作为训练所述 q网络过程中的初始状态,所述货车组当前状态包括相邻货车的间距和速度差,以货车加速度为动作值,建立动作集;
15.每次训练中,所述货车组车辆相继出发,通过制动所述领航者,记录所述跟随者停车过程的状态变化;
16.对于每次训练,若训练结束时所述跟随者未在货车运行状态目标停止,则根据q网络并基于ε策略,从所述动作集中选择不同时刻运行状态对应的动作,计算得到的奖励与下一状态,所述状态、动作、奖励和下一状态共同构成一个样本。
17.进一步的,所述经验回放策略具体包括:
18.设置经验回放缓冲区,存放所述样本;
19.当经验回放缓冲区内样本数小于训练所需的样本数量时,每次训练使用所有的样本;
20.当经验回放缓冲区被占满时,剔除一个最早的样本,向经验回放缓冲区加入一个样本。
21.进一步的,所述固定q网络具体包括:
22.使用两个参数相同的q网络模型,其中一个设为目标q网络,另一个设为预测q网络;
23.设定损失函数,利用回归训练并更新预测q网络中的参数;
24.将预测q网络的参数赋值给目标q网络。
25.第二方面,提供一种货车组协作控制系统,包括如下模块:
26.初始化模块:用于获取货车组的实际运行情况;
27.输入模块:用于将所述货车组的实际运行情况输入训练好的q网络中;
28.输出模块:用于通过所述q网络得到所述货车组执行每个动作对应的价值,并输出价值最高对应的动作。
29.第三方面,提供一种计算机设备,包括存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,其特征在于,所述处理器执行所述计算机程序时实现上述任一项所述货车组协作控制方法。
30.第四方面,提供一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现上述任一项所述货车组协作控制方法。
31.与现有技术相比,本发明具有如下有益效果:
32.本发明提供的基于apf启发式深度q网络的货车组协作控制性能优化方法,强化学习弥补了apf易陷入局部最优的问题从而找到全局最优策略,而基于apf设计的奖励函数为强化学习提供丰富的先验知识,提高了训练效率,训练过程平均缩短了一个训练周期,鲁棒性更强,如引入外界干扰的情况下终点抵达率至少提高了36%,因而安全性能更佳,更适宜
于工业物联网的货车组运输实际。
附图说明
33.构成本发明的一部分的说明书附图用来提供对本发明的进一步理解,本发明的示意性实施例及其说明用于解释本发明,并不构成对本发明的不当限定。
34.在附图中:
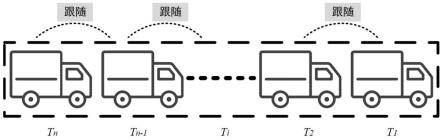
35.图1为本发明一种货车组协作控制方法中基于领航跟随法得到货车组拓扑结构图;
36.图2为本发明一种货车组协作控制方法流程示意图。
具体实施方式
37.下面将参考附图并结合实施例来详细说明本发明。需要说明的是,在不冲突的情况下,本发明中的实施例及实施例中的特征可以相互组合。
38.以下详细说明均是示例性的说明,旨在对本发明提供进一步的详细说明。除非另有指明,本发明所采用的所有技术术语与本发明所属领域的一般技术人员的通常理解的含义相同。本发明所使用的术语仅是为了描述具体实施方式,而并非意图限制根据本发明的示例性实施方式。
39.实施例1
40.如图2所示,q网络模型训练包括三个步骤模块。
41.步骤1,模型构建与算法初始化,确定网络参数,初始化q网络。主要包括下列步骤:
42.步骤11:q网络训练所基于的货车组模型,采用领航跟随的编队方法,货车组被分为领航者与跟随者。领航者起引导作用,利用强化学习方法作为控制手段,使跟随者智能地跟随领航者,以实现两者之间速度的一致和间距的稳定;编队控制则基于人工势场法apf实现,以保证跟随者与领航者间距趋于目标间距,且速度一致,图1为基于领航跟随法得到货车组拓扑结构图;
43.步骤12:基于人工势场法apf的控制律设计奖励函数。人工势场法apf 的控制律为,跟随者越接近运行状态目标获得越多奖励。将势力场函数导数的近似曲线作为奖励函数的设计依据。在本实施例中,设计势力场函数为 ln(cosh(
·
))的形式,因此势力场函数导数为ln(cosh(
·
))=tanh(
·
)的形式。
44.步骤13:将以上理论转化为q网络学习可应用的样本参数,货车的当前状态为sjk=[xijk,vijk],其中xijk为与相邻货车的间距,vijk为与相邻货车的速度差。将n辆货车当前状态集合汇总为状态集,s={s1,s2,...,sn}。由于间距xij 和速度差vij是连续变量,需将其进行分区间离散,将间距与速度差划分为若干区间,则状态数为两者乘积数。在本实施例中,将间距与速度差分别划分为21 和23个区间,则状态数为483。
[0045]
货车加速度为动作值ajk,则a={a1,a2,...,am}为动作集。将动作值进行离散,可取正数、0和负数来分别表示加速、匀速和减速的动作,如 a={a1=0.8,a2=0,a3=-0.8};
[0046]
步骤14:奖励函数基于apf的基本模型设计,其设计原则遵循:达到货车运行状态目标给予固定且较大的奖励,训练失败则给予固定且较大的惩罚,以迫使控制器选择更好的行为。安全状态奖励为正,边缘状态奖励为负,设跟随者每一步获得的奖励值为rj,rj分
别以eij(货车i与货车j的间距误差)和vij (两者速度差)为自变量的reij和rvij两个奖励函数共同决定,为使跟随者在选择动作时尽量使eij逼近0,将vij=
±
0.16给予与vij=0相同的奖励。由于有两种不同自变量的奖励函数,为保证奖励值的合理性,设计负数奖励值优先级高于正数奖励值来平衡两种奖励函数以得到rj;
[0047]
步骤2:经验回放进行训练,以打破样本间的强相关性,提高过去经验利用率,而采用“经验回放”策略;
[0048]
进行步骤2前,需要对训练过程中出现的变量进行定义:
[0049]
episode:训练次数;
[0050]
sjt:训练结束前最后一个状态;
[0051]
step:是δt的计数,每个训练次数episode经过有若干个δt;
[0052]
target:单步q学习的目标;
[0053]
γ:对未来预计奖励的折扣率,取值范围为0-1,数值越大,表示算法对未来预计奖励越敏感;
[0054]
α:表示学习率,取值范围为0-1,决定了对target与当下奖励估计值间误差的学习程度;
[0055]
q(sjk,a):状态与动作对应的值,表示未来按当前策略选择动作所能得到的奖励估计值;
[0056]
ε贪婪策略:设定随机选择动作的概率为ε,1-ε的概率按照q表选择动作,训练过程中ε初始值为0.1,衰减率为0.98,也既每经过一个训练次数episode,ε按照0.98的倍率缩小一次,该设计可以使训练得到的q表具有一定的抗干扰特性;
[0057]
sample batch:训练所需的样本数量;
[0058]
replay buffer:经验回放缓冲区,存储每一个step得到的[sjk,ajk,rjk,sjk+1];
[0059]
所述步骤2具体包括下列步骤:
[0060]
步骤21:开始训练,随机初始化经验回放缓冲区replay buffer为10000,采用三层全连接神经网络,用随机权重初始化q,设定每经过4个step对目标 q网络进行赋值,训练所需的样本数量sample batch大小为140。设定仿真场景为货物装载后,货车组车辆相继出发,即非同时出发。
[0061]
设定episode训练次数为200次,δt为0.2s,领航者与第一辆跟随者初始距离为20m,最大距离为180m,初始速度为0,其最大速度分别为20m/s和 20.32m/s。领航者在第1个step即启动,跟随者在第38个step开始启动,时间为7.4s,考虑跟随者的反应时间,并在第2500个step进行制动,领航者停车时长为200个step即200个δt,以显示跟随者停车过程的状态变化。折扣率γ设为0.2,学习率α设为0.9,ε在每个episode初始值为0.1,衰减率为0.98,最小值为0.01。
[0062]
开始训练,对于每次训练episode:若训练结束时未在货车运行状态目标停止,那么该episode的每个step根据q网络并基于ε策略选择当前的运行状态sjk对应的动作ajk,得到奖励rjk与下一状态sjk+1;
[0063]
步骤22:将当前状态、动作、奖励与下一状态看做一个样本,也既 [sjk,ajk,rjk,sjk+1]存储于经验回放缓冲区replay buffer,当经验回放缓冲区 replay buffer内样本数小于训练所需的样本数量sample batch时,每次训练使用所有的样本;当经验回放缓冲
区replaybuffer被占满时,剔除一个最早的样本,向经验回放缓冲区replaybuffer加入一个样本;
[0064]
步骤23:按照训练所需的样本数量samplebatch从经验回放缓冲区replaybuffer中进行采样;
[0065]
步骤3:使用两个参数相同的q网络模型,其中一个设为目标q网络,另一个设为预测q网络,两者结构相同,权重不同,固定目标q网络,用于提高神经网络稳定性。
[0066]
所述步骤3具体包括下列步骤:
[0067]
步骤31:每次训练结束,结合即时实际奖励与未来奖励估值更新target的目标值,若当前状态不是训练终点状态,target由即时实际奖励与未来奖励估值组成;若到达sjt,由于已经到达终点,没有下一状态,target即为实际奖励;
[0068]
步骤32:以(target-q(s,a))2为损失函数,利用回归训练并更新预测q网络中的参数。
[0069]
步骤33:将训练一定次数的预测q网络,赋值给目标q网络。降低了训练时损失值震荡发散的可能性,从而提高了算法的稳定性。
[0070]
经过上述三个步骤的训练学习之后,形成基于apf启发式深度q网络的货车组协作控制性能优化模型,从而实现对货车组协作控制性能的优化。用训练好的q网络作为智能体货车组实际情况下选择动作的依据,整个训练测试过程即为应用q网络进行自主控制决策的过程。
[0071]
实施例2
[0072]
一种货车组协作控制系统,包括如下模块:
[0073]
初始化模块:用于根据领航跟随的编队方法构建货车组模型,根据相邻货车的间距及速度差,构建货车状态集;
[0074]
输入训练模块:用于将所述货车状态集作为强化学习的状态,并作为神经网络模型的输入,训练神经网络模型;
[0075]
输出模块:用于所述神经网络模型输出每个动作对应的价值,所述价值最高对应的动作即为货车组要执行的动作。
[0076]
实施例3
[0077]
一种计算机设备,包括存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,其特征在于,所述处理器执行所述计算机程序时实现任一项所述货车组协作控制方法。
[0078]
实施例4
[0079]
一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,其特征在于,所述计算机程序被处理器执行时任一项所述货车组协作控制方法。
[0080]
本领域内的技术人员应明白,本技术的实施例可提供为方法、系统、或计算机程序产品。因此,本技术可采用完全硬件实施例、完全软件实施例、或结合软件和硬件方面的实施例的形式。而且,本技术可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器、cd-rom、光学存储器等)上实施的计算机程序产品的形式。
[0081]
本技术是参照根据本技术实施例的方法、设备(系统)、和计算机程序产品的流程
图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和 /或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/ 或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
[0082]
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
[0083]
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
[0084]
由技术常识可知,本发明可以通过其它的不脱离其精神实质或必要特征的实施方案来实现。因此,上述公开的实施方案,就各方面而言,都只是举例说明,并不是仅有的。所有在本发明范围内或在等同于本发明的范围内的改变均被本发明包含。
[0085]
最后应当说明的是:以上实施例仅用以说明本发明的技术方案而非对其限制,尽管参照上述实施例对本发明进行了详细的说明,所属领域的普通技术人员应当理解:依然可以对本发明的具体实施方式进行修改或者等同替换,而未脱离本发明精神和范围的任何修改或者等同替换,其均应涵盖在本发明的权利要求保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1