1.本发明涉及基于改进蜜獾算法结合近红外光谱的阻燃塑料分类方法,属于近红外光谱应用技术领域。
背景技术:2.传统的阻燃塑料分类检测方法为化学分析法,需要对样品进行预处理,由于检测等待时间较长且检测过程使用化学试剂,会对样品造成破坏,浪费样品,造成环境污染,因此急需开发一种可以代替传统检测方法的新型检测方法。
3.近红外光谱检测技术是近年来发展最快的无损检测技术,目前被广泛应用于各种行业,具有检测快速、不需要预处理样品、成本低以及不会对样品产生损害的特性。蜜獾优化算法(hba)作为一种新型群体智能优化算法,主要模拟了自然界中蜜獾捕食蜂蜜的行为,该算法具有参数少、全局搜索性能强、搜索速度快等优点。海洋捕食者优化算法(mpa)是模拟海洋中捕食者的捕食动作而提出的一种智能优化算法,该算法有较强的跳出局部最优能力。支持向量机(svm)是一种基于统计学理论的机器学习方法,在处理非线性和高维度样本的分类问题有广泛的应用。
技术实现要素:4.本发明的目的是提供一种基于改进蜜獾算法结合近红外光谱的阻燃塑料分类方法,能够快速高效地对阻燃塑料的种类进行区分,对于工业规模的阻燃塑料分类有着重要的作用。
5.为了实现上述目的,本发明采用的技术方案是:
6.基于改进蜜獾算法结合近红外光谱的阻燃塑料分类方法,包括以下步骤:
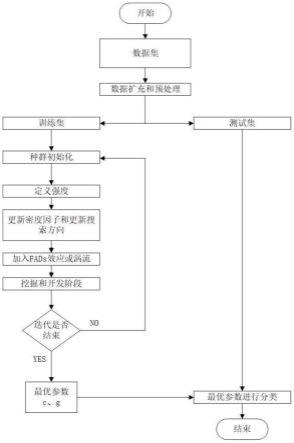
7.步骤1:对阻燃塑料近红外光谱的原始数据集进行预处理,并按照7∶3的比例随机分为训练集和测试集;
8.步骤2:利用svm算法建立阻燃塑料近红外光谱的分类模型;
9.步骤3:利用训练集结合mpa-hba算法优化svm模型的参数c和g;
10.步骤4:选取最优的svm参数构建mpa-hba-svm模型,对测试集数据进行分类并判断分类结果的正确率。
11.本发明技术方案的进一步改进在于:所述步骤1中对阻燃塑料近红外光谱的原始数据集进行预处理为对阻燃塑料近红外光谱的原始数据进行滤波、归一化、标准正态变量变换和基线校正。
12.本发明技术方案的进一步改进在于:所述步骤3具体包括以下步骤:
13.步骤3.1:设定mpa-hba算法模型的种群初始化和mpa-hba算法的寻优上下边界、种群数、迭代次数和选择维度等参数;
14.步骤3.2:定义mpa-hba算法的搜索强度和更新密度因子;
15.步骤3.3:定义mpa-hba算法的搜索方式;
16.步骤3.4:为mpa-hba的搜索过程添加fads效应或涡流效应;
17.步骤3.5:随着迭代次数增多,mpa-hba算法种群会跟随向鸟直达猎物位置;
18.步骤3.6:选取训练样本的分类错误率作为mpa-hba算法的适应度函数来计算每个蜜獾个体的适应度值。
19.本发明技术方案的进一步改进在于:所述步骤3.1具体为:
20.对种群进行初始化,定义种群边界最大值为ub,最小值为lb,种群个数为n,迭代次数为tmax,维度为dim,x为初始化的随机种群样本,初始化公式为:
21.x=rand(n,dim)*(ub-lb)+lb。
22.本发明技术方案的进一步改进在于:所述步骤3.2具体为:
23.定义搜索强度i,d为猎物位置与当前蜜獾位置的距离,s为源强度,xi为种群中第i个个体,r1为0到1的随机数,搜索强度i的公式如下:
[0024][0025]
s=(x
i-x
i+1
)2[0026]ai
=x
best-xi[0027]
定义更新密度因子α,c为一个大于1的常数,α随着迭代次数会发生变化,用来控制勘探和开发阶段的稳定,更新密度因子α的公式如下:
[0028][0029]
本发明技术方案的进一步改进在于:所述步骤3.3搜索方式执行过程的种群中每个个体都执行类心形运动曲线,具体运动公式如下:
[0030]
x
new
=x
best
+f*β*i*x
best
+f*r2*α*di*|cos(2πr3)*[1-cos(2πr4)]|
[0031][0032]
其中,f为方向控制符,可使搜索过程避免陷入局部最优,r2、r3、r4、r5为0到1的随机数,β为大于1的常数,表示搜索算法搜索的能力。
[0033]
本发明技术方案的进一步改进在于:所述步骤3.4添加fads效应或涡流效应的公式为:
[0034][0035][0036]
u=rand(n,dim)<fads
[0037]
r为服从levy飞行的随机向量,x
max
和x
min
为x的最大值和最小值,fads为设定常数取值为0.2,cf为控制移动步长,r6为0到1的随机数。
[0038]
本发明技术方案的进一步改进在于:所述步骤3.5执行的公式为:
[0039]
x
new
=x
best
+f*r7*α*di[0040]
其中r7为0到1的随机数。
[0041]
本发明技术方案的进一步改进在于:所述步骤3.6具体为:
[0042]
使用算法选择的随机数值c和g作为参数对svm中的libsvmtrain函数构建svm分类模型,并用libsvmpredict函数进行预测,算法每次迭代都会生成最优的参数c和g,直至分类正确率达到100%或迭代结束,其中svm算法的惩罚参数c的计算公式和适应度函数计算公式如下:
[0043]
k(x,xi)=exp(-γ||x-xi||2),γ>0
[0044]
fitness=1-acc/100
[0045]
其中,γ为待选取的核函数参数,acc为训练集分类正确率。
[0046]
由于采用了上述技术方案,本发明取得的技术效果有:
[0047]
本发明采用近红外光谱检测技术结合寻优算法和分类算法在阻燃塑料分类检测领域的应用填补了我国在工业上阻燃塑料快速无损检测的空白,具有检测速度快、检测准确率高、相较传统检测无污染等优点。
[0048]
本发明利用svm作为分类算法来对阻燃塑料种类进行分类,其中svm算法的核心参数c和g由改进后的蜜獾优化算法(mpa-hba)来进行优化选择,检测方法准确快速。
附图说明
[0049]
图1是本发明的流程图;
[0050]
图2是原始光谱图;
[0051]
图3是本发明mpa-hba-svm算法对数据的适应度函数图;
[0052]
图4是本发明mpa-hba-svm算法对训练集的分类结果混淆矩阵;
[0053]
图5是本发明mpa-hba-svm算法对测试集的分类结果混淆矩阵。
具体实施方式
[0054]
下面结合附图及具体实施例对本发明做进一步详细说明:
[0055]
基于改进蜜獾算法结合近红外光谱的阻燃塑料分类方法,其总体思路为:
[0056]
将获得的阻燃塑料近红外光谱的原始数据进行sg滤波、标准正态变量变换(snv)和基线校正处理,将处理后的数据集随机选取30%作为测试集数据,剩下的70%作为训练集数据。构建蜜獾优化算法(hba)结合海洋捕食者优化算法(mpa)优化支持向量机(svm)的模型,并将训练样本分类错误率作为权1的mpa-hba算法的适应度函数。
[0057]
基于改进蜜獾算法结合近红外光谱的阻燃塑料分类方法,如图1所示,包括以下步骤:
[0058]
步骤1:采集阻燃塑料的近红外光谱和对阻燃塑料近红外光谱的原始数据集进行预处理,并按照7∶3的比例随机分为训练集和测试集
[0059]
购买pcabs-v0、pp-v1和pp-v2三种阻燃塑料,使用便捷式近红外光谱仪探测每种塑料的近红外光谱,每种样品采集20条近红外光谱,波数范围为12493-4000cm-1
,原始光谱图如图2所示。
[0060]
将获得的阻燃塑料近红外光谱的原始数据进行sg滤波、归一化、标准正态变量变换(snv)和基线校正处理,将处理后的数据集随机选取30%作为测试集数据,剩下的70%作为训练集数据。
[0061]
步骤2:利用svm算法建立阻燃塑料近红外光谱的分类模型
[0062]
利用svm算法中的libsvmtrain函数使用训练集构建svm分类模型,并用libsvmpredict函数进行预测。
[0063]
步骤3:利用训练集结合mpa-hba算法优化svm模型的参数c和g
[0064]
步骤3.1:设定mpa-hba算法模型的种群初始化和mpa-hba算法的寻优上下边界、种群数、迭代次数和选择维度等参数
[0065]
对种群进行初始化,定义种群边界最大值为ub,最小值为lb,种群个数为n,迭代次数为tmax,维度为dim,初始化公式为:
[0066]
x=rand(n,dim)*(ub-lb)+lb
[0067]
x为初始化的随机种群样本。
[0068]
步骤3.2:定义mpa-hba算法的搜索强度和更新密度因子
[0069]
定义搜索强度i,d为猎物位置与当前蜜獾位置的距离,s为源强度,xi为种群中第i个个体,r1为0到1的随机数。
[0070][0071]
s=(x
i-x
i+1
)2[0072]di
=x
best-xi[0073]
定义更新密度因子α,c为一个大于1的常数,α随着迭代次数会发生变化,用来控制勘探和开发阶段的稳定。
[0074][0075]
步骤3.3:定义mpa-hba算法的勘探搜索方式
[0076]
x
new
=x
best
+f*β*i*x
best
+f*r2*α*di*|cos(2πr3)*[1-cos(2πr4)]|
[0077][0078]
其中,f为方向控制符,可使搜索过程避免陷入局部最优,r2、r3、r4、r5为0到1的随机数,β为大于1的常数,表示搜索算法搜索的能力。
[0079]
步骤3.4:为mpa-hba的搜索过程添加fads效应或涡流效应
[0080][0081][0082]
u=rand(n,dim)<fads+
[0083]
r为服从levy飞行的随机向量,x
max
和x
min
为x的最大值和最小值,fads为设定常数取值为0.2,cf为控制移动步长,r6为0到1的随机数。
[0084]
步骤3.5:随着迭代次数增多,mpa-hba算法种群会跟随向鸟直达猎物位置,执行的公式为:
[0085]
x
new
=x
best
+f*r7*α*di[0086]
其中r7为0到1的随机数。
[0087]
步骤3.6:选取训练样本的分类错误率作为mpa-hba算法的适应度函数来计算每个蜜獾个体的适应度值
[0088]
使用算法选择的随机数值c和g作为参数对svm中的libsvmtrain函数构建svm分类模型,并用libsvmpredict函数进行预测。算法每次迭代都会生成最优的参数c和g,直至分类正确率达到100%或迭代结束。其中svm算法的惩罚参数c的计算公式和适应度函数计算公式如下:
[0089]
k(x,xi)=exp(-γ||x-xi||2),γ>0
[0090]
fitness=1-acc/100
[0091]
其中,γ为待选取的核函数参数,acc为训练集分类正确率。
[0092]
适应度函数图如图3所示。
[0093]
步骤4:选取最优的svm参数构建mpa-hba-svm模型,对测试集数据进行分类并判断分类结果的正确率
[0094]
将步骤3.6中每次迭代所选取的最优参数放置于一个数组中,按照参数c所在列数值进行由小到大排列,取第一行参数作为最优参数进行对测试集的分类。经过算法优化后选择的svm的惩罚参数c为0.0472、核函数参数g为0.0012。训练集的准确率为90.4762%,测试集的准确率为83.3333%,训练集分类结果的混淆矩阵如图4所示,测试集分类结果的混淆矩阵如图5所示。