基于多图像协同注意力机制的植物叶片识别系统及方法
1.本发明涉及植物叶片识别技术领域,特别是涉及一种基于多图像协同注意力机制的植物叶片识别系统及方法。
背景技术:
2.植物是地球上生命存在的主要形态之一,是整个地球生态圈非常重要的组成部分,也是人类生产生活中不可或缺的一部分。植物在人类保护环境方面具有基础性作用,广泛应用于工业、营养、医药等领域,是人类赖以生存的战略物资之一。植物在提供生态平衡方面也发挥着重要作用。因此,在全球变暖和环境污染使濒危植物的地位不断恶化的情况下,保护濒危植物品种具有重要意义。
3.自然界中的植物物种繁多,约40多万种,植物叶片是植物的重要器官之一,是识别植物种类的一个重要参考标准,通过植物叶片可以有效识别植物的种类,对研究和保护植物有着重要意义。但是由于植物种类繁多,不同种类植物的叶片具有一定的差异,同一种植物的叶片形状和纹理特征可能随季节变化而变化,植物识别图像在采集过程中,也存在光照、角度、遮挡等问题,给植物叶片图像的识别任务带来很大的困难。
4.植物叶片图像识别是图像识别任务中的一种,根据已有的植物叶片图像数据集,通过建立好算法和模型,使得模型能够从数据集中提取出具有判别性图像特征,通过这些特征对未知图像进行识别分类。图像识别技术发展至今已有30年的历史,识别技术也越来越趋近于成熟,近年来图像识别技术被广泛应用于工业、农业、植被繁殖、人脸识别、指纹识别等领域,给人们的生产生活带来了极大的便利。传统的图像处理技术是将计算机中存储的数字图像,采用一系列的图像学处理、分析、计算对数字图像进行处理,常见的处理技术有图像平滑处理、锐化处理、马赛克处理、灰度化、阈值分割、滤波降噪、边缘检测、形态学等。传统的图像分类算法在植物识别领域也得到重要发展,传统方法多倾向于对单一的植物叶片图像预先提取多种叶片特征,作为分类识别的依据。而特征提取需要研究人员对识别图像的目标图像领域知识深度挂钩,这些传统的特征提取方法很难有统一的标准,具有应用成本高,植物种类单一,识别的准确率低的缺点。而随着神经网络的出现,使得计算机对于图像的识别能力相较于传统方法得到了较大的提升。对于植物叶片识别而言,卷积网络的出现使得原本繁琐的特征设定,特征向量提取变得相对简便。近年来的注意力机制更是为图像识别领域注入了新的活力,有效结合卷积神经网络和注意力机制,设计新的模型和方法,研究如何解决植物叶片中存在的类内间距大、类间间距小的问题,是目前植物叶片识别技术上需要突破的关键。
技术实现要素:
5.为了克服上述现有技术中存在的缺陷,本发明提出了一种基于多图像协同注意力机制的植物叶片识别系统及方法。
6.为实现上述目的,本发明提供了如下方案:
7.一种基于多图像协同注意力机制的植物叶片识别系统,包括客户端和与所述客户端相连的服务器端;
8.所述客户端用于获取植物叶片图像并进行预处理,并将预处理后的植物叶片图像通过无线网络发送至所述服务器端;
9.所述服务器端用于接收来自所述客户端预处理后的植物叶片图像,并调用基于多图像协同注意力网络进行识别。
10.优选地,所述客户端为ios客户端,所述ios客户端包括图像上传模块、图像采集模块、图像处理模块、人机交互界面、客户端数据存储模块和客户端网络通信模块,所述图像采集模块和所述图像上传模块分别与所述人机交互界面连接,所述图像处理模块分别与所述图像采集模块、图像上传模块、人机交互界面、客户端数据存储模块和客户端网络通信模块相连接,所述图像上传模块与所述客户端数据存储模块连接,所述客户端网络通信模块与所述服务器端相连接。
11.优选地,所述服务器端包括用于对外联网的流量分发服务器和用于根据分发规则对请求进行分发的主任务分发服务器,所述主任务分发服务器包含单图像识别任务队列和批量图像识别任务队列,所述服务器端根据所述任务队列中的任务选择工作服务器组中的工作服务器进行识别,得到识别结果,最终所述识别结果将以json格式返回给所述客户端。
12.优选地,所述服务器端的服务器架构为分布式架构,服务器端由所述主任务分发服务器组分发识别任务,所述工作服务器组完成识别任务。
13.优选地,所述服务器端还包括同类别协同注意力模块和共同特征擦除模块以及采用特征联合方式进行协同分类的网络模型;所述同类别协同注意力模块通过采用一对同类别图像输入的方式,基于骨干卷积神经网络分别提取一对图像的特征映射,计算一对同类别图像两个特征映射之间的相似性特征矩阵,得到一对图像的共同注意特征。
14.优选地,所述共同特征擦除模块采用所述同类别协同注意力模块提取出的共同注意特征,通过擦除图像中的共同注意特征对应区域来捕捉互补特征,对同类别协同注意力模块加权的特征映射执行全局平均池,选取最大值对应的特征图通道作为注意力特征图,并将其向上采样至原始图像大小,将所述图像上传模块中原始图像进行图像剔除操作,得到剔除同类别图像的共同特征的剔除图像,所述剔除图像将重新传入所述骨干卷积神经网络取得新分类器,用于模型训练和图像分类识别。
15.优选地,所述采用特征联合方式进行协同分类的网络模型基于特征联合方案采用以原始图像提取的特征图分类器为主,所述同类别协同注意力模块获得的相似特征分类器、所述共同特征擦除模块挖掘的互补分类器作为辅助分类器,形成联合分类器,挖掘图像中可识别性特征,得到分类结果,所述分类结果由原始图像分类器结果,联合加权后的擦除图像分类器结果,经过softmax进行输出。
16.一种植物叶片识别方法,其特征在于,包括以下步骤:
17.客户端首先根据用户请求选择图像识别方式,基于图像处理模块将识别到的图像进行预处理操作,得到经过预处理后的图像,其中所述图像识别方式包括单张图像识别和批量图像识别;
18.通过人机交互界面选取上传操作,将所述经过预处理后的图像基于图像上传模块进行上传,其中上传方式包括本地图像识别路径请求和拍照图像识别请求;
19.服务器端接收到来自所述客户端的图像后,调用部署于所述服务器端的植物叶片识别模型对图像数据进行植物叶片识别,并返回结果至所述客户端的人机交互页面上实时展示识别结果。
20.优选地,若用户通过所述客户端选择的上传方式为所述本地识别路径请求,则所述人机交互界面将读取本地系统存储空间中的图像数据,图像数据经过本地预处理完成后,所述客户端将需要识别的图像数据发送至所述服务器端的图像识别模块,所述服务器端的图像识别模块调用所述植物叶片识别模型对经过预处理的植物叶片图像进行识别,并将识别结果返回至所述客户端的人机交互界面实时展示识别结果;所述植物叶片识别模型为基于多图像协同注意力网络模型。
21.优选地,其特征在于,若用户通过所述客户端选择的上传方式为所述拍照图像识别请求,则用户选择本地拍照图像识别后,所述客户端将调用本地相机权限进行图像拍照,并将拍照图像存储在本地系统中,并将图像上传至所述服务器端进行识别,并将识别结果返回至客户端的所述人机交互页面实时展示识别结果。
22.本发明的有益效果为:
23.1)本发明系统利用弱监督方式训练基于多图像协同注意力模型,通过最小的代价,不需要人工标注信息即可训练一个高性能的植物叶片识别模型,便于实现;
24.2)本发明所设计的服务器端架构,采用了多冗余节点共同协同工作、流量分发的分布式架构,创新性的提出多服务器协同工作方法,让本发明支持批量图像识别功能,具备快速图像识别、24小时高可用等优点。
附图说明
25.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
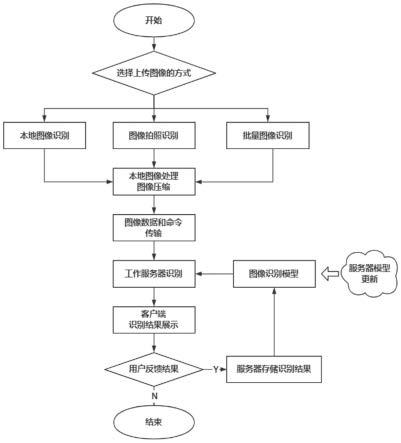
26.图1为本发明实施例的基于多图像协同注意力的植物叶片识别系统实现植物叶片识别的流程示意图;
27.图2为本发明实施例的服务端架构示意图;
28.图3为本发明实施例的基于多图像协同注意力结合的植物叶片识别模型流程示意图。
具体实施方式
29.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
30.为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本发明作进一步详细的说明。
31.本发明涉及一种基于多图像协同注意力机制的植物叶片识别系统及方法,用以根
据植物的叶片的图像进行植物物种识别并对识别进行反馈。
32.本发明系统提供本地上传图像、拍照上传图像识别和批量上传图像识别三种植物叶片的识别功能,该系统包括通过无线网络互相连接的ios客户端和服务器端。
33.ios客户端包括图像采集模块、图像上传模块、图像处理模块、人机交互界面、客户端数据存储模块和客户端网络通信模块,人机交互界面与图像采集模块、图像上传模块连接,图像处理模块分别与图像采集模块、图像上传模块、人机交互界面、客户端数据存储模块和客户端网络通信模块连接,图像上传模块与客户端数据存储模块连接,客户端网络通信器与服务器端连接。图像处理模块用于对ios客户端本地的图片(即图像采集模块及图像上传模块的植物叶片图像)进行预处理。
34.服务器端用于对ios客户端发送来的植物叶片图像进行精准识别。如图2所示,服务器端包括流量分发服务器、主服务器组内的多个主任务分发服务器和多个工作服务器,主任务分发服务器与流量分发服务器相互连接,每个主任务分发服务器分别连接多个工作服务器。
35.用户发出的请求首先全部转发到一台高性能流量分发服务器,高性能流量分发服务器会根据当前服务器集群中各个服务器的负载状态来将用户请求分配到相对空闲的主任务分发服务器上进行处理,以实现服务器集群的负载均衡。另一方面为了保持集群的高可用性,实现部分主任务分发服务器故障后,整个集群仍能够对外提供服务。工作服务器集群通过多冗余节点共同协同工作的技术来为集群中的高性能工作服务器提供替换备份,确保高可用性。集群中负责请求转发的高性能流量分发服务器配备一台从属备份服务器,该从属备份服务器负责监视负责请求转发的高性能流量分发服务器的运行状态,当负责请求转发的高性能流量分发服务器发生机器故障时,该从属备份服务器开始接管请求转发的相关工作,从而增加整个集群的高可用性。
36.如图1所示,本发明系统实现植物叶片识别的具体步骤包括:
37.步骤1、ios客户端获取叶片图像并对图像采取交互式的方式通过图像采集模块进行植物叶片的拍摄,也可利用图像上传模块选择客户端数据存储模块中的某植物叶片图像,拍摄图片后或选择图像后将图像送至图像处理模块进行图像预处理。
38.步骤2、用户可根据自己的需求在人机交互页面进行识别数量的任意选择。即选择单张图像或多张图像批量识别。
39.步骤3、当用户选择单张图像快速识别后,人机交互页面将图像传输至服务器端进行图像识别,传输采用http协议进行传输,服务器端将采用步骤5进行图像识别,将得到的结果返回给ios端快速的在人机交互页面展示出识别结果。
40.步骤4、当用户选择批量图像识别后,人机交互页面将多张图像送至打包压缩模块,打包压缩模块将批量识别图像压缩包传送至服务器端,服务器端接收到批量识别命令后将对批量识别图像压缩包进行解压和处理,送至多台服务器中进行并发识别,服务器端将采用步骤5进行图像识别,服务器端将批量识别结果组织成对应的识别结果集,服务器端将识别得到的结果集返回给ios端快速的在人机交互页面展示出识别结果。
41.步骤5、服务器端接收到需要识别的图像后,对每台工作服务器,对于收到的识别图像,传送至部署在服务器端的基于多图像协同注意力的植物叶片识别模型中,将模型输出的结果,封装成返回的数据json格式进行返回,采用http协议传送识别结果。
42.下面针对服务器端的设计以及服务器端的基于多图像协同注意力的植物叶片分类算法进行详细介绍和说明:
43.(1)服务器端设计
44.本发明支持用户通过ios客户端选择单张图像识别或批量图像识别,本发明为了实现了高可用、高效、高准确率的特点,服务器端需要设计出支撑本发明的分布式架构。本发明的服务器架构设计如图2所示,服务器节点模仿reactor线程模式,采用一组主服务器用于识别主任务的分发,另外的工作服务器节点共同形成一个集群负责服务器图像的识别工作。ios用户客户端选择需要上传的图像数据,将需要识别的图像传输给nginx负载均衡服务器,nginx负载均衡服务器将所有的传输流量采用轮询的方式传输给主任务分发服务器组内的所有分发服务器。
45.主任务分发服务器组内的所有分发服务器采用并行的方式,每台分发服务器都维护了一个自己服务器内的任务分发列表,服务器接收到需要识别的图像数据后,将其简单封装成一个识别任务,存储在当前分发服务器内的任务列表内。采用另一个线程对任务列表内的任务循环处理,按照任务的类型分为单图像识别任务和批量图像识别任务。对于单图像识别任务,再次封装后随即分发给工作服务器组的工作服务器进行识别,识别结构由工作服务器直接传输给nginx服务器后返回给ios客户端进行展示。对于批量识别图像任务,将任务内的批量图像压缩包进行解压缩,将所有图像单独封装成多幅单图像识别任务分发给工作服务器组内的工作服务器,当所有工作服务器完成识别任务后将识别结果返回给当前任务分发服务器内,将识别结果集进行返回。
46.为了能够灵活的使用返回结果,减少网络传输的负担,需要统一返回格式,所述识别结果最终均由nginx服务器返回给ios客户端,返回格式均采用json格式,服务器之间及nginx服务器与客户端之间的数据传输采用http协议。
47.(2)基于多图像协同注意力的植物叶片分类算法及实验分析
48.植物叶片识别任务属于图像分类任务,由于植物叶片图像存在类内间距较小,类间间距较大的特点,高度混淆的类别之间存在固有的微妙差异,传统的图像识别分类方法所能取得的性能有限。且现有的图像识别方法都是基于单幅图像作为输入,从单幅图像中提取具有判别性的特征用于图像分类,忽视了图像与图像之间也存在某些特征的关系。本发明从注意力机制的角度出发,提出了基于多图像协同注意力的植物叶片识别方法。具体来说,通过鼓励同类别图像对中的特征通道之间的交互来计算通道相似性,以捕获共同的鉴别特征。考虑到互补信息对识别也是至关重要的,删除了信道交互增强的突出区域,迫使网络聚焦于其他有区别的区域。
49.受协同注意力机制的启发,本发明提出了一个同类别协同注意力模块来模拟一对同类图像之间的通道交互。通过获取通道间的对比特征,模型可以更好地学习同类别图像的共性,从而迫使网络聚焦于共同的具有判别性特征。但是,只关注同类别图像的共同特征会导致网络忽略对高度混淆的类别至关重要的互补特征。为了解决这一问题,本发明还设计了一个共同特征擦除模块,通过擦除同类别协同注意力模块中最突出的区域来学习互补特征。结合这两个模块,该方法可以捕获更多相关区域,从而提高模型的性能。
50.1)同类别协同注意力模块
51.给定一对同类别图像{img1,img2},首先对这两幅图像进行卷积网络处理,将其作
为输入传入卷积神经网络提取出图像的特征图,特征图的每个通道都可以看作是某一种特征的表示,特征图中的值是对当前特征强度的响应,得到一对特征图映射f1,其中c、h和w分别表示通道数、高度和宽度。采用特征图映射内积的方式来计算特征通道相似度。首先将得到一对特征图映射f1,按照通道进行重新投影,将每个通道对应的特征的高度和宽度进行降维得到f
′1,其中r=h*w,内积的结果分别为m1、m2。
[0052][0053][0054]
其中表示按元素内积操作。再取相似矩阵m1、m2与原图像提取的特征图进行矩阵乘法,计算出矩阵的共同特征fc1,fc2。
[0055]
fc1=m1*f1[0056]
fc2=m2*f2[0057]
2)共同特征擦除模块
[0058]
为了探索互补信息的其他细微线索,提出共同特征擦除模块,提取出共同特征图fc两幅同类别图像中的最显著的共同特征,将通道对应的共同特征进行擦除,将擦除特征的上采样图像对原始图像添加蒙板操作,形成擦除图像。
[0059]
具体的,对同类别协同注意力模块加权的特征映射执行全局平均池。然后选取最大值对应的feature map通道作为attention map,并将其向上采样至原始图像大小:
[0060]
fcm=max(gap(fc1))
[0061]
其中fcm表示一对相似图像中的共同特征中的最显著特征,gap表示全局平均池化操作。得到的共同特征中的最显著特征fcm,表示需要进行删除的共同最显著特征。对于共同最显著特征中包含许多信息,共同最显著特征中所取得的图像信息并不需要全部进行删除,选取一个阈值θ作为条件进行对应特征的信息擦除,将fcm大于阈值θ的元素设为0,将其他元素设为1,得到一个降掩码m:
[0062][0063]
将掩码m与原始图像进行点乘,得到擦除后的新图像。
[0064][0065]
其中为元素乘法,img为原始图像,ie为删除后的图像。
[0066]
经过共同特征擦除模块将获取到一个擦除共同特征后的图像,也即原始图像中突出的区域被擦除。将该擦除后的上采样图像重新传入到骨干网络中进行训练,得到fe,fe表示擦除图像特征图,此时骨干网络的注意力被分散,网络被迫从其他区域学习有区别的信息。减少了对训练样本的依赖,提高了模型的鲁棒性。
[0067]
3)特征联合网络模型
[0068]
经过上述的两个模块:同类别协同注意力模块和共同特征擦除模块,将得到两个特征图,分别为由两幅同类别图像计算得到的共同特征图和经过特征擦除图像重新训练的
擦除特征。这两个特征图分别代表着不同的包含其他粒度信息的感知能力,有助于细粒度图像分类。为了利用好上文中经过同类别协同注意力模块和共同特征擦除模块提取出的互补特征,设计了一个联合不同粒度特征表示的网络模型,将提取到的互补特征与原特征图进行结合。
[0069]
网络模型如图3所示,选取同类别中一对幅图像共同进行训练,两幅图像分别经过骨干卷积神经网络得到特征图f1和f2,经过同类别协同注意力模块得到fc1和fc2,经过共同特征擦除模块得到擦除图像特征fe,考虑到原始图像中提取出的特征对图像分类的影响较大,选取挖掘到的fc1和fe作为的互补特征,将这两者特征形成的分类器作为辅助分类器以挖掘其他细微粒度。最终的分类结果由原始图像分类器结果,联合加权后的擦除图像分类器结果,经过softmax进行输出。
[0070]
cls=softmax(softmax(cls_1)+γ*∑softmax(cls_i))
[0071]
其中γ为超参数,cls_1表示由原始图像分类器结果,cls_i表示由同类别协同注意力模块和共同特征擦除模块得到的fc1和fe形成的分类结果。每个分类器的输出结果归一化、联合加权后的输出结果归一化。采用softmax进行归一化,softmax用于多分类过程中,它将多个输出结果,映射到(0,1)区间内,最终的映射结果可以看成概率来理解,每个类别的概率也即最终的预测类别的得分,得分最高的类别为最终输出结果,从而来进行多分类,最终采用交叉熵损失计算每个阶段的分类误差。经过原始图像分类器与加权后的擦除图像分类器结果联合后得到的最终分类器,损失函数如下所示:
[0072]
loss
cls
=-y
t
*log(softmax(softmax(cls_1(zp))+γ*∑softmax(cls_i)))
[0073]
数据组织——icl植物叶片数据集是同济大学机器学习与系统生物学研究所与合肥市植物园合作进行整理、收集、标注的。该数据及囊括了220种植物,共计16851张植物叶片的样本,其中每类植物的样本数量不等,从26张到1078张。数据集中的图像格式相同,都为jpg压缩格式,其扫描精度为300dpi,均是24位白色背景图片。从中50类的植物叶片样本,其中每类植物含有100多张图片。
[0074]
选取resnet50、resnet101和densenet161作为骨干网络对模型进行性能对比实验,数据集采用icl植物叶片数据集。两组实验采用一套同样的实验环境,采用python语言,版本3.6.5,框架采用pytorch,版本为1.4.0,采用cuda进行加速,使用两张gtx titan x显卡进行训练,每张显卡显存8gb。icl数据集经过预处理,数据预处理方式前文有详细说明。实验采用随机梯度下降法对模型进行优化,并设置动量为0.9、epoch为200、权重衰减为5e-4、batch-size为20。实验设置超参数γ=0.5,训练过程中的学习率设置为0.02,使用余弦退火法(cosine annealing)调整学习率,训练过程中同样采用余弦退火法调整学习率。采用余弦退火法可以通过余弦函数来降低学习率,余弦函数中随着x的增加余弦值首先缓慢下降,然后加速下降,再次缓慢下降。这种下降模式能和学习率配合,以一种十分有效的计算方式来产生很好的效果。
[0075]
为了能够直观的比较本发明所提出的方案的模型性能,选取经典卷积神经网络进行对比试验分析,得到的详细结果如下表1所示。
[0076]
表1
[0077][0078]
其中mca(multi-image collaborative attention model)表示基于多图像协同注意力的植物叶片识别方法的实验结果。
[0079]
从实验结果来看,在骨干网络原有基础上,本发明提出的基于多图像协同注意力的植物叶片识别方法,能够通过同类别协同注意力模块和共同特征擦除模块来捕捉微妙的互补特征。经过结合擦除图像后提取的互补特征,模型的准确率相较于骨干神经网络而言平均提升4-5%。该发明在植物叶片数据集icl上,很好的解决了不同类别相似样本很容易被错误分类成同类别,以及相同类别样本差异过大被错误分成不同类别样本的问题。
[0080]
以上所述的实施例仅是对本发明优选方式进行的描述,并非对本发明的范围进行限定,在不脱离本发明设计精神的前提下,本领域普通技术人员对本发明的技术方案做出的各种变形和改进,均应落入本发明权利要求书确定的保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1