一种融合双深度学习网络的无参考视频质量评价方法
1.本发明涉及计算机图像识别领域,具体是一种融合双深度学习网络的无参考视频质量评价方法。
背景技术:
2.受到传输条件的限制,获取的视频通常需要压缩处理,有损压缩会导致视频信息丢失,造成模糊或者块状等失真现象。传输过程中可能会引起丢包现象,随机噪声的影响也不容忽视,拍摄者的技巧是否专业也影响着拍摄视频的质量。失真的视频会带给用户不好的观看体验,所以开发探索一种可靠的视频质量评价方法是非常需要的。
3.主观视频质量评价方法是对收集的主观评判分数进行统计学分析,而得出评价模型的方法,具有较高的可靠性,但在收集每个人的评分时会消耗大量的时间和精力,显然在主观视频质量评价并不适合这个快节奏的发展时代。客观视频质量评价根据是否需要源视频的参与可分为全参考视频质量评价(fr-vqa),半参考视频质量评价(rr-vqa)和无参考视频质量评价(nr-vqa)。与全参考视频质量评价和半参考视频质量评价方法相比,无参考视频质量评价不受源视频的限制,即整个评价过程中无参考视频质量评价模型不需要访问视频“完美版本”,但在模型最终的评价指标上面无参考视频质量评价会略逊一些。虽然如今视频质量评价已经取得了较多成果,但在科技进步和大数据时代的推动下,网络上的视频包含的内容越来越多,各种失真情况相互交融增加了视频的复杂程度,显然视频质量评价也面临着种种困难考验。
4.在已经提出的视频质量评价方法中有些是从影响用户体验质量因素的角度出发对视频进行评价;有些方法则是对包含多种合成失真情况的视频进行系统建模评价;但有些方案直接处理未经过加工的自然野生视频来构建视频质量评价模型。现有的视频质量评价方法来说各有特色,但对于未经处理的由用户直接生成的内容复杂多变,且受多种失真影响的真实视频,现存的质量评价方法并不能做到有效预测。
技术实现要素:
5.本发明要解决的技术问题是提供一种融合双深度学习网络的无参考视频质量评价方法,用以方便地对视频图像质量给出快速的预测评价分数。
6.为了解决上述技术问题,本发明提供一种融合双深度学习网络的无参考视频质量评价方法,过程包括:将视频内每一帧的视频图像i
t
输入至无参考视频质量评价网络,无参考视频质量评价网络首先通过双深度学习网络提取获得视频图像i
t
的深度特征f
t
,深度特征f
t
经过ann网络进行特征降维处理后输入双向门控循环网络,通过双向门控循环网络构建视频帧特征之间的联系获取视频帧质量分数q
t
,然后视频帧质量分数q
t
经过改进的时间记忆模型获得视频质量分数预测分量q1,同时视频帧质量分数q
t
经过高斯分布回归预测模型获得视频质量分数预测分量q2,视频质量分数预测分量q1和视频质量分数预测分量再经过调节因子ρ进行优化调节获得最终的视频质量分数q。
7.作为本发明的一种融合双深度学习网络的无参考视频质量评价方法的改进:
8.所述双深度学习网络包括并联的inceptionv3网络和resnet50网络,所述深度特征f
t
为:
[0009][0010]
其中,表示卷积操作,g
mean
为全局平均池化g
mean
,g
std
为全局标准差池化,表示在inceptionv3网络下的深度特征映射,表示在resnet50网络下的深度特征映射:
[0011][0012][0013]
作为本发明的一种融合双深度学习网络的无参考视频质量评价方法的进一步改进:
[0014]
所述视频帧质量分数q
t
为:
[0015][0016]
其中,ω
t
为视频帧质量信息的权重,b
t
为视频帧质量信息的偏差参数,表示视频内每一帧图像i
t
在通过双向门控循环网络后所得特征:
[0017][0018]
其中,bigru(
·
)表示双向门控循环网络操作,ann(
·
)表示ann网络的降维操作;
[0019]
所述ann网络包含两个全连接层和一个dropout层。
[0020]
作为本发明的一种融合双深度学习网络的无参考视频质量评价方法的进一步改进:
[0021]
所述改进的时间记忆模型包括在时间记忆模型的拟合过程中加入了正比例函数拟合与指数函数拟合获得记忆影响因素且在softmin-weighted模块的可微的softmin函数中加入参数ε获得视觉滞留影响因素引入参数δ用于的平衡记忆影响因素和视觉滞留影响因素以此获得第t帧图像的质量评分q
′
t
,然后获得改进的时间记忆模型的预测分量q1,具体为:
[0022]
在tm∈(t-τ,t-1)帧对第t帧的记忆影响因素为:
[0023][0024][0025]
其中,qm表示进行最小值池化操作后得到的帧质量分数,l
t1
和l
t2
分别表示利用正比例函数和指数函数进行拟合得到的结果,v
p
={t-τ,...,t-2,t-1};
[0026]
在tc∈(t,t+τ)内的视频图像对第t帧图像的视觉滞留影响因素为:
[0027]
[0028][0029]
其中,代表每帧图像的权重,vc={t,t+1,...,t+τ},ε为参数,qn表示q
t
在t∈(t,t+τ)时的视频帧质量分数;
[0030]
所述视频质量分数预测分量q1为:
[0031][0032][0033]
作为本发明的一种融合双深度学习网络的无参考视频质量评价方法的进一步改进:
[0034]
所述视频质量分数预测分量q2为:
[0035][0036][0037]
其中,qc为经过平均值池化操作后所得特征,l为经过双向gru处理后的特征维度,t为视频中总图像数;μc和σc分别为当前整个视频中所有帧经过平均值池化所得特征的均值和方差。
[0038]
作为本发明的一种融合双深度学习网络的无参考视频质量评价方法的进一步改进:
[0039]
所述视频质量分数q为:
[0040][0041]
其中,ρ为调节因子,范围限制在0到1内。
[0042]
作为本发明的一种融合双深度学习网络的无参考视频质量评价方法的进一步改进:
[0043]
所述无参考视频质量评价网络的训练过程为:
[0044]
获取konvid-1k数据库和live-vqc数据库中的视频并随机划分为60%、20%和20%,分别作为训练集、验证集和测试集;将训练集和验证集输入无参考视频质量评价网络进行训练,损失函数采用l1损失函数,优化方法采用adam优化方法,其中学习率和训练时的步长设置为0.00001和16,在验证集上获得最大斯皮尔诺曼秩系数为目的进行1000次迭代优化,得到训练好的无参考视频质量评价网络;然后将测试集均随机划分输入训练好的无参考视频质量评价网络,以斯皮尔诺曼秩系数、皮尔逊系数作为视频质量预测评价指标,并将10次测试的平均值和标准差作为最终的测试结果,从而验证了在线使用的无参考视频质量评价网络。
[0045]
本发明的有益效果主要体现在:
[0046]
1、本发明提出了一种新的深度学习无参考视频质量评价模型。
[0047]
2、本发明结合双深度学习网络的优势,提高了视频感知特征提取的有效性。
[0048]
3、本发明的改进时间记忆模型,添加高斯分布回归模型,提升模型评价指标。
附图说明
[0049]
下面结合附图对本发明的具体实施方式作进一步详细说明。
[0050]
图1为本发明的模型总的框图;
[0051]
图2为感知特征提取结构图以第t帧图像为例;
[0052]
图3为模型中的ann模型结构图;
[0053]
图4为以斯皮尔诺曼秩系数(srocc)为指标,在δ=0.5,ε=2时,τ不同值时训练所得图;
[0054]
图5为以斯皮尔诺曼秩系数(srocc)为指标,在τ=12,ε=2时,δ不同值时训练所得图;
[0055]
图6为以斯皮尔诺曼秩系数(srocc)为指标,在τ=12,δ=0.5时,ε不同值时训练所得图;
[0056]
图7为以斯皮尔诺曼秩系数(srocc)为指标,在τ=12,δ=0.5,ε=2时,ρ不同值时训练所得图;
[0057]
图8为发明模型在两个数据库上训练所得的损失曲线。
[0058]
图8中,从上至下依次为:livevqc val_loss、konvid-1k val_loss、uvevqc train_loss、konvid-1k train_loss。
具体实施方式
[0059]
下面结合具体实施例对本发明进行进一步描述,但本发明的保护范围并不仅限于此:
[0060]
实施例1、一种融合双深度学习网络的无参考视频质量评价方法,如图1所示,具体过程为:
[0061]
步骤1、构建无参考视频质量评价网络
[0062]
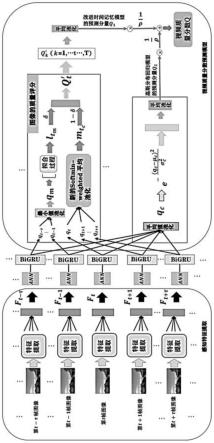
无参考视频质量评价网络包括双深度学习网络、ann网络、双向门控循环网络、改进的时间记忆模型和高斯分布回归模型,如图1所示,首先通过双深度学习网络实现视频感知特征的提取:以inceptionv3和resnet50双深度学习网络为基础,通过全局平均池化和全局标准差池化保证视频获取信息的多样性,使获得的视频帧基本特征和变化信息更加完备;然后通过双向门控循环网络(bigru)构建视频帧特征之间的联系,获取视频帧质量分数,最后通过增加了指数函数拟合尺度和引入超参数的改进的时间记忆模型,改善softmin-weighted平均池化模块中的权重特性,融合改进的时间记忆模型和高斯分布回归模型获得的视频质量预测,并通过调节因子进行优化调节,以便实现更可靠的视频质量预测。具体过程包括:
[0063]
步骤1.1、感知特征的提取
[0064]
inceptionv3网络和resnet50网络在机器学习领域具有广泛的应用,所以选取这
两个深度学习网络来提取视频感知特征。
[0065]
首先令i
t
,t∈(1,2,3,...,t)代表视频内每一张图像,t为每一个视频内的图像的总数,将视频图像i
t
从深度网络顶端输入得到两组深度特征映射:
[0066][0067][0068]
其中,表示在inceptionv3网络下的深度特征映射,表示在resnet50网络下的深度特征映射。
[0069]
得到的深度特征映射不能直接用于下一步处理,需要根据传统算法对获得的深度特征映射进行全局平均池化g
mean
和全局标准差池化g
std
来保存提取的信息。因为本模型涉及两组深度网络特征,故需要对获得的视频信息进行融合处理,得到视频内每一个图像的深度特征f
t
:
[0070][0071]
其中,表示卷积操作,目的是连接提取的特征信息,保证视频信息获取的完整性。具体的感知特征提取结构如图2所示。
[0072]
步骤1.2、视频帧质量分数的预测
[0073]
视频是由连续的图像构成,在进行质量评价时需要考虑到视频的连续性对评价结果的影响。在本模型中对视频帧质量分数的预测采用双向门控循环网络(bigru)网络,双向门控循环网络(bigru)与单向的门控循环网络(gru)网络相比增加了反向传播层,增强了视频内容之间的联系,提升预测效果:
[0074][0075]
其中,表示每个图像在通过双向门控循环网络(bigru)后所得特征,bigru(
·
)表示双向门控循环网络(bigru)操作,ann(
·
)表示降维操作(包含两个全连接层和一个dropout层其结构如图3所示)。ann(
·
)目的是减少在inceptionv3和resnet50网络中保留的视频信息特征的维度,使提取的视频内容信息更加凝练。
[0076]
经过双向门控循环网络(bigru)处理后,再增加一个全连接层来获得视频帧质量分数:
[0077][0078]
其中,q
t
是预测的视频帧质量分数,ω
t
为视频帧质量信息的权重,b
t
为视频帧质量信息的偏差参数。
[0079]
步骤1.3、视频质量分数预测
[0080]
(1)改进的时间记忆模型的预测分量
[0081]
要获得改进的时间记忆模型的预测分量需要考虑当tm∈(t-τ,t-1)和tc∈(t,t+τ)两个周期内的图像对第t帧图像的质量评分的影响。对于解决tm∈(t-τ,t-1)图像对第t帧图像的质量评分的影响问题,本发明通过采用正比例函数+指数函数拟合的方法获得重要影响因素对tc∈(t,t+τ)段的影响则通过在由可微的softmin函数构成的softmin-weighted模块中加入参数ε改善可微的softmin函数中的权重特性来获得重要影响因素
最后引入参数δ用于的平衡和以此获得第t帧图像的质量评分q
t
',并最终获得改进的时间记忆模型的预测分量q1。具体步骤如下所示。
[0082]
以预测视频第t帧图像的质量分数为例,取周期t'∈(t-τ,t+τ)表示从视频的第t-τ帧图像到视频第t+τ帧图像,共包含2τ+1张图片,假设需要预测第t帧图像的质量分数q
t
',引入参数表示在tm∈(t-τ,t-1)帧对第t帧的记忆影响因素,表示tc∈(t,t+τ)在第t帧的视觉滞留影响因素。
[0083]
在tm∈(t-τ,t-1)时,时间记忆模型中加入了指数函数的拟合方法。正比例函数拟合与指数函数拟合的具体步骤如下所示:
[0084][0085][0086]
其中,qm表示进行最小值池化操作后得到的帧质量分数,l
t1
和l
t2
分别表示利用正比例函数和指数函数进行拟合得到的结果,v
p
={t-τ,...,t-2,t-1},qt为视频帧质量预测分数。
[0087]
上述部分考虑到了tm段内对第t帧图像的影响,接下来需要考虑在tc段内tc∈(t,t+τ)对第t帧的影响。采用可微的softmin函数进行拟合规划权重,可以实现较好的效果,为了进一步优化整个模型的结构和提升系统的性能,在权重定义时引入参数ε,用于改善权重的特性。
[0088][0089][0090]
其中,代表每帧图像的权重,为在tc∈(t,t+τ)内的视频图像对第t帧图像的影响,vc={t,t+1,...,t+τ}。
[0091]qn
表示q
t
在t∈(t,t+t)时的视频帧质量分数。
[0092]
在得到tm∈(t-τ,t-1)和tc∈(t,t+τ)各分段内的记忆影响因素和视觉滞留影响因素后,可以推导出视频第t帧图像质量评分,进而利用全局平均池化获得整个视频质量预测分:
[0093][0094][0095]
其中,δ为引入的平衡和两个影响因素的参数,q
t
'为第t帧图像的质量评分,q1为经过改进时间记忆模型获得的视频质量分数预测分量。
[0096]
(2)高斯分布回归模型的预测分量
[0097]
高斯分布回归模型中,μ和σ随模型训练动态变化,参数的动态改变可以增加模型
结果的稳定性和可靠性。
[0098][0099][0100]
其中,qc为经过平均值池化操作后所得特征,l为经过双向gru处理后的特征维度;q2为高斯分布回归模型的预测分量,t为视频中总图像数。μc和σc分别为当前整个视频中所有帧经过平均值池化所得特征的均值和方差,两者的值因视频不同而变化。
[0101]
(3)视频质量分数预测
[0102]
q1为改进的时间记忆模型所得视频预测分量,q2为高斯分布回归模型所得的预测分量,两种质量预测模型的原理存在差异。为了充分结合两种质量预测分量的优势,引入一个超参数ρ作为调节因子,以便获取更准确的视频质量评价。为了将调节因子的范围限制在0到1内,调节因子的形式取为
[0103][0104]
其中,q为最终获得的视频质量分数。
[0105]
步骤2、训练无参考视频质量评价网络
[0106]
步骤2.1、训练数据
[0107]
(1)konvid-1k数据库:该数据库以yfcc100作为基线,由793436个知识共享视频序列组成,共形成1200个视频数据,每个视频包含240帧图像,分辨率为960
×
540,以mos作为主观质量分数,mos值范围为1-5。最高评分4.64,最低评分1.22。
[0108]
(2)live-vqc数据库:该数据库由德克萨斯大学奥斯汀分校影像与视频工程实验室构建,整个视频数据库中包含585段视频,80个不同复杂视频失真类型。4776名受试者参与主观评价,主观质量分数范围0-100,分辨率320
×
240-1920
×
1080。最高评分94.2865,最低评分6.2237。
[0109]
将konvid-1k数据库和live-vqc数据库中的视频随机划分为60%、20%和20%,分别作为训练集、验证集和测试集;
[0110]
步骤2.1、训练无参考视频质量评价网络
[0111]
选用步骤2.1中进行随机划分后获得的训练集进行训练,在imagenet上训练好的inceptionv3网络和resnet50网络作为主干特征提取网络,提取视频中的感知特征,两网络中提取的特征分别为1536维和4096维,融合特征为5632维,即f
t
是5632维的视频内容信息特征。本发明所选取的两个特征提取网络结构存在较大的差异,故可以极大地改善单一网络提取特征的局限性,使得本发明在初步信息提取阶段具有较大的优势。
[0112]
获取到的视频内容信息特征需要经过ann网络进行特征降维处理后,输入双向门控循环网络(bigru)的特征为维度为256维特征,特征降维后使得获取的视频信息特征更加凝练。双向门控循环网络隐藏大小设置为32;在改进的时间记忆模型的拟合过程中增加指数函数尺度和在softmin-weighted模块中的可微的softmin函数加入参数ε改善其权重特
性,在改进时间记忆模型中需要确定参数τ,δ和ε,具体步骤如下。
[0113]
对于参数τ的确定,在konvid-1k数据集上对数据进行随机划分。在δ=0.5和e=2的前提下,将参数τ在3-24之间以步长为3变化时测试所得的srocc参数作为评价指标。可见srocc的值在0.785上下波动,τ=12时视频质量预测结果最优,具体变化趋势如图4。
[0114]
对于参数δ的确定,在konvid-1k数据集上对数据进行随机划分。在τ=12和ε=2前提下,将参数δ在从0.1-0.9之间以步长为0.1变化时测试所得的srocc参数作为评价指标。就整个曲线趋势来讲,大致呈现中间高两端低的情况,当δ=0.5时视频质量预测结果最优,具体变化趋势如图5所示。
[0115]
对于参数ε的确定,在konvid-1k数据集上对数据进行随机划分。在τ=12和d=0.5前提下,将参数ε在1-5以步长为1变化测试所得的srocc参数作为评价指标。可见当ε=2视频质量预测结果最优,具体变化趋势如图6所示。
[0116]
最终将τ值设置为12,δ值设置为0.5,ε值设置为2。
[0117]
从改进创新时间记忆模型中获得视频质量分数预测分量q1。引入高斯分布模型对视频质量分数进行第二次预测,在高斯分布回归预测模型中参数μ和σ随模型训练动态变化,增强模型稳定性。进而获得视频质量分数预测分量q2。
[0118]
引入一个超参数ρ作为调节因子,用于结合两种预测方法的优越性,为限制调节因子范围,调节因子的形式取为ρ值设置为3,最后获得视频质量分数q。对于参数ρ的确定,在konvid-1k数据集上对数据进行随机划分。在τ=12,δ=0.5和ε=2前提下,将ρ范围在2到50之间测试所得的srocc参数作为评价指标,当ρ值小于3时模型性能较差,但当ρ大于3时,随着ρ值增大,系统性能呈现下降趋势,但其整体srocc值仍然大于0.77。当ρ=3时获得系统最佳性能,具体变化趋势如图7所示。
[0119]
模型中损失函数采用l1损失函数,优化方法采用adam优化方法,其中学习率和训练时的步长设置为0.00001和16。
[0120]
模型在训练过程中以在验证集获得最大斯皮尔诺曼秩系数(srocc)的模型为目的进行1000次迭代优化,进而得到训练模型。
[0121]
图8具体展示了在数据集konvid-1k和livevqc上的训练和验证过程中损失曲线。
[0122]
步骤2.2、测试无参考视频质量评价网络
[0123]
测试采用斯皮尔诺曼秩系数(srocc)、皮尔逊系数(plcc)作为视频质量预测评价指标,srocc和plcc越接近1表示预测效果越好;每次实验的测试集均随机划分,且测试结果以srocc和plcc数值进行展示,srocc和plcc的计算方式如下所示;
[0124][0125]
其中n为测试视频总个数,ui为测试获得的视频质量分数,为测试获得的视频质量分数的平均值,vi为主观实验获得的视频质量分数(数据库中给出的视频质量分数),为主观实验获得的视频质量分数的平均值。
[0126][0127]
其中x为测试获得的视频质量分数,y主观实验获得的视频质量分数(数据库中给出的视频质量分数)。cov(x,y)表示测试所得的质量分数和主观测试获得视频质量分数的协方差。σ
x
表示测试获得的视频质量分数的标准差,σy表示主观实验获得的视频质量分数的标准差
[0128]
与其他模型进行对比试验中,将10次实验获得srocc和plcc的平均值和标准差作为展示结果;随机一次测试中,srocc和plcc均以单一值进行展示。从而验证了训练好的无参考视频质量评价网络可在线使用。
[0129]
步骤3、在线使用
[0130]
在上位机中,将待评价的视频内的每一帧视频图像i
t
输入至无参考视频质量评价网络,首先通过双深度学习网络提取获得视频内每一帧图像i
t
的深度特征f
t
,经过ann网络进行特征降维处理后输入双向门控循环网络,通过双向门控循环网络构建视频帧特征之间的联系获取视频帧质量分数q
t
,然后视频帧质量分数q
t
经过改进的时间记忆模型获得视频质量分数预测分量q1,同时视频帧质量分数q
t
经过高斯分布回归预测模型获得视频质量分数预测分量q2,视频质量分数预测分量q1和视频质量分数预测分量再经过调节因子ρ进行优化调节获得最终的视频质量分数q,并在上位机中呈现视频质量分数q。
[0131]
实验1:
[0132]
为了验证本发明的有效性,为减少不同数据对最终分析结果的影响,统一采用实施例1中步骤2.1所使用训练数据集和数据集
[0133]
测试环境为:pytorch,torch-1.70,python3.7进行搭建,在包含intel(r)xeon(r)gold 6136 cpu@3.00ghz,2.99ghz双核处理器,256gbram和nvidia quadro rtx 6000显卡的联想台式机上进行实验。
[0134]
选取viideo[1],tlvqm[2]、vsfa[3]、v-bliinds[4]、chipqa[5]、brisque[6]、tang[7]等模型进行对比。所选取的对比模型均来自已经发表的论文,均为无参考视频质量评价模型,具体的模型出处如下所示:
[0135]
对比模型来源:
[0136]
[1]min,x.,zhai,g.,zhou,j.,farias,m.c.,&bovik,a.c.(2020).study of subjective and objective quality assessment of audio-visual signals.ieee transactions on image processing,29,6054-6068.
[0137]
[2]korhonen,j.(2019).two-level approach for no-reference consumer video quality assessment.ieee transactions on image processing,28(12),5923-5938.
[0138]
[3]li,d.,jiang,t.,&jiang,m.(2019,october).quality assessment of in-the-wild videos.in proceedings of the 27th acm international conference on multimedia(pp.2351-2359).
[0139]
[4]saad,m.a.,bovik,a.c.,&charrier,c.(2014).blind prediction of natural video quality.ieee transactions on image processing,23(3),1352-1365.
[0140]
[5]ebenezer,j.p.,shang,z.,wu,y.,wei,h.,sethuraman,s.,&bovik,a.c.
(2021).chipqa:no-reference video quality prediction via space-time chips.ieee transactions on image processing,30,8059-8074.
[0141]
[6]mittal,a.,moorthy,a.k.,&bovik,a.c.(2012).no-reference image quality assessment in the spatial domain.ieee transactions on image processing,21(12),4695-4708.
[0142]
[7]tang,j.,dong,y.,xie,r.,gu,x.,song,l.,li,l.,&zhou,b.(2020,december).deep blind video quality assessment for user generated videos.in 2020ieee international conference on visual communications and image processing(vcip)(pp.156-159).ieee.
[0143]
[8]sinno,z.,&bovik,a.c.(2018).large-scale study of perceptual video quality.ieee transactions on image processing,28(2),612-627..
[0144]
实验进行10次,每次实验数据库均随机划分,并将10次实验的平均值和标准差作为最终的实验结果。对于选取的对比模型其结果则来自相应文献。对比结果如表1所示:
[0145]
表1中结果以“平均值(方差)”的形式进行展示,且每一列中的最好结果和次好结果已经用粗体字和下划线标出表示,“*”表示测试结果来自文献[8],
“‑”
表示论文原作者未在文章中展示,overall performance中其计算方式为score*(1200+585)=konvid-1k*1200+livevqc*585
[0146][0147]
由表1可知,在konvid-1k数据集上,本发明提出无参考视频质量评价网络的实验结果在srocc、plcc上均显然优于其他算法。尤其与vsfa模型相比,无参考视频质量评价网络在srocc上提升了3.87%,plcc上提升4.73%,提升效果明显;在livevqc数据集中,无参考视频质量评价网络在srocc上处于最优,高出次优结果2.25%,在plcc测试结果中属于次优,与最优结果相差1.77%。就整体性能来讲,srocc为最优性能高出次优结果2.87%,plcc为最优结果高出次优结果0.52%。
[0148]
最后,还需要注意的是,以上列举的仅是本发明的若干个具体实施例。显然,本发明不限于以上实施例,还可以有许多变形。本领域的普通技术人员能从本发明公开的内容直接导出或联想到的所有变形,均应认为是本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1