小样本目标检测方法、系统、装置
1.本发明属于机器人技术领域,具体涉及一种小样本目标检测方法、系统、装置。
背景技术:
1.随着科技的不断进步,机器人在人们日常生活、生产中发挥着日益重要的作用,机器人检测识别不同类别物体的能力直接影响到其应用价值。为实现机器人目标检测,国内外研究人员基于深度学习开展了深入的研究,但是现有基于深度学习的目标检测方法大多需要在大规模的标注数据上进行网络训练。大规模的数据标注成本较高,加之一些类别的物体难以获得充足的训练样本,为此,机器人研究人员开始关注在大规模数据集上对现有的目标检测网络进行预训练,利用训练后的网络定位场景中各个潜在的目标物体,进而借助少量的新类目标物体的训练样本实现对新类目标物体的分类,从而完成小样本目标检测。
2.目前的小样本目标检测方法多用ssd(single shot multibox detector)、faster r-cnn等现有的目标检测网络在imagenet等大规模数据集上进行预训练,预训练后的网络用于定位场景中各个潜在的目标物体,在此基础上,结合新类目标物体的标注样本进一步训练网络,最后利用检索的方式实现对潜在目标物体的分类。对于上述小样本目标检测方法来说,如果新类目标物体与预训练的大规模数据集中的目标物体外观差别较大,会导致新类目标物体难以被当作潜在目标物体检测出来,这将影响小样本目标检测的质量。针对该问题,图像检索由于其对各类物体表征的包容性成为一种可能的解决方案。图像检索通常用densenet169骨干网络将查询图像和检索数据库中的所有图像转化为对应的特征图,然后利用gem(generalized-mean pooling)或rmac(regional maximum activations of convolutions)等聚合操作将特征图聚合为图像级编码向量,进而通过不同图像对应的图像级编码向量之间的匹配相似度来度量图像之间的相似度,在检索数据库中选取与查询图像具有最大相似度的图像作为图像检索结果。图像检索网络训练时常借助三元组损失(hard triplet loss)加以进行。然而,现有的图像检索网络并不能直接应用于小样本目标检测中。
3.为此,本领域技术人员有必要在基于图像检索网络的小样本目标检测方面进行更深入的研究,以解决新类目标物体与预训练数据集中的目标物体外观差异较大情形下新类目标物体的检测问题。
技术实现要素:
4.为了解决现有技术中的上述问题,即为了解决新类目标物体与预训练数据集中的目标物体外观差异较大情形下,新类目标物体的检测鲁棒性较差的问题,本发明提供了一种小样本目标检测方法,包括以下步骤:
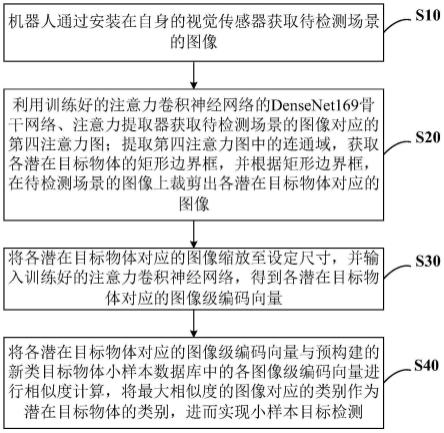
5.步骤s10,机器人通过安装在自身的视觉传感器获取待检测场景的图像;
6.步骤s20,利用训练好的注意力卷积神经网络的densenet169骨干网络、注意力提
取器获取待检测场景的图像对应的第四注意力图;提取所述第四注意力图中的连通域,获取各潜在目标物体的矩形边界框,并根据矩形边界框,在待检测场景的图像上裁剪出各潜在目标物体对应的图像;
7.步骤s30,将各潜在目标物体对应的图像缩放至设定尺寸,并输入训练好的注意力卷积神经网络,得到各潜在目标物体对应的图像级编码向量;
8.步骤s40,将各潜在目标物体对应的图像级编码向量与预构建的新类目标物体小样本数据库中的各图像级编码向量进行相似度计算,将最大相似度的图像对应的类别作为潜在目标物体的类别,进而实现小样本目标检测;
9.其中,所述注意力卷积神经网络包括densenet169骨干网络、注意力提取器和聚合器;
10.所述densenet169骨干网络,用于提取输入的图像的卷积特征,并将densenet169骨干网络第104层的输出作为第一卷积特征,将densenet169骨干网络第169层的输出作为第二卷积特征;
11.所述注意力提取器基于依次连接的卷积层、空间softmax运算层、均值滤波器、阈值化处理操作、图割处理操作构建;
12.所述卷积层,用于对所述第一卷积特征进行卷积处理,将卷积处理后的特征图作为第一注意力图;所述空间softmax运算层,用于对所述第一注意力图进行softmax运算,得到第二注意力图;所述均值滤波器,用于对所述第二注意力图进行滤波处理,得到第三注意力图;
13.所述阈值化处理操作,用于对第三注意力图进行阈值化处理,得到第四注意力图;所述图割处理操作,用于将所述第四注意力图中的非0元素划分成两个最优子集合,并分别得到这两个最优子集合对应的矩形边界框,作为第一边界框、第二边界框;
14.所述聚合器,用于将第一边界框、第二边界框、第二卷积特征进行聚合处理,得到图像级编码向量。
15.在一些优选的实施方式中,对所述第一注意力图进行softmax运算,得到第二注意力图,其方法为:
[0016][0017]
其中,a
1(a,b)
和a
2(a,b)
分别为第一注意力图a1和第二注意力图a2的第a行第b列的元素,β为可学习的缩放系数,a
1(h,w)
为a1的第h行第w列的元素。
[0018]
在一些优选的实施方式中,将所述第四注意力图中的非0元素划分成两个最优子集合,并分别得到这两个最优子集合对应的矩形边界框,作为第一边界框、第二边界框,其方法为:
[0019]
将第四注意力图中非0元素的横纵坐标构成第一集合l;
[0020]
对所述第一集合l进行k近邻建图,即以第一集合中每个元素为节点,以节点之间的欧氏距离的倒数作为连接节点的边的权重得到邻接矩阵w,其中k为预设常数;
[0021]
基于邻接矩阵w,通过谱聚类方法求解下式得到最优子集合和
[0022][0023]
其中,w
p,q
代表邻接矩阵w中的第p行第q列的元素,l1和l2为l的子集合,表示空集;
[0024]
基于最优子集合和获取第一边界框box1(t1,l1,b1,r1)和第二边界框box2(t2,l2,b2,r2);t1,l1,b1,r1分别为最优子集合中元素的纵坐标最小值、横坐标最小值、纵坐标最大值、横坐标最大值;t2,l2,b2,r2分别为最优子集合中元素的纵坐标最小值、横坐标最小值、纵坐标最大值、横坐标最大值。
[0025]
在一些优选的实施方式中,将第一边界框、第二边界框、第二卷积特征进行聚合处理,得到图像级编码向量,其方法为:
[0026]
分别结合第一边界框box1(t1,l1,b1,r1)和第二边界框box2(t2,l2,b2,r2),利用faster r-cnn中的roi池化操作在第二卷积特征f2上进行池化操作,得到第三卷积特征f3和第四卷积特征f4;
[0027]
利用gem聚合操作,将第二卷积特征f2、第三卷积特征f3和第四卷积特征f4分别聚合为第一编码向量v1、第二编码向量v2和第三编码向量v3;
[0028]
将第一编码向量v1、第二编码向量v2和第三编码向量v3相加进而得到图像级编码向量。
[0029]
在一些优选的实施方式中,提取所述第四注意力图中的连通域,其方法为:采用python的opencv2库的opencv2.findcontours函数对所述第四注意力图进行处理,得到所述第四注意力图中的连通域。
[0030]
本发明的第二方面,提出了一种小样本目标检测系统,该系统包括:图像采集模块、潜在目标物体提取模块、编码向量获取模块、类别检测模块;
[0031]
所述图像采集模块,配置为机器人通过安装在自身的视觉传感器获取待检测场景的图像;
[0032]
所述潜在目标物体提取模块,配置为利用训练好的注意力卷积神经网络的densenet169骨干网络、注意力提取器获取待检测场景的图像对应的第四注意力图;提取所述第四注意力图中的连通域,获取各潜在目标物体的矩形边界框,并根据矩形边界框,在待检测场景的图像上裁剪出各潜在目标物体对应的图像;
[0033]
所述编码向量获取模块,配置为将各潜在目标物体对应的图像缩放至设定尺寸,并输入训练好的注意力卷积神经网络,得到各潜在目标物体对应的图像级编码向量;
[0034]
所述类别检测模块,配置为将各潜在目标物体对应的图像级编码向量与预构建的新类目标物体小样本数据库中的各图像级编码向量进行相似度计算,将最大相似度的图像对应的类别作为潜在目标物体的类别,进而实现小样本目标检测;
[0035]
其中,所述注意力卷积神经网络包括densenet169骨干网络、注意力提取器和聚合器;
[0036]
所述densenet169骨干网络,用于提取输入的图像的卷积特征,并将densenet169骨干网络第104层的输出作为第一卷积特征,将densenet169骨干网络第169层的输出作为
第二卷积特征;
[0037]
所述注意力提取器基于依次连接的卷积层、空间softmax运算层、均值滤波器、阈值化处理操作、图割处理操作构建;
[0038]
所述卷积层,用于对所述第一卷积特征进行卷积处理,将卷积处理后的特征图作为第一注意力图;所述空间softmax运算层,用于对所述第一注意力图进行softmax运算,得到第二注意力图;所述均值滤波器,用于对所述第二注意力图进行滤波处理,得到第三注意力图;
[0039]
所述阈值化处理操作,用于对第三注意力图进行阈值化处理,得到第四注意力图;所述图割处理操作,用于将所述第四注意力图中的非0元素划分成两个最优子集合,并分别得到这两个最优子集合对应的矩形边界框,作为第一边界框、第二边界框;
[0040]
所述聚合器,用于将第一边界框、第二边界框、第二卷积特征进行聚合处理,得到图像级编码向量。
[0041]
本发明的第三方面,提出了一种存储装置,其中存储有多条程序,所述程序适用于由处理器加载并执行以实现上述的小样本目标检测方法。
[0042]
本发明的第四方面,提出了一种处理设置,包括处理器、存储装置;处理器,适用于执行各条程序;存储装置,适用于存储多条程序;所述程序适用于由处理器加载并执行以实现上述的小样本目标检测方法。
[0043]
本发明的有益效果:
[0044]
本发明可以利用新类目标物体少量的数据,有效检测出与预训练数据集中的目标物体外观差异较大的新类目标物体,为机器人在助老助残、家庭服务等领域下的目标物体检测提供技术支持。
附图说明
[0045]
图1是本发明一种实施例的小样本目标检测方法的流程示意图;
[0046]
图2是本发明一种实施例的小样本目标检测系统的框架示意图。
具体实施方式
[0047]
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0048]
下面结合附图和实施例对本技术作进一步的详细说明。可以理解的是,此处所描述的具体实施例仅用于解释相关发明,而非对该发明的限定。另外还需要说明的是,为了便于描述,附图中仅示出了与有关发明相关的部分。
[0049]
需要说明的是,在不冲突的情况下,本技术中的实施例及实施例中的特征可以相互组合。
[0050]
本发明的一种小样本目标检测方法,如图1所示,包括以下步骤:
[0051]
步骤s10,机器人通过安装在自身的视觉传感器获取待检测场景的图像;
[0052]
步骤s20,利用训练好的注意力卷积神经网络的densenet169骨干网络、注意力提
取器获取待检测场景的图像对应的第四注意力图;提取所述第四注意力图中的连通域,获取各潜在目标物体的矩形边界框,并根据矩形边界框,在待检测场景的图像上裁剪出各潜在目标物体对应的图像;
[0053]
步骤s30,将各潜在目标物体对应的图像缩放至设定尺寸,并输入训练好的注意力卷积神经网络,得到各潜在目标物体对应的图像级编码向量;
[0054]
步骤s40,将各潜在目标物体对应的图像级编码向量与预构建的新类目标物体小样本数据库中的各图像级编码向量进行相似度计算,将最大相似度的图像对应的类别作为潜在目标物体的类别,进而实现小样本目标检测;
[0055]
其中,所述注意力卷积神经网络包括densenet169骨干网络、注意力提取器和聚合器;
[0056]
所述densenet169骨干网络,用于提取输入的图像的卷积特征,并将densenet169骨干网络第104层的输出作为第一卷积特征,将densenet169骨干网络第169层的输出作为第二卷积特征;
[0057]
所述注意力提取器基于依次连接的卷积层、空间softmax运算层、均值滤波器、阈值化处理操作、图割处理操作构建;
[0058]
所述卷积层,用于对所述第一卷积特征进行卷积处理,将卷积处理后的特征图作为第一注意力图;所述空间softmax运算层,用于对所述第一注意力图进行softmax运算,得到第二注意力图;所述均值滤波器,用于对所述第二注意力图进行滤波处理,得到第三注意力图;
[0059]
所述阈值化处理操作,用于对第三注意力图进行阈值化处理,得到第四注意力图;所述图割处理操作,用于将所述第四注意力图中的非0元素划分成两个最优子集合,并分别得到这两个最优子集合对应的矩形边界框,作为第一边界框、第二边界框;
[0060]
所述聚合器,用于将第一边界框、第二边界框、第二卷积特征进行聚合处理,得到图像级编码向量。
[0061]
为了更清晰地对本发明小样本目标检测方法进行说明,下面结合附图对本发明方法一种实施例中各步骤进行展开详述。
[0062]
在下述实施例中,先对注意力卷积神经网络的构建及训练过程进行详述,再对小样本目标检测方法获取待检测场景的图像中潜在目标物体的类别的过程进行描述。
[0063]
1、注意力卷积神经网络的构建及训练过程
[0064]
该实施例为一种较优的实现方式,预先构建一个包含densenet169骨干网络、注意力提取器和聚合器的图像检索网络,称之为注意力卷积神经网络,并结合三元组损失对注意力卷积神经网络在imagenet数据集上进行训练,获取注意力卷积神经网络的参数。具体如下:
[0065]
首先将imagenet数据集中的图像尺寸缩放至设定尺寸,本发明中优选缩放至512
×
512尺寸,之后将缩放后的图像送入densenet169骨干网络,获取densenet169骨干网络中第104层的输出并将其作为第一卷积特征f1,获取第169层的输出并将其作为第二卷积特征f2,其中第一卷积特征f1的尺寸为32
×
32
×
1280,第二卷积特征f2的尺寸为16
×
16
×
1664。
[0066]
将第一卷积特征f1输入注意力提取器中,其中注意力提取器由一个卷积核尺寸为1
×1×
1280的卷积层、空间softmax运算层、3
×
3的均值滤波器、阈值化处理操作、图割处理
操作依次连接而成。卷积核尺寸为1
×1×
1280的卷积层将第一卷积特征f1处理为第一注意力图a1,第一注意力图的尺寸为32
×
32
×
1;空间softmax运算层将第一注意力图a1处理为第二注意力图a2,具体处理见式(1):
[0067][0068]
其中a
1(a,b)
和a
2(a,b)
分别为a1和a2的第a行第b列的元素,β为可学习的缩放系数,a
1(h,w)
为a1的第h行第w列的元素;
[0069]3×
3的均值滤波器将第二注意力图a2进行滤波从而得到第三注意力图a3,3
×
3的均值滤波器采用python的opencv2库中的openscv2.blur函数加以实现;阈值化处理操作以第三注意力图a3中0.75倍最大值作为阈值,将第三注意力图a3进行处理,小于该阈值的元素置为0,从而得到第四注意力图a4;
[0070]
图割处理操作将第四注意力图a4中的非0元素划分成两个最优子集合,并分别得到这两个最优子集合对应的矩形边界框,具体过程如下:
[0071]
将第四注意力图a4中非0元素的横纵坐标构成第一集合其中l为第四注意力图a4中非0元素的个数,(xc,yc)为第四注意力图a4中第c个非0元素的横纵坐标,c=1,2,...,l。对第一集合进行k近邻建图,其中k为预设常数,本发明中优选设置为3,以第一集合中每个元素为节点,以节点之间的欧氏距离的倒数作为连接节点的边的权重得到邻接矩阵w,进而通过谱聚类方法求解式(2)得到最优子集合和其中谱聚类方法利用python的skleam库中的sklearn.cluster.spectralclustering函数予以实现。
[0072][0073]
其中w
p,q
代表邻接矩阵w中的第p行第q列的元素,l1和l2为l的子集合,表示空集。基于最优子集合和获取第一边界框box1(t1,l1,b1,r1)和第二边界框box2(t2,l2,b2,r2);t1,l1,b1,r1分别为最优子集合中元素的纵坐标最小值、横坐标最小值、纵坐标最大值、横坐标最大值;t2,l2,b2,r2分别为最优子集合中元素的纵坐标最小值、横坐标最小值、纵坐标最大值、横坐标最大值。
[0074]
将第一边界框box1(t1,l1,b1,r1)、第二边界框box2(t2,l2,b2,r2)和第二卷积特征f2输入聚合器中,得到图像级编码向量。首先分别结合第一边界框box1(t1,l1,b1,r1)和第二边界框box2(t2,l2,b2,r2),利用faster r-cnn中的roi池化操作在第二卷积特征f2上进行池化操作,得到第三卷积特征f3和第四卷积特征f4,其中第三卷积特征的尺寸为5
×5×
1664,第四卷积特征的尺寸为5
×5×
1664;再利用gem聚合操作,将第二卷积特征f2、第三卷积特征f3和第四卷积特征f4分别聚合为第一编码向量v1、第二编码向量v2和第三编码向量v3,将第一编码向量v1、第二编码向量v2和第三编码向量v3相加进而得到图像级编码向量v4,此即为注意力卷积神经网络的最终输出。
[0075]
在imagenet数据集中,选一个批量的imagenet图像,利用注意力卷积神经网络将它们转化为对应的图像级编码向量,这些图像级编码向量构建三元组损失,利用该损失对注意力卷积神经网络进行训练;然后,更换另一批量的imagenet图像按照上述方式继续对注意力卷积神经网络进行训练,直至imagenet数据集的图像被全部遍历;最终获得注意力卷积神经网络的参数。
[0076]
2、小样本目标检测方法
[0077]
将训练好的注意力卷积神经网络应用到本发明的小样本目标检测方法中,具体步骤如下:
[0078]
步骤s10,机器人通过安装在自身的视觉传感器获取待检测场景的图像;
[0079]
在本实施例中,机器人通过安装在自身的视觉传感器zed2采集待检测场景的图像i,图像尺寸为1920
×
1024。
[0080]
步骤s20,利用训练好的注意力卷积神经网络的densenet169骨干网络、注意力提取器获取待检测场景的图像对应的第四注意力图;提取所述第四注意力图中的连通域,获取各潜在目标物体的矩形边界框,并根据矩形边界框,在待检测场景的图像上裁剪出各潜在目标物体对应的图像;
[0081]
在本实施例中,将待检测场景的图像i输入训练好的注意力卷积神经网络中,获取其对应的第四注意力图,对该第四注意力图采用python的opencv2库的opencv2.findcontours函数进行处理,获得其中所有的连通域,记为其中,cj代表第j个连通域中各元素的坐标集合,j=1,2,...,d,d为连通域的个数;每个连通域对应一个潜在目标物体,根据获得各潜在目标物体的矩形边界框其中pboxj代表第j个潜在目标物体的矩形边界框,ptj,plj,pbj,prj分别代表第j个连通域中元素的纵坐标最小值、横坐标最小值、纵坐标最大值、横坐标最大值;根据各潜在目标物体的矩形边界框,在待检测场景的图像i上裁剪出各潜在目标物体对应的图像ij,j=1,2,...d,ij为第j个潜在目标物体对应的图像。
[0082]
步骤s30,将各潜在目标物体对应的图像缩放至设定尺寸,并输入训练好的注意力卷积神经网络,得到各潜在目标物体对应的图像级编码向量;
[0083]
在本实施例中,各潜在目标物体对应的图像ij(j=1,2,...d)首先被缩放至设定尺寸,即512
×
512尺寸,其中缩放采用python的opencv2库中的opencv2.resize函数予以实现;将缩放过的图像依次输入训练好的注意力卷积神经网络中,获得各潜在目标物体对应的图像级编码向量v
4,j
,j=1,2,...d。
[0084]
步骤s40,将各潜在目标物体对应的图像级编码向量与预构建的新类目标物体小样本数据库中的各图像级编码向量进行相似度计算,将最大相似度的图像对应的类别作为潜在目标物体的类别,进而实现小样本目标检测;
[0085]
在本实施例中,针对新类目标物体离线构建小样本数据库,具体的,对每一个新类目标物体,采集n张不同视角的图像,要求新类目标物体在图像中所占的比例不低于50%,本实施例中n优先设置为20,将这些采集的图像送入训练好的注意力卷积网络中得到对应
的图像级编码向量;各新类目标物体的不同视角的图像所对应的图像级编码向量及其对应的类别构成新类目标物体小样本数据库{yf,v
4,f,g
},f=1,2,...,m,g=1,2,...,n,其中,yf是第f个新类目标物体的类别,m为新类目标物体的个数;
[0086]
对第j个潜在目标物体的图像级编码向量v
4,j
,j=1,2,...d,将其与离线构建的新类目标物体小样本数据库中的各图像级编码向量进行相似度计算,计算公式如式(3)所述:
[0087][0088]
其中v
4,j,t
和v
4,f,g,t
分别代表图像级编码向量v
4,j
和v
4,f,g
的第t个元素,t=1,2,...,c,c代表图像级编码向量的维度。
[0089]
对于第j个潜在目标物体(j=1,2,...d),根据式(4)在新类目标物体小样本数据库检索出与其有最大相似度的图像的索引f
*
和g
*
,根据索引f
*
对应的得到第j个潜在目标物体的类别;得到所有潜在目标物体的类别即完成针对待检测场景的图像的小样本目标检测。
[0090][0091]
采用本发明能够实现新类目标物体的检测,有效检测出与预训练数据集中的目标物体外观差异较大的新类目标物体,为机器人在助老助残、家庭服务等领域下的目标物体检测提供技术支持。
[0092]
本发明第二实施例的一种小样本目标检测系统,如图2所示,包括:图像采集模块100、潜在目标物体提取模块200、编码向量获取模块300、类别检测模块400;
[0093]
所述图像采集模块100,配置为机器人通过安装在自身的视觉传感器获取待检测场景的图像;
[0094]
所述潜在目标物体提取模块200,配置为利用训练好的注意力卷积神经网络的densenet169骨干网络、注意力提取器获取待检测场景的图像对应的第四注意力图;提取所述第四注意力图中的连通域,获取各潜在目标物体的矩形边界框,并根据矩形边界框,在待检测场景的图像上裁剪出各潜在目标物体对应的图像;
[0095]
所述编码向量获取模块300,配置为将各潜在目标物体对应的图像缩放至设定尺寸,并输入训练好的注意力卷积神经网络,得到各潜在目标物体对应的图像级编码向量;
[0096]
所述类别检测模块400,配置为将各潜在目标物体对应的图像级编码向量与预构建的新类目标物体小样本数据库中的各图像级编码向量进行相似度计算,将最大相似度的图像对应的类别作为潜在目标物体的类别,进而实现小样本目标检测;
[0097]
其中,所述注意力卷积神经网络包括densenet169骨干网络、注意力提取器和聚合器;
[0098]
所述densenet169骨干网络,用于提取输入的图像的卷积特征,并将densenet169骨干网络第104层的输出作为第一卷积特征,将densenet169骨干网络第169层的输出作为第二卷积特征;
[0099]
所述注意力提取器基于依次连接的卷积层、空间softmax运算层、均值滤波器、阈值化处理操作、图割处理操作构建;
[0100]
所述卷积层,用于对所述第一卷积特征进行卷积处理,将卷积处理后的特征图作为第一注意力图;所述空间softmax运算层,用于对所述第一注意力图进行softmax运算,得到第二注意力图;所述均值滤波器,用于对所述第二注意力图进行滤波处理,得到第三注意力图;
[0101]
所述阈值化处理操作,用于对第三注意力图进行阈值化处理,得到第四注意力图;所述图割处理操作,用于将所述第四注意力图中的非o元素划分成两个最优子集合,并分别得到这两个最优子集合对应的矩形边界框,作为第一边界框、第二边界框;
[0102]
所述聚合器,用于将第一边界框、第二边界框、第二卷积特征进行聚合处理,得到图像级编码向量。
[0103]
所述技术领域的技术人员可以清楚的了解到,为描述的方便和简洁,上述描述的系统的具体的工作过程及有关说明,可以参考前述方法实施例中的对应过程,在此不再赘述。
[0104]
需要说明的是,上述实施例提供的小样本目标检测系统,仅以上述各功能模块的划分进行举例说明,在实际应用中,可以根据需要而将上述功能分配由不同的功能模块来完成,即将本发明实施例中的模块或者步骤再分解或者组合,例如,上述实施例的模块可以合并为一个模块,也可以进一步拆分成多个子模块,以完成以上描述的全部或者部分功能。对于本发明实施例中涉及的模块、步骤的名称,仅仅是为了区分各个模块或者步骤,不视为对本发明的不当限定。
[0105]
本发明第三实施例的一种存储装置,其中存储有多条程序,所述程序适用于由处理器加载并实现上述的小样本目标检测方法。
[0106]
本发明第四实施例的一种处理装置,包括处理器、存储装置;处理器,适于执行各条程序;存储装置,适于存储多条程序;所述程序适于由处理器加载并执行以实现上述的小样本目标检测方法。
[0107]
所述技术领域的技术人员可以清楚的了解到,为描述的方便和简洁,上述描述的存储装置、处理装置的具体工作过程及有关说明,可以参考前述方法实例中的对应过程,在此不再赘述。
[0108]
本领域技术人员应该能够意识到,结合本文中所公开的实施例描述的各示例的模块、方法步骤,能够以电子硬件、计算机软件或者二者的结合来实现,软件模块、方法步骤对应的程序可以置于随机存储器(ram)、内存、只读存储器(rom)、电可编程rom、电可擦除可编程rom、寄存器、硬盘、可移动磁盘、cd-rom、或技术领域内所公知的任意其它形式的存储介质中。为了清楚地说明电子硬件和软件的可互换性,在上述说明中已经按照功能一般性地描述了各示例的组成及步骤。这些功能究竟以电子硬件还是软件方式来执行,取决于技术方案的特定应用和设计约束条件。本领域技术人员可以对每个特定的应用来使用不同方法来实现所描述的功能,但是这种实现不应认为超出本发明的范围。
[0109]
术语“第一”、“第二”、“第三”等是用于区别类似的对象,而不是用于描述或表示特定的顺序或先后次序。
[0110]
至此,已经结合附图所示的优选实施方式描述了本发明的技术方案,但是,本领域技术人员容易理解的是,本发明的保护范围显然不局限于这些具体实施方式。在不偏离本发明的原理的前提下,本领域技术人员可以对相关技术特征做出等同的更改或替换,这些
更改或替换之后的技术方案都将落入本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1