片段指针交互模型的构建方法及社会传感灾情监测方法
1.本发明涉及自然语言处理技术领域,具体涉及一种片段指针交互模型的构建方法及社会传感灾情监测方法。
背景技术:
2.自然灾害的发生,给人们带来了诸多不便,需要及时开展救灾工作,恢复正常生活秩序。传统的灾情收集工作主要由相关工作人员手工完成,但有限的工作人员很难在短时间内做到对灾情事件的全覆盖,且部分灾情信息需要工作人员实地勘察上报,常常在灾害发生较长时间后才能有效掌握灾情信息,即,传统的灾情收集工作耗费较大的人力物力且及时性差。近年来,随着社交媒体的发展,社交媒体用户可以通过移动设备便捷地发送自己生活状况,而在灾害发生的第一时间,社交媒体用户作为灾害的直接接触群体,扮演着动态传感器的角色,而社交媒体用户发送的短文本充当着社会传感信息的作用,这部分灾害有关的短文本作为社会传感的载体,极大的拓宽了灾情状况的获取途径,且这些信息具有很强的实时性,无需人工再次录入,能够有效提升灾情处理效率。
3.基于上述短文本的灾情事件检测,其重点在于灾情事件触发词的检测,灾情事件触发词指用于标示灾情事件发生的词语,例如,“台风正面袭击xx市xx区,使xx区多条主干道的绿化树倒塌堵塞交通”这句话中的“倒塌”为灾情事件触发词,通常检测出灾情事件触发词就可检测出灾情事实。
4.然而,现有技术缺乏一种有效的基于社交媒体短文本的灾情事件触发词检测方法。
技术实现要素:
5.本发明解决的问题是如何实现基于社交媒体短文本的灾情事件触发词检测方法。
6.本发明提出一种片段指针交互模型的构建方法,所述片段指针交互模型包括基于预训练语言模型的实体感知编码层、指针网络检测层以及区间交互感知层;所述片段指针交互模型的构建方法包括以下步骤:
7.获取训练文本集,其中,所述训练文本集为社交媒体文本数据经过预处理操作后得到的文本数据;
8.将所述训练文本集中的训练文本输入所述实体感知编码层,获得所述实体感知编码层输出所述训练文本的语义表征;
9.将所述训练文本的语义表征输入所述指针网络检测层,获得所述指针网络检测层预测的所述训练文本中每个字的起始区间表示和终止区间表示;
10.将所述起始区间表示和所述终止区间表示输入所述区间交互感知层,由所述区间交互感知层对所述起始区间表示和所述终止区间表示进行特征交互,获得特征交互后的起始类别标签和终止类别标签;
11.基于所述起始类别标签和所述终止类别标签生成对应的起始类别列表和终止类
别列表,并基于所述起始类别列表和所述终止类别列表进行解码获得灾情事件触发词。
12.可选地,所述预处理操作包括以下步骤:
13.基于预设分词算法从所述社交媒体文本中抽取实体信息,其中,所述实体信息包括抽取的实体词的实体类型和所述实体词在所述社交媒体文本中的位置信息;
14.将所述从所述社交媒体文本抽取的实体词的实体类型和位置信息附加在所述社交媒体文本后,作为所述训练文本;
15.所述预训练语言模型为bert模型;所述将所述训练文本集中的训练文本输入所述实体感知编码层,获得所述实体感知编码层输出所述训练文本的语义表征包括输入所述实体感知编码层时的输入编码步骤,具体包括:
16.将所述社交媒体文本编码为上下句形式,其中一句对应所述社交媒体文本全文的顺序编码,另一句对应从所述社交媒体文本抽取的实体词的实体类型和位置信息的编码。
17.可选地,在所述基于预设分词算法从所述社交媒体文本中抽取实体信息的步骤之前,所述预处理操作还包括以下步骤:
18.获取原始的社交媒体文本数据,并采用以下至少一种操作对所述原始的社交媒体文本数据进行处理:
19.对所述原始的社交媒体文本数据进行去重处理;
20.采用预设的关键字模板对所述原始的社交媒体文本数据进行过滤处理,其中,所述关键字模板中的关键字包括灾情事实无关性文本;
21.对所述原始的社交媒体文本数据中的非事件句进行过滤处理。
22.可选地,所述将所述起始区间表示和所述终止区间表示输入所述区间交互感知层,由所述区间交互感知层对所述起始区间表示和所述终止区间表示进行特征交互,获得特征交互后的起始类别标签和终止类别标签包括以下步骤:
23.将所述起始区间表示和所述终止区间表示进行交互后,再融入原始的所述训练文本的语义表征,得到第一特征;
24.将所述第一特征经过线性处理后,得到第二特征;
25.将所述第一特征和所述第二特征进行交互后,输出起始类别标签或终止类别标签。
26.可选地,所述将所述起始区间表示和所述终止区间表示输入所述区间交互感知层,由所述区间交互感知层对所述起始区间表示和所述终止区间表示进行特征交互,获得特征交互后的起始类别标签和终止类别标签包括:
27.r=tanh(wd·
concat(us,ue)),
ꢀꢀꢀ
(1)
28.m
(1)
=w
(1)
·
concat(h,r)+b
(1)
,
ꢀꢀꢀ
(2)
29.m
(2)
=w
(2)
·
(layernorm(m
(1)
))+b
(2)
,
ꢀꢀꢀ
(3)
30.p
hin
(h,us,ue)=w
(3)
·
concat(m
(1)
,m
(2)
)+b
(3)
,
ꢀꢀꢀ
(4)
31.其中,公式(1)包括将所述起始区间表示和所述终止区间表示进行交互;公式(2)包括将所述起始区间表示和所述终止区间表示进行交互后,再融入原始的所述训练文本的语义表征,得到第一特征;公式(3)包括将所述第一特征经过线性处理后,得到第二特征;公式(4)包括将所述第一特征和所述第二特征进行交互后,输出起始类别标签或终止类别标签;
32.r指所述起始区间表示和所述终止区间交互后所得特征,us指所述起始区间表示,ue指所述终止区间表示,h指原始的所述训练文本的语义表征,m
(1)
指所述第一特征,m
(2)
指所述第二特征,p
hin
(h,us,ue)指所述起始类别标签或终止类别标签,wd、w
(1)
、w
(2)
、w
(3)
均为权重矩阵,b
(1)
、b
(2)
、b
(3)
均为偏置参数。
33.可选地,所述基于所述起始类别标签和所述终止类别标签生成对应的起始类别列表和终止类别列表包括:
34.p
start
=argmax
eachrow
(p
hinstart
),
35.p
end
=argmax
eachrow
(p
hinend
),
36.其中,p
start
表示所述起始类别列表,p
end
表示所述终止类别列表,p
hinstart
表示所述起始类别标签,p
hinend
表示所述终止类别标签。
37.可选地,所述指针网络检测层包括起始位置判定模块和终止位置判定模块;所述将所述训练文本的语义表征输入所述指针网络检测层,获得所述指针网络检测层预测的所述训练文本中每个字的起始区间表示和终止区间表示包括以下步骤:
38.将所述训练文本的语义表征输入所述起始位置判定模块,获得所述起始位置判定模块预测的所述训练文本中每个字的起始区间表示;
39.获取所述训练文本中每个字的真实的起始区间表示,将所述真实的起始区间表示和所述训练文本的语义表征输入所述终止位置判定模块,获得所述终止位置判定模块预测的所述训练文本中每个字的终止区间表示。
40.本发明还提出一种基于片段指针交互模型的社会传感灾情监测方法,包括:
41.获取社交媒体文本数据,对所述社交媒体文本数据进行预处理操作,得到灾情监测文本;
42.将所述灾情监测文本输入至训练好的片段指针交互模型,获得所述片段指针交互模型输出的灾情事件触发词,其中,所述片段指针交互模型通过如上所述片段指针交互模型的构建方法构建而成。
43.可选地,所述片段指针交互模型包括基于预训练语言模型的实体感知编码层、指针网络检测层以及区间交互感知层,所述指针网络检测层包括起始位置判定模块和终止位置判定模块;所述将所述灾情监测文本输入至训练好的片段指针交互模型,获得所述片段指针交互模型输出的灾情事件触发词包括以下步骤:
44.将所述灾情监测文本输入所述实体感知编码层,获得所述实体感知编码层输出所述灾情监测文本的语义表征;
45.将所述灾情监测文本的语义表征输入所述起始位置判定模块,获得所述起始位置判定模块预测的所述灾情监测文本中每个字的起始区间表示;
46.将所述起始位置判定模块预测的所述灾情监测文本中每个字的起始区间表示,和所述灾情监测文本的语义表征输入所述终止位置判定模块,获得所述终止位置判定模块预测的所述灾情监测文本中每个字的终止区间表示;
47.将所述起始区间表示和所述终止区间表示输入所述区间交互感知层,由所述区间交互感知层对所述起始区间表示和所述终止区间表示进行特征交互,获得特征交互后的起始类别标签和终止类别标签;
48.基于所述起始类别标签和所述终止类别标签生成对应的起始类别列表和终止类
别列表,并基于所述起始类别列表和所述终止类别列表进行解码获得灾情事件触发词。
49.本发明还提出一种基于片段指针交互模型的社会传感灾情监测装置,包括存储有计算机程序的计算机可读存储介质和处理器,所述计算机程序被所述处理器读取并运行时,实现如上所述的基于片段指针交互模型的社会传感灾情监测方法。
50.本发明通过利用基于指针网络架构的指针网络检测层,通过框定实体区间实现对社交媒体文本数据中事件触发词的检测和识别,因指针网络架构具有较快的预测速度,可实现比传统crf(条件随机场)方式更快的事件检测,能够有效提升检测效率,且社交媒体文本数据中无关标签很多,且口语化,传统crf方式对社交媒体文本数据这种标签稀疏的数据的事件触发词抽取效果不佳,采用指针网络架构也可提升预测精度。此外,采用基于highway network(高速网络)的区间交互感知层提升触发词区间信息的交互能力,将区间终止位置信息与区间起始位置信息充分融合后,用于确定最终的起始类别列表和终止类别列表,进而提高模型的检测精度,实现有效快速的事件检测。
附图说明
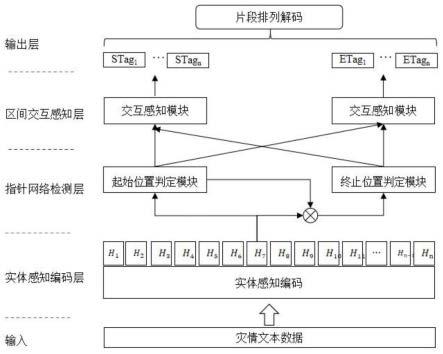
51.图1为本发明实施例片段指针交互模型的构建方法中片段指针交互模型整体结构一实施例示意图;
52.图2为本发明实施例片段指针交互模型的构建方法片段指针交互模型的指针网络检测层结构的一实施例示意图;
53.图3为本发明实施例片段指针交互模型的构建方法片段指针交互模型的指针区间交互感知层结构的一实施例示意图;
54.图4为本发明实施例片段指针交互模型的构建方法一流程示意图;
55.图5为本发明实施例片段指针交互模型的构建方法中文本编码方式一实施例示意图;
56.图6为本发明实施例片段指针交互模型的构建方法中实体感知编码层一实施例示意图;
57.图7为本发明实施例片段指针交互模型的构建方法中预处理操作一实施例示意图。
具体实施方式
58.为使本发明的上述目的、特征和优点能够更为明显易懂,下面结合附图对本发明的具体实施例做详细的说明。
59.本发明提出一种片段指针交互模型的构建方法,片段指针交互模型用于实现社会传感灾情监测方法。本发明中片段指针交互模型包括基于预训练语言模型的实体感知编码层、指针网络检测层以及区间交互感知层,区间交互感知层包含交互感知模块。图1为本发明构建的片段指针交互模型整体结构一实施例示意图。
60.本发明一实施例中,如图4,所述片段指针交互模型的构建方法包括以下步骤:
61.步骤s1,获取训练文本集,其中,所述训练文本集为社交媒体文本数据经过预处理操作后得到的文本数据。
62.其中,社交媒体文本数据指用户发布在微博或微信等社交媒体上的文本数据。在
构建训练文本集时,首先对社交媒体文本数据执行预处理操作,再对预处理后的文本数据进行灾情事件标注,将其划分为训练文本集和测试文本集,训练文本集用于执行包含步骤s2-s6在内的训练操作,在训练完成后,将测试文本集用于送入片段指针交互模型评估片段指针交互模型训练的结果。
63.其中,对预处理后的文本数据进行灾情事件标注,举例而言,社交媒体文本数据为“因台风导致路侧绿化带棕榈树倒塌,相关路段交通封闭”,则“倒塌”为植被损失的触发词,“封闭”为交通故障的触发词,为触发词的首尾字进行对应灾情事件标注,将“倒”“塌”分别标注为植被损失,“封”“闭”分别标注为交通故障。
64.可选地,预处理操作包括以下至少一种操作:对所述原始的社交媒体文本数据进行去重处理;采用预设的关键字模板对所述原始的社交媒体文本数据进行过滤处理;对所述原始的社交媒体文本数据中的非事件句进行过滤处理。
65.其中,有关对所述原始的社交媒体文本数据进行去重处理,具体地,因为社交媒体的用户自主性较强,同一用户可能发布多条相同内容的文本,不同用户也可能发布内容相同的文本,而且,在某些社交媒体的编码机制,如微博的编码机制中,用户转发内容和发布新内容都会获得唯一的id标识,因此以用户id为区分的爬虫程序可能重复爬取了大量相似内容或相同内容,所以需要对原始的社交媒体文本数据进行去重处理,在不影响灾情检测的同时,降低数据处理量。可选地,为了高效去除重复的文本数据,本发明实施例采用simhash算法,该算法基于原始语句中包含的词语生成语句的特征向量,无需外部数据和词组库,能够极大节省时间和空间资源,提高计算效率。具体地,simhash算法首先对原始数据进行分词,随后为分词设定权重,通过hash的方法计算出每个分词的哈希值,分别与对应的权重相乘得到每个分词的加权向量,最后将所有词的加权向量相加得到整句话的加权向量值,对整句话的加权向量值进行二值化操作得到该语句的指纹向量,再通过计算不同语句指纹向量之间的汉明距离得到相似度,判定相似度大于一定值的语句为重复语句,再进行去重处理。
66.有关采用预设的关键字模板对所述原始的社交媒体文本数据进行过滤处理。其中,关键字模板中的关键字包括灾情事实无关性文本。因为社交媒体文本数据内容丰富多元,并不一定都是与灾情相关的文本,而且,在气象灾害在发生前期,相关部门及媒体也会根据预测结果发布一定的信息进行预警,这种非事实性文本会对本文的数据构建造成干扰。所以,设置关键字模板,用于过滤掉与灾情事实无关的文本。可选地,关键字模板包括常识科普类模板和预警信息类,其中,常识科普类包含科普知识、气象知识等关键字模板,预警信息类包含预警、提醒、预测等关键字模板。
67.有关对所述原始的社交媒体文本数据中的非事件句进行过滤处理。因为因为社交媒体文本数据中存在相当多的短文本没有提到事件,因此,需要对其中的非事件句进行过滤。此处可采用逻辑回归(lr)模型构建二分类模型,用以区分事件句与非事件句,具体可构建带二分类事件标注的训练数据进行模型训练,因逻辑回归(lr)模型为常用模型,此处不赘述。
68.可选地,如图7,预处理操作包括:首先执行对所述原始的社交媒体文本数据进行去重处理,再采用预设的关键字模板对所述原始的社交媒体文本数据进行过滤处理,最后对所述原始的社交媒体文本数据中的非事件句进行过滤处理。
69.通过上述预处理操作,可将原始的社交媒体文本数据中的重复数据、灾情无关数据及非事件数据筛除出去,在不影响片段指针交互模型的模型训练效果的同时,降低数据处理量,减少人工标注耗时,减少不相干数据的干扰,提升数据质量,进而提升片段指针交互模型的训练效率和训练效果。
70.步骤s2,将所述训练文本集中的训练文本输入所述实体感知编码层,获得所述实体感知编码层输出所述训练文本的语义表征。
71.训练文本输入实体感知编码层后,由实体感知编码层输出向量形式的语义表征。预训练语言模型可选为bert模型。
72.步骤s3,将所述训练文本的语义表征输入所述指针网络检测层,获得所述指针网络检测层预测的所述训练文本中每个字的起始区间表示和终止区间表示。
73.图2为本发明构建的片段指针交互模型指针网络检测层结构的一实施例示意图。如图2,指针网络检测层包括起始位置判定模块(start index block,简称sib)和终止位置判定模块(end index block,简称eib)。如图2,起始位置判定模块包括dropout处理、linear线性化处理和relu函数处理,终止位置判定模块包括起始区间表示输入start logit、dropout处理、融合处理、dense1处理(第一全连接处理)、tanh函数处理、layernorm处理(归一化处理)、dense2处理(第二全连接处理)和relu函数处理。
74.具体地,起始位置判定模块sib将输入的序列标记转为对每个字进行c分类,从而获取每个字的起始区间表示,其中,c为事件类别数。通过起始位置判定模块sib获得的起始区间表示如下:
75.u
start
=softmax
eachrow
(relu(e
·
t
start
+b
end
))∈r
n*c
,
76.其中,u
start
是起始位置判定模块sib的输出概率,e∈r
n*d
表示bert的语义表征输出,t
start
∈r
d*c
为权重矩阵,d是bert向量维度,n是输入的字的数量,即句子长度,b
end
为偏置参数,eachrow表示是对每个字进行c分类。
77.终止位置判定模块eib为了获取每个字的终止区间表示,采用的同样是对每个字进行c分类,但需要将起始区间表示作为额外的信息输入,以提升实体区间感知,即终止位置判定模块eib将训练文本的语义表征结合起始区间表示作为输入。通过终止位置判定模块eib获得的终止区间表示如下:
78.u
end
=softmax
eachrow
(relu(m
·
t
end
+b
end
))∈r
n*c
,
79.m=layernorm(z),
80.zi=tanh(w
·
concat(u
istart
,ei)),
81.其中,u
end
是终止位置判定模块eib的输出概率,u
istart
指第i个字的起始区间表示,ei指第i个字的语义表征,w指dense1的权重,m指dense2的权重,t
end
∈r
d*c
为权重矩阵。
82.其中,因为起始位置判定模块sib还在训练阶段,其预测结果还不准确,若其输出错误结果,也会影响终止位置判定模块eib的训练,因此,在训练过程中,为了避免错误累计传播的问题,同时加快模型收敛,将真实的起始区间表示输入终止位置判定模块eib。具体地,所述步骤s3包括以下步骤:将所述训练文本的语义表征输入所述起始位置判定模块,获得所述起始位置判定模块预测的所述训练文本中每个字的起始区间表示;获取所述训练文本中每个字的真实的起始区间表示,将所述真实的起始区间表示和所述训练文本的语义表征输入所述终止位置判定模块,获得所述终止位置判定模块预测的所述训练文本中每个字
的终止区间表示。
83.步骤s4,将所述起始区间表示和所述终止区间表示输入所述区间交互感知层,由所述区间交互感知层对所述起始区间表示和所述终止区间表示进行特征交互,获得特征交互后的起始类别标签和终止类别标签。
84.为了进一步提升实体区间检测的效果,设置区间交互感知层。在指针网络检测层中,虽然终止位置判定模块eib能够感知起始位置,但是在预测起始位置的时候,无法获取区间终止信息,这造成了预测阶段的偏差,因此,在区间交互感知层中,对起始区间表示和终止区间表示进行特征交互,生成起始类别标签和终止类别标签。
85.可选地,步骤s4包括以下步骤:将所述起始区间表示和所述终止区间表示进行交互后,再融入原始的所述训练文本的语义表征,得到第一特征;将所述第一特征经过线性处理后,得到第二特征;将所述第一特征和所述第二特征进行交互后,输出起始类别标签或终止类别标签。
86.具体而言,如图3,区间交互感知层中的交互感知模块包括:linear(线性函数)、layernorm(归一化)。起始类别标签或终止类别标签通过下述的方式计算:
87.r=tanh(wd·
concat(us,ue)),
ꢀꢀꢀ
(1)
88.m
(1)
=w
(1)
·
concat(h,r)+b
(1)
,
ꢀꢀꢀ
(2)
89.m
(2)
=w
(2)
·
(layernorm(m
(1)
))+b
(2)
,
ꢀꢀꢀ
(3)
90.p
hin
(h,us,ue)=w
(3)
·
concat(m
(1)
,m
(2)
)+b
(3)
,
ꢀꢀꢀ
(4)
91.其中,公式(1)包括将所述起始区间表示和所述终止区间表示进行交互;公式(2)包括将所述起始区间表示和所述终止区间表示进行交互后,再融入原始的所述训练文本的语义表征,得到第一特征;公式(3)包括将所述第一特征经过线性处理后,得到第二特征;公式(4)包括将所述第一特征和所述第二特征进行交互后,输出起始类别标签或终止类别标签;
92.r指所述起始区间表示和所述终止区间交互后所得特征,us指所述起始区间表示,ue指所述终止区间表示,h指原始的所述训练文本的语义表征,m
(1)
指所述第一特征,m
(2)
指所述第二特征,p
hin
(h,us,ue)指所述起始类别标签或终止类别标签,wd、w
(1)
、w
(2)
、w
(3)
均为权重矩阵,b
(1)
、b
(2)
、b
(3)
均为偏置参数,其中,wd为经linear线性化的权重矩阵。
93.其中,各采用一个如上所述的交互感知模块分别计算起始类别标签(p
hinstart
)和终止类别标签(p
hinend
),二者为完全对称的双塔结构,仅训练目标不同,一个用于判断区间头部,一个用于判断区间尾部,可在训练阶段通过构建不同的训练数据标签,以训练出对应的参数,进而实现相应的训练目标。以举例而言,社交媒体文本数据为“因台风导致路侧绿化带棕榈树倒塌,相关路段交通封闭”,“倒塌”为植被损失的触发词,“封闭”为交通故障的触发词,为触发词的首尾字进行对应灾情事件标注,将“倒”“塌”分别标注为植被损失,“封”“闭”分别标注为交通故障,则识别起始类别标签的交互感知模块的训练样本为:带触发词首字标注的文本,即带“倒”“封”二字灾情事件标注的文本,此时,句子中其他无关的字,使用other标签;识别终止类别标签的交互感知模块的训练样本为:带触发词尾字标注的文本,即带“塌”“闭”二字灾情事件标注的文本,此时,句子中其他无关的字,使用other标签。
94.通过片段指针架构进行触发词区间信息的抽取,并采用highway network提升触发词区间信息的交互能力,进而有效地通过区间交互实现快速有效的事件检测。
95.步骤s5,基于所述起始类别标签和所述终止类别标签生成对应的起始类别列表和终止类别列表,并基于所述起始类别列表和所述终止类别列表进行解码获得灾情事件触发词。
96.可选地,可将起始类别标签和终止类别标签分别经过argmax处理后得到起始类别列表和终止类别列表,经argmax处理后得到起始类别列表和终止类别列表为1维的类别标签列表。具体地,步骤s5中所述基于所述起始类别标签和所述终止类别标签生成对应的起始类别列表和终止类别列表包括:
97.p
start
=argmax
eachrow
(p
hinstart
),
98.p
end
=argmax
eachrow
(p
hinend
),
99.其中,p
start
表示所述起始类别列表,p
end
表示所述终止类别列表,p
hinstart
表示所述起始类别标签,p
hinend
表示所述终止类别标签。
100.基于所述起始类别列表和所述终止类别列表进行解码获得灾情事件触发词,具体地,获取输入的训练文本的句子长度length和触发词最大长度s,对于训练文本中的每个字,首先,从起始类别列表中获取字的起始类别,判断字的起始类别是否为非事件类别标签,若为非事件类别标签,则直接跳过当前字,处理下一个字,若为事件类别标签,则以当前字作为当前事件触发词的开始边界,在终止类别列表中当前字之后的位置,以触发词最大长度s为限制,查找终止边界,如果找到一个同类别标签的字,则当前事件触发词寻找结束,继续开始寻找下一个触发词。
101.本发明实施例通过利用基于指针网络架构的指针网络检测层,通过框定实体区间实现对社交媒体文本数据中事件触发词的检测和识别,因指针网络架构具有较快的预测速度,可实现比传统crf方式更快的事件检测,能够有效提升检测效率,且社交媒体文本数据中无关标签很多,且口语化,传统crf方式对社交媒体文本数据这种标签稀疏的数据的事件触发词抽取效果不佳,采用指针网络架构也可提升预测精度。此外,采用基于highway network的区间交互感知层提升触发词区间信息的交互能力,将区间终止位置信息与区间起始位置信息充分融合后,用于确定最终的起始类别列表和终止类别列表,进而提高模型的检测精度,实现有效快速的事件检测。
102.可选地,所述预处理操作包括以下步骤:
103.基于预设分词算法从所述社交媒体文本中抽取实体信息,其中,所述实体信息包括抽取的实体词的实体类型和所述实体词在所述社交媒体文本中的位置信息;将所述从所述社交媒体文本抽取的实体词的实体类型和位置信息附加在所述社交媒体文本后,作为所述训练文本。
104.由于语言的复杂性,不同事件可能存在相同的事件触发词用于指示不同的事件类型,例如,s1“台风正面袭击xx市xx区,使xx区多条主干道的绿化树倒塌堵塞交通”、s2“事发现场,xx楼的主体建筑被大风吹垮,主体建筑倒塌”,其中的s1中的倒塌指示了“交通问题”,s2中的倒塌指示了“民生问题”。因此有必要关注触发词的歧义性问题。
105.通过对灾害领域数据的观察,发现在灾害文本中的名词、地名、人名的客观实体对于事件的类别能起到辅助判别作用,从而解决触发词的歧义性问题。因此,利用如jieba分词等的预设分词算法对社交媒体文本进行先一步的分词处理,抽取出其中的实体信息,记录对应的实体类型(实体类型是通过jieba识别的地名、事物名称等)和文本对应的下标(下
标是实体的位置信息),将抽取的实体词的实体类型和位置信息附加在社交媒体文本后,作为训练文本。
106.进一步地,所述预训练语言模型为bert模型;所述步骤s2包括输入所述实体感知编码层时的输入编码步骤,具体包括:
107.将所述社交媒体文本编码为上下句形式,其中一句对应所述社交媒体文本全文的顺序编码,另一句对应从所述社交媒体文本抽取的实体词的实体类型和位置信息的编码。
108.为了可插拔式地将实体信息融入预训练语言模型,本发明有别于传统的文本信息输入方式如图5(a),采用了如图5(b)所示的文本编码方式,图5(a)中,采用[cls]text[sep]形式编码文本,并按顺序编码每个字的位置,而图5(b)中,采用[cls]text[sep]text-entity[sep]形式编码文本,其中,text-entity用于编码实体类型,位置编码则采用相应实体词的位置。
[0109]
进一步地,如图6,输入编码包含三部分,word编码用于表征语义;segment编码用于学习上下句信息;position编码用于提供位置信息,本发明在bert模型原始的输入方式基础上进行了更改,将[cls]text[sep]形式的单句输入改为上下句形式输入。一实施方式中,如图6,上句对应社交媒体文本全文的顺序编码,下句对应从社交媒体文本抽取的实体词的实体类型和位置信息的编码,其形式为[cls]text[sep]text-entity[sep],修改position编码,上半句按顺序进行位置表示,下半句中各个实体对应的position。另一实施方式中,上句对应从社交媒体文本抽取的实体词的实体类型和位置信息的编码,下句对应社交媒体文本全文的顺序编码。
[0110]
通过改变传统的文本编码方式,抽取事件相关实体词信息,融入文本编码中,充分利用句子中的实体信息,能够减轻事件检测问题中触发词歧义性的干扰,有效提升预测精度。
[0111]
可选地,在所述基于预设分词算法从所述社交媒体文本中抽取实体信息的步骤之前,所述预处理操作还包括以下步骤:
[0112]
获取原始的社交媒体文本数据,并采用以下至少一种操作对所述原始的社交媒体文本数据进行处理:对所述原始的社交媒体文本数据进行去重处理;采用预设的关键字模板对所述原始的社交媒体文本数据进行过滤处理,其中,所述关键字模板中的关键字包括灾情事实无关性文本;对所述原始的社交媒体文本数据中的非事件句进行过滤处理。上述三种操作的具体内容已在上文详述,此处不赘述。
[0113]
可选地,本发明采用交叉熵损失函数训练片段指针交互模型。片段指针交互模型的损失函数表示如下:
[0114]
l
start
=ce(p
start
,y
start
),
[0115]
l
end
=ce(p
end
,y
end
),
[0116]
l=l
start
+l
end
,
[0117]
其中,l
start
指起始位置判定模块的损失函数,l
end
指终止位置判定模块,l指片段指针交互模型总的损失函数,p
start
指起始位置判定模块预测的区间起始位置,y
start
指实际的区间起始位置,p
end
指终止位置判定模块预测的区间终止位置,y
end
指实际的区间终止位置。
[0118]
本发明还提出一种基于片段指针交互模型的社会传感灾情监测方法。在本发明一实施例中,本发明基于片段指针交互模型的社会传感灾情监测方法包括:
[0119]
获取社交媒体文本数据,对所述社交媒体文本数据进行预处理操作,得到灾情监测文本。
[0120]
将所述灾情监测文本输入至训练好的片段指针交互模型,获得所述片段指针交互模型输出的灾情事件触发词,其中,所述片段指针交互模型通过如上所述片段指针交互模型的构建方法构建而成。
[0121]
其中,社交媒体文本数据指用户发布在微博或微信等社交媒体上的文本数据,可通过爬虫不断爬取实时的社交媒体文本数据,输入训练好的片段指针交互模型进行事件检测。预处理操作包括以下至少一种操作:对所述原始的社交媒体文本数据进行去重处理;采用预设的关键字模板对所述原始的社交媒体文本数据进行过滤处理。上述操作的具体内容已在上文详述,此处不赘述。
[0122]
可选地,在片段指针交互模型训练好之后的实际使用过程中,将最新的历史数据输入训练好的片段指针交互模型进行增量训练,以增强模型的性能,其中,最新的历史数据可指前一日或者前几日的历史数据。
[0123]
可选地,所述片段指针交互模型包括基于预训练语言模型的实体感知编码层、指针网络检测层以及区间交互感知层,所述指针网络检测层包括起始位置判定模块和终止位置判定模块。所述将所述灾情监测文本输入至训练好的片段指针交互模型,获得所述片段指针交互模型输出的灾情事件触发词包括以下步骤:
[0124]
将所述灾情监测文本输入所述实体感知编码层,获得所述实体感知编码层输出所述灾情监测文本的语义表征;
[0125]
将所述灾情监测文本的语义表征输入所述起始位置判定模块,获得所述起始位置判定模块预测的所述灾情监测文本中每个字的起始区间表示;
[0126]
将所述起始位置判定模块预测的所述灾情监测文本中每个字的起始区间表示,和所述灾情监测文本的语义表征输入所述终止位置判定模块,获得所述终止位置判定模块预测的所述灾情监测文本中每个字的终止区间表示;
[0127]
将所述起始区间表示和所述终止区间表示输入所述区间交互感知层,由所述区间交互感知层对所述起始区间表示和所述终止区间表示进行特征交互,获得特征交互后的起始类别标签和终止类别标签;
[0128]
基于所述起始类别标签和所述终止类别标签生成对应的起始类别列表和终止类别列表,并基于所述起始类别列表和所述终止类别列表进行解码获得灾情事件触发词。
[0129]
上述步骤的相关解释已在前文中详述,与前文所述的片段指针交互模型构建过程/训练过程不同的是,此处已训练好的片段指针交互模型在实际使用过程中,终止位置判定模块的输入为起始位置判定模块预测的起始区间表示和灾情监测文本的语义表征,而非实际的起始区间表示和灾情监测文本的语义表征。
[0130]
本发明实施例通过将灾情监测文本输入至训练好的片段指针交互模型,获得所述片段指针交互模型输出的灾情事件触发词,而片段指针交互模型通过利用基于指针网络架构的指针网络检测层,通过框定实体区间实现对社交媒体文本数据中事件触发词的检测和识别,因指针网络架构具有较快的预测速度,可实现比传统crf方式更快的事件检测,能够有效提升检测效率,且社交媒体文本数据中无关标签很多,且口语化,传统crf方式对社交媒体文本数据这种标签稀疏的数据的事件触发词抽取效果不佳,采用指针网络架构也可提
升预测精度。此外,采用基于highway network的区间交互感知层提升触发词区间信息的交互能力,将区间终止位置信息与区间起始位置信息充分融合后,用于确定最终的起始类别列表和终止类别列表,进而提高模型的检测精度,实现有效快速的事件检测。
[0131]
本发明一实施例中,基于片段指针交互模型的社会传感灾情监测装置包括存储有计算机程序的计算机可读存储介质和处理器,所述计算机程序被所述处理器读取并运行时,实现如上所述的基于片段指针交互模型的社会传感灾情监测方法。本发明基于片段指针交互模型的社会传感灾情监测装置相对于现有技术所具有的有益效果与上述基于片段指针交互模型的社会传感灾情监测方法一致,此处不赘述。
[0132]
读者应理解,在本说明书的描述中,参考术语“一个实施例”、“一些实施例”、“示例”、“具体示例”或“一些示例”等的描述意指结合该实施例或示例描述的具体特征、结构、材料或者特点包含于本发明的至少一个实施例或示例中。在本说明书中,对上述术语的示意性表述不必针对的是相同的实施例或示例。而且,描述的具体特征、结构、材料或者特点可以在任一个或多个实施例或示例中以合适的方式结合。此外,在不相互矛盾的情况下,本领域的技术人员可以将本说明书中描述的不同实施例或示例以及不同实施例或示例的特征进行结合和组合。
[0133]
尽管上面已经示出和描述了本发明的实施例,可以理解的是,上述实施例是示例性的,不能理解为对本发明的限制,本领域的普通技术人员在本发明的范围内可以对上述实施例进行变化、修改、替换和变型。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1