一种基于多任务学习的中文电子病历命名实体识别方法
1.本发明属于计算机应用技术领域,尤其涉及一种基于多任务学习的中文电子病历命名实体识别的方法。
背景技术:
2.目前,随着现代医学技术的不断提高,基于深度学习的方法被广泛应用在中文医疗领域ner任务,这类方法可以减少特征工程的构建,但模型的训练依赖于大规模的标注数据集。并且现存的中文电子病历标注语料规模比较小,神经网络模型无法充分学习医疗文本的隐藏特征,命名实体识别效果往往较差。因此人工构建大规模的电子病历标注语料需要花费大量的时间和金钱,难度大。现存的标注数据集规模较小,不同数据集的实体类型存在差异,无法直接合并多个数据集,这使得这项工作成为一个不小的挑战。
技术实现要素:
3.本发明目的在于提供一种基于多任务学习的中文电子病历命名实体识别的方法,以解决上述的技术问题。
4.为解决上述技术问题,本发明的一种基于多任务学习的中文电子病历命名实体识别的方法的具体技术方案如下:
5.一种基于多任务学习的中文电子病历命名实体识别的方法,所述方法基于bert-bimcgru-att-crf模型,包括如下步骤:
6.步骤1、获取ccks2017电子病历数据集和自建脑血管疾病数据集;
7.步骤2、利用bert模型将医疗文本中的中文字符转化为向量表示;
8.步骤3、利用双向多单元bimcgru模型提取不同数据集的共享特征;
9.步骤4、引入自注意力机制att消除梯度消失和依赖信息问题;
10.步骤5、使用crf模型解码得到最优标记序列;
11.步骤6、计算模型loss值。
12.进一步的,所述步骤1包括如下具体步骤:
13.ccks2017数据集是中文电子病历的命名实体识别标注数据集,公开的中文电子病历标注数据集包含训练集和测试集,人工标注了五类实体:包括症状和体征、检查和检验、疾病和诊断、治疗、身体部位;
14.利用真实临床电子病历构建脑血管疾病标注语料,通过提取病人现病史、既往史、入院诊断、住院经过等信息,其中80%的语料作为训练集,20%用于测试集,对病历做去隐私脱敏处理。
15.进一步的,所述步骤2包括如下具体步骤:
16.bert将中文字符转化为向量过程,由字向量、句向量和位置向量三者组合成最终的向量表示,bert通过查找字向量表将中文字符转化为向量形式,其中第一个字符为[cls],用于分类任务;句向量表示用于区分不同的句子;位置向量用于区分句子中不同位
置的字的语义信息;通过爬虫技术获得医学领域的语料,并生成txt文件用于预训练bert模型,从现有的bert checkpoint开始对特定领域进行额外的预训练;create_pretraining_data.py将医疗txt文件生成一个.tfrecord文件,并设置模型参数,调用run_pretraining.py进行预训练,完成后得到一个以.ckpt结束tensorflow模型,然后使用huggingface提供的转换脚本将模型转换为以.bin结尾的pytorch模型,记作ftbert。
[0017]
进一步的,所述步骤3包括如下具体步骤:
[0018]
利用一种基于gru模型改进的多单元gru模型,实现基于多任务学习的跨域知识迁移,multi-cell gru由l个实体类型单元et cell和一个组成单元c cell构成,l表示源域和目标域中出现的不重复实体类型个数之和,每个et cell对应一种实体类型,模型使用单独的et cell来改进标准gru的结构,在处理句子时,mcgru可以单独计算当前字向量x
(t)
对应各个实体类型的概率,并为每个实体类型创建不同的特征分布,mcgru中设计了一个组成单元用于计算每个实体类型单元的加权和,并获得最终隐藏状态输出,其中每个实体类型单元的权重对应于其相应实体类型的概率。进一步的,所述实体类型单元计算步骤如下:
[0019]
给定当前字向量x
(t)
前一时刻的隐藏状态输出向量计算第k个(k∈[1,2,
…
l])et cell的更新门和重置门和候选隐藏状态计算公式如下:
[0020][0021]
利用上一时刻的输出和候选隐藏状态通过更新门得到真正隐藏状态计算公式如下:
[0022][0023]
对每个实体类型单元重复上述操作,获得由所有et cell构成的隐藏状态列
[0024]
进一步的,所述组成单元计算步骤如下:
[0025]
给定当前输入x
(t)
及前时刻的输出状态计算更新门重置门和候选隐藏状态
[0026][0027][0028]
进一步的,所述最终隐藏状态计算步骤如下:
[0029]
结合所有et cell和c cell计算mcgru最终隐藏状态,使用加型注意力机制计算c cell的候选隐藏状态与的权重权重反映了c cell的候选隐藏状态与第k个et cell的隐藏状态之间的相似性,其计算公式如下:
[0030][0031]
根据各个et cell的权重,通过加权求和得到c cell的候选隐藏状态计算公式如下:
[0032][0033]
利用上一时刻的输出和候选隐藏状态通过c cell的更新门计算得到真正隐藏状态计算公式如下:
[0034][0035]
进一步的,所述步骤4括如下具体步骤:
[0036]
首先,通过计算查询矩阵q与每个键矩阵k之间的相似度来获得每个单词的权重,然后,使用softmax函数对这些权重进行归一化处理,最后,权重和数值矩阵v使用加权求和得到最后的注意力值;
[0037]
使用缩放点积函数来计算相似性,函数a用于计算注意力值:
[0038][0039]
式(7)中:q、k和v分别表示查询矩阵、键矩阵和数值矩阵,三者是来自同一输入与不同参数计算后得到的,自注意力中设置q=k=v=h,不同参数计算后得到的,自注意力中设置q=k=v=h,即bimcgru模型的输出向量。
[0040]
进一步的,所述步骤5括如下具体步骤:
[0041]
给定一个输入序列x={w1,w2,...wn},假设预测标签序列为y={y1,y2,...yn},函数s用于计算该标签序列的得分:
[0042][0043]
式(8)中:t为crf的转移矩阵,表示yi标签转移到y
i+1
标签的分值,p为
bigru层的输出矩阵,为句子序列中第i+1个字符对应标签y
i+1
的分值;
[0044]
之后使用softmax进行归一化处理,公式如(9)所示:
[0045][0046]
使用对数最大似然估计,用于计算loss函数,如公式(10)所示:
[0047][0048]
crf模型通过使用维特比算法求解出可能性最大的标注序列,公式如(11)所示:
[0049]yresult
=argmax(s
(x,y)
)。
ꢀꢀ
(11)
[0050]
进一步的,所述步骤6括如下具体步骤:
[0051]
引入实体类型预测任务和计算注意力评分任务这2个辅助任务,用于训练实体类型单元和组成单元,给定一个训练集x表示一个训练文本序列[w1,w2,...wn],e表示文本序列对应的实体类型标注[e1,e2,...en],其中的实体类型标签是不带bie分割标记的,如[check,o,disease];
[0052]
实体类型预测任务:
[0053]
给定当前字符x
(t)
的实体类型单元的序列的实体类型单元的序列表示正向和反向实体类型单元的拼接向量,实体类型预测任务用于预测x
(t)
是某个实体类型的概率,通过式(12)计算当前字符的实体类型分布:
[0054][0055]
式中wk、ck表示第k个实体类型单元的可学习参数;
[0056]
使用负对数似然函数计算实体类型预测任务的loss值,计算公式如(13)所示:
[0057][0058]
式中,n表示训练集中一共有n个训练样本(x,e);m表示句子中包含的字符个数;|d
ent
|表示当前训练集中的样本个数;
[0059]
计算注意力评分任务:
[0060]
给定当前字符x
(t)
的et cell和c cell的attention score序列其中,表示正向et cell和c cell、反向et cell和c cell计算得到的注意力值的平均值,使用softmax函数将x
(t)
的注意力分数转换为实体类型分布,计算公式如(14)所示:
[0061][0062]
使用负对数似然函数计算当前任务的loss值,计算公式如(15)所示:
[0063][0064]
ner序列预测任务:
[0065]
我们将自注意力层的输出向量输入到crf模型中,预测当前文本最大可能的序列标注结果,对应一个输入序列x={w1,w2,...wn},crf在预测标签序列为y={y1,y2,...yn}的概率时,计算公式如(16)所示:
[0066][0067]
式中:t为crf的转移矩阵,表示yi标签转移到y
i+1
标签的分值,p为自注意力层的输出矩阵,表示文本中第i+1个字符对应标签y
i+1
的分值;
[0068]
之后使用softmax进行归一化处理,计算公式如(17)所示:
[0069][0070]
式中,y
′
表示所有可能出现的标注序列;
[0071]
使用最大似然估计函数计算ner任务的loss值,计算公式如(18)所示:
[0072][0073]
式中,xn、yn分别表示当前训练集中第n个训练样本和对应的序列预测结果;
[0074]
ner模型的损失值由ner任务和实体类型预测任务、计算注意力评分任务这2个辅助任务的损失值共同计算得到,源领域(s)和目标领域(t)的训练集完成辅助任务后获得损失值和并与ner任务的损失值相加,计算公式(19)所示:
[0075][0076]
式中,λ为l2正则化参数,ι
ent
和ι
atten
分别表示两个辅助任务损失值的权重,λd(d∈{s,t})表示ner任务的权值,表示ner任务的损失值。
[0077]
本发明的一种基于多任务学习的中文电子病历命名实体识别的方法具有以下优
点:本发明充分利用了源领域和目标领域的标记数据进行跨域命名实体识别,解决目标域中ner样本稀缺的问题。通过使用未标记的临床文本预训练bert模型,获得了中文医疗领域特定知识;通过引入共享bimcgru得到包含前向和后向文本的语义特征,实现基于实体类型的跨域知识迁移;通过加入自注意力模型弥补了bimcgru不能获取两个实体之间的长距离依赖关系的缺陷;通过使用crf模型解码得到最优的标记序列。
附图说明
[0078]
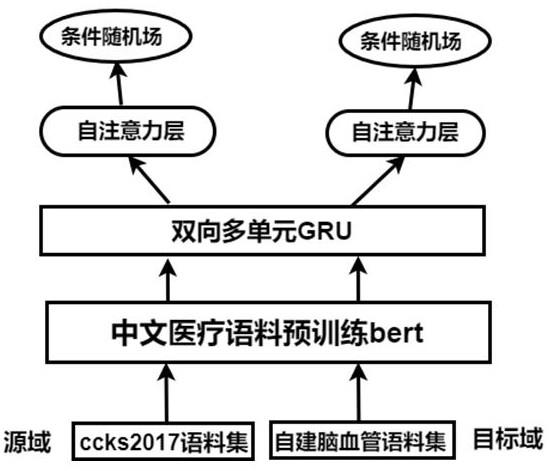
图1为本发明实施例提供的基于bert-bimcgru-att-crf模型的结构图;
[0079]
图2为本发明实施例提供的bert模型结构图;
[0080]
图3为本发明实施例提供的多单元gru(multi-cell gru,mcgru)模型结构图。
具体实施方式
[0081]
为了更好地了解本发明的目的、结构及功能,下面结合附图,对本发明一种基于多任务学习的中文电子病历命名实体识别的方法做进一步详细的描述。
[0082]
如图1-3所示,本发明的一种基于多任务学习的中文电子病历命名实体识别的方法,基于bert-bimcgru-att-crf模型,其流程步骤包括:
[0083]
步骤1、获取ccks2017电子病历数据集和自建脑血管疾病数据集
[0084]
ccks2017数据集是中文电子病历的命名实体识别标注数据集,公开的中文电子病历标注数据集包含训练集和测试集,其中训练集包括300个医疗记录,人工标注了五类实体:包括症状和体征、检查和检验、疾病和诊断、治疗、身体部位。测试集包含100个医疗记录。
[0085]
利用从合作医院获得的真实临床电子病历构建脑血管疾病标注语料,通过提取病人现病史、既往史、入院诊断、住院经过等信息总计获得1062条文本,其中80%的语料作为训练集,20%用于测试集。为保护病人隐私,对病历做去隐私脱敏处理。
[0086]
结合当前需求以及临床医疗文本的特点,本发明定义了四种实体类型,各个实体的定义及示例如下:
[0087]
(1)身体部位:人体器官及身体部位。例如“冠状动脉”、“小脑半球”、“右侧上颌窦”。
[0088]
(2)症状体征:疾病引起的各种不适或异常的表现。例如“意识障碍”、“头晕”、“行走不稳”。
[0089]
(3)疾病诊断:主要对应于疾病名、综合征。例如“高血压”“脑梗死”、“脑血栓”、“颈动脉硬化”。
[0090]
(4)治疗:手术治疗及药物。例如“瓣膜置换术”、“冠脉造影术”、“阿司匹林片”。
[0091]
步骤2、利用bert模型将医疗文本中的中文字符转化为向量表示
[0092]
bert将中文字符转化为向量过程,由字向量、句向量和位置向量三者组合成最终的向量表示。bert通过查找字向量表将中文字符转化为向量形式,其中第一个字符为[cls],用于分类任务;句向量表示用于区分不同的句子;位置向量用于区分句子中不同位置的字的语义信息。本发明通过爬虫技术获得医学领域的语料,并生成txt文件用于预训练bert模型,从现有的bert checkpoint开始对特定领域进行额外的预训练。create_
pretraining_data.py将医疗txt文件生成一个.tfrecord文件。并设置模型参数,调用run_pretraining.py进行预训练,完成后得到一个以.ckpt结束tensorflow模型。然后使用huggingface提供的转换脚本将模型转换为以.bin结尾的pytorch模型,记作ftbert。
[0093]
步骤3、利用双向多单元bimcgru模型提取不同数据集的共享特征
[0094]
利用一种基于gru模型改进的多单元gru(multi-cell gru,mcgru)模型,实现基于多任务学习的跨域知识迁移。multi-cell gru由l个实体类型单元(entity typed cell,et cell)和一个组成单元(compositional cell,c cell)构成。l表示源域和目标域中出现的不重复实体类型个数之和,每个et cell对应一种实体类型。模型使用单独的et cell来改进标准gru的结构,在处理句子时,mcgru可以单独计算当前字向量x(t)对应各个实体类型的概率,并为每个实体类型创建不同的特征分布。mcgru中设计了一个组成单元用于计算每个实体类型单元的加权和,并获得最终隐藏状态输出,其中每个实体类型单元的权重对应于其相应实体类型的概率。
[0095]
实体类型单元:
[0096]
给定当前字向量x
(t)
前一时刻的隐藏状态输出向量计算第k个(k∈[1,2,
…
l])et cell的更新门和重置门和候选隐藏状态计算公式如下:
[0097][0098]
利用上一时刻的输出和候选隐藏状态通过更新门得到真正隐藏状态计算公式如下:
[0099][0100]
对每个实体类型单元重复上述操作,获得由所有et cell构成的隐藏状态列
[0101]
组成单元:
[0102]
给定当前输入x
(t)
及前时刻的输出状态计算更新门重置门和候选隐藏状态
[0103]
[0104]
计算mcgru最终隐藏状态:
[0105]
结合所有et cell和c cell计算mcgru最终隐藏状态。使用加型注意力机制(additive attention)计算c cell的候选隐藏状态与的权重权重反映了c cell的候选隐藏状态与第k个et cell的隐藏状态之间的相似性,其计算公式如下:
[0106][0107]
根据各个et cell的权重,通过加权求和得到c cell的候选隐藏状态计算公式如下:
[0108][0109]
利用上一时刻的输出和候选隐藏状态通过c cell的更新门计算得到真正隐藏状态计算公式如下:
[0110][0111]
步骤4、引入自注意力机制(self-attention,att)消除梯度消失和依赖信息问题
[0112]
引入自注意力机制可以根据字符的重要性赋予不同的权值,关注对模型训练有效的关键信息并忽略非重要信息。进而有效地捕捉句子内部结构信息,提升医疗命名实体识别的准确率。其计算过程可总结如下:
[0113]
首先,通过计算查询矩阵q与每个键矩阵k之间的相似度来获得每个单词的权重,常用的相似度函数有点积,拼接,感知机等。然后,使用softmax函数对这些权重进行归一化处理。最后,权重和数值矩阵v使用加权求和得到最后的注意力值。
[0114]
本发明使用缩放点积函数来计算相似性,函数a用于计算注意力值:
[0115][0116]
式(7)中:q、k和v分别表示查询矩阵、键矩阵和数值矩阵,三者是来自同一输入与不同参数计算后得到的。自注意力中设置q=k=v=h,不同参数计算后得到的。自注意力中设置q=k=v=h,即bimcgru模型的输出向量。
[0117]
步骤5、使用crf模型解码得到最优标记序列
[0118]
crf能够通过考虑标签之间的依赖关系获得全局最优的标记序列。给定一个输入序列x={w1,w2,...wn},假设预测标签序列为y={y1,y2,...yn},函数s用于计算该标签序列
的得分:
[0119][0120]
式(8)中:t为crf的转移矩阵,表示yi标签转移到y
i+1
标签的分值。p为bigru层的输出矩阵,为句子序列中第i+1个字符对应标签y
i+1
的分值。
[0121]
之后使用softmax进行归一化处理,公式如(9)所示。
[0122][0123]
使用对数最大似然估计,用于计算loss函数,如公式(10)所示。
[0124][0125]
crf模型通过使用维特比算法求解出可能性最大的标注序列,公式如(11)所示。
[0126]yresult
=argmax(s
(x,y)
)
ꢀꢀ
(11)
[0127]
步骤6、计算模型loss值
[0128]
引入实体类型预测任务和计算注意力评分任务这2个辅助任务,用于训练实体类型单元和组成单元,从而辅助ner任务能正确识别出文本中的实体类型。给定一个训练集x表示一个训练文本序列[w1,w2,...wn],e表示文本序列对应的实体类型标注[e1,e2,...en],其中的实体类型标签是不带bie分割标记的,如[check,o,disease]。
[0129]
实体类型预测任务:
[0130]
给定当前字符x
(t)
的实体类型单元的序列的实体类型单元的序列表示正向和反向实体类型单元的拼接向量,实体类型预测任务用于预测x
(t)
是某个实体类型的概率。我们通过式(12)计算当前字符的实体类型分布:
[0131][0132]
式中wk、ck表示第k个实体类型单元的可学习参数。
[0133]
使用负对数似然函数计算实体类型预测任务的loss值,计算公式如(13)所示:
[0134][0135]
式中,n表示训练集中一共有n个训练样本(x,e);m表示句子中包含的字符个数;|d
ent
|表示当前训练集中的样本个数。
[0136]
计算注意力评分任务:
[0137]
给定当前字符x
(t)
的et cell和c cell的attention score序列其中,表示正向et cell和c cell、反向et cell和c cell计算得到的注意力值的平均值。我们使用softmax函数将x
(t)
的注意力分数转换为实体类型分布,计算公式如(14)所示:
[0138][0139]
使用负对数似然函数计算当前任务的loss值,计算公式如(15)所示:
[0140][0141]
ner序列预测任务:
[0142]
我们将自注意力层的输出向量输入到crf模型中,预测当前文本最大可能的序列标注结果。对应一个输入序列x={w1,w2,...wn},crf在预测标签序列为y={y1,y2,...yn}的概率时,计算公式如(16)所示:
[0143][0144]
式中:t为crf的转移矩阵,表示yi标签转移到y
i+1
标签的分值。p为自注意力层的输出矩阵,表示文本中第i+1个字符对应标签y
i+1
的分值。
[0145]
之后使用softmax进行归一化处理,计算公式如(17)所示。
[0146][0147]
式中,y
′
表示所有可能出现的标注序列。
[0148]
使用最大似然估计函数计算ner任务的loss值,计算公式如(18)所示。
[0149][0150]
式中,xn、yn分别表示当前训练集中第n个训练样本和对应的序列预测结果。
[0151]
ner模型的损失值由ner任务和实体类型预测任务、计算注意力评分任务这2个辅助任务的损失值共同计算得到。源领域(s)和目标领域(t)的训练集完成辅助任务后获得损失值和并与ner任务的损失值相加,计算公式(19)所示。
[0152][0153]
式中,λ为l2正则化参数,通过正则化方法可以防止过拟合,提高泛化能力。ι
ent
和ι
atten
分别表示两个辅助任务损失值的权重,λd(d∈{s,t})表示ner任务的权值,表示ner任务的损失值。
[0154]
实验过程:
[0155]
在本实验中,我们使用了ccks2017电子病历数据集和自建脑血管疾病数据集,并且使bimcgru-att-crf的参数设置如下,bimcgru设置最大训练次数为100;批处理大小为32;学习率0.01;使用adam优化算法进行模型的优化;使用dropout方法来解决模型训练中出现过拟合问题。ccks2017电子病历数据集包含5个实体类型,自建脑血管疾病数据集包含4个与ccks2017电子病历数据集中相同的实体类型,所有mcgru的实体类型单元数量设置为5。
[0156]
为了衡量实验结果的准确性,同时考虑到ner任务需同步确定实体边界及实体类别。在精确匹配评估中,只有当实体边界以及实体类别同时被精确标出时,实体识别任务才能被认定为成功。所以采用精确率(precision,p)、召回率(recall,r)和f1值作为评价指标。
[0157]
与当前较有效的方法进行了对比实验,参考jia等人将bilstm模型改进为双向多单元lstm(bi-directional multi-cell lstm,bimclstm)的做法,通过对标准bigru进行改进,提出bimcgru模型。数据集采用的是ccks2017和自建脑血管疾病数据集,并与yang等人,jia等人提出的多任务ner模型比较性能。试验设置4个只包含目标域数据的单任务模型word2vec-bilstm-crf,word2vec-bigru-crf,ftbert-bilstm-att-crf,ftbert-bigru-att-crf和6个包含源域和目标域数据集的多任务模型word2vec-bilstm-crf,word2vec-bigru-crf,word2vec-bimclstm-crf,word2vec-bimcgru-crf,ftbert-bimclstm-att-crf以及ftbert-bimcgru-att-crf(ours)。试验结果如表1所示,本发明所提ftbert-bimcgru-att-crf模型相对于其他ner模型提升了识别精度,在自建脑血管疾病数据集上本发明模型的f1值达到89.34,在ccks2017数据集上f1值达到91.53。
[0158]
表1不同命名实体识别模型结果:
[0159][0160]
分析6个多任务学习模型的试验效果,对于word2vec-bilstm-crf和word2vec-bigru-crf模型,由bimclstm替换bilstm,bimcgru替换bigru后f1值均有所提升,因为bimclstm和bimcgru为跨域的每个实体类型创建不同的特征分布,可以在实体类型级别进行跨域知识转移,有效提升命名实体识别效果。在相同参数设置下,本发明提出mcgru效果比mclstm更好,主要原因在于gru不仅具有lstm的优势,而且减少参数,简化其网络结构,提升计算速度。
[0161]
在word2vec-bilstm-crf,word2vec-bigru-crf,基于多任务学习的word2vec-bimclstm-crf,word2vec-bimcgru-crf这4个模型中添加bert和self-attention模块后,试验结果中的f1值均有所提升,证明引入bert和self-attention模块可以有效提升命名实体识别效果。原因是使用word2vec处理字符向量存在一词多义问题,无法充分考虑上下文关系特征,引入bert预训练模型可以充分考虑上下文关系特征并解决一词多义问题。bilstm,bigru及其改进模型由于梯度消失问题,其获取长距离依赖的能力会随着本发明序列的增加而降低,引入self-attention可获得长序列间任意字符的依赖关系。
[0162]
因此可以得出,本发明具有以下优势:充分利用源领域和目标领域的标记数据进行跨域命名实体识别,解决目标域中ner样本稀缺的问题。通过使用未标记的临床文本预训练bert模型,获得了中文医疗领域特定知识;通过引入共享bimcgru得到包含前向和后向文本的语义特征,实现基于实体类型的跨域知识迁移;通过加入自注意力模型弥补了bimcgru不能获取两个实体之间的长距离依赖关系的缺陷;通过使用crf模型解码得到最优的标记序列。本发明在ccks2017医疗数据集和自建脑血管疾病数据集上进行试验,试验结果证明本发明提出的模型在各类指标上优于传统多任务ner模型,证明该模型在中文医疗命名实体识别任务上的有效性。
[0163]
可以理解,本发明是通过一些实施例进行描述的,本领域技术人员知悉的,在不脱离本发明的精神和范围的情况下,可以对这些特征和实施例进行各种改变或等效替换。另外,在本发明的教导下,可以对这些特征和实施例进行修改以适应具体的情况及材料而不会脱离本发明的精神和范围。因此,本发明不受此处所公开的具体实施例的限制,所有落入
本技术的权利要求范围内的实施例都属于本发明所保护的范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1