一种试题难度预测模型的实现装置及方法与流程
1.本发明涉及自然语言处理技术领域,特别是涉及一种试题难度预测模型的实现装置及方法。
背景技术:
2.在人才测评行业中存在一种普遍的现象,即存在大量的试题定制的需求。试题定制意味着题目正处于初生阶段,尚未用于实践过程中,因而未能留下答题记录,这就导致对试题参数的估计存在较大的困难,从而对测量精度产生了极大的影响。
技术实现要素:
3.为克服上述现有技术存在的不足,本发明之目的在于提供一种试题难度预测模型的实现装置及方法,以通过利用nlp(natural language processing,自然语言处理)技术构建历史试题文本与历史答题记录之间的函数关系,从而实现对定制试题的难度预测,以解决“物品冷启动”阶段的问题。
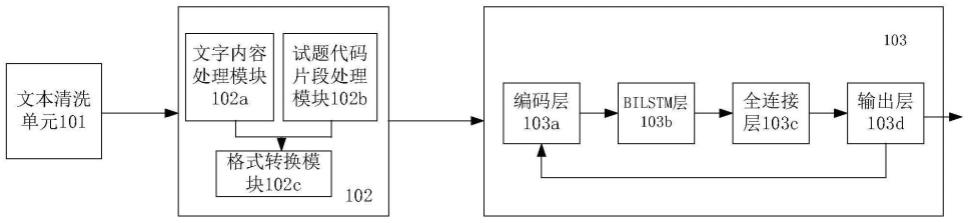
4.为达上述目的,本发明提供一种试题难度预测模型的实现装置,包括:
5.文本清洗单元,用于对试题库中已存在的试题进行文本清洗;
6.语料库构建单元,用于构建语料库,并将清洗后的试题文本转换为计算机可以处理的编码;
7.模型构建训练单元,用于将编码后的试题参数代入bilstm函数进行运算,并对其结果进行max处理,将经bilstm函数处理后的题干信息、选项信息、解析信息和知识点信息进行拼接,通过全连接层和输出层的运算,并对输出层的结果构建交叉熵损失函数进行训练。
8.优选地,所述文本清洗单元依次对试题库中每道试题进行文本清洗,包括:
9.删除含有“《img.*?》”字样的数据;
10.将html格式转成utf-8格式;
11.删除html的标签符号;
12.删除特殊字符;
13.删除标点符号;以及
14.合并文本片段。
15.优选地,所述语料库构建单元进一步包括:
16.文字内容处理模块,用于通过对技术社区内容进行新词挖掘,将挖掘结果与一般词库合并为一个大的词库,作为jieba词库的参考标准,使用jieba分词对所述试题文本的文字内容进行分词及编码;
17.试题代码片段处理模块,用于对所述试题文本中的试题代码片段进行ast解析、编码;
18.格式转换模块,用于将编码后的试题参数转换成模型所需要的格式。
19.优选地,所述模型构建单元进一步包括:
20.编码层,用于将编码后的试题参数并将其转换为模型所能处理的数字;
21.bilstm函数处理模块,用于将编码层处理后的试题参数代入bilstm函数进行运算,并对其结果进行最大值化处理;
22.全连接层,用于将bilstm函数处理模块输出的试题参数进行拼接,再执行全连接层的运算;
23.输出层,用于参照全联接层的操作方式,将全连接层的结果转变为一维的logit值,经过sigmoid转换之后代入交叉熵损失函数进行训练。
24.优选地,所述试题参数包括试题题干信息、试题选项信息、试题解析信息、试题标注知识点以及试题标签。
25.为达到上述目的,本发明还提供一种试题难度预测模型的实现装置,包括:
26.文本清洗单元,用于对试题库中已存在的试题进行文本清洗;
27.语料库构建单元,用于构建语料库,给试题文本中的每一个文本单元进行标定,并将标定后的试题参数转换成符合idpm算法所需要的编码规范;
28.模型构建训练单元,用于将编码后的试题参数进行embedding_lookup的转换,转换为idpm模型所能处理的数学向量代入bilstm函数进行运算,并对其结果进行max处理,将经bilstm函数处理后的试题题干信息、试题选项信息、试题解析信息和试题标注知识点信息进行拼接,通过全连接层和输出层的运算,并对输出层的结果构建交叉熵损失函数进行训练。
29.优选地,所述文本清洗单元依次对试题库中每道试题进行文本清洗,包括:
30.删除含有“《img.*?》”字样的数据;
31.将html格式转成utf-8格式;
32.删除html的标签符号;
33.删除特殊字符;
34.删除标点符号;以及
35.合并文本片段。
36.优选地,所述语料库构建单元进一步包括:
37.文字内容处理模块,用于通过对技术社区内容进行新词挖掘,将挖掘结果与一般词库合并为一个大的词库,作为jieba词库的参考标准,使用jieba分词对所述试题文本的文字内容进行分词及编码;
38.试题代码片段处理模块,用于对所述试题文本中的试题代码片段进行ast解析及编码;
39.格式转换模块,用于将编码后的试题参数转换成idpm模型所需要的格式。
40.优选地,所述模型构建单元进一步包括:
41.编码层,用于将编码后的试题参数进行embedding_lookup的转换,使其转换成idpm模型所能处理的数学向量;
42.bilstm函数处理模块,用于将编码层处理后的试题参数代入bilstm函数进行运算,并对其结果进行最大值化处理;
43.全连接层,用于将bilstm函数处理模块输出的试题参数进行拼接,再执行全连接
层的运算;
44.输出层,用于参照全联接层的操作方式,将全连接层的结果转变为一维的logit值,经过sigmoid转换之后代入交叉熵损失函数进行训练。
45.优选地,所述试题参数包括试题题干信息、试题选项信息、试题解析信息、试题标注知识点以及试题标签。
46.优选地,所述格式转换模块将编码后的试题参数转换成idpm模型所需要的格式包括:试题题干信息,尺寸为[n_item,n_length];试题选项信息,尺寸为[n_item,n_length];试题解析信息,尺寸为[n_item,n_length];试题标注知识点,尺寸为[n_item,1];试题标签,尺寸为[n_item],其中,n_item表示试题数量,n_length表示每道试题包含的单词数量。
[0047]
优选地,试题参数经所述embedding_lookup的转换为idpm模型所能处理的数学向量为:试题题干信息转换为[n_item,n_length,embed_size];试题选项信息转换为[n_item,n_length,embed_size];试题解析信息转换为[n_item,n_length,embed_size];试题标注知识点转换为[n_item,1,embed_size]。
[0048]
优选地,对于试题代码片段,所述试题代码片段处理模块首先利用第三方库将试题代码片段处理成树状结构;其次对每个节点进行编码,包括利用语料库对每个节点的文本进行编码、对节点的特殊字义或类型进行编码,文本编码和类型编码的格式均为[n_item,n_length’],n_length’表示代码片段的单词数量;然后提取每一个节点的父节点经上述处理;提取每一个节点的子节点的集合,经上述处理,子节点集合的格式为[n_item,n_length’,n_child],n_child表示子节点的数量;最终将父节点、当前节点和子节点一并作为当前节点的输入项。
[0049]
优选地,对于试题文本中的代码片段,在将当前节点的文本编码和类型编码转换为[n_item,n_length’,embed_size]后,进行拼接,拼接之后的格式为[n_item,n_length’,2*embed_size];然后对父节点和子节点集合进行编码,并对编码后的子节点集合进行max处理,两者的格式均为[n_item,n_length’,2*embed_size];再后,将父节点、当前节点和子节点进行拼接,格式转变为[n_item,n_length’,6*embed_size];最后对其执行降维操作,与文本部分一并代入到后续的运算过程中。
[0050]
为达到上述目的,本发明还提供一种试题难度预测模型的实现方法,包括如下步骤:
[0051]
步骤s1,对试题库中已存在的试题进行文本清洗;
[0052]
步骤s2,构建语料库,给试题文本中的每一个文本单元进行标定,并将标定后的试题参数转换成符合idpm算法所需要的编码规范;
[0053]
步骤s3,将编码后的试题参数进行embedding_lookup的转换,转换为idpm模型所能处理的数学向量代入bilstm函数进行运算,并对其结果进行max处理,将经bilstm函数处理后的试题题干信息、试题选项信息、试题解析信息和试题标注知识点信息进行拼接,通过全连接层和输出层的运算,并对输出层的结果构建交叉熵损失函数进行训练。
[0054]
与现有技术相比,本发明一种试题难度预测模型的实现装置及方法通过利用nlp技术构建历史试题文本与历史答题记录之间的函数关系,从而实现对定制试题的难度预测,以解决“物品冷启动”阶段的问题。
附图说明
[0055]
图1为本发明一种试题难度预测模型的实现装置的系统结构图;
[0056]
图2为本发明一种试题难度预测模型的实现方法的步骤流程图。
具体实施方式
[0057]
以下通过特定的具体实例并结合附图说明本发明的实施方式,本领域技术人员可由本说明书所揭示的内容轻易地了解本发明的其它优点与功效。本发明亦可通过其它不同的具体实例加以施行或应用,本说明书中的各项细节亦可基于不同观点与应用,在不背离本发明的精神下进行各种修饰与变更。
[0058]
图1为本发明一种试题难度预测模型的实现装置的系统结构图。如图1所示,本发明一种试题难度预测模型的实现装置,包括:
[0059]
文本清洗单元101,用于对试题库中已存在的试题进行文本清洗。
[0060]
在本发明中,所述文本清洗是指对题库中已存在的试题进行必要的转义、合并或剔除等相关操作。一般来说,数据库在存储试题的过程中,往往会根据产品需求而对文本进行一些变换,例如:绝大部分试题会变换成html格式,以方便前端渲染的工作;部分试题涉及到图片、音频、视频等多媒体文件的存储或调取,会增加必要的“占位符”来予以表示;而有的试题,如填空题,考虑到数据治理方面的要求,会将题干文本与“___”进行分开处理,因此试题的最终展现形式是一个列表,而非文本,经过计算机处理之后的文本,会增加许多“无意义”的、或者说是没有数据价值的信息,这会干扰到模型的预测效果,因此需要通过文本清洗单元101对这些试题进行文本清洗,将它们予以修正。
[0061]
具体地,文本清洗单元101依次对试题库中每道试题进行文本清洗,具体如下:
[0062]
删除含有“《img.*?》”字样的数据,若当前试题中含有“《img.*?》”,则删除含有“《img.*?》”字样的数据;
[0063]
将html格式转成utf-8格式,将html格式的试题转换成utf-8格式;
[0064]
删除html的标签符号,如《div》,将试题的html格式的标签符号删除;
[0065]
删除特殊字符,如\xa0,若当前试题中存在特殊字符,如\xa0,则删除该特殊字符;
[0066]
删除标点符号,即删除当前试题中的标点符号;
[0067]
合并文本片段,若部分试题(如填空题)因为存储需要存成了若干文本片段,则在各文本片段进行文本清洗后需合并文本片段,例如若当前试题将原本的文本“我是一个___的人”,变成[
‘
我是一个’,
‘
___’,
‘
的人’],并用html格式进行标识,以方便前后端的操作,则需要在各文本片段清洗后进行合并。
[0068]
语料库构建单元102,用于构建语料库,给试题文本中的每一个文本单元进行标定,并将标定后的试题参数转换成符合idpm算法所需要的编码规范。
[0069]
语料库构建的目的是为了试题文本转换成计算机可以处理的编码。在本发明具体实施例中,语料库是指与it技术相关的专业名词的集合,类似于《新华字典》,其构建的目的是为了将文本片段拆解为单词,语料库中的每一个单词都有对应的编码,可以将被分割后的单词进行编码。
[0070]
具体地,语料库构建单元102进一步包括:
[0071]
文字内容处理模块102a,用于通过对技术社区内容进行新词挖掘,将挖掘结果与
一般词库合并为一个大的词库,作为jieba词库的参考标准,使用jieba分词对所述试题文本的文字内容进行分词及编码。
[0072]
在本发明中,构建语料库的过程包含两个部分,一是对文字内容的处理,另一个则是对代码片段的处理,具体地,首先用正则表达式提取出试题文本中的代码片段,其剩余的部分则为文字内容。对文字内容的处理是比较容易的,由于经过清洗之后的文本是比较干净的,只需要使用jieba分词的第三方库对其进行分词即可。但需要注意的是,面向it技术领域的人才测评中,通常包含大量的领域知识,也即专业词汇,使用一般性质的词库是不尽如人意的。对此,本发明利用it技术社区中的帖子内容,使用新词挖掘的技术来构建新词词库,并与一般词库合并为一个大的词库,作为jieba词库的参考标准,同时,为了避免少数罕见的单词对预测效果的影响,本发明将单词的入选新词词库的标准定位在题库中出现10次以上,以减少异常值的出现。
[0073]
试题代码片段处理模块102b,用于对所述试题文本中的试题代码片段进行ast解析及编码。
[0074]
对代码片段的处理也是至关重要的,既然试题考察的是it技术知识,就必然离不开代码片段。而编程代码并不属于自然语言,它是人工语言的一种,具体表现在每一个字符后都有严格的、可用于解析的语法规则,同时,代码片段中的词汇(除了特殊字符以外)也不具有参考价值,因为它们都是主观命名的,自成一套体系。对此,本发明采取的办法是使用ast(抽象技能树)来进行解析,将代码片段处理成树型结构,再对树型结构中父节点与子节点的属性、类别进行提取、编码,其余操作与上述文字内容的处理过程一致。
[0075]
具体过程如下:首先利用现有的javalang、ast等第三方库将编程语言(即试题文本中的试题代码片段)处理成树状结构,具体地说,由于编程语言是结构性语言,可以按照逻辑将它拆解为树状结构,例如:python中的def(x,y):return y-x,def为一个节点,x,y是它的子节点,return也是其子节点,与x,y平级,y-x为return的子节点,即def的子孙节点,此处的节点是对def,x,y等的代称,通常会具有一个特定的属性,如x,y是变量,def是函数符号等;其次是对每个节点进行编码,编码工作包括了利用语料库对每个节点的文本进行编码、对节点的特殊字义或类型进行编码(例如:while、for属于循环语句,public和def属于函数,以及ast自带的节点类型),文本编码和类型编码的格式均为[n_item,n_length’],n_length’表示代码片段的单词数量;然后是提取每一个节点的父节点,父节点亦经过上述处理;接下来是提取每一个节点的子节点的集合,子节点亦经过上述处理,子节点集合的格式为[n_item,n_length’,n_child],n_child表示子节点的数量,最后将父节点、当前节点和子节点一并作为当前节点的输入项。
[0076]
格式转换模块102c,用于将编码后的试题参数转换成idpm模型所需要的格式。
[0077]
idpm,全称为item difficulty predict model(试题难度预测模型),是利用自然语言处理技术,通过解析试题文本信息而对其难度进行预测的一种方法,目的是为了解决试题在初生阶段(即“物品冷启动”阶段)的参数标定的难题。
[0078]
在本发明具体实施例中,经过上述编码,试题文本中的每一个文本单元,如单词等,都已标定一个id,则还需将其将其转换为符合idpm算法所需要的编码规范,具体地,获取试题题干信息,尺寸为[n_item,n_length];试题选项信息,尺寸为[n_item,n_length];试题解析信息,尺寸为[n_item,n_length];试题标注知识点,尺寸为[n_item,1];试题标
签,尺寸为[n_item],其中,n_item表示试题数量,即共有n_item道试题,n_length表示每道试题包含的单词数量,即每道试题包含n_length个单词;
[0079]
模型构建训练单元103,用于将编码后的试题参数进行embedding_lookup转换为idpm模型所能处理的数学向量后,代入bilstm函数进行运算,并对其结果进行max处理,将经bilstm函数处理后的试题题干信息、试题选项信息、试题解析信息和试题标注知识点信息进行拼接,通过全连接层和输出层的运算,并对输出层的结果构建交叉熵损失函数进行训练。
[0080]
具体地,模型构建训练单元103进一步包括
[0081]
编码层103a,用于将编码后的试题参数进行embedding_lookup的转换,使其转换成idpm模型所能处理的数学向量。
[0082]
需说明的是,在格式转换模块102c中虽然对试题参数进行了格式转换,但是只是完成了格式整理,参数本身不具备数学含义,例如可以是1、2、3,也可以是a、b、c,只是标识而已,编码层103a则要将编码后的试题参数赋予一个数学向量。具体地,将编码之后的试题参数,将编码后的试题参数进行embedding_lookup的转换,使其转换成模型所能处理的数学向量,例如,获取试题题干信息,尺寸为[n_item,n_length],试题选项信息,尺寸为[n_item,n_length],试题解析信息,尺寸为[n_item,n_length],试题标注知识点,尺寸为[n_item,1],试题标签,尺寸为[n_item,],其中,n_item表示试题数量,n_length表示单词数量,表示这一个文本片段包含了多少个单词,通过embedding_lookup转换后变为:试题题干信息转换为[n_item,n_length,embed_size];试题选项信息转换为[n_item,n_length,embed_size];试题解析信息转换为[n_item,n_length,embed_size];试题标注知识点转换为[n_item,1,embed_size],其中,embed_size表示向量长度。具体如下:
[0083]
embed=embedding_lookup(embedding_matrix,input)
[0084]
其中,embedding_matrix为生成全部单词或节点的矩阵,每个单词对应有序号,input为单词编码之后的序号,从embedding_matrix中取出对应的向量。由于embedding_lookup的具体过程为现有技术,在此不予赘述。
[0085]
在本发明具体实施例中,在对代码片段的处理中需要增加如下环节:
[0086]
将当前节点的文本编码和类型编码转换为[n_item,n_length’,embed_size]后,进行拼接,拼接之后的格式为[n_item,n_length’,2*embed_size];具体如下:
[0087][0088]
然后对父节点和子节点集合进行编码,并对编码后的子节点集合进行max处理,两者的格式均为[n_item,n_length’,2*embed_size],具体如下:
[0089]
child(n_item,n_length
′
,2*embed_size)=max(children(n_item,n_length
′
,n_child,2*embed_size),axis=2)
[0090][0091]
再后,将父节点、当前节点和子节点进行拼接,格式转变为[n_item,n_length’,6*embed_size],具体拼接如下:
[0092][0093]
最后对其执行降维操作,与文本部分一并代入到之后的运算过程中。
[0094]
node(n_item,n_length
′
,embed_size)=weight*node+bias
[0095]
其中,weight、bias为线性函数的权重和偏置项,如y=wx+b,本发明中为矩阵形式,前一个node对应线性函数中的y,后一个node对应x。
[0096]
bilstm层103b,用于将编码层103a处理后的试题参数代入bilstm函数进行运算,并对其结果进行最大值化(max)处理。
[0097]
在本发明中,将编码层103a处理后的试题题干信息、选项信息、解析信息代入bilstm函数进行运算,并对其结果进行最大值化(max)处理,处理之后的参数尺寸均为[n_item,1,2*hidden_size],具体过程如下公式所示:
[0098]
hidden
(n_item,n_length,2*hidden_size)
=bilstm(embed)
[0099]
hidden
(n_item,1,2*hidden_size)
=max(hidden,axis=1)
[0100]
其中,bilstm是双向长短时记忆机制,分别从序列数据(即试题题干信息、选项信息、解析信息)前向和后向进行扫描处理。
[0101]
全连接层103c,用于将bilstm层103b输出的题干信息、选项信息、解析信息和知识点信息进行拼接,再执行全连接层的运算。
[0102]
在本发明中,将题干信息、选项信息、解析信息和知识点信息进行拼接,并执行全连接层的操作,输出结果的尺寸为[n_item,1,hidden_size],具体如下:
[0103]
hidden
(n_item
,
1,hidden_size)
=concat([hidden
context
,hidden
option
,hidden
anaiyze
,knowledge],axis=-1)
[0104]
hidden
(n_item,1,hidden_size)
=weight*hidden+bias
[0105]
hidden
(n_item,1,hidden_size)
=p*tanh(hidden)+(1-p)*hidden
[0106]
其中,tanh是激活函数,p是调节参数,是为了一方面是为了避免层数过多而造成的梯度消散情况,另一方面则是避免resnet设计所造成的梯度爆炸情况,通过上述处理可使输出结果处于一个稳定的范围之内。
[0107]
输出层103d,用于参照全联接层的操作方式,将全连接层的结果转变为一维的logit值,经过sigmoid转换之后代入交叉熵损失函数进行训练。
[0108]
输出层103d的具体过程可如下式所示:
[0109]
logit
(n_item,1,1)
=weight*hidden+bias
[0110]
prob=sigmoid(logit)
[0111]
loss=-[y*log(p)+(1-y)*log(1-p)]
[0112]
图2为本发明一种试题难度预测模型的实现方法的步骤流程图。如图2所示,本发明一种试题难度预测模型的实现方法,包括如下步骤:
[0113]
步骤s1,对试题库中已存在的试题进行文本清洗。
[0114]
在本发明中,所述文本清洗是指对题库中已存在的试题进行必要的转义、合并或剔除等相关操作。一般来说,数据库在存储试题的过程中,往往会根据产品需求而对文本进行一些变换,例如:绝大部分试题会变换成html格式,以方便前端渲染的工作;部分试题涉及到图片、音频、视频等多媒体文件的存储或调取,会增加必要的“占位符”来予以表示;而
有的试题,如填空题,考虑到数据治理方面的要求,会将题干文本与“___”进行分开处理,因此试题的最终展现形式是一个列表,而非文本,经过计算机处理之后的文本,会增加许多“无意义”的、或者说是没有数据价值的信息,这会干扰到模型的预测效果,因此需要通过文本清洗单元101对这些试题进行文本清洗,将它们予以修正。
[0115]
具体地,于步骤s1中,依次对试题库中每道试题进行如下文本清洗操作:
[0116]
删除含有“《img.*?》”字样的数据,若当前试题中含有“《img.*?》”,则删除含有“《img.*?》”字样的数据;
[0117]
将html格式转成utf-8格式,将html格式的试题转换成utf-8格式;
[0118]
删除html的标签符号,如《div》,将试题的html格式的标签符号删除;
[0119]
删除特殊字符,若当前试题中存在特殊字符,如\xa0,则删除该特殊字符;
[0120]
删除标点符号,即删除当前试题中的标点符号;
[0121]
合并文本片段,若部分试题(如填空题)因为存储需要存成了若干文本片段,则在各文本片段进行文本清洗后需合并文本片段,例如若当前试题将原本的文本“我是一个___的人”,变成[
‘
我是一个’,
‘
___’,
‘
的人’],并用html格式进行标识,以方便前后端的操作,则需要在各文本片段清洗后进行合并。。
[0122]
步骤s2,构建语料库,给试题文本中的每一个文本单元进行标定,将标定后的试题参数转换成符合idpm算法所需要的编码规范。
[0123]
在本发明中,语料库构建的目的是为了试题文本转换成计算机可以处理的编码。在本发明具体实施例中,语料库是指与it技术相关的专业名词的集合,类似于《新华字典》,其构建的目的是为了将文本片段拆解为单词,语料库中的每一个单词都有对应的编码,可以将被分割后的单词进行编码。
[0124]
具体地,步骤s2进一步包括:
[0125]
步骤s200,通过对技术社区内容进行新词挖掘,将挖掘结果与一般词库合并为一个大的词库,作为jieba词库的参考标准,使用jieba分词对所述试题文本的文字内容进行分词、编码。
[0126]
在本发明中,构建语料库的过程包含两个部分,一是对文字内容的处理,另一个则是对代码片段的处理,具体地,首先用正则表达式提取出试题文本中的代码片段,其剩余的部分则为文字内容。对文字内容的处理是比较容易的,由于经过清洗之后的文本是比较干净的,只需要使用jieba分词的第三方库对其进行分词即可。但需要注意的是,面向it技术领域的人才测评中,通常包含大量的领域知识,也即专业词汇,使用一般性质的词库是不尽如人意的。对此,本发明利用it技术社区中的帖子内容,使用新词挖掘的技术来构建新词词库,并与一般词库合并为一个大的词库,作为jieba词库的参考标准,同时,为了避免少数罕见的单词对预测效果的影响,本发明将单词的入选新词词库的标准定位在题库中出现10次以上,以减少异常值的出现。
[0127]
步骤s201,对所述试题文本中的试题代码片段进行ast解析、编码。
[0128]
对代码片段的处理也是至关重要的,既然试题考察的是it技术知识,就必然离不开代码片段。而编程代码并不属于自然语言,它是人工语言的一种,具体表现在每一个字符后都有严格的、可用于解析的语法规则,同时,代码片段中的词汇(除了特殊字符以外)也不具有参考价值,因为它们都是主观命名的,自成一套体系。对此,本发明采取的办法是使用
ast(抽象技能树)来进行解析,将代码片段处理成树型结构,再对树型结构中父节点与子节点的属性、类别进行提取、编码,其余操作与文字内容的处理上述过程一致。
[0129]
具体过程如下:首先利用现有的javalang、ast等第三方库将编程语言(即试题文本中的试题代码片段)处理成树状结构,具体地说,由于编程语言是结构性语言,可以按照逻辑将它拆解为树状结构,例如:python中的def(x,y):return y-x,def为一个节点,x,y是它的子节点,return也是其子节点,与x,y平级,y-x为return的子节点,即def的子孙节点,此处的节点是对def,x,y等的代称,通常会具有一个特定的属性,如x,y是变量,def是函数符号等;其次是对每个节点进行编码,编码工作包括了利用语料库对每个节点的文本进行编码、对节点的特殊字义或类型进行编码(例如:while、for属于循环语句,public和def属于函数,以及ast自带的节点类型),文本编码和类型编码的格式均为[n_item,n_length’],n_length’表示代码片段的单词数量;然后是提取每一个节点的父节点,父节点亦经过上述处理;接下来是提取每一个节点的子节点的集合,子节点亦经过上述处理,子节点集合的格式为[n_item,n_length’,n_child],n_child表示子节点的数量,最后将父节点、当前节点和子节点一并作为当前节点的输入项。
[0130]
步骤s202,将编码后的试题参数转换成idpm模型所需要的格式。
[0131]
在本发明具体实施例中,获取试题题干信息,尺寸为[n_item,n_length];试题选项信息,尺寸为[n_item,n_length];试题标注知识点,尺寸为[n_item,1];试题标签,尺寸为[n_item,]。其中,n_item表示试题数量,n_length表示单词数量,表示这一个文本片段包含了多少个单词;
[0132]
步骤s3,将编码之后的试题参数进行embedding_lookup转换为idpm模型所能处理的数学向量后,代入bilstm函数进行运算,并对其结果进行最大值化(max)处理,将经bilstm函数处理后的试题题干信息、试题选项信息、试题解析信息和试题标注知识点信息进行拼接,通过全连接层和输出层的运算,并对输出层的结果构建交叉熵损失函数进行训练。
[0133]
具体地,步骤s3进一步包括
[0134]
步骤s300,通过编码层将编码后的试题参数进行embedding_lookup的转换,使其转换成idpm模型所能处理的数学向量。
[0135]
具体地,对编码之后的试题参数,将试题参数进行embedding_lookup的转换,使其转换成模型所能处理的数学向量,例如,获取试题题干信息,尺寸为[n_item,n_length],试题选项信息,尺寸为[n_item,n_length],试题解析信息,尺寸为[n_item,n_length],试题标注知识点,尺寸为[n_item,1],试题标签,尺寸为[n_item,],其中,n_item表示试题数量,n_length表示单词数量,表示这一个文本片段包含了多少个单词,转换后为:试题题干信息转换为[n_item,n_length,embed_size];试题选项信息转换为[n_item,n_length,embed_size];试题解析信息转换为[n_item,n_length,embed_size];试题标注知识点转换为[n_item,1,embed_size]。其中,embed_size表示向量长度,具体如下:
[0136]
embed=embedding_lookup(embedding_matrix,input)
[0137]
在本发明具体实施例中,在对代码片段的处理中需要增加一个环节,也即将当前节点的文本编码和类型编码转换为[n_item,n_length’,embed_size]后,进行拼接,拼接之后的格式为[n_item,n_length’,2*embed_size];具体如下:
[0138][0139]
然后对父节点和子节点集合进行编码,并对编码后的子节点集合进行max处理,两者的格式均为[n_item,n_length’,2*embed_size],具体如下:
[0140]
child
(n-item,n_length
′
,2*embed_size)
=max(children
(n_item,n_length
′
,n_child,2*embed_size)
,axis=2)
[0141][0142]
再后,将父节点、当前节点和子节点进行拼接,格式转变为[n_item,n_length’,6*embed_size],具体如下:
[0143][0144]
最后对其执行降维操作,与文本部分一并代入到之后的运算过程中。
[0145]
node
(n_item,n_length
′
,embed_size)
=weight*node+bias
[0146]
步骤s301,用于将编码层处理后的试题参数代入bilstm函数进行运算,并对其结果进行max处理。
[0147]
在本发明中,将编码层处理后的试题题干信息、选项信息、解析信息代入bilstm函数进行运算,并对其结果进行max处理,处理之后的参数尺寸均为[n_item,1,embed_size]:
[0148]
hidden
(nn_item,n_length,2*hidden_size)
=bilstm(embed)
[0149]
hidden
(n_item,1,2*hidden_size)
=max(hidden,axis=1)
[0150]
其中,bilstm是双向长短时记忆机制,分别从序列数据的前向和后向进行扫描处理。
[0151]
步骤s302,将步骤s301输出的题干信息、选项信息、解析信息和知识点信息进行拼接,再执行全连接层的运算。
[0152]
在本发明中,将题干信息、选项信息、解析信息和知识点信息进行拼接,并执行全连接层的操作,输出结果的尺寸为[n_item,1,hiddensize],具体如下:
[0153]
hidden
(n_item,1,hidden_size)
=concat([hidden
context
,hidden
option
,hidden
analyze
,knowledge],axis=-1)hidden
(n-item,1,hidden_size)
=weight*hidden+bias
[0154]
hidden
(n_item,1,hidden_size)
=p*tanh(hidden)+(1-p)*hidden
[0155]
其中,tanh为激活函数,p为调节参数,是为了一方面是为了避免层数过多而造成的梯度消散情况,另一方面则是避免resnet设计所造成的梯度爆炸情况,通过上述处理可使输出结果处于一个稳定的范围之内。
[0156]
步骤s303,参照步骤s302中全联接层的操作方式,将全连接层的结果转变为一维的logit值,经过sigmoid转换之后代入交叉熵损失函数进行训练。
[0157]
步骤s303的具体过程可如下式所示:
[0158]
logit
(nn_item,1,1)
=weight*hidden+bias
[0159]
prob=sigmoid(logit)
[0160]
loss=-[y*log(p)+(1-y)*log(1-p)]
[0161]
上述实施例仅例示性说明本发明的原理及其功效,而非用于限制本发明。任何本
领域技术人员均可在不违背本发明的精神及范畴下,对上述实施例进行修饰与改变。因此,本发明的权利保护范围,应如权利要求书所列。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1