一种基于平均认知策略的双档案存储的人工蜂群算法
1.本发明涉及一种基于平均认知策略的双档案存储的人工蜂群算法,属于人工智能技术领域。
背景技术:
2.为了在求解复杂问题时得到更加精确的解,多种基于仿生学的智能优化算法相继被提出,例如:人工蜂群算法、果蝇算法、遗传算法、鲸鱼算法、粒子群算法等。其中,人工蜂群算法于2005年由karaboga.d等人提出,其最初是为了解决单目标问题。后来由reza akbar等人改进提出多目标人工蜂群算法,可有效满足当时多目标优化问题的需要。
3.随着现实生产生活中的优化问题日益复杂,人工蜂群算法由于其结构简单,参数少等优势受到广泛关注,近年来,国内外学者对蜂群算法提出了多种改进方案,使人工蜂群算法不断完善,但其自身依然存在局部搜索能力较差、容易出现过早收敛的问题,仍需对其进一步改进。
技术实现要素:
4.本发明的目的是提供一种基于平均认知策略的双档案存储的人工蜂群算法,增加种群的多样性,提高算法收敛精度与进化速度,平衡人工蜂群算法全局开发能力与局部搜索能力不平衡的问题。
5.为了实现上述目的,本发明采用的技术方案是:
6.一种基于平均认知策略的双档案存储的人工蜂群算法,包括以下步骤:
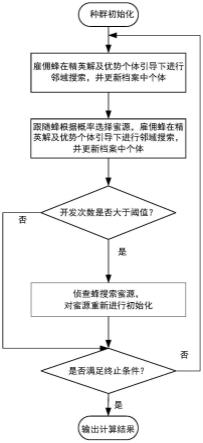
7.步骤一:初始化算法参数,所述参数包括种群数量、外部档案和个体档案大小np、最大评价次数maxfes;
8.步骤二:随机生成sn个具有d维变量的初始种群,并利用非支配排序选出外部档案与个体档案中的个体;
9.步骤三:计算平均认知位置;
10.步骤四:雇佣蜂对邻域进行搜索,并对外部档案及个体档案进行更新;
11.步骤五:跟随蜂阶段通过轮盘对赌的方式选择蜜源,并对蜜源进行邻域搜索,然后对外部档案及个体档案进行更新;
12.步骤六:若一个食物源在经过最大限制次数limit次迭代后,蜜源若未得到更新,雇佣蜂转变为侦查蜂,并搜索新的蜜源代替原有蜜源;
13.步骤七:判断评估次数≥maxfes,若是,则输出最优解;否则,转至步骤四。
14.本发明技术方案的进一步改进在于:所述步骤二根据式(1)随机生成sn个具有d维变量的初始种群,
15.x
i,j
=x
min,j
+rand(0,1)(x
max,j-x
min,j
)
ꢀꢀꢀ
(1)
16.式中,i=1,2,
…
,sn,j=1,2,
…
,d,其中每个xi代表一个d维向量,x
max
和x
min
为搜索空间内的上界和下界。
17.本发明技术方案的进一步改进在于:所述步骤三计算平均认知位置的公式为:
[0018][0019]
式中,c.p.为平均认知位置,a.i.i为个体档案中第i个个体,n为个体档案中优势个体数量。
[0020]
本发明技术方案的进一步改进在于:所述步骤四中雇佣蜂利用式(3)对邻域进行搜索:
[0021][0022]
式中,v
i,j
为邻域解,elite
i,j
为外部档案中随机选择的精英解,leader
i,j
为个体档案中优势个体的平均认知位置,
[0023]
根据式(4)对外部档案及个体档案进行更新,
[0024][0025]
式中,xm为拥挤距离最小的解,x为xm与其左侧解融合产生的解,y为xm与其右侧解融合产生的解,x
l
为与xm距离最近左侧的解,xr为与xm距离最近右侧的解。
[0026]
本发明技术方案的进一步改进在于:所述步骤五中跟随蜂阶段轮盘对赌方式的公式为:
[0027][0028]
式中,pi为第i个蜜源被选择概率,fiti为第i个蜜源适应度值,sn为蜜源个数。
[0029]
本发明技术方案的进一步改进在于:所述步骤六通过式(1)搜索新的蜜源代替原有蜜源。
[0030]
由于采用了上述技术方案,本发明取得的技术效果有:
[0031]
本发明提出双档案存储策略,在目标空间的精英解档案的基础上,增加了变量空间上的优势个体存储档案,对种群进化过程中产生的有益信息进行了充分利用,提高了算法的进化速度与寻优精度。
[0032]
本发明采用平均认知策略,将个体档案中个体引入搜索公式中,提高了种群的多样性,避免算法出现过早收敛的现象。
[0033]
本发明通过改进的外部档案维护机制,避免外部档案中出现环境多样性缺失的现象,保证种群的多样性,进一步提高算法的寻优效率。
附图说明
[0034]
图1是本发明的流程简图。
具体实施方式
[0035]
下面结合附图及具体实施例对本发明做进一步详细说明:
[0036]
一种基于平均认知策略的双档案存储的人工蜂群算法(atmabc),能够达到搜索某一问题最值的目的,通过matlab(商业数学软件,用于算法开发、数据可视化、数据分析以及数值计算的高级技术计算语言和交互式环境)对uf系列的测试函数最小化问题的仿真寻优,来测试本发明atmabc的性能,并与moabc、nsgaⅱ算法进行对比。测试函数特性如表1所示。
[0037]
表1uf系列测试函数特性
[0038][0039]
一种基于平均认知策略的双档案存储的人工蜂群算法(atmabc),如图1所示,包括以下步骤:
[0040]
步骤一:初始化算法参数:种群数量、外部档案和个体档案大小np,最大评价次数maxfes;
[0041]
步骤二:根据式(1)随机生成sn个具有d维变量的初始种群,并利用非支配排序选出外部档案与个体档案中的个体:
[0042]
x
i,j
=x
min,j
+rand(0,1)(x
max,j-x
min,j
)
ꢀꢀꢀ
(1)
[0043]
式中,i=1,2,
…
,sn,j=1,2,
…
,d,其中每个xi代表一个d维向量,x
max
和x
min
为搜索空间内的上界和下界。
[0044]
步骤三:根据式(2)计算平均认知位置:
[0045][0046]
式中,c.p.为平均认知位置,a.i.i为个体档案中第i个个体,n为个体档案中优势个体数量。
[0047]
步骤四:雇佣蜂利用式(3)对邻域进行搜索:
[0048][0049]
式中,v
i,j
为邻域解,elite
i,j
为外部档案中随机选择的精英解,leader
i,j
为个体档案中优势个体的平均认知位置,
[0050]
根据式(4)对外部档案及个体档案进行更新,
[0051][0052]
式中,xm为拥挤距离最小的解,x为xm与其左侧解融合产生的解,y为xm与其右侧解融合产生的解,x
l
为与xm距离最近左侧的解,xr为与xm距离最近右侧的解。
[0053]
步骤五:跟随蜂阶段通过式(5)中轮盘对赌的方式选择蜜源,并通过式(3)对蜜源进行邻域搜索,根据式(4)对外部档案及个体档案进行更新,
[0054][0055]
式中,pi为第i个蜜源被选择概率,fiti为第i个蜜源适应度值,sn为蜜源个数。
[0056]
步骤六:若一个食物源在经过最大限制次数limit次迭代后,蜜源若未得到更新,雇佣蜂转变为侦查蜂,并通过式(1)搜索新的蜜源代替原有蜜源。
[0057]
步骤七:判断评估次数≥maxfes,若是,则输出最优解;否则,转至步骤四。
[0058]
采用atmabc、moabc、nsga
ꢀⅱ
三种算法在相同条件下对uf系列测试函数进行寻优求解,且每个函数独立运行30次,并记录igd均值(mean)和方差(std),并用*引出同意测试函数下算法所获得最优值。表2为三种算法igd指标仿真结果比较。
[0059]
表2 igd指标仿真结果比较
[0060][0061]
由表2可以看出:atmabc算法在uf系列十个测试函数中有九个获得有优igd值,可以说明atmabc算法在uf系列测试函数上可获得良好的解集。在双目标问题(uf1-uf7)中,atmabc算法在uf3测试函数上未取得最优值,但与最优值在同一数量级上,说明解集也具有较好的收敛效果。在uf6和uf7两个测试函数上,均取得较好的方差值,但未取得较好的平均值,其原因是算法在这两种测试函数下收敛效果不明显,有待进一步改进。在三目标测试函数下,只有在uf9测试上未获得最优平均值。整体效果来看,atmabc算法优于其他对比算法,说明算法所获得解集具有良好的分布性与收敛性,且针对三目标问题仍然可以获得较好的结果,说明算法有处理复杂问题的能力。
[0062]
本发明采用了双档案存储的方式,在原有外部档案存储目标空间的精英解的基础上,增加一个个体档案,用于存储变量空间中的优势个体,以达到充分利用种群进化过程中的有利信息,起到对种群的进化方向充分引导的作用,提高算法的进化效率与搜索精度。由于人工蜂群算法存在全局开发策略与局部搜索策略不平衡的问题,在提高种群引导性的同时,也要保障种群的多样性,利用平均认知策略,在种群进化过程中引入新个体,在提高种群多样性的同时,也保证了种群的进化速度。
[0063]
虽然以上描述了本发明的具体实施方式,但是熟悉本技术领域的技术人员应当理
解,我们所描述的具体的实施例只是说明性的,而不是用于对本发明的范围的限定,熟悉本领域的技术人员在依照本发明的精神所作的等效的修饰以及变化,都应当涵盖在本发明的权利要求所保护的范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1