一种融合常识知识的中文特定领域实体链接方法
1.本发明属于深度学习技术领域,具体涉及一种中文特定领域实体链接方法。
背景技术:
2.近年来,国内外针对跨领域的实体链接方法具有广泛研究,目前最常用的是一种端到端的方法,总共分为两个步骤:命名实体识别(ner)和链接(linking)。前者准确率的提升可以极大的影响到后者链接的准确率。从目前的研究现状来看,传统的 ner研究主要集中在对人名、地名、组织机构名、时间表达式等通用命名实体的识别上,缺乏对特定领域实体的识别研究。另外,由于中文本身的一词多义、多词一意和断句困难的特殊性,以及中英转化的不准确不完整性,这使得在通用中文命名实体识别任务中的准确率通常会比英文命名实体识别低10%左右。因此中文特定领域知识的命名实体识别任务成为目前该领域的一大挑战。
3.现阶段最常用于ner任务的模型是bert-crf模型,这是一种不依赖人工的端到端的深度学习方法。但这种方法只利用到了短文本的信息,仅能实现短文本到知识库的单向匹配链接,没有利用到知识库中的实体信息。并且仍然存在实体边界识别错误,句子中实体识别不全等问题。
技术实现要素:
4.为了克服现有技术的不足,本发明提供了一种融合常识知识的中文特定领域实体链接方法,该方法先进行常识知识的获取和预处理,再基于指定领域进行百科语料知识库的构建与补全,然后基于bert-bigru-crf模型和双向匹配策略进行命名实体识别,最终基于知识表示学习实现实体链接过程。本发明能够有效的解决上述实体边界识别错误和实体识别补全的问题,极大的提高了命名实体识别任务和实体链接任务的准确性。
5.本发明解决其技术问题所采用的技术方案包括如下步骤:
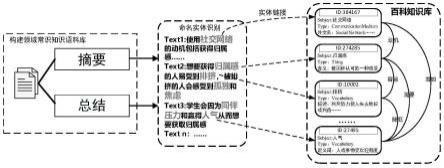
6.步骤1:构建指定领域常识知识语料库:爬取包括心理学、社会学在内的指定领域文献,提取文献中的摘要部分和总结部分的文本,并对提取的文本进行句子切分、去除标点、去掉停用词,以处理后的每个文本字段text、文本中的提及实体mention_data 和提及实体对应在百科知识库中的编号kb_id作为训练样本,得到指定领域常识知识语料库;所述的文本中的提及实体mention_data包括识别后待链接的实体mention;
7.步骤2:构建与补全百科知识库:首先,根据百度百科中社交网络用户行为相关的百科知识,将百科词条以三元组《h,r,t》的结构构建百科知识图谱,h为实体entity, r为谓词predicate,t为对象object;然后,对百科知识图谱进行修正与补全,具体包括:
8.(1)对由大写英文字母构成的特殊专有实体名称进行小写转换;
9.(2)将包括单引号、逗号、句号在内的特殊符号转换为英文字符,并将转换后的名称加入到该实体所对应的别名中;
10.(3)爬取包括心理学、社会学在内的指定领域专有名词词条,进行数据格式的转
换,转换成三元组《h,r,t》的结构,并添加到已构建好的百科知识图谱中;
11.步骤3:实体描述文本重建:将百科知识库中的所有谓词和对象相连得到实体描述文本,如果实体描述文本的长度大于d,对描述文本以d为单位进行截断处理,d为预设的长度;构建五个字典,包括:
12.(1)以百科知识库中的实体名称作为主键,构建得到实体索引字典entity_id;
13.(2)以百科知识库中的实体在百科知识库中的索引作为主键,构建得到索引实体字典id_entity;
14.(3)以百科知识库中的实体描述文本的索引作为主键,构建得到实体描述文本字典id_text;
15.(4)以百科知识库中的实体在百科知识库中的索引作为主键,构建得到实体类别字典id_type;
16.(5)以百科知识库中的实体类别的索引作为主键,构建得到类别字典type_index;
17.步骤4:构建中文命名实体识别bert-bigrus-crf模型:包括输入层、深度双向预训练语言模型bert层、双向门控循环神经网络bigrus层和条件随机场crf层;
18.步骤4-1:所述深度双向预训练语言模型bert层的结构由嵌入层、编码器、池化层三部分构成;输入来自常识知识语料库的文本,通过bert层后,生成基于上下文信息的词向量;
19.步骤4-2:所述双向门控循环神经网络bigrus层包括方向相反的2个门控环单元gru网络和1个全局池化层,将bert层输出的词向量分别输入到正向gru网络和反向gru网络中,分别获得实体mention对应的前后语义信息向量和将这两个向量做拼接得到h
con
;之后到池化层做最大池化操作,得到文本中字词的全局语义信息h
max
后输入到条件随机场crf层中等待输出序列标注结果;其中,bigrus 层在t时刻的隐层状态h
t
按下式计算得到:
[0020][0021]
其中,表示t时刻正向gru网络的隐层状态,表示t时刻反向gru网络的隐层状态,w
t
表示t时刻正向gru网络的隐层状态的权重,v
t
表示t时刻反向gru网络的隐层状态的权重,b
t
表示t时刻隐层状态所对应的偏置;
[0022]
和分别按以下公式计算得到:
[0023][0024][0025]
其中,gru表示对输入的词向量的非线性变换,把词向量编码成对应的gru隐层状态;x
t
表示当前输入的词向量,表示t-1时刻正向gru网络的隐层状态,表示t-1时刻反向gru网络的隐层状态;
[0026]
步骤4-3:条件随机场crf层利用文本中每个词的邻近标签关系进行最优序列预测,其计算过程如下:
[0027]
首先,按照以下公式计算得到预测序列y对于输入序列x的预测得分s:
[0028][0029]
其中,x=(x1,x2,
…
,xn)表示输入crf层的词向量序列,即全局语义信息h
max
,xi表示输入的第i个词向量,n表示输入的词向量总数,y=(y1,y2,
…
,yn)表示预测序列,yi表示第i个词的预测标注结果,s(x,y)表示预测序列y对于输入序列x的预测得分,p
i,yi
表示第i个词被标注为yi标签的分数;a表示转移分数,a
yi,yi+1
代表标签yi转移为标签yi+1的分数;
[0030]
再按照以下公式计算得到预测序列y产生的概率p(y|x):
[0031][0032]
其中,表示真实的标注序列,y
x
表示所有可能的标注序列集合,表示真实标注序列对于输入序列x的预测得分;
[0033]
对公式(5)的等式两边取对数得到预测序列y的似然函数ln(p(y|x)):
[0034][0035]
最后,按照以下公式(7)计算得到最高预测分数的输出序列y
*
:
[0036][0037]
步骤5:命名实体识别模型训练:将步骤1得到的指定领域常识知识语料库中的训练样本随机均分9份数据集,输入到步骤4构建的bert-bigrus-crf模型,采用 9折交叉验证方式,对模型进行训练,得到训练好的bert-bigrus-crf模型;
[0038]
步骤6:常识文本知识命名实体识别:运用训练好的bert-bigrus-crf模型对步骤1中常识知识语料库中的文本进行处理,得到每条文本中的标注序列;
[0039]
步骤7:常识知识语料库mention与百科知识库实体双向匹配:将实体描述文本输入至深度双向预训练语言模型bert层中获得实体向量表示,与步骤6中得到的文本标注序列再次进行拼接后,经过一层卷积神经网络和激活函数,最终输出命名实体识别结果,输出结果为一维的01向量,0代表未识别,1代表成功识别;
[0040]
步骤8:实体链接模型训练:模型训练时的训练样本选取部分正确链接的实体作为正例,其余未被正确连接的候选实体作为负例;
[0041]
所述实体链接模型为将步骤7输出中“1”所对应的mention向量与百科知识库中已匹配到的候选实体的实体描述文本连在一起,输入到深度双向预训练语言模型bert 层获得向量表示;之后经过全连接层,通过激活函数激活得到候选实体的概率得分,选取概率最高的候选实体建立链接;最后输出建立链接的序列,若正确链接值为1,否则值为0;
[0042]
步骤9:将常识知识语料库中的文本中已识别的mention向量以及百科知识库中待链接的实体描述文本向量做拼接,输入至训练好的实体链接模型,输出最终是否建立链接的序列,筛选出值为1所对应的拼接向量,即获得完成实体链接的领域知识库。
[0043]
本发明的有益效果如下:
[0044]
本发明中采用的bert-bigru-crf算法以及双向匹配策略是一种既利用短文本中上下文信息也利用知识库中实体描述信息的方法,实现了双相匹配的过程,且能够有效的解决上述实体边界识别错误和实体识别补全的问题,极大的提高了命名实体识别任务和实
体链接任务的准确性。
附图说明
[0045]
图1是本发明方法框架图;
[0046]
图2是本发明中命名实体识别匹配过程的算法网络结构图。
[0047]
图3是本发明百科知识库进行实体表示学习的过程图。
[0048]
图4是本发明双向实体匹配成功后进行实体链接的模型图。
具体实施方式
[0049]
下面结合附图和实施例对本发明进一步说明。
[0050]
如图1所示,一种融合常识知识的中文特定领域实体链接方法,包括如下步骤:
[0051]
步骤1:构建指定领域常识知识语料库:爬取包括心理学、社会学在内的指定领域文献,提取文献中的摘要部分和总结部分的文本,并对提取的文本进行句子切分、去除标点、去掉停用词,以处理后的每个文本字段text、文本中的提及实体mention_data 和提及实体对应在百科知识库中的编号kb_id作为训练样本,得到指定领域常识知识语料库;所述的文本中的提及实体mention_data包括识别后待链接的实体mention;
[0052]
步骤2:构建与补全百科知识库:首先,根据百度百科中社交网络用户行为相关的百科知识,将百科词条以三元组《h,r,t》的结构构建百科知识图谱,h为实体entity, r为谓词predicate,t为对象object;然后,对百科知识图谱进行修正与补全,具体包括:
[0053]
(1)对由大写英文字母构成的特殊专有实体名称进行小写转换;
[0054]
(2)将包括单引号、逗号、句号在内的特殊符号转换为英文字符,并将转换后的名称加入到该实体所对应的别名中;
[0055]
(3)爬取包括心理学、社会学在内的指定领域专有名词词条,进行数据格式的转换,转换成三元组《h,r,t》的结构,并添加到已构建好的百科知识图谱中;
[0056]
步骤3:实体描述文本重建:将百科知识库中的所有谓词和对象相连得到实体描述文本,如果实体描述文本的长度大于d,对描述文本以d为单位进行截断处理,d为预设的长度;构建五个字典,包括:
[0057]
(1)以百科知识库中的实体名称作为主键,构建得到实体索引字典entity_id;
[0058]
(2)以百科知识库中的实体在百科知识库中的索引作为主键,构建得到索引实体字典id_entity;
[0059]
(3)以百科知识库中的实体描述文本的索引作为主键,构建得到实体描述文本字典id_text;
[0060]
(4)以百科知识库中的实体在百科知识库中的索引作为主键,构建得到实体类别字典id_type;
[0061]
(5)以百科知识库中的实体类别的索引作为主键,构建得到类别字典type_index;
[0062]
步骤4:构建中文命名实体识别bert-bigrus-crf模型:包括输入层、深度双向预训练语言模型bert层、双向门控循环神经网络bigrus层和条件随机场crf层;
[0063]
步骤4-1:所述深度双向预训练语言模型bert层的结构由嵌入层、编码器、池化层三部分构成;输入来自常识知识语料库的文本,通过bert层后,生成基于上下文信息的词向
量;
[0064]
步骤4-2:所述双向门控循环神经网络bigrus层包括方向相反的2个门控环单元gru网络和1个全局池化层,将bert层输出的词向量分别输入到正向gru网络和反向gru网络中,分别获得实体mention对应的前后语义信息向量和将这两个向量做拼接得到h
con
;之后到池化层做最大池化操作,得到文本中字词的全局语义信息h
max
后输入到条件随机场crf层中等待输出序列标注结果;其中,bigrus 层在t时刻的隐层状态h
t
按下式计算得到:
[0065][0066]
其中,表示t时刻正向gru网络的隐层状态,表示t时刻反向gru网络的隐层状态,w
t
表示t时刻正向gru网络的隐层状态的权重,v
t
表示t时刻反向gru网络的隐层状态的权重,b
t
表示t时刻隐层状态所对应的偏置;
[0067]
和分别按以下公式计算得到:
[0068][0069][0070]
其中,gru表示对输入的词向量的非线性变换,把词向量编码成对应的gru隐层状态;x
t
表示当前输入的词向量,表示t-1时刻正向gru网络的隐层状态,表示t-1时刻反向gru网络的隐层状态;
[0071]
步骤4-3:条件随机场crf层利用文本中每个词的邻近标签关系进行最优序列预测,其计算过程如下:
[0072]
首先,按照以下公式计算得到预测序列y对于输入序列x的预测得分s:
[0073][0074]
其中,x=(x1,x2,
…
,xn)表示输入crf层的词向量序列,即全局语义信息h
max
,xi表示输入的第i个词向量,n表示输入的词向量总数,y=(y1,y2,
…
,yn)表示预测序列,yi表示第i个词的预测标注结果,s(x,y)表示预测序列y对于输入序列x的预测得分,p
i,yi
表示第i个词被标注为yi标签的分数;a表示转移分数,a
yi,yi+1
代表标签yi转移为标签yi+1的分数;
[0075]
再按照以下公式计算得到预测序列y产生的概率p(y|x):
[0076][0077]
其中,表示真实的标注序列,y
x
表示所有可能的标注序列集合,表示真实标注序列对于输入序列x的预测得分;
[0078]
对公式(5)的等式两边取对数得到预测序列y的似然函数ln(p(y|x)):
[0079][0080]
最后,按照以下公式(7)计算得到最高预测分数的输出序列y
*
:
[0081][0082]
步骤5:如图2所示,命名实体识别模型训练:将步骤1得到的指定领域常识知识语料库中的训练样本随机均分9份数据集,输入到步骤4构建的bert-bigrus-crf 模型,采用9折交叉验证方式,对模型进行训练,得到训练好的bert-bigrus-crf 模型;
[0083]
步骤6:如图3所示,常识文本知识命名实体识别:运用训练好的bert-bigrus
‑ꢀ
crf模型对步骤1中常识知识语料库中的文本进行处理,得到每条文本中的标注序列;使用bio标注方法,即用{b(begin),i(inside),o(outside)}来标注文本中所提及的实体,被标注为“b”和“i”的连续向量片段即为识别出的mention;
[0084]
步骤7:常识知识语料库mention与百科知识库实体双向匹配:将实体描述文本输入至深度双向预训练语言模型bert层中获得实体向量表示,与步骤6中得到的文本标注序列再次进行拼接后,经过一层卷积神经网络和激活函数,最终输出命名实体识别结果,输出结果为一维的01向量,0代表未识别,1代表成功识别;
[0085]
步骤8:实体链接模型训练:模型训练时的训练样本选取部分正确链接的实体作为正例,其余未被正确连接的候选实体作为负例;
[0086]
所述实体链接模型为将步骤7输出中“1”所对应的mention向量与百科知识库中已匹配到的候选实体的实体描述文本连在一起,输入到深度双向预训练语言模型bert 层获得向量表示;之后经过全连接层,通过激活函数激活得到候选实体的概率得分,选取概率最高的候选实体建立链接;最后输出建立链接的序列,若正确链接值为1,否则值为0;如图4所示;
[0087]
步骤9:将常识知识语料库中的文本中已识别的mention向量以及百科知识库中待链接的实体描述文本向量做拼接,输入至训练好的实体链接模型,输出最终是否建立链接的序列,筛选出值为1所对应的拼接向量,即获得完成实体链接的领域知识库。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1