信息处理装置、信息处理方法以及计算机程序与流程
信息处理装置、信息处理方法以及计算机程序
1.本技术以日本特许申请2021-070913(申请日:04/20/2021)为基础,根据该申请享受优先利益。本技术通过参照该申请而包含该申请的全部内容。
技术领域
2.本实施方式涉及信息处理装置、信息处理方法以及计算机程序。
背景技术:
3.在气象预测、异常气象预测、防灾、可再生能量、水力发电、股价、风险分析等领域中,广泛进行了使用当前和过去的时间序列数据来预测目标变量的一定时间后的值(将来值)。已知以使得在时间序列数据的全部区间中预测值与实绩值的误差最小化的方式构建模型的方法,但在通过该方法构建的模型中,具有在峰值、即极值处预测误差变得非常大的问题。另外,具有如下倾向:当预测期间变长时,预测误差会在峰值处变得更大。
4.在水库的水位预测、风速预测、异常气象预测等中,为了防灾而高精度地预测峰值是非常重要的。虽然能够生成能使用基于深度学习的方法来高精度地预测峰值的模型,但为了对庞大数量的模型参数进行学习,需要收集大量的采样。当所收集的采样数少时,模型的预测精度会变低,难以高精度地预测峰值(极值)。另外,具有如下倾向:当预测期间变长时,预测误差会变大。
技术实现要素:
5.本发明的实施方式提供能够高精度地预测成为预测对象的变量的值的信息处理装置、信息处理方法以及计算机程序。
6.用于解决问题的技术方案
7.本实施方式涉及的信息处理装置具备:分组部,其对包含多个第1变量和第2变量的第1数据中的所述多个第1变量进行分组,生成包含所述第1变量的多个组;和决定部,其基于所述第1数据,决定对所述多个组所包含的所述第1变量和所述第2变量的预测值进行关联的预测模型的模型架构。
附图说明
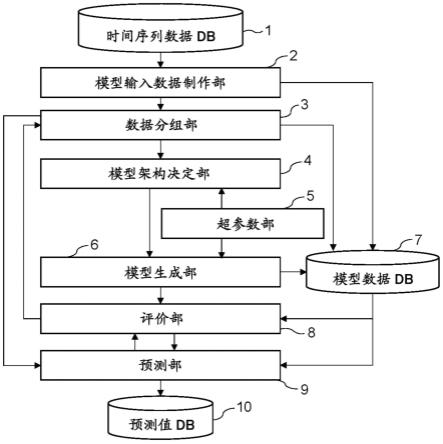
8.图1是实施方式涉及的预测装置的框图。
9.图2是表示峰值的预测精度低的例子和能够高精度地预测峰值的例子的图。
10.图3是表示目标变量和说明变量的时间序列数据的例子的图。
11.图4是表示使用了说明变量与目标变量之间的相互相关的模型输入数据的制作例的图。
12.图5是相互相关的说明图。
13.图6是表示使用了变量选择方法的模型输入数据的制作例的图。
14.图7是表示使用了变量选择方法的模型输入数据的制作例的图。
15.图8是表示预测模型的一个例子的图。
16.图9是表示使用了比较例涉及的深度学习的预测模型的模型架构的例子的图。
17.图10是表示使用了本实施方式涉及的深度学习的预测模型的模型架构的例子的图。
18.图11是表示与模型架构相应的输入输出节点数的例子的图。
19.图12是表示与模型架构相应的各层的参数数量的计算例的图。
20.图13是表示比较例涉及的深度学习的模型参数数量和本实施方式涉及的深度学习的模型参数数量的比较例的图。
21.图14是表示层数、数据分组、参数(n)、模型参数数量、预测精度的关系的图。
22.图15是表示时间序列数据的一个例子的图。
23.图16是表示决定模型架构的第1例的图。
24.图17是表示决定模型架构的第2例的图。
25.图18是用于生成预测模型、预测目标变量的将来值的流程图。
26.图19是用于决定模型输入数据的数据分组和模型架构的流程图。
27.图20是表示用于决定数据分组和模型架构的gui的图。
28.图21是表示生成新的变量的例子的图。
29.图22是表示使用遗传编程来制作新的变量的例子的图。
30.图23是实施方式涉及的信息处理系统的框图。
31.标号说明
[0032]1ꢀꢀꢀ
时间序列数据db
[0033]2ꢀꢀꢀ
模型输入数据制作部(数据制作部)
[0034]3ꢀꢀꢀ
数据分组部(分组部)
[0035]4ꢀꢀꢀ
模型架构决定部(决定部)
[0036]5ꢀꢀꢀ
超参数部
[0037]6ꢀꢀꢀ
模型生成部
[0038]7ꢀꢀꢀ
模型数据db
[0039]8ꢀꢀꢀ
评价部
[0040]9ꢀꢀꢀ
预测部
[0041]
101 信息处理装置(预测装置)
[0042]
102 计划装置(计划部)
[0043]
801 文件名
[0044]
802 采样数
[0045]
803 说明变量和目标变量的个数
[0046]
804 预测步长数
[0047]
805 变量表
[0048]
806 时滞(lag)字段
[0049]
807 模型输入数据制作方法
[0050]
808 数据分组
[0051]
809 文本框
[0052]
810 分割方法
[0053]
811 层数
[0054]
812 模型架构
[0055]
813 模型参数数量
[0056]
814 评价得分表
[0057]
815 模型输出文件
具体实施方式
[0058]
以下,参照附图对本发明的实施方式进行说明。另外,在附图中,对相同的构成要素赋予相同的编号,适当地省略说明。
[0059]
图1是作为本实施方式涉及的信息处理装置的预测装置101的框图。
[0060]
图1的预测装置101具备时间序列数据db(数据库)1、模型输入数据制作部2(数据制作部)、数据分组部3(分组部)、模型架构决定部4(决定部)、超参数部5、模型生成部6、模型数据db7、评价部8、预测部9、预测值db10。
[0061]
图1的预测装置101是用于基于包含说明变量和目标变量的时间序列数据来高精度地预测目标变量将来的值的装置。例如,进行水库的水位预测(与水力发电站的蓄水量有关的预测)、风速预测、异常气象预测、风险分析预测、股价预测等。作为本实施方式的技术背景,存在目标变量的预测、特别是峰值(极值)的预测困难这一问题。本实施方式使得能够高精度地进行目标变量的峰值的预测。
[0062]
图2的左图表示难以预测峰值的例子。本例表示使用了比较例涉及的深度学习的预测结果。根据本事例,最高的峰的预测值与实绩值之差pd1、第二高的峰的预测值与实绩值之差pd2都大,预测的精度低。
[0063]
图2的右图表示能够高精度地预测峰值的例子。在全部峰中,预测值与实绩值的差分小,能得到高的预测精度。该预测结果是通过后述的本实施方式涉及的深度学习得到的,在本实施方式中能够进行峰值的高精度的预测。
[0064]
时间序列数据db1保持目标变量的过去和当前的时间序列数据。另外,时间序列数据db1保持说明变量的过去、当前、将来的时间序列数据。说明变量的将来的时间序列数据是说明变量的预测值的时间序列数据。例如在进行水库流入量预测的情况下,说明变量的预测值也可以是气象预测值。
[0065]
时间序列数据db1既可以仅保持目标变量的时间序列数据,也可以保持目标变量和说明变量的时间序列数据。进行目标变量的预测的时间点的时刻与当前时刻对应。
[0066]
另外,时间序列数据db1也可以不是保持说明变量或者目标变量的过去的全部区间的时间序列数据,而是仅保持全部区间中的呈现特征性波形的区间的数据。
[0067]
时间序列数据db1保持以各时间戳计测的目标变量的值和说明变量的值是模型学习用数据还是预测用数据的标志(识别标志)。时间序列数据db1也可以保持是实施模型学习处理还是实施预测处理的标志(模式标志)。
[0068]
图3表示时间序列数据db1保持的目标变量和说明变量的时间序列数据的一个例子。x1(t)和x2(t)是说明变量项目,y(t)是目标变量。x1(t)、x2(t)以及y(t)是互不相同的项目的值。时间戳是对目标变量的值或者说明变量的值进行了计测的日期时间(时刻)。对
于各时间戳的数据(目标变量的值和说明变量的值)仅设定有是为模型学习用数据、还是为预测用数据的标志(识别标志)。
[0069]
模型输入数据制作部2使用由时间序列数据db1所保持的目标变量和说明变量的时间序列数据,基于目标变量与说明变量的关系性来制作模型输入数据。
[0070]
模型输入数据制作部2在实施模型学习处理时,基于识别标志从时间序列数据db1提取模型学习用数据,制作模型学习用的模型输入数据(第1数据)。模型输入数据制作部2在实施预测处理时,基于识别标志从时间序列数据db1提取预测用数据,制作预测用的模型输入数据(第1数据)。
[0071]
模型输入数据制作部2为了制作模型输入数据(第1数据),使用时间序列数据中的目标变量与说明变量间的相互相关、目标变量的自相关、交互信息(mic)、aic、lasso、线性回归、回归树或者变量选择方法(例如遗传算法等)。
[0072]
图4表示使用说明变量与目标变量之间的相互相关来制作模型输入数据的例子。在本事例中,t+δt表示从各时间戳t起δt步长后的时刻(预测对象时刻)。δt与预测期间或者预测步长对应。在相互相关中,发现目标变量与说明变量的相关高的时间偏差(时滞)。若将时间偏差设为li,则从t+δt回溯了li的时刻成为t+δt-li。包含该时刻而提取说明变量的2wi+1(w:窗宽度)个时刻的过去的值。2wi+1(w:窗宽度)个时刻是说明变量的多个不同的时刻,该多个不同的时刻是预测对象时刻(t+δt)之前的时刻。
[0073]
图5表示提取某说明变量中的2wi+1(w:窗宽度)个时刻的值的例子。确定从t+δt回溯了li的时刻t+δt-li。包含t+δt-li而提取包括过去的wi个时刻和将来的wi个时刻的合计2wi+1个说明变量的值。
[0074]
在上述的图4的例子中,对于说明变量x1,作为与目标变量的相互相关而算出了l1的时滞,因此,包含t+δt-l1而提取包括过去的w1个时刻和将来的w1个时刻的合计2w1+1个过去的时刻的值。即,在说明变量x1的情况下,模型输入数据的各时间戳的数据成为x1(t+δt-l
1-w1)、
……
、x1(t)、x1(t+δt-l1+w1)。
[0075]
同样地,对于说明变量x2,作为与目标变量的相互相关而算出了l2的时滞,因此,包含t+δt-l2而提取包括过去的w2个时刻和将来的w2个时刻的合计2w2+1个过去的时刻的值。即,在说明变量x2的情况下,模型输入数据中的各时间戳的数据成为x2(t+δt-l
2-w2)、
……
、x2(t)、x2(t+δt-l2+w2)。此外,在假如不存在说明变量的预测值的情况下,仅使用过去的值。在该情况下,成为δt=0,成为-li+wi=min(0、-li+wi)。w1和w2的值是预先设定的。min(a、b)是表示a和b中的某个较小一方的函数。
[0076]
此外,提取说明变量x1、x2的当前时刻t的值、目标变量y的当前时刻t的值、目标变量的δt后的时刻(t+δt)的值。
[0077]
通过以上,制作一个时间戳量的模型输入数据(图4的表的1行量的数据)。关于多个时间戳同样地制作模型输入数据。一个时间戳量的数据与模型输入数据的1个采样对应。各采样的时间戳与当前时刻t对应。此外,也可以是模型输入数据不包含y(t)的构成。
[0078]
y(t+δt)以外的多个变量与模型输入数据(第1数据)中的多个第1变量对应。当前时刻t的值(在图4的例子中为y(t))也与模型输入数据中的第1变量对应。y(t+δt)与模型输入数据中的第2变量对应。时刻(t+δt)与预测对象时刻对应。y(t)是预测对象时刻之前的时刻的目标变量的一个例子,也存在使用目标变量的自相关而y(t-1)、y(t-2)
……
等被
作为第1变量进行提取的情况。另外,y(t+δt)是模型输入数据中的第2变量的一个例子,也可以存在多个第2变量。例如,在δt=5的情况下,也可以是y(t+1)、y(t+2)、y(t+3)、y(t+4)进一步被设定为第2变量(相当于预测模型的目标变量)。
[0079]
图6表示使用变量选择方法来制作模型输入数据(第1数据)的例子。在本例子中,在存在说明变量的预测值的情况下,使用时刻t的窗宽度w前的时刻t-w~t+δt的各时刻的说明变量的值、和时刻t的窗宽度w前的时刻t-w~时刻t的各时刻和δt后的时刻(t+δt)的目标变量的值,制作暂时性的模型输入数据(暂定模型输入数据)。在图6中示出所制作的暂时性的模型输入数据的例子。y(t+δt)以外的多个变量与暂时性的模型输入数据中的多个第1变量对应。当前时刻t的y的值(y(t))、
……
、y(t-w)等也与暂时性的模型输入数据中的第1变量对应。y(t+δt)与暂时性的模型输入数据中的第2变量对应。
[0080]
图7表示在按说明变量x1、x2以及目标变量y而设定了不同的值来作为窗宽度w的值的情况下所制作的暂时性的模型输入数据的例子。y(t+δt)与暂时性的模型输入数据中的第2变量对应。y(t+δt)以外的变量与暂时性的模型输入数据中的第1变量对应。
[0081]
模型输入数据制作部2使用交互信息(mic)、aic、lasso、线性回归、回归树或者变量选择方法,从暂时性的模型输入数据选择重要的第1变量。模型输入数据制作部2也可以具备选择变量的变量选择部。在使用了lasso、线性回归或者回归树的情况下,使用暂时性的模型输入数据,制作预测第2变量(相当于暂时性的预测模型的目标变量)的暂时性的预测模型,使用暂时性的预测模型所包含的第1变量的系数,选择第1变量。例如选择系数的绝对值为上位的多个第1变量。使用所选择的多个第1变量的值和第2变量的值,制作模型输入数据。所选择的第1变量相当于暂时性的预测模型的说明变量,第2变量与暂时性的预测模型的目标变量对应。时间序列数据中的说明变量以及目标变量与暂时性的预测模型中的说明变量以及目标变量不一定一致。例如时间序列数据中的当前时刻t以前的目标变量可能与暂时性的预测模型中的说明变量对应。
[0082]
数据分组部3对模型输入数据制作部2所制作的模型输入数据所包含的变量(第1变量)进行分组,生成一个以上的数据组(将把第1变量分为多个数据组的方法称为数据分组)。数据分组部3既可以根据先验知识将变量分割到多个数据组,也可以随机地对变量(第1变量)进行分割,生成多个数据组。或者,也可以在模型输入数据制作部2与模型架构决定部4之间进行协作来进行向数据组的分割。
[0083]
在根据先验知识将变量(第1变量)分割到多个数据组的情况下,也可以将模型输入数据中的变量分割到过去的数据组(第2组)、当前的数据组(第1组)以及将来的数据组(第3组)这三个数据组。在随机地对变量进行分割的情况下,也可以决定数据组数,对各组随机地分配模型输入数据的变量。数据分组部3也可以与模型架构决定部4协作,为了能够生成能进行高精度的预测的预测模型的模型架构,生成数据分组的多个候选,对能够生成该模型架构的分组候选进行选择。
[0084]
模型架构决定部4使用通过数据分组部3所决定的数据分组对变量(第1变量)进行了分割而得到的数据组,决定能够进行高精度的预测的预测模型的模型架构。模型架构规定模型的型式或者函数的型式。例如若模型为多层神经网络,则具有层的种类、数量、层所包含的节点数等。将在后面对此进行描述。
[0085]
超参数部5决定模型的超参数的值。例如在深度学习的情况下,决定activation函
数、批大小、世代(epoch)数、损失函数、优化方法等来作为超参数。作为一个例子,超参数部5存储这些值,使用所存储的值。或者,超参数部5也可以经由输入装置从作为本装置的操作者的用户取得超参数的值,使用所取得的值。此外,超参数是指在进行学习时预先决定的参数。
[0086]
模型生成部6基于与数据分组相应的模型学习用数据、和由模型架构决定部4决定的模型架构,生成(学习)预测模型。作为模型学习方法,使用基于了深度学习的方法、基于了通常的神经网络(前馈神经网络)的方法等。在基于了深度学习的方法中,使用多层化的神经网络。这些方法是基于回归模型的方法的一个例子,也可以使用基于其他回归模型的方法。例如也可以使用组合了各数据组的线性回归(或者重回归)和将各线性回归的输出值作为成员(member)的集成(ensemble)学习的方法等。在本实施方式中,使用基于了深度学习的方法来进行说明。预测模型所包含的第1变量相当于预测模型的说明变量,预测模型的第2变量与预测模型的目标变量对应。因此,时间序列数据中的说明变量以及目标变量与预测模型中的说明变量以及目标变量不一定一致。例如时间序列数据中的当前时刻t以前的目标变量可能与预测模型中的说明变量(第1变量)对应。
[0087]
模型生成部6也可以根据模型输入数据的第2变量(目标变量)的值,对各采样(各时间戳中的模型输入数据;即模型输入数据的一行)附加权重。例如,模型生成部6也可以通过模型输入数据的第2变量(目标变量)的值与阈值的比较,将模型输入数据分类到多个类别,按各类别对模型输入数据(采样)附加不同的权重,生成预测模型(即对模型参数进行学习)。作为一个例子,对于目标变量(第2变量)的值为阈值以上的采样,作为该第2变量的值与峰部对应来设定第1权重。对于目标变量(第2变量)的值小于阈值的采样,作为该第2变量的值与非峰部对应来设定比第1权重小的第2权重。模型生成部6也可以使用将模型输入数据的目标变量的值作为输入的函数,将函数的输出作为权重来附加于各采样。
[0088]
模型数据db7保持与模型输入数据制作部2所制作的模型输入数据所包含的变量有关的信息(变量信息)、与模型生成部6所生成的预测模型有关的信息(模型信息。例如预测模型所包含的模型参数的值)、与数据分组部3输出的数据分组有关的信息(数据分组信息)、与模型架构决定部4决定的模型架构有关的信息(模型架构信息)。
[0089]
具体而言,变量信息包括由模型输入数据制作部2制作的模型输入数据所包含的变量(第1变量和第2变量)。在变量由函数表示的情况下,也可以保持该函数。在通过变量选择方法选择了变量(第1变量)的情况下,也可以将变量选择方法的信息包含于变量信息。
[0090]
数据分组信息包括数据组数和属于各数据组的变量(第1变量)的信息。
[0091]
模型架构信息在深度学习的情况下包括神经网络(模型)中的层的信息、层数、各层的节点数。
[0092]
模型信息包括超参数信息、模型的参数值(例如节点与节点的连接的权重、偏置值)。也可以在模型信息中包括模型架构信息。
[0093]
评价部8使用预测模型和模型学习用的模型输入数据,算出各采样(模型输入数据)的预测值,基于采样的实绩值与预测值的差分,算出预测模型的评价得分。例如使用图6的模型输入数据的第1个采样所包含的变量(第1变量和第2变量)中的预测模型所包含的变量(第1变量和第2变量),预测t+δt的y的值。算出所预测到的值与第1个采样的第2变量的值y(t+δt)的差分。关于其他采样也同样地算出差分。
[0094]
基于对多个采样算出的差分来算出评价得分。可以使用均方根误差(root mean square error、rmse)、决定系数(r2)、平均绝对误差(mean absolute error、mae)、平均绝对误差率(mean absolute percentage error、mape)来作为评价得分。
[0095]
评价部8关于一个以上的数据分组与一个以上的模型架构之间的多个组合,生成预测模型,算出评价得分。基于所算出的评价得分,决定数据分组和模型架构的最好的组(评价得分最高的组)。将与所决定的组对应地生成的预测模型作为最好的预测模型。
[0096]
图8是表示预测模型的一个例子的图。函数f是进行与模型架构相应的处理的函数。函数f的括号内的变量与第1变量(预测模型的说明变量)对应。y(t+3)与第2变量(预测模型的目标变量)对应。在该例子中为δt=3。
[0097]
预测部9使用预测用的模型输入数据和通过模型生成部生成了的预测模型,算出第2变量(预测模型的目标变量)的预测值。模型输入数据制作部2在时间序列数据db1的时间序列数据中,确定标志(识别标志)表示“预测”的数据,在所确定的数据中,使用变量信息表示的变量(在预测模型中所使用的第1变量),制作预测用的模型输入数据。另外,使用数据分组信息,进行预测用的模型输入数据所包含的变量(第1变量)的分组。使用各数据组的变量(第1变量)和所生成的预测模型(即模型参数),算出目标变量(第2变量)的预测值。
[0098]
预测值db10将预测部9所算出的预测值(所预测到的目标变量的将来值)与成为预测对象的时刻(预测对象时刻或者时间戳)关联来进行保持。
[0099]
图9表示使用了比较例涉及的深度学习的预测模型生成的模型架构的例子。在本例中,本模型架构包括输入层、输出层以及中间层。中间层包括两个lstm(long short term memory、长短期存储)层和两个dense层(高密度层)来作为两种层。模型输入数据的全部变量(第1变量)是来自输入层中的节点(输入节点)的输出,并且,成为向第1lstm层中的隐藏节点的输入。来自第1lstm层的隐藏节点的输出成为向第2lstm层中的隐藏节点的输入,来自第2lstm层的隐藏节点的输出成为向第1dense层中的隐藏节点的输入,来自第1dense层的隐藏节点的输出成为向第2dense层中的隐藏节点的输入,来自第2dense层的隐藏节点的输出成为向输出层中的节点(输出节点)的输入,来自输出节点的输出成为预测值。
[0100]
在lstm层的情况下,进行学习的模型参数数量使用以下的式(1)来求出。此外,在使用了rnn(recurrent neural network、循环神经网络)层或者gru(gated recurrent unit、门控循环单元)层的情况下,进行学习的模型参数数量同样也使用以下的式(1)来求出。
[0101]
p=g(hm+h2+h)
ꢀꢀꢀ
(1)
[0102]
在此,m是输入节点数(或者输入源的层的节点数),h是隐藏层节点数(或者向下一层进行输出的节点数),g是门数。在lstm层的情况下,g为4。此外,在rnn层的情况下,g为1,在gru层的情况下,g为3。
[0103]
在第1dense层和第2dense层的情况下,进行学习的参数数量使用以下的式(2)来求出。
[0104]
p=h(m+1)
ꢀꢀꢀ
(2)
[0105]
在此,m为输入节点数(或者输入源的层的节点数),h是隐藏节点数(或者向下一层进行输出的节点数)。
[0106]
另一方面,在使用了通常的前馈神经网络的情况下,进行学习的参数数量使用以
下的式(3)来求出。
[0107]
p=h(m+o)+(h+o)
ꢀꢀꢀ
(3)
[0108]
在此,m为输入节点数(或者输入源的层的节点数),h为隐藏节点数(或者向下一层进行输出的节点数),o为输出节点数。
[0109]
图10表示使用了本实施方式涉及的深度学习的预测模型生成的模型架构的例子。在本例子中,与比较例涉及的深度学习同样地使用两个lstm(long short term memory)层和两个dense层,但第1lstm层和第2lstm层分别与数据组数相应地包括多个子lstm层(子模型)。第2lstm层中的多个子lstm层被合并,被合并后的子lstm层的输出成为第1dense层的输入。通过使用本实施方式的模型架构,模型输入数据的变量(第1变量)被分割为多个数据组,因此,能得到进行学习的模型参数减少的效果。此外,在图10的例子中,第2变量(预测模型的目标变量)具有y(t+1)、y(t+2)、
……
、y(t+δt)的多个变量,但也可能存在预测模型的目标变量的个数为一个的情况。
[0110]
图11表示与模型架构相应的各层的输入节点数(输入源的层的节点数)、隐藏节点数(向下一层进行输出的节点数)以及进行学习的模型参数数的例子。
[0111]
在图11的例子中,设想将变量(第1变量)分为过去数据(时滞数据)的组、当前数据的组、将来数据(超前(lead)数据)的组的情况。m1是过去数据的组的变量的个数,m2是当前数据的组的变量的个数,m3是将来数据的组的变量的个数。
[0112]
使用两个lstm层(lstm层1和lstm层2),使用两个dense层(dense层1和dense层2),图11lstm层2的节点数设为前一个的lstm层1的节点数的一半。同样地,dense层2的节点数设为前一个的dense层1的节点数的一半。在lstm层数为3个以上的情况下,lstm层的节点数也同样地可以设为前一个的lstm层的节点数的一半。在dense层数为3个以上的情况下,dense层的节点数也同样地可以设为前一个的dense层的节点数的一半。此外,“一半”为一个例子,也可以使用不同的比率。
[0113]
参数(n)是与lstm层的节点数的决定有关的参数(节点数系参数)。当根据参数(n)决定第1lstm层的节点数时,第2lstm层的节点数被决定为第1lstm层的节点数的一半等。根据参数(n)的值,lstm层的节点数会变动。另外,根据参数(n)的值,各层的进行学习的模型参数数量会变动。在图11中示出的各层的节点数的算出为一个例子,也可以通过其他方法来决定。参数(n)也可以按数据组而不同。
[0114]
图12基于图11的例子来表示与模型架构相应的、各层的进行学习的模型参数数量的计算的具体例。示出在第1lstm层中进行学习的模型参数数量n1、在第2lstm层中进行学习的模型参数数量n2、在第1dense层中进行学习的模型参数数量n3、在第2dense层中进行学习的模型参数数量n4的计算例。
[0115]
为了生成(学习)高精度的预测模型,模型输入数据的采样数需要为n1+n2+n3+n4(“+”意味着加法运算)以上。作为一个例子,在采样数为15万个、过去数据组的变量的个数m1=9、当前数据组的变量的个数m2=3、将来数据组的变量的个数m3=12、输出层的变量的个数p=12的情况下,参数(n)成为9以下。基于采样数为n1+n2+n3+n4以上这一条件(采样数条件),能够根据模型输入数据的采样数来决定各层的节点数。由此,能够与采样数无关地(即使采样数少),生成高精度的预测模型。即,能够决定能生成高精度的预测模型的模型架构,生成具有所决定的模型架构的预测模型。
[0116]
图13表示比较例涉及的深度学习的模型参数数量和本实施方式涉及的深度学习的模型参数数量。本实施方式涉及的深度学习的模型参数数量成为比较例涉及的深度学习的模型参数数量的大约三分一。在本实施方式中,若采样数为26560以上,则能够对精度高的预测模型进行学习,但在比较例涉及的深度学习的情况下,要对精度高的预测模型进行学习,需要75872以上的采样。
[0117]
图14表示如下例子:在模型学习用数据的采样数为15万、在预测模型中使用的变量(第1变量)的个数为10、预测模型的目标变量(第2变量)的个数、即输出数(预测步长数)为12的情况下,决定深度学习的层数、数据组数、节点数系参数(n)。
[0118]
首先,组合深度学习的中间层的各种类的层数、数据组数以及节点数系参数(n)来制作多个候选,关于各候选,由模型生成部6通过模型学习来生成预测模型。用评价部8对预测模型进行评价,算出评价得分。评价部8对多个候选中的得到了最好的评价得分或者小于阈值的评价得分的候选进行选择。此外,根据评价得分的定义,可以是值越大则评价越高的情况、值越小则评价越高的情况的任何构成。在本实施方式中,对值越小则评价越高的情况进行处理。
[0119]
根据本例子,选择了lstm层数为2、dense层数为2、数据组数为2(两个数据组的变量的个数均为5)、节点数系参数(n)为20的候选。也就是说,将模型输入数据的变量(10个)两等分为两个数据组。构建包括两个lstm层和两个dense层的模型架构,使用节点数系参数(n)来决定这些层的节点数。例如,也可以在满足前述的采样数条件的范围内进行决定以使得各层的节点数尽量变大。在该情况下所生成的预测模型的评价得分为56。该值是在多个候选中最好的预测精度(误差)。另外,所选择的候选中的模型参数数量(各层的模型参数数量的合计)为147924。
[0120]
使用图15、图16以及图17来对本实施方式的具体例(具体例1和具体例2)进行说明。
[0121]
图15表示时间序列数据的一个例子。图15的时间序列数据是说明变量(x1和x2)和目标变量(y)的时间序列数据。图16表示基于图15的时间序列数据来决定模型架构和数据分组的例子(具体例1)。在具体例1中表示在模型输入数据的制作中使用了时间升序的情况下的例子。在相互相关分析中,说明变量x1的时滞(l1)为4,说明变量x2的时滞(l2)为6,各自与目标变量y的相互相关成为最大。目标变量y的自相关在时滞3成为最大。预测步长δt设为12(在该例子中,对预测从当前的时间戳t起12个时刻后的目标变量的值的情况进行处理)。
[0122]
对于说明变量(x1和x2),对相互相关最大的时滞设定窗宽度w(=1),取得包括该时滞的时刻和前后的时刻的3个数据。此外,窗宽度是用户预先设定的。另外,对于目标变量,取得从当前的时间戳t到相互相关最大的时滞前为止的数据。在本例子中,包含当前的时间戳t而取得4个时刻量的数据。根据对于各说明变量和目标变量取得的数据制作模型输入数据。在本例子中,模型输入数据成为x1(t+7)、x1(t+8)、x1(t+9)、x2(t+5)、x2(t+6)、x2(t+7)、y(t-3)、y(t-2)、y(t-1)、y(t)。模型输入数据中的这些变量与第1变量(预测模型的说明变量)对应。也可以与前述的图4等的例子同样地在模型输入数据中包含第2变量(预测模型的目标变量y(t+δt))。
[0123]
接着,基于时间戳的升序,对模型输入数据进行分类。当进行分类时,模型输入数
据成为y(t-3)、y(t-2)、y(t-1)、y(t)、x2(t+5)、x2(t+6)、x2(t+7)、x1(t+7)、x1(t+8)、x1(t+9)。
[0124]
接着,按时间顺序对进行了分类的模型输入数据所包含的变量(第1变量)进行分组,生成数据分组的多个候选。在本例子中,生成两个分组候选。
[0125]
在分组候选1中,分别将4个、3个、3个变量分到第1数据组、第2数据组、第3数据组。其结果,第1数据组成为{y(t-3)、y(t-2)、y(t-1)、y(t)},第2数据组成为{x2(t+5)、x2(t+6)、x2(t+7)},第3数据组成为{x1(t+7)、x1(t+8)、x1(t+9)}。
[0126]
在分组候选2中,分别将3个、3个、4个变量分到第1数据组、第2数据组、第3数据组。其结果,第1数据组成为{y(t-3)、y(t-2)、y(t-1)},第2数据组成为{y(t)、x2(t+5)、x2(t+6)},第3数据组成为{x2(t+7)、x1(t+7)、x1(t+8)、x1(t+9)}。
[0127]
对于各分组候选决定模型架构,进行模型生成和评价(在本例子中为算出rmse来作为评价得分)。也可以对于各分组候选决定模型架构的多个候选,基于评价得分来选择最好的模型架构。与分组候选2有关的评价得分比分组候选1的评价得分好(小),因此,分组候选2被选择。另外,将对于分组候选2所决定的模型架构选择为最好的模型架构。另外,根据分组候选2和该模型架构生成的预测模型被选择。
[0128]
图17表示基于图15的时间序列数据来决定模型架构和数据分组的例子(具体例2)。表示对模型输入数据的制作和数据分组使用了先验知识的情况下的例子。设为用户预先对说明变量x1、说明变量x2以及目标变量y将时滞均设定为了6。另外,设为预测步长(δt)被设定为了12。因此,关于说明变量x1、x2,从时间序列数据取得t-6~t+12的时间戳的数据,关于目标变量y,从时间序列数据取得t-6~t的时间戳的数据,生成模型输入数据{x1(t-6)、
……
、x1(t+12)、x2(t-6)、
……
、x2(t+12)、y(t-6)、
……
、y(t-1)、y(t)}。模型输入数据中的这些变量与第1变量(预测模型的说明变量)对应。可以与前述的图4等的例子同样地在模型输入数据中包含第2变量(预测模型的目标变量y(t+δt))。
[0129]
将模型输入数据分为过去的数据{x1(t-6)、
……
、x1(t-1)、x2(t-6)、
……
、x2(t-1)、y(t-6)、
……
、y(t-1)}、当前的数据{x1(t)、x2(t)、y(t)}、将来的数据{x1(t+1)、
……
、x1(t+12)、x2(t+1)、
……
、x2(t+12)}这三个组。在数据分组后,决定模型架构,进行模型生成和评价(在本例子中为算出rmse来作为评价得分)。时刻t与第1时刻对应,时刻t之前的时刻(t-1~t-6)与第2时刻对应,时刻t之后的时刻(t+1~t+12)与第3时刻对应。时刻t与当前时刻、即进行预测的时间点的时刻对应。
[0130]
也可以生成时滞的多个候选,关于各时滞的候选算出评价得分。在该情况下,在时滞的候选之间对评价得分进行比较,决定最好的时滞。选择得到了最好的时滞的数据分组。
[0131]
在本说明中,分为了过去、当前、将来的3个数据数据组来作为数据分组,但也可以从多个分组的候选和多个时滞的候选选择分组候选和时滞候选的最好的组。也可以追加多个模型架构的候选,选择分组候选、时滞候选以及模型架构候选的最好的组。
[0132]
图18表示生成预测模型、预测目标变量的将来值的处理的流程图来作为本实施方式涉及的信息处理方法。首先,模型输入数据制作部2从时间序列数据db1得到处理标志(步骤s01),检查处理标志表示模型学习处理和预测处理中的哪个(步骤s02)。
[0133]
在处理标志表示模型学习处理的情况下(步骤s02:是),模型输入数据制作部2从时间序列数据db1读入模型学习用数据(步骤s03)。
[0134]
模型输入数据制作部2使用模型学习用数据来制作模型输入数据,向模型数据db7写入作为与模型输入数据所包含的变量(第1变量和第2变量)有关的信息的变量信息(步骤s04)。
[0135]
数据分组部3与模型架构决定部4、模型生成部6以及评价部8协作,进行模型输入数据所包含的第1变量的分组、模型架构的决定、预测模型的生成(模型参数的决定)以及预测模型的评价,决定最好的分组和最好的模型架构(最好的预测模型)(步骤s05)。得到表示所决定的分组的数据分组信息、所决定的模型架构的层信息、与所决定的预测模型有关的信息(模型信息)。步骤s05的详细将在后面进行描述。
[0136]
接着,评价部8向模型数据db7写入变量信息、数据分组信息、层信息、模型信息,结束处理(步骤s06)。
[0137]
在处理标志表示预测处理的情况下(步骤s02:否),模型输入数据制作部2基于保存于模型数据db7的信息,检查是否已生成预测模型(步骤s07)。在尚未生成预测模型的情况下(步骤s07:否),使用步骤s03~步骤s06来生成预测模型。
[0138]
在已生成预测模型的情况下(步骤s07:是),模型输入数据制作部2从时间序列数据db1读入预测用数据(步骤s08)。
[0139]
接着,模型输入数据制作部2从模型数据db7读入变量信息、数据分组信息、模型信息(步骤s09)。
[0140]
模型输入数据制作部2使用预测用数据和变量信息,制作预测用的模型输入数据(步骤s10)。
[0141]
模型输入数据制作部2使用数据组信息,对预测用的模型输入数据所包含的变量(第1变量)进行分组化(步骤s11)。
[0142]
预测部9使用各组的变量(第1变量)和模型信息表示的预测模型,算出预测值(步骤s12)。预测部9向预测值db10写入所算出的预测值(步骤s13)。
[0143]
图19是表示图18的步骤s05的详细动作的流程图。首先,模型架构决定部4决定在深度学习中使用的一个以上的种类的层,关于各种类的层生成层数候选(步骤s501)。例如,决定lstm层和dense层来作为层的种类,生成如<2、2>、<1、2>、<2、3>、<3、4>那样的多个层数候选。在<a、b>中,a为lstm层数,b为dense层数。层的种类和层数是模型架构的一个例子,此外,在能够选择模型的种类(线性回归模型、深度学习、神经网络等)的情况下,也可以决定模型的种类。模型的种类也是模型架构的一个例子。
[0144]
接着,数据分组部3生成一个或者多个分组候选(步骤s502)。分组候选是用于将模型输入数据的变量(第1变量)向多个数据组进行分类的分组的候选。既可以使用先验知识来生成分组候选,也可以随机地生成分组候选。作为制作分组候选的例子,也可以首先决定数据组数,然后,决定分类到各数据组的变量。作为一个例子,模型输入数据的变量的分组候选成为[5、5]、[4、6]、[3、3、4]、[2、3、5]、[4、2、4]、[1、3、6]、
……
。例如,[5、5]表示两个数据组,在各数据组中包含5个变量。同样地,在[3、3、4]的情况下,具有3个数据组,在各个数据组中包含3个、3个、4个变量。
[0145]
数据分组部3从在步骤s501和步骤s502中分别生成了的层数候选和分组候选,选择接下来的深度学习用(接下来的反复处理用)的层数候选和分组候选(步骤s503)。
[0146]
接着,模型架构决定部4对所选择的层数候选表示的值决定各层的节点数(步骤
s504)。
[0147]
接着,模型架构决定部4使用前述的式来按各层而算出模型参数数量,对各层的模型参数数量进行合计(步骤s505)。
[0148]
接着,模型架构决定部4检查模型参数的合计数是否为模型输入数据的采样数以下(步骤s506)。在模型参数的合计数不为采样数以下的情况下(步骤s506:否),模型架构决定部4对数据分组部3进行指示以使得对接下来的候选(层数候选和分组候选的组)进行选择。
[0149]
在模型参数数量为采样数以下的情况下(步骤s506:是),数据分组部3检查变量是否已分组化(步骤s507)。即,在从步骤s506返回到步骤s503时、或者在从后述的步骤s513返回到步骤s503时,在选择了与前次相同的分组候选的情况下,成为变量已分组化。在变量未分组化的情况下(步骤s507:否),数据分组部3对变量进行分组化(步骤s508)。在该情况下,或使用先验知识、或随机地、或按时间顺序将模型输入数据的变量分割为多个组。
[0150]
在使用了先验知识的分割的情况下,例如将模型输入数据的变量(第1变量)分为过去的数据、当前的数据以及将来的数据,分别作为第1数据组、第2数据组、第3数据组。例如设为模型输入数据的变量(第1变量和第2变量)为{x1(t-2)、x1(t-1)、x2(t-2)、x2(t-1)、y(t-2)、y(t-1)、x1(t)、x2(t)、y(t)、x1(t+1)、x1(t+2)、x2(t+1)、x2(t+2)、y(t+2)}。y(t+2)为第2变量(相当于预测模型的目标变量),其余的变量为第1变量(相当于预测模型的说明变量)。在该情况下,将第1变量分割为{{x1(t-2)、x1(t-1)、x2(t-2)、x2(t-1)、y(t-2)、y(t-1)}、{x1(t)、x2(t)、y(t)}、{x1(t+1)、x1(t+2)、x2(t+1)、x2(t+2)}}这3个组。
[0151]
在按时间顺序的分割的情况下,当分组候选为[3、3、4]时,按时间的升序对全部的变量进行排列,最初的三个被分为第1数据组,接下来的三个被分为第2数据组,最后的四个被分为第3数据组。
[0152]
在随机的分割的情况下,首先随机地选择3个变量来分为第1数据组,从剩余的7个变量随机地选择3个变量来分为第2数据组,将剩余的4个变量分为第3数据组。
[0153]
在变量已分组化的情况下(步骤s507:是),接着,模型生成部6从超参数部5得到模型的超参数信息(步骤s509)。
[0154]
模型生成部6基于各组的变量、超参数信息以及架构(层的种类、各层的节点数等),生成(学习)预测模型(步骤s510)。
[0155]
评价部8使用所生成的预测模型,算出模型输入数据的预测精度,算出评价值(评价得分等)(步骤s511)。
[0156]
评价部8通过步骤s503~s512的反复,保持最好的分组候选和预测模型的信息(步骤s512)。另外,也可以保持预测模型的模型架构的信息。
[0157]
接着,评价部8基于结束条件是否已成立来判断是否结束处理(步骤s513)。作为结束条件的例子,具有所保持的预测模型的精度为阈值以上的情况(足够的情况)。作为结束条件的其他例子,具有进行了预先设定的数量的反复的情况。作为结束条件的又一例子,具有选择了全部的层数候选的情况、选择了全部的分组候选的情况或者选择了全部的层数候选和分组候选的组合的情况。在结束条件已成立的情况下,决定结束处理。
[0158]
在结束处理的情况下(步骤s513:是),评价部8向模型数据db7写入在步骤s512中保持的信息、即最好的候选的信息(数据组信息、层信息)和与预测模型有关的信息(模型信
息)(步骤s514)。也可以向模型数据db7写入预测模型的模型架构的信息。
[0159]
在不结束处理的情况下(步骤s513:否),评价部8对数据分组部3进行指示以使得对接下来的候选进行选择。
[0160]
图20表示设定数据分组的条件(第1条件)和模型架构的条件(第2条件)等的学习条件、提示学习结果来作为评价部8的一个功能的图形用户界面(gui:graphical user interface)的一个例子。
[0161]
首先,用户点击处于“文件名”栏的右方的选择按钮,选择时间序列数据文件。当选择时间序列数据文件时,在文件名(801)这一栏保存有所选择的文件名。另外,生成模型输入数据,显示模型输入数据的采样数(802)、成为对象的说明变量和目标变量的个数(803)。进一步,显示包括说明变量和目标变量的名称(变量名)和预测值的有无的变量表(805)。在本例子中,作为时间序列数据,存在说明变量x1、x2和目标变量y。说明变量x1、x2均具有预测值。具有预测值意味着存在当前时刻t之后的时刻的值(预测值)。关于x1和x2,说明变量分别包括当前值、过去值、预测值。此外,目标变量y包括当前时刻的值和过去时刻的值。
[0162]
接着,用户输入预测步长数(804)。预测步长数相当于预测模型的目标变量(第2变量)的个数、即输出变量的个数。
[0163]
接着,用户将时滞(变量的时间偏差)输入到时滞字段(806),将模型输入数据制作方法从多个中选择(807)。在图的例子中,具有“没有”、“自动决定(相互相关)”、“自动决定(变量选择方法)”。在“没有”的情况下,说明变量和目标变量的时滞设为在时滞字段所输入的值,使用作为超参数所预先决定的窗口宽度来制作模型输入数据。在“自动决定(相互相关)”、“自动决定(变量选择方法)”的情况下,按照各个算法,将在时滞字段所输入的值作为最大时滞的限制,使用预先决定的窗口宽度来制作模型输入数据。也可以设为能够在本gui中指定窗口宽度。另外,参数(n)既可以作为超参数来预先决定,也可以设为能够在本gui中指定参数(n)。
[0164]
接着,用户选择是本装置决定数据分组(808)、还是用户决定来手动地进行输入。即,在画面中选择“自动决定”和“手动”中的任一个。
[0165]
在用户决定数据分组的情况下,在保存数据组数和数据组1~8(dg1~dg8)的成员数的文本框(809)输入各个值。在图的例子中,数据组数为3,数据组1~3的成员数分别为3、3、4。数据组数为3,因此,不存在数据组4~8,数据组4~8的成员数被输入作为默认值的-1。
[0166]
接着,选择模型输入数据的变量(第1变量)的分割方法(810)。在“先验知识”的情况下,将模型输入数据的变量分为过去的数据组、当前的数据组、将来的数据组。在选择“随机”的情况下,将模型输入数据的变量随机地分为多个数据组。在选择“依次”的情况下,按时间的顺序对全部的变量进行分类来分为多个数据组。此外,在“先验知识”的情况下,也可以与文本框(809)的值无关地,根据模型输入数据的结构来决定数据组数、各数据组的成员数。
[0167]
接着,用户选择是本装置决定各层的层数(811)、还是用户决定来手动地进行输入。在用户决定的情况下,在lstm、dense、dropout的文本框输入各个值。
“‑
1”意味着不使用相应的层,在附图的例子中,不使用dropout。也可以定义其他层、例如rnn层、gru层、cnn层。
[0168]
当用户点击模型架构决定按钮时,数据分组(选择了“自动决定”的情况)和模型架构被决定。作为所决定的模型架构(812)的信息,显示各层的节点数。另外,也显示各层的模
型参数数量的合计(813)和评价得分表(814)。
[0169]
评价部8也可以使用模型学习用数据的目标变量的值和阈值,将全部采样分类为峰部和非峰部的任一类别。将目标变量的值为阈值以上的采样分类为峰部的类别,将小于阈值的采样分类为非峰部的类别。评价部8按峰部和非峰部的各类别来算出rmse和mae。另外,也算出全部采样(全部区间)的rmse和mae。在评价得分表(814)中包含有峰部和非峰部的各类别的rmse和mae、全部采样(全部区间)的rmse和mae。
[0170]
用户确认评价得分表(814),在用户接纳学习结果的情况下,按下选择按钮,输入模型输出文件(815)的“文件名”,按下模型数据输出按钮。由此,模型架构的层信息(层名、层数)、数据组信息(数据组数、属于数据组的变量列表)、模型信息(模型参数值、超参数信息等)被写入到模型数据db7。
[0171]
(变形例)
[0172]
在上述的实施方式中,模型输入数据制作部2基于说明变量和目标变量的关系性,制作模型学习用的模型输入数据和预测用的模型输入数据,但在所制作的模型输入数据中相同的变量名的变量间的相关高的情况下,所生成的预测模型的精度有时会下降。例如在图6的模型输入数据中,具有x1(t-1)与x1(t-2)的相关高的情况、x2(t+1)与x2(t-1)的相关高的情况、y(t-1)与y(t-2)的相关高的情况等。为了消除该问题,模型输入数据制作部2关于时间序列数据中的各说明变量和目标变量,按相同的变量名而生成不同时刻的多个暂时性的变量,使用暂时性的变量来生成新的变量,将所生成的变量作为包含于模型输入数据的第1变量。要生成新的变量,也可以设为将暂时性的变量作为输入的函数,将函数的输出值作为新的变量。
[0173]
图21是模型输入数据制作部2生成新的变量的例子的说明图。对于变量x1生成t~t-24的多个时刻的暂时性的变量x1(t)~x1(t-24),对于变量x2生成t~t-24的多个时刻的暂时性的变量x2(t)~x2(t-12)。另外,作为对于变量x1的函数,准备f11、f12、f13、
……
,作为与变量x2有关的函数,准备f21、f22、f23、
……
。f11和f21是计算暂时性的变量的log的总和的函数,f12和f22是计算暂时性的变量的总和的函数,f13和f23是计算暂时性的变量的sin函数的总和的函数。
[0174]
由此,在该例子中,作为新的变量,计算:
[0175]
f11=log(x1(t-24))+log(x1(t-23))+
…
+log(x1(t))、
[0176]
f21=log(x2(t-12))+log(x2(t-11))+
…
+log(x2(t))、
[0177]
f12=sum(x1(t-24)、x1(t-23)、
…
、x1(t))、
[0178]
f22=sum(x2(t-12)、x2(t-11)、
…
、x2(t))、
[0179]
f13=sum(sinx1(t-24)、sinx1(t-23)、
…
、sinx1(t))、
[0180]
f23=sum(sinx2(t-12)、sinx2(t-11)、
…
、sinx2(t))。
[0181]
在本例子中示出了3个函数的例子,但也可以使用其他函数来生成新的变量。另外,关于x1,将输入变量的时刻设为了t~t-24,但也可以组合两个以上的多个时刻,生成多个新的变量。例如也可以如f14=log(x1(t-24))+log(x1(t-22))+log(x1(t-20))+
…
+log(x1(t-2))、f15=log(x1(t-23))+log(x1(t-21))+
…
+log(x1(t-3))+log(x1(t))、f16=sum(x1(t-11)、x1(t-7)、x1(t-5)、x1(t-3)、x1(t))、f17=sum(sinx1(t-4)、sinx1(t-3)、sinx1(t-2)、sinx1(t-1)、sinx1(t))那样追加地生成新的变量。关于x2也是同样的。
[0182]
也可以将新的变量间的相关系数满足阈值θ以下这一条件(相关条件)作为要件。即也可以将满足correlation(f1i、f1j)≤θ1和correlation(f2i、f2j)≤θ2作为要件。correlation(f1i、f1j)是函数的输出值f1i(新的变量)与函数的输出值f1j(新的变量)的相关系数。θ1和θ2是阈值,θ1和θ2也可以是相同的值。在该情况下,例如生成全部的新的变量的组,关于各组计算相关系数。仅最终地采用与其他任何新的变量的相关系数都为阈值θ以下的新的变量。
[0183]
在本例子中示出了关于x1和x2生成新的变量的例子,但也可以关于y也同样地生成新的变量。
[0184]
在图21的例子中使用预先确定的函数来生成了新的变量,但也可以通过其他方法来生成新的变量。例如也可以使用遗传编程(遗传算法)来生成新的变量。
[0185]
图22表示使用了遗传编程的新的变量的生成例。在使用了遗传编程的情况下,能够选择任意的变量,用于生成新的变量的函数也被自动地进行学习。在图22的例子中,作为基于遗传编程的学习的结果,生成解个体的树结构180。解个体的树结构180保持4个函数的树结构1801、1802、1803、1804。树结构1801、1802、1803、1804表示的函数为以下所述。
[0186]
f11=log(sin(x1(t-2))*(x1(t-24)-x1(t-3))/(x1(t-1)+x1(t-7)))
[0187]
f12=cos(x1(t-24))*x1(t)
[0188]
f13=x1(t-9)+x1(t-13)
[0189]
f14=log(x1(t-5))-sin(x1(t-11))
[0190]
在遗传编程中,首先从暂时性的模型输入数据和算子列表{+、-、/、*、log、sin、cos、tan、
…
}分别随机地选择变量和算子(运算符),制作包括多个初始解个体的列表。各初始解个体包括多个由随机地选择的算子和变量构成的函数(树结构)。即,在该列表中,与图22同样的形态的解个体的树结构作为一个要素,在列表中包括多个要素。算出初始解个体所包含的函数间的相关系数,算出初始解个体的适应度。例如关于初始解个体所包含的全部函数的对(组)算出相关系数,基于相关系数的平均、最大值或者最小值等来算出适应度。适应度越低,意味着初始解个体越好。
[0191]
接着,根据适应度,从初始解个体列表选择几个解个体(初始解个体),对所选择的解个体应用交叉和突变处理,生成新的解个体。接着,关于新的解个体算出适应度,从在前次的反复处理中所使用了的解个体列表(第1次为初始解个体列表)所包含的解个体和新的解个体中选择多个解个体,生成包括所选择的多个解个体的、接下来的反复处理用的解个体列表。反复按顺序进行解个体的选择、交叉和突变处理、下一次的反复处理用的解个体列表的制作,直到满足结束条件(例如反复次数等)。最后,在解个体列表中选择适应度为阈值以下的多个解个体,根据所选择的解个体所包含的多个树结构分别生成函数。图22的例子所示的解个体相当于所选择的解个体中的一个。基于图22所示的解个体的树结构180所包含的树结构1801~1804,生成上述的函数f11~f14。
[0192]
(应用例)
[0193]
图23表示本实施方式涉及的信息处理系统。图23的信息处理系统具备本实施方式涉及的信息处理装置(预测装置)101和计划装置(计划部)102。预测装置101和计划装置102能够通过有线方式或者无线方式进行通信。计划装置102也可以被组入到预测装置101。
[0194]
在本例子中,预测装置101预测与水力发电站的蓄水量关联的目标变量。例如,目
标变量是水库的蓄水量、水位、河水的水位等。说明变量是气象量(天气、降水量、气温等)。预测装置101向计划装置102提供所预测到的目标变量的预测值。计划装置102基于目标变量将来的预测值来生成发电计划。例如,生成使水库的水位落在一定范围内的发电计划。在估计为会因今后的降水量不足等而水位变低、无法得到所希望的发电量时,也可以进行通过基于需求响应的供需控制等来要求需要者节电等的控制。发电计划的方法不限定于特定的方法,只要使用预测装置101的输出结果,则也可以是任何方法。例如估计发电力不足的情况下,也可以为追加性地执行扬水发电等。也可以对核电站等其他发电机关通知不足的发电量等。
[0195]
也可以对上述的实施方式涉及的预测装置的至少一部分的构成部分进行芯片化。另外,也可以例如在边缘设备等的soc(system on chip,片上系统)的内部组入实施方式涉及的预测装置的至少一部分的构成部分。在该情况下,也可以为时间序列数据db、预测值db以及模型数据db中的至少一个设置在soc的外部,能够经由预定的接口设备进行访问。在上述的实施方式中说明过的预测装置的至少一部分既可以由硬件构成,也可以由软件构成。在由软件构成的情况下,也可以将实现预测装置的至少一部分功能的计算机程序保存于软盘、cd-rom等的记录介质,使包括处理器等的计算机读入来加以执行。记录介质不限定于磁盘、光盘等的可拆装的记录介质,也可以是硬盘装置或者存储器等的固定型的记录介质。
[0196]
[技术方案1]
[0197]
一种信息处理装置,具备:
[0198]
分组部,其对包含多个第1变量和第2变量的第1数据中的所述多个第1变量进行分组,生成包括所述第1变量的多个组;和
[0199]
决定部,其基于所述第1数据,决定对所述多个组所包含的所述第1变量和所述第2变量的预测值进行关联的预测模型的模型架构。
[0200]
[技术方案2]
[0201]
根据技术方案1所述的信息处理装置,
[0202]
具备评价部,所述评价部基于所述第2变量的预测值与所述第1数据中的所述第2变量的值的差分,算出所述预测模型的评价值,
[0203]
所述分组部基于所述评价值,进行所述多个第1变量的分组。
[0204]
[技术方案3]
[0205]
所述分组部生成对所述多个第1变量进行分组的多个分组候选,
[0206]
所述分组部根据基于所述评价值从所述多个分组候选中选择出的分组候选,对所述多个第1变量进行分组。
[0207]
[技术方案4]
[0208]
根据技术方案2或者3所述的信息处理装置,
[0209]
所述决定部基于所述评价值,决定所述模型架构。
[0210]
[技术方案5]
[0211]
根据技术方案1~4中任一项所述的信息处理装置,
[0212]
具备模型生成部,所述模型生成部基于由所述决定部决定的所述模型架构,生成所述预测模型。
[0213]
[技术方案6]
[0214]
根据技术方案1~5中任一项所述的信息处理装置,
[0215]
所述预测模型是包括将所述多个组的所述第1变量作为输入的多个子模型、基于所述多个子模型的输出值来预测所述第2变量的模型。
[0216]
[技术方案7]
[0217]
根据技术方案1~6中任一项所述的信息处理装置,
[0218]
所述多个第1变量与多个时刻关联,
[0219]
所述分组部按与所述时刻相应的顺序对所述多个第1变量进行分组。
[0220]
[技术方案8]
[0221]
根据技术方案1~7中任一项所述的信息处理装置,
[0222]
所述多个第1变量包括第1时刻的变量、所述第1时刻之前的第2时刻的变量以及所述第1时刻之后的第3时刻的变量,
[0223]
所述分组部将所述第1时刻的变量分类到第1组,将所述第2时刻的变量分类到第2组,所述第3时刻的变量分类到第3组。
[0224]
[技术方案9]
[0225]
根据技术方案8所述的信息处理装置,
[0226]
所述第1时刻与进行基于所述预测模型的预测的时间点的时刻对应。
[0227]
[技术方案10]
[0228]
根据技术方案1~6中任一项所述的信息处理装置,
[0229]
所述分组部随机地对所述多个第1变量进行分组。
[0230]
[技术方案11]
[0231]
根据技术方案1~9中任一项所述的信息处理装置,
[0232]
所述预测模型是包括输入层、至少一个中间层以及输出层的神经网络,
[0233]
所述决定部决定所述至少一个中间层中的节点数来作为所述模型架构。
[0234]
[技术方案12]
[0235]
根据技术方案1~11中任一项所述的信息处理装置,
[0236]
所述决定部决定所述至少一个层的层数来作为所述模型架构。
[0237]
[技术方案13]
[0238]
根据技术方案1~12中任一项所述的信息处理装置,
[0239]
所述决定部决定所述预测模型的模型参数数量为所述第1数据的采样数以下的模型架构。
[0240]
[技术方案14]
[0241]
根据技术方案1~13中任一项所述的信息处理装置,
[0242]
具备数据制作部,所述数据制作部在一个以上的说明变量的时间序列数据和目标变量的时间序列数据中算出所述说明变量与所述目标变量的相互相关,基于所述相互相关来制作所述第1数据,
[0243]
所述第1数据中的所述第2变量包括预测对象时刻的所述目标变量,
[0244]
所述第1数据中的所述多个第1变量相应于所述相互相关而包括所述预测对象时刻之前的多个时刻的所述说明变量。
[0245]
[技术方案15]
[0246]
根据技术方案14所述的信息处理装置,
[0247]
所述数据制作部算出所述目标变量的自相关,
[0248]
所述第1数据中的所述多个第1变量相应于所述自相关而包括所述预测对象时刻之前的时刻的所述目标变量。
[0249]
[技术方案16]
[0250]
根据技术方案1~14中任一项所述的信息处理装置,
[0251]
具备数据制作部,所述数据制作部在一个以上的说明变量的时间序列数据和目标变量的时间序列数据中,根据所述预测对象时刻之前的多个时刻的所述说明变量对预测对象时刻的所述目标变量进行回归,算出所述多个时刻的所述说明变量的系数,基于所述系数,从所述多个时刻的所述说明变量中选择多个时刻的所述说明变量,
[0252]
通过将所选择的多个时刻的所述说明变量作为所述第1数据的所述多个第1变量,将所述预测对象时刻的所述目标变量作为所述第1数据的所述第2变量,从而制作所述第1数据。
[0253]
[技术方案17]
[0254]
根据技术方案15所述的信息处理装置,
[0255]
所述数据制作部通过基于遗传算法对所述一个以上的说明变量的时间序列数据中的多个时刻的所述说明变量、所述目标变量的时间序列数据中的多个时刻的所述目标变量以及至少一个运算符进行组合,从而生成所述第1变量。
[0256]
[技术方案18]
[0257]
根据技术方案5所述的信息处理装置,
[0258]
所述模型生成部基于所述第1数据中的所述第2变量的值来对所述第1数据设定权重,基于所述权重来生成所述预测模型。
[0259]
[技术方案19]
[0260]
根据技术方案18所述的信息处理装置,
[0261]
所述模型生成部在所述第2变量的值与峰部对应的情况下对所述第1数据设定第1权重,在所述第2变量的值与非峰部对应的情况下对所述第1数据设定比所述第1权重小的第2权重。
[0262]
[技术方案20]
[0263]
根据技术方案2~4中任一项所述的信息处理装置,
[0264]
所述评价部具备设定与所述分组有关的第1条件和与所述模型架构有关的第2条件的图形用户界面,
[0265]
所述分组部基于所述第1条件来进行所述分组,
[0266]
所述决定部基于所述第2条件来决定所述模型架构。
[0267]
[技术方案21]
[0268]
一种信息处理方法,包括:
[0269]
对包含多个第1变量和第2变量的第1数据中的所述多个第1变量进行分组,生成包括所述第1变量的多个组;和
[0270]
基于所述第1数据,决定对所述多个组所包含的所述第1变量和所述第2变量的预测值进行关联的预测模型的模型架构。
[0271]
[技术方案22]
[0272]
一种计算机程序,用于使计算机执行:
[0273]
对包含多个第1变量和第2变量的第1数据中的所述多个第1变量进行分组,生成包括所述第1变量的多个组的步骤;和
[0274]
基于所述第1数据,决定对所述多个组所包含的所述第1变量和所述第2变量的预测值进行关联的预测模型的模型架构的步骤。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1